
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
Límites teóricos del recupero basado en embeddings
Cada vez que usamos un buscador, un asistente virtual o un sistema que mezcla información para contestar preguntas, detrás hay un mecanismo que decide qué traer y en qué orden mostrarlo. Ese mecanismo, en los últimos años, se apoya de manera creciente en los llamados embeddings, representaciones numéricas que convierten palabras, frases o documentos completos en puntos de un espacio geométrico. La idea básica es que lo que tiene significados parecidos debería quedar cerca, y lo que es muy distinto debería estar lejos. Así, buscar un concepto se convierte en una tarea de medir distancias: la consulta se transforma en un vector, cada documento también, y los más próximos a la consulta aparecen como resultados.
Ese procedimiento es ágil, general y eficiente, razón por la cual se ha vuelto tan popular en motores de búsqueda, en plataformas de preguntas y respuestas, en sistemas de recomendación e incluso en aplicaciones creativas donde se necesita combinar contexto externo con generación de texto. Sin embargo, lo que este enfoque oculta es que no siempre puede capturar la enorme variedad de combinaciones que los usuarios exigen cuando las consultas se vuelven más elaboradas. No es lo mismo recuperar un solo documento que contenga una palabra clave, que atender a peticiones que combinan condiciones, comparan escenarios o piden conjuntos específicos de resultados. En esos casos aparece un límite estructural: hay situaciones en las que, por más sofisticado que sea el entrenamiento del modelo, un espacio de dimensión fija no alcanza para representar todas las posibles relaciones.
El artículo On the Theoretical Limitations of Embedding-Based Retrieval se adentra en este problema y lo muestra con claridad. No se trata de una falla en el entrenamiento ni de un descuido técnico. Se trata de un límite geométrico y matemático: existen patrones de relevancia entre consultas y documentos que no pueden expresarse dentro de un mapa de pocas dimensiones. Aunque aumentemos el tamaño del modelo o la calidad de los datos, esas restricciones persisten porque son consecuencia de la propia forma en que funciona el sistema. Reconocerlo no implica abandonar los embeddings, sino entender mejor dónde resultan útiles y dónde conviene complementarlos con otras técnicas.
El trabajo aporta tres contribuciones principales. Primero, una demostración teórica de que la capacidad de los embeddings de un solo vector está acotada por la complejidad de las combinaciones de resultados que se deben cubrir. Segundo, una serie de experimentos de “mejor caso posible” que muestran cómo, incluso en condiciones ideales, la capacidad se satura cuando aumenta el número de combinaciones a representar. Y tercero, la creación de un conjunto de datos llamado LIMIT, diseñado para forzar este escenario y poner en evidencia las debilidades prácticas de los modelos de referencia. Con estos elementos, se construye una narrativa convincente: los embeddings funcionan muy bien en muchos contextos, pero no son una solución mágica para todo tipo de recupero de información.
La lógica detrás de los embeddings
Para dimensionar cómo trabajan los embeddings, pensemos en un mapa. Cada documento ocupa un lugar, cada consulta se convierte en un punto, y el sistema busca lo que está más cerca. Si el mapa es de dos dimensiones, como una hoja de papel, podemos dibujar círculos alrededor de la consulta y elegir lo que cae adentro. Si el mapa tiene más dimensiones, la idea se repite aunque ya no podamos visualizarlo. Lo importante es que la cercanía en ese espacio se supone equivalente a la relevancia en el sentido del usuario.
Este procedimiento resulta muy útil cuando las consultas son simples: “dame información sobre volcanes”, “tráeme un artículo sobre vacunas”, “busco canciones de los años setenta”. En esos casos, los documentos con palabras y contextos parecidos quedarán cerca y aparecerán en la lista. El problema surge cuando las consultas se vuelven más exigentes. Supongamos que pedimos “artículos que hablen de volcanes y también mencionen agricultura, pero que no traten sobre turismo”. Aquí ya no basta con una proximidad simple, porque la combinación de condiciones genera un patrón mucho más complejo de qué debería estar dentro y qué fuera.
Lo que el estudio muestra es que este tipo de combinaciones pueden ser tan numerosas que exceden la capacidad del mapa. En un conjunto grande de documentos, la cantidad de formas posibles de elegir subconjuntos relevantes crece de manera explosiva. Llega un punto en el que un espacio de dimensión fija no tiene suficiente “resolución” para separar todos esos casos a la vez. Esto no depende del algoritmo específico ni de la potencia de cómputo. Es una limitación de principio: cuando intentamos cubrir demasiadas combinaciones con un único vector por consulta y por documento, inevitablemente habrá escenarios que queden mal representados.
Este hallazgo se traduce en un mensaje claro. Los embeddings de un solo vector funcionan bien para tareas promedio y consultas habituales, pero no se les puede pedir que resuelvan por sí solos consultas composicionales o altamente condicionales. Allí se necesita aumentar la expresividad del modelo o combinar técnicas que sumen más grados de libertad.
