
Por Elena Vargas, Periodista Especializada en Ciencia y Tecnología, para Mundo IA
Cómo la destilación de prompts resuelve el mayor enigma de la Inteligencia Artificial
En el corazón de la revolución tecnológica que define nuestra era, se encuentra una conversación. No es una conversación entre humanos, sino una que mantenemos con una nueva forma de inteligencia, vasta y poderosa: los Grandes Modelos de Lenguaje, o LLMs. Estas inteligencias artificiales, entrenadas con la práctica totalidad del conocimiento humano digitalizado, son capaces de escribir poesía, generar código informático, redactar análisis de mercado complejos y responder a nuestras preguntas más extrañas con una fluidez asombrosa. La clave para desbloquear este inmenso potencial reside en una sola cosa: la instrucción que les damos, una frase o un párrafo que en la jerga del sector se conoce como «prompt». Un prompt es la varita mágica, la llave que abre la puerta a las capacidades del modelo. Es el pincel con el que un artista dirige a la IA para que pinte una obra maestra. Sin embargo, en esta aparente simplicidad se esconde uno de los mayores desafíos y cuellos de botella de la inteligencia artificial moderna.
Descubrir el prompt perfecto para una tarea específica se ha convertido en una especie de arte oscuro, una disciplina a medio camino entre la ciencia, la psicología y la intuición, conocida como «ingeniería de prompts». Los expertos en este campo, a menudo llamados «susurradores de IA», pasan horas, e incluso días, experimentando con diferentes frases, estructuras y palabras clave para coaccionar al modelo a que produzca el resultado deseado de manera consistente y fiable. Un pequeño cambio en la redacción puede producir una diferencia abismal en la calidad de la respuesta. Esta dependencia de la artesanía manual es una profunda ironía: para poder utilizar eficazmente una de las tecnologías más avanzadas y automatizadas de la historia, dependemos de un proceso que es lento, costoso y eminentemente humano. Es como tener el motor de un coche de Fórmula 1 y tener que pasar una semana tallando a mano la llave perfecta para poder arrancarlo. Este desafío no es solo académico; limita la velocidad con la que las empresas pueden desarrollar nuevas aplicaciones de IA, aumenta los costos y crea una barrera de entrada para aquellos que no tienen la experiencia necesaria.
En un intento por resolver este problema, los investigadores desarrollaron métodos de «Optimización Automática de Prompts» (APO). La idea era brillante: usar una IA para que descubriera el mejor prompt para otra IA. Estos sistemas generan automáticamente docenas de prompts candidatos, los prueban y se quedan con el que funciona mejor. Sin embargo, esta primera solución, aunque potente, trajo consigo sus propios problemas. Los prompts que estas IAs generaban eran a menudo monstruosidades de la ingeniería: largos, complejos, repetitivos y casi incomprensibles para un ser humano. Funcionaban, sí, pero eran cajas negras. Nadie sabía exactamente por qué funcionaban, y un humano no podía aprender nada de ellos ni modificarlos fácilmente. Además, el proceso de prueba y error era computacionalmente muy caro. Era como pedirle a una máquina que construyera la llave del coche, y que en lugar de una llave elegante, nos diera una enorme y enrevesada escultura de metal que, de alguna manera, lograba arrancar el motor.
Es en este contexto donde un nuevo trabajo de investigación, titulado «Optimización Automática de Prompts con Destilación de Prompts», presenta una solución tan elegante como revolucionaria. Los investigadores proponen un sistema que no solo automatiza la creación de prompts, sino que lo hace con un objetivo final en mente: la simplicidad y la comprensión humana. Su método, APO-PD, introduce un segundo paso crucial en el proceso, la «destilación». El proceso comienza de forma similar a otros métodos de optimización: una IA «optimizadora» genera una multitud de prompts complejos y los pone a prueba para encontrar los de mejor rendimiento. Pero aquí es donde ocurre la magia. En lugar de quedarse simplemente con el prompt más exitoso y enrevesado, el sistema reúne a un grupo de los mejores candidatos. Luego, se los presenta a una segunda IA, la «destiladora», con una tarea muy especial: actuar como una experta editora. La misión de la destiladora es analizar todos esos prompts exitosos y extraer su esencia común, sus principios subyacentes, para luego «destilar» esa sabiduría en un prompt nuevo, que sea a la vez conciso, potente y, lo más importante, perfectamente comprensible para un ser humano.