Demostraciones y experimentos
El artículo no se queda en afirmaciones generales. Propone experimentos que buscan el mejor escenario posible para los embeddings. En lugar de depender de textos reales, los investigadores optimizan directamente los vectores de consultas y documentos para ver hasta dónde se puede llegar. De esta manera eliminan cualquier factor externo y se concentran en la pregunta pura: ¿cuánto puede expresar un embedding en un espacio de dimensión fija?
El resultado es revelador. Se observa que existe un punto crítico a partir del cual, aunque se optimicen los vectores de la manera más favorable, el sistema ya no puede representar todas las combinaciones requeridas. La relación entre la dimensión del embedding y el tamaño de las colecciones que se pueden cubrir muestra una curva clara: con pocas dimensiones solo se pueden manejar pocas combinaciones; al aumentar la dimensión, se amplía la cobertura, pero siempre hay un límite finito. Aun con tamaños de embedding comunes en la práctica, los problemas aparecen mucho antes de lo que uno podría suponer cuando se trata de consultas que exigen múltiples condiciones.
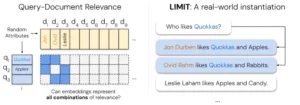
Los investigadores también llevan la teoría al terreno del lenguaje con el dataset LIMIT. Allí construyen documentos muy simples con atributos definidos y consultas que combinan esos atributos de distintas maneras. A pesar de que las oraciones son claras y no tienen ambigüedad, los modelos de referencia fallan de manera notable. No es un problema de comprensión lingüística, porque las frases son triviales. Es un problema de que las combinaciones a cubrir son tantas que el espacio vectorial no puede diferenciarlas. En contraste, modelos que usan múltiples vectores por documento o métodos clásicos de alta dimensionalidad como BM25 logran resultados mucho mejores, justamente porque disponen de más grados de libertad para separar patrones.
Un aspecto interesante es que cuando se aplica un reranqueador potente, es decir, un modelo más caro que examina un número reducido de candidatos con mayor detalle, los resultados mejoran drásticamente. Esto confirma que el cuello de botella está en la primera fase de recupero con un solo vector, no en la capacidad general del sistema de razonamiento. En consecuencia, una estrategia práctica es usar embeddings como filtro inicial y luego aplicar métodos más expresivos en una segunda etapa.
El papel del dataset limit
La creación de LIMIT tiene un valor pedagógico además de experimental. Se trata de un conjunto de datos construido de forma natural, sin trampas, pero con una estructura que fuerza a los modelos a cubrir un gran número de combinaciones. Los documentos son simples descripciones de personas con ciertos gustos, y las consultas piden encontrar a las que comparten atributos específicos. Lo interesante es que, con un número relativamente pequeño de documentos y consultas, se logra generar todas las posibles combinaciones de pares relevantes. Esto pone en evidencia el límite de los embeddings sin necesidad de ejemplos artificiales o de alta complejidad.
En las pruebas, modelos de referencia que brillan en benchmarks masivos caen en desempeño cuando enfrentan LIMIT. Por el contrario, técnicas multivectoriales o de gran dimensionalidad como BM25 resisten mejor. Esto confirma que el problema no está en la calidad del entrenamiento, sino en la forma misma de representar la información. Un solo vector por documento y por consulta no tiene capacidad suficiente para distinguir entre todas las combinaciones cuando estas se multiplican.
El valor de LIMIT es que ofrece una herramienta sencilla para medir esta debilidad y para guiar futuras investigaciones. Al ser un dataset público y fácil de comprender, permite a distintos equipos probar variaciones de modelos y confirmar si efectivamente logran superar el límite estructural o solo mejorar marginalmente en contextos donde el problema no se presenta.
Consecuencias prácticas
Aceptar que los embeddings tienen límites no significa descartarlos, sino usarlos con mayor criterio. Para muchas aplicaciones siguen siendo la mejor opción inicial: son rápidos, compactos y versátiles. Funcionan bien en escenarios donde las consultas no requieren combinaciones complejas y donde el número de posibles patrones relevantes es manejable. El problema surge cuando se intenta usarlos como única herramienta en aplicaciones que necesitan cubrir una gran variedad de combinaciones y condiciones. Allí conviene combinarlos con otros métodos.
Una estrategia efectiva es la de dos etapas. Primero, se usa un sistema de embeddings para recuperar un conjunto amplio de candidatos de manera eficiente. Después, un modelo más expresivo, que puede ser multivectorial o un reranqueador basado en generación, refina la lista y elige lo realmente relevante. Otra posibilidad es emplear representaciones híbridas que mezclan embeddings densos con métodos esparsos tradicionales, de modo que se aproveche la rapidez de unos y la capacidad discriminativa de otros.
También se pueden reformular las consultas para descomponerlas en partes más simples que se recuperan por separado y luego se combinan. Esto reduce la presión sobre el embedding, que no necesita representar todas las condiciones a la vez. Y en algunos casos se pueden añadir metadatos o señales adicionales que ayudan a restringir el espacio de búsqueda antes de aplicar la métrica vectorial.