Es un proceso análogo al de la destilación de un buen whisky. Primero se fermenta una gran cantidad de grano para crear un líquido complejo (la optimización). Luego, a través del calor y la condensación del alambique, se extrae solo el espíritu más puro y concentrado, el corazón del sabor (la destilación). De la misma manera, APO-PD toma la complejidad generada por la máquina y extrae la esencia pura de la instrucción. Los resultados son extraordinarios. El sistema produce prompts que no solo igualan o superan el rendimiento de los generados por otros métodos automáticos, sino que son drásticamente más cortos y claros. En lugar de una parrafada ininteligible de cien palabras, se obtiene una instrucción clara y directa de veinte. Esto tiene implicaciones monumentales. Por primera vez, tenemos un método automático que no solo nos da una solución, sino que nos enseña por qué es una solución. Los ingenieros humanos pueden mirar el prompt destilado y entender la estrategia que funciona, aprender de ella y aplicarla a otros problemas. Se transforma una caja negra en una herramienta de aprendizaje. Este avance promete derribar la barrera de la ingeniería de prompts, haciendo que el poder de los Grandes Modelos de Lenguaje sea más accesible, eficiente y comprensible para todos, acelerando la innovación y marcando el comienzo de una nueva era de colaboración más fluida e intuitiva entre humanos y máquinas.
El arte y la ciencia de hablar con máquinas
Para apreciar la magnitud del problema que la destilación de prompts viene a resolver, primero debemos sumergirnos en el fascinante mundo de cómo «piensan» los Grandes Modelos de Lenguaje. Estas IAs no entienden el lenguaje de la misma manera que los humanos. No poseen conciencia, creencias ni intenciones. En su núcleo, son motores de predicción de patrones a una escala inimaginable. Un LLM se entrena con una cantidad de texto que un humano no podría leer en miles de vidas: libros, artículos de Wikipedia, conversaciones en foros, código de programación, noticias, y un largo etcétera. Durante este entrenamiento, el modelo aprende las relaciones estadísticas entre las palabras, las frases y los conceptos. Aprende que la palabra «cielo» suele estar asociada con «azul», que la frase «Érase una vez» suele preceder a un cuento, y que en el lenguaje de programación Python, def inicia la definición de una función.
Cuando le damos un prompt a un LLM, lo que realmente estamos haciendo es proporcionarle un punto de partida, un contexto inicial. El modelo toma este contexto y comienza a hacer lo que mejor sabe: predecir la siguiente palabra más probable. Luego, toma la secuencia original más esa nueva palabra y predice la siguiente, y así sucesivamente, palabra por palabra, o más técnicamente «token por token». Este proceso, aunque simple en su descripción, da lugar a la asombrosa capacidad de generar texto coherente y relevante cuando se realiza a la velocidad de los chips modernos. La calidad de este texto generado, sin embargo, depende de forma crítica de la calidad del punto de partida. El prompt es el timón que dirige el barco del LLM a través del océano infinito de posibles respuestas.
Aquí es donde nace la disciplina de la ingeniería de prompts. Pronto se descubrió que para tareas que no fueran triviales, un simple «escribe un poema sobre el mar» a menudo producía resultados mediocres. Para obtener algo verdaderamente bueno, el prompt debía ser mucho más sofisticado. Los ingenieros de prompts aprendieron a incluir elementos clave en sus instrucciones.
- Contexto y Rol: Darle a la IA un papel que desempeñar a menudo mejora drásticamente los resultados. En lugar de «resume este texto», un prompt mucho más eficaz sería «Actúa como un analista financiero experto. Resume el siguiente informe de resultados para un inversor que no tiene tiempo, centrándote en los riesgos y oportunidades clave». Esto prepara a la IA para que utilice un vocabulario, un tono y un enfoque específicos.
- Especificidad y Restricciones: Las instrucciones vagas producen resultados vagos. Un buen prompt establece límites y requisitos claros. Por ejemplo, «Genera ideas para un nombre de empresa» es débil. «Genera cinco nombres para una empresa de café sostenible que sean cortos, memorables y que evoquen una sensación de calidez y comunidad. Evita nombres que contengan la palabra ‘express'» es infinitamente mejor.
- Ejemplos (Few-Shot Prompting): Una de las técnicas más poderosas es proporcionar al modelo algunos ejemplos del resultado deseado. Si quieres que la IA clasifique el sentimiento de las opiniones de los clientes, podrías darle un prompt que incluya dos o tres ejemplos: «Opinión: ‘El servicio fue increíblemente rápido.’ Sentimiento: Positivo. Opinión: ‘Esperé cuarenta minutos por un café frío.’ Sentimiento: Negativo. Opinión: ‘La comida estuvo bien, pero el lugar era ruidoso.’ Sentimiento:». El modelo aprende el patrón a partir de los ejemplos y lo aplica a la nueva opinión.
Dominar estas técnicas requiere una mezcla de lógica, creatividad y muchísima experimentación. Es un proceso iterativo de escribir un prompt, probarlo, analizar el resultado, ajustar el prompt y volver a empezar. Para una empresa que quiere integrar un LLM en su servicio de atención al cliente o en su herramienta de análisis de datos, este proceso manual es un enorme cuello de botella. Requiere personal altamente especializado, consume un tiempo de desarrollo valioso y los resultados pueden ser frágiles; un prompt que funciona bien hoy podría necesitar ajustes después de una actualización del modelo. La necesidad de una forma de automatizar esta «magia negra» era evidente. El objetivo era claro: crear un sistema que pudiera descubrir estas instrucciones complejas y eficaces por sí mismo, liberando a los humanos de este ciclo de prueba y error.
Los primeros intentos de automatización: una solución incompleta
La respuesta lógica al cuello de botella de la ingeniería de prompts manual fue recurrir a la propia inteligencia artificial para obtener una solución. Así nacieron los primeros métodos de Optimización Automática de Prompts (APO). El concepto era elegante en su núcleo: si los LLMs son tan buenos generando y entendiendo texto, ¿por qué no podrían ser buenos generando y mejorando los prompts que ellos mismos utilizan? El enfoque general de estos sistemas pioneros se asemeja a un proceso de selección natural o evolución darwiniana para las instrucciones de IA.
El proceso normalmente comenzaba con un prompt inicial muy simple, escrito por un humano, como «Responde a la pregunta basándote en el documento». Además, el sistema recibía un pequeño conjunto de datos de entrenamiento, que consistía en pares de problemas y sus soluciones correctas deseadas. Por ejemplo, una serie de documentos, preguntas sobre esos documentos y las respuestas correctas. Armado con esto, el sistema, a menudo utilizando un LLM «maestro» o «optimizador», se ponía a trabajar en un ciclo iterativo. Primero, generaba una variedad de prompts candidatos. Podía tomar el prompt original y proponer formas de reformularlo, añadirle más detalles o sugerir instrucciones completamente nuevas. Por ejemplo, podría generar variantes como: «Extrae la respuesta exacta del siguiente documento» o «Lee el documento adjunto y responde a la pregunta de forma concisa. Tu respuesta debe ser una cita directa del texto».
En el segundo paso, cada uno de estos prompts candidatos se utilizaba para que un segundo LLM «trabajador» intentara resolver los problemas del conjunto de entrenamiento. El sistema evaluaba el rendimiento de cada prompt. Si el LLM trabajador, usando un prompt candidato específico, lograba responder correctamente a muchas de las preguntas, ese prompt recibía una puntuación alta. Si, por el contrario, producía respuestas incorrectas o irrelevantes, su puntuación era baja. Finalmente, el sistema utilizaba la información de estas puntuaciones para guiar la siguiente ronda de generación de prompts. Se quedaba con las ideas de los prompts que habían funcionado bien y las combinaba o refinaba para crear una nueva generación de candidatos, con la esperanza de que fueran aún mejores. Este ciclo de generar, probar y refinar se repetía una y otra vez.
Estos métodos de APO demostraron ser sorprendentemente eficaces. A menudo, lograban descubrir prompts que superaban con creces a los que un humano podría haber escrito, logrando una mayor precisión en la tarea objetivo. Sin embargo, esta victoria en el rendimiento puro ocultaba varios problemas fundamentales que limitaban su utilidad práctica. El primer problema era la complejidad y la falta de interpretabilidad. Los prompts que «evolucionaban» a través de este proceso a menudo se volvían extremadamente largos y extraños. Podían contener frases repetidas, instrucciones redundantes o combinaciones de palabras que no tenían mucho sentido para un observador humano, pero que, por alguna razón estadística, funcionaban bien con el modelo. Se convirtieron en artefactos de ingeniería inversa, no en instrucciones claras. Esto significaba que, aunque se tuviera un prompt de alto rendimiento, no se podía aprender nada de él. Era una caja negra que no ofrecía ninguna idea sobre cómo abordar problemas similares en el futuro.