En resumen, la enseñanza es que los embeddings deben verse como una pieza dentro de un engranaje más amplio, no como la solución definitiva. Reconocer sus limitaciones permite diseñar sistemas más robustos y evitar decepciones cuando las consultas se vuelven demasiado exigentes para su capacidad representacional.
Reflexión final
El estudio de los límites teóricos del recupero basado en embeddings nos recuerda que ninguna técnica es ilimitada. Los embeddings revolucionaron la búsqueda porque transformaron la semántica en geometría, pero esa geometría tiene fronteras claras. Cuando las consultas son simples, funcionan con eficacia notable. Cuando la diversidad de combinaciones se expande, la capacidad se satura y aparecen fallos inevitables. La solución no es abandonar el enfoque, sino integrarlo con otras estrategias que compensen sus carencias.
En términos más amplios, este trabajo señala un rumbo para toda la investigación en inteligencia artificial: no basta con celebrar lo que funciona, hay que explorar dónde deja de funcionar y por qué. Solo así se pueden construir sistemas confiables y honestos con sus usuarios. Para quienes diseñan productos, la lección es práctica: los embeddings son una herramienta poderosa, pero no deben usarse en soledad cuando las demandas crecen en complejidad. Para la sociedad en general, el mensaje es de madurez: entender los límites de la tecnología es parte de aprender a usarla de manera responsable.
La importancia de este estudio radica en que llega en un momento en que la IA se está convirtiendo en infraestructura crítica. Saber hasta dónde llegan las técnicas actuales y dónde empiezan a flaquear es indispensable para no sobredimensionar promesas ni poner en riesgo aplicaciones sensibles. El futuro del recupero de información, y de la inteligencia artificial en general, depende tanto de reconocer sus capacidades como de aceptar sus fronteras. Solo así se podrá avanzar hacia sistemas que no solo sean impresionantes en demostraciones, sino también confiables en el uso cotidiano.
Referencias:
Weller, O., Boratko, M., Naim, I., y Lee, J. (2025). On the theoretical limitations of embedding-based retrieval. arXiv:2508.21038.
Papadimitriou, C. H., y Sipser, M. (1982). Communication complexity. Proceedings of the fourteenth annual ACM symposium on Theory of computing, 196–200.
Alon, N., Moran, S., y Yehudayoff, A. (2014). Sign rank, VC dimension and spectral gaps. Electronic Colloquium on Computational Complexity, 21, 10.
Hatami, H., y Hatami, P. (2024). Structure in communication complexity and constant-cost complexity classes. arXiv:2401.14623.
Chierichetti, F., Gollapudi, S., Kumar, R., Lattanzi, S., Panigrahy, R., y Woodruff, D. P. (2017). Algorithms for ℓp low-rank approximation. ICML, 806–814.
Reimers, N., y Gurevych, I. (2020). The curse of dense low-dimensional information retrieval for large index sizes. arXiv:2012.14210.
Khattab, O., y Zaharia, M. (2020). ColBERT: Efficient and effective passage search via contextualized late interaction over BERT. SIGIR, 39–48.
Robertson, S. E., Walker, S., Jones, S., Hancock-Beaulieu, M. M., y Gatford, M. (1995). Okapi at TREC-3. NIST Special Publication SP, 109.
Muennighoff, N., Tazi, N., Magne, L., y Reimers, N. (2022). MTEB: Massive Text Embedding Benchmark. arXiv:2210.07316.
Lee, J., Chen, F., Dua, S., Cer, D., Shanbhogue, M., Naim, I., Ábrego, G. H., Li, Z., Chen, K., Vera, H. S., y otros. (2025). Gemini embedding: Generalizable embeddings from Gemini. arXiv:2503.07891.
Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., Howard-Snyder, W., Chen, K., Kakade, S., Jain, P., y otros. (2022). Matryoshka representation learning. NeurIPS, 35, 30233–30249.
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., y otros. (2019). Natural Questions: A benchmark for question answering research. TACL, 7, 453–466.
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., y Manning, C. D. (2018). HotpotQA: A dataset for diverse, explainable multi-hop question answering. arXiv:1809.09600.
Su, H., Shi, W., Kasai, J., Wang, Y., Hu, Y., Ostendorf, M., Yih, W.-t., Smith, N. A., Zettlemoyer, L., y Yu, T. (2024). BRIGHT: A realistic and challenging benchmark for reasoning-intensive retrieval. arXiv:2407.12883.
Malaviya, C., Shaw, P., Chang, M.-W., Lee, K., y Toutanova, K. (2023). QUEST: A retrieval dataset of entity-seeking queries with implicit set operations. arXiv:2305.11694.
Chaffin, A., y Sourty, R. (2024). Pylate: Flexible training and retrieval for late interaction models. https://github.com/lightonai/pylate
Voronoi, G. (1908). Nouvelles applications des paramètres continus à la théorie des formes quadratiques. Journal für die reine und angewandte Mathematik, 134, 198–287.