El segundo problema era el costo. Cada ciclo de este proceso implicaba hacer múltiples llamadas a la API de un potente LLM, tanto para generar los prompts como para probarlos. Multiplicar esto por docenas de candidatos y múltiples iteraciones podía resultar en un gasto computacional y económico prohibitivo, especialmente para organizaciones más pequeñas. Por último, estos prompts eran a menudo frágiles. Al estar tan finamente ajustados a las peculiaridades de un modelo específico y a un conjunto de datos de entrenamiento, a veces no lograban generalizar bien a nuevos problemas o podían dejar de funcionar eficazmente si el modelo de IA subyacente se actualizaba. La comunidad de IA tenía una herramienta que podía fabricar llaves para arrancar el motor, pero las llaves eran esculturas incomprensibles, caras de fabricar y que a veces se rompían. Se necesitaba un enfoque diferente, uno que no solo buscara el rendimiento, sino también la elegancia, la simplicidad y la comprensión.
La destilación: de la complejidad a la esencia pura
El avance presentado en el trabajo sobre la destilación de prompts no es una simple mejora de los métodos existentes, sino un cambio de paradigma en el objetivo de la optimización automática. En lugar de preguntar «¿cuál es el prompt más eficaz que podemos generar, sin importar su forma?», los investigadores se preguntaron: «¿cuál es el prompt más eficaz, conciso e inteligible que podemos descubrir?». La respuesta la encontraron en un proceso de dos etapas, inspirado en la idea de la destilación: el arte de separar las sustancias para obtener la más pura y concentrada.
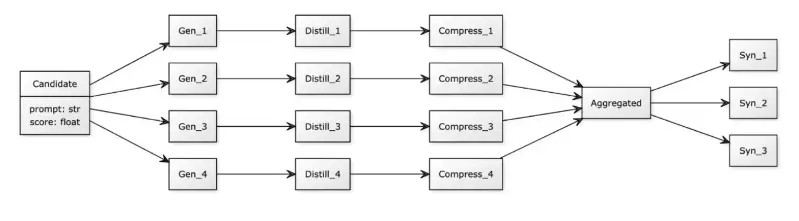
La primera etapa del sistema, bautizado como APO-PD, es la Fase de Optimización. Esta fase es similar en espíritu a los métodos APO anteriores, pero con un énfasis en la diversidad. Partiendo de una instrucción humana simple, como «Traduce este texto», y un conjunto de ejemplos, un primer LLM, el Optimizador, se encarga de explorar el vasto universo de posibles prompts. No solo busca mejorar la instrucción original, sino que genera una amplia gama de candidatos con diferentes estrategias. Algunos prompts pueden ser muy directos, otros pueden incluir cadenas de razonamiento paso a paso, algunos pueden pedir al modelo que adopte un rol específico, como el de un traductor profesional. La idea es crear un ecosistema rico y variado de instrucciones. Cada uno de estos prompts candidatos es luego probado rigurosamente en un conjunto de tareas de validación, y se le asigna una puntuación de rendimiento. Al final de esta fase, no tenemos un único «ganador», sino una colección de los prompts de mayor rendimiento, por ejemplo, los diez o veinte mejores. Estos son los «líquidos fermentados»: complejos, potentes, pero aún no refinados.
Aquí comienza la segunda y más innovadora etapa: la Fase de Destilación. Este es el corazón del método. El sistema toma a este grupo de élite de prompts de alto rendimiento, que pueden ser largos, redundantes y complejos, y se los presenta a un segundo LLM, el Destilador. El Destilador recibe una instrucción muy especial, un «meta-prompt», que define su tarea. Este meta-prompt es una obra de ingeniería en sí mismo y le dice al Destilador algo como: «Eres un ingeniero de prompts de renombre mundial. A continuación se presentan varios prompts que han demostrado ser muy eficaces para una tarea específica. Tu misión es analizar sus estructuras, las instrucciones comunes y las estrategias subyacentes. Basándote en este análisis, tu objetivo es generar un único prompt nuevo. Este nuevo prompt debe capturar la esencia de por qué los otros funcionaron bien, pero debe ser lo más conciso, claro y directo posible. Debe ser una instrucción que un humano pueda entender y utilizar fácilmente».
Esta tarea obliga al Destilador a realizar una forma de razonamiento abstracto. No se limita a mezclar y combinar frases. Debe inferir los principios clave. Por ejemplo, el Destilador podría observar que muchos de los mejores prompts para una tarea de resumen incluyen la instrucción de «identificar primero a la audiencia principal» y «terminar con una conclusión de una sola frase». Aunque estas instrucciones estaban expresadas de diferentes maneras en los distintos prompts, el Destilador identifica este patrón como una estrategia ganadora. Entonces, en lugar de incluir todas las variantes, lo sintetiza en una instrucción clara y concisa dentro del nuevo prompt destilado: «Resume el texto para una audiencia ejecutiva, identificando los puntos clave y concluyendo con un resumen de una sola frase».
El resultado final de este proceso de destilación es un único prompt que es, en muchos sentidos, lo mejor de ambos mundos. Por un lado, encapsula las estrategias complejas y a menudo no intuitivas descubiertas durante la fase de optimización automática, lo que le confiere un alto rendimiento. Por otro lado, ha sido refinado y simplificado a través del proceso de síntesis abstracta, lo que lo hace corto, legible y comprensible para un ser humano. Se ha pasado de la complejidad cruda de la máquina a la elegancia refinada de una instrucción bien elaborada. La caja negra se ha vuelto transparente. El sistema no solo ha encontrado una solución, sino que ha explicado la solución de una manera que los humanos pueden aprender y generalizar.
Resultados que iluminan el camino
La prueba de fuego para cualquier nuevo método de investigación no reside en la elegancia de su teoría, sino en la contundencia de sus resultados. El equipo detrás de la Optimización Automática de Prompts con Destilación de Prompts sometió su sistema a una batería de pruebas en una amplia gama de tareas de razonamiento y procesamiento del lenguaje, y los resultados confirmaron de manera concluyente la superioridad de su enfoque. En términos de rendimiento bruto, es decir, la precisión en la resolución de las tareas, los prompts generados por APO-PD demostraron ser excepcionalmente potentes. En la mayoría de los casos, lograron un rendimiento comparable o incluso superior al de los prompts generados por los métodos de optimización automática más complejos y de última generación. Esto por sí solo ya es un logro significativo, ya que demuestra que el proceso de destilación no sacrifica la eficacia en el altar de la simplicidad.
Pero donde el método APO-PD realmente brilló fue en las métricas cualitativas, que son a menudo más importantes para la aplicación práctica en el mundo real. La primera de ellas es la concisión. Los investigadores compararon la longitud de los prompts destilados con la de los prompts generados por otros métodos de APO. Los resultados fueron espectaculares. Los prompts de APO-PD eran, en promedio, cuatro veces más cortos que los de sus homólogos. En lugar de instrucciones enrevesadas que se extendían por cientos de palabras o tokens, el sistema producía prompts claros y directos, a menudo de menos de cincuenta palabras. Esta brevedad no es solo una cuestión de estética; tiene implicaciones prácticas directas. Los prompts más cortos son más rápidos de procesar por los LLMs y, por lo tanto, más baratos de usar en términos de costos de API.
La segunda y quizás más importante ventaja es la interpretabilidad. Este es el verdadero cambio de juego. Los investigadores presentaron los prompts generados por diferentes sistemas a evaluadores humanos. Los prompts destilados fueron calificados como abrumadoramente más fáciles de entender, modificar y reutilizar. Un ingeniero de software o un desarrollador de productos puede mirar un prompt de APO-PD y comprender de inmediato la estrategia que la IA ha descubierto. Por ejemplo, podría descubrir que para una tarea particular de extracción de datos, la estrategia más eficaz es pedirle al modelo que «piense paso a paso en una cadena de razonamiento antes de dar la respuesta final». Esta es una idea valiosa que el ingeniero puede tomar y aplicar a otros problemas similares. El prompt deja de ser una solución de un solo uso y se convierte en una lección reutilizable, una pieza de conocimiento. Transforma el proceso de optimización de una tarea de fuerza bruta en una oportunidad de aprendizaje para el desarrollador humano.
Para ilustrar este punto, en una de las tareas, un método de APO convencional produjo un prompt largo y repetitivo que incluía frases como «realiza la tarea con la máxima precisión posible, sé fiel a los hechos, no inventes información». El método APO-PD, después de analizar varios prompts exitosos que contenían ideas similares, lo destiló a una instrucción mucho más elegante y potente: «Actúa como un verificador de hechos y extrae solo la información que esté explícitamente respaldada por el texto». Esta instrucción destilada no solo es más corta, sino que es conceptualmente más rica, ya que utiliza el rol de «verificador de hechos» para englobar todas las demás ideas de precisión y fidelidad. En resumen, los resultados demuestran que APO-PD no es una simple mejora incremental. Es un sistema que logra un equilibrio casi perfecto entre el rendimiento de la máquina y la comprensión humana. Produce soluciones que no solo funcionan bien, sino que nos enseñan por qué funcionan bien, abriendo una nueva vía para una colaboración más profunda y efectiva entre los humanos y la inteligencia artificial.
El futuro de la interacción Humano-IA
El desarrollo de la Optimización Automática de Prompts con Destilación de Prompts es más que un simple avance técnico en un subcampo de la inteligencia artificial. Representa una evolución fundamental en la filosofía de cómo interactuamos con las máquinas inteligentes y cómo desarrollamos aplicaciones basadas en ellas. Las implicaciones de esta investigación se extienden mucho más allá de la comunidad de investigación y apuntan hacia un futuro en el que el poder de los Grandes Modelos de Lenguaje sea más democrático, fiable y colaborativo.
En primer lugar, esta tecnología tiene el potencial de reducir drásticamente la barrera de entrada para el desarrollo de aplicaciones de IA. Hasta ahora, la necesidad de contar con ingenieros de prompts altamente especializados era un obstáculo importante para las pequeñas empresas, los investigadores individuales o las organizaciones sin ánimo de lucro que deseaban aprovechar el poder de los LLMs. Con una herramienta como APO-PD, un desarrollador con una comprensión básica de su problema puede proporcionar una instrucción simple y dejar que el sistema descubra automáticamente una forma muy eficaz y, lo que es más importante, comprensible de comunicarse con la IA. Esto democratiza la innovación, permitiendo que más personas y organizaciones construyan soluciones de IA sofisticadas sin necesidad de contar con un «susurrador de IA» en su equipo.
En segundo lugar, este enfoque conduce a la creación de sistemas de IA más robustos y fiables. Los prompts «caja negra» generados por los métodos anteriores eran a menudo frágiles. Al no entender por qué funcionaban, era difícil predecir cuándo podrían fallar o cómo arreglarlos si lo hacían. Los prompts destilados, al ser claros e interpretables, permiten a los desarrolladores entender la lógica subyacente. Esto facilita la depuración de errores, el ajuste fino del comportamiento del sistema y la adaptación del prompt a nuevas situaciones o a versiones actualizadas del modelo de IA. Conduce a un ciclo de desarrollo más transparente y controlado, que es crucial para construir aplicaciones de misión crítica en campos como la medicina, las finanzas o el derecho.
En tercer lugar, y quizás lo más profundo, APO-PD cambia nuestra relación con la IA, de ser meros usuarios a convertirnos en aprendices y colaboradores. Al analizar los prompts destilados que el sistema genera, los humanos podemos obtener nuevas ideas sobre cómo estructurar problemas y cómo comunicarnos de manera más eficaz. La IA no solo resuelve el problema, sino que nos enseña una mejor manera de plantearlo. Esto crea un círculo virtuoso: la IA nos ayuda a convertirnos en mejores ingenieros de prompts, y nosotros, con esa nueva comprensión, podemos guiar a la IA para que resuelva problemas aún más complejos. Es un modelo de co-evolución de la inteligencia humana y la artificial.
Mirando hacia el futuro, podemos imaginar sistemas aún más avanzados basados en este principio de destilación. Las futuras versiones podrían no solo producir un prompt de texto, sino también generar guías de mejores prácticas, explicaciones detalladas de por qué ciertas estrategias funcionan, e incluso advertir sobre posibles sesgos o puntos ciegos en la instrucción. Podríamos ver esta tecnología integrada directamente en las interfaces de desarrollo, proporcionando sugerencias y optimizaciones en tiempo real a medida que un desarrollador escribe un prompt. En esencia, la destilación de prompts es un paso crucial para pasar de una era en la que los humanos se esforzaban por entender el lenguaje de las máquinas a una era en la que las máquinas nos ayudan a perfeccionar el nuestro. Es un puente que nos acerca a una colaboración verdaderamente simbiótica, donde la claridad de la comprensión humana y el poder del cómputo de la máquina se unen para resolver los problemas más desafiantes del mundo.
Fuentes
- Zheng, Y., Wang, X., Wang, Y., & Chen, Y. (2025). Automatic Prompt Optimization with Prompt Distillation. arXiv preprint arXiv:2508.18992.

