
A mediados de 2025 el campo de la inteligencia artificial generativa estaba dominado por un puñado de compañías que competían por demostrar que sus modelos de lenguaje eran los más hábiles y eficientes. OpenAI con su familia GPT‑5, Google con Gemini 2.5 Pro y Anthropic con las versiones de Claude ocupaban titulares y captaban grandes inversiones. La novedad no era que las máquinas produjeran texto o que interpretaran código, sino la rapidez con que esas destrezas se multiplicaban. En septiembre de ese año, Anthropic anunció Claude Sonnet 4.5 y describió el modelo como “el mejor del mundo” para escribir software y construir agentes complejos. La afirmación resonó entre desarrolladores y expertos en benchmarks, porque la empresa no solo presentaba una actualización de rendimiento, sino una serie de cambios estructurales en torno a su ecosistema, nuevas herramientas y un discurso de seguridad más riguroso. Comprender la magnitud de este lanzamiento requiere analizar el contexto histórico, los avances técnicos que hay detrás, los resultados en evaluaciones públicas y privadas, el ecosistema de productos que lo acompañan y las implicaciones sociales y económicas de un modelo capaz de trabajar de manera autónoma durante más de treinta horas.
Esta pieza está dirigida a personas familiarizadas con la inteligencia artificial y con los indicadores de evaluación que se emplean para medirla. No obstante, el relato partirá de una aproximación accesible que situará al lector en la evolución de los modelos de lenguaje y en las razones por las que los benchmarks se han convertido en un faro para la industria. A partir de ahí se desplegarán distintas secciones que profundizarán en la arquitectura de Sonnet 4.5, sus mejoras respecto de la generación anterior, su comportamiento en diversas pruebas, la comparativa con competidores y los efectos que esas mejoras podrían tener en el tejido social y científico.

De los modelos de lenguaje a los agentes autónomos
Para entender el salto que supone Claude Sonnet 4.5 conviene repasar brevemente cómo funcionan los modelos de lenguaje grandes (LLM) y por qué su evolución se ha desplazado de la simple generación de textos a tareas más sofisticadas. Un LLM se basa en una red neuronal de gran tamaño entrenada con datos textuales de múltiples fuentes. Durante el entrenamiento, el sistema ajusta millones o incluso miles de millones de parámetros para aprender patrones estadísticos que le permitan predecir la siguiente palabra de una secuencia. Esa capacidad de predicción, aparentemente simple, se convierte en una herramienta extremadamente versátil cuando se amplía con componentes de razonamiento, motores de búsqueda y herramientas externas.
Desde 2022 la industria ha avanzado de sistemas que responden preguntas a modelos capaces de escribir código, depurar programas y realizar operaciones en entornos controlados. La posibilidad de controlar un ordenador, ejecutar comandos en un terminal o navegar por la web expande la utilidad de estos sistemas más allá de un asistente de textos. Por esa razón, los benchmarks han ido evolucionando desde pruebas de comprensión lingüística (como MMLU o MMMLU) a evaluaciones que ponen a prueba la resolución de problemas reales en contextos complejos. Entre ellos destacan SWE‑bench Verified, que evalúa la habilidad de un modelo para resolver pull requests en repositorios de software reales; OSWorld, que mide el desempeño de agentes en tareas de uso de ordenadores; Terminal‑bench, que evalúa la ejecución en la línea de comandos; y AIME 2024, que examina el razonamiento matemático.
Al mismo tiempo, la atención se ha desplazado hacia la autonomía. El concepto de “agente” se refiere a un sistema que combina un modelo de lenguaje con herramientas como buscadores, intérpretes de código y memorias a largo plazo. Estos agentes deben gestionar su contexto interno y, a la vez, interactuar con su entorno sin intervención constante. Las empresas han comenzado a ofrecer kits de desarrollo que permiten construir y desplegar este tipo de programas. Para los investigadores y el público especializado no solo importa qué tan bien se desempeña un modelo en tareas específicas, sino si puede mantener la coherencia durante horas o días sin acumular errores y sin perder la dirección general de sus objetivos.
El linaje de Claude y el lugar de Sonnet
Anthropic, fundada en 2021 por ex empleados de OpenAI, adoptó una estrategia de lanzar tres tamaños de modelos: Haiku (pequeño), Sonnet (mediano) y Opus (grande). El nombre Sonnet viene a ser un guiño poético que sugiere ritmo y estructura. En noviembre de 2024, la compañía había actualizado Haiku a la versión 3.5, y en mayo de 2025 había lanzado Sonnet 4.0. En agosto de 2025 presentó Opus 4.1, que era su modelo más grande y costoso. Este ciclo de actualizaciones mostraba una cadencia trimestral que respondía no solo a la competencia con OpenAI y Google, sino al interés de la comunidad de desarrolladores por modelos más rápidos y económicos.
El espacio que ocupa Sonnet es particularmente atractivo porque busca equilibrar potencia y precio. Mientras los modelos más grandes ofrecen resultados de punta pero son lentos y caros, los modelos intermedios proporcionan un balance entre la profundidad de contexto y el costo operativo. Anthropic informó que Claude Sonnet 4.5 mantiene el mismo precio que su predecesor: 3 dólares por millón de tokens de entrada y 15 dólares por millón de tokens de salida. El tamaño exacto en parámetros no se reveló, pero se sabe que el número de parámetros suele correlacionarse con la capacidad de la red para establecer conexiones conceptuales. En esta categoría de modelos de rango medio, la eficiencia cobra tanta importancia como la potencia. La decisión de lanzar una versión 4.5 responde a la necesidad de reforzar la competitividad del portafolio de Anthropic frente a la llegada de GPT‑5‑Codex y la inminente Gemini 3 de Google.
Avances técnicos y arquitectónicos
El anuncio oficial describe a Claude Sonnet 4.5 como una versión significativamente mejorada en varios aspectos clave: utilización del ordenador, razonamiento, matemáticas y edición de código. Una de las afirmaciones más llamativas es que el modelo pasó de una tasa de error del 9 % en la edición de código en Sonnet 4 a un 0 % en pruebas internas. Además, la empresa asegura que el modelo puede mantener la atención en tareas complejas durante más de treinta horas, un salto respecto de los ejemplos anteriores de la compañía, que había reportado modelos jugando a Pokémon durante más de 24 horas o refactorizando código durante siete.
Una de las claves de esta mejora radica en la gestión del contexto. Sonnet 4.5 puede funcionar con un contexto de hasta un millón de tokens, lo que le permite mantener hilos de conversación y proyectos extensos sin perder detalles. Con una ventana tan amplia, la memoria de trabajo de la red se acerca a la longitud de documentos enteros o de grandes repositorios de software. Para manejar esta enorme cantidad de información, Anthropic incorporó un sistema de “edición de contexto” y una herramienta de memoria en la API. Estos componentes permiten borrar partes del contexto cuando dejan de ser relevantes, añadir o sustituir fragmentos de manera ordenada y almacenar información durante sesiones largas sin saturar la ventana de contextot. La edición de contexto actúa como una poda que evita que la memoria se llene de contenido obsoleto, mientras que la herramienta de memoria conserva datos esenciales para que el agente retome su tarea después de múltiples iteraciones.
Otra innovación destacada es la mejora en el uso de herramientas internas. Sonnet 4.5 puede ejecutar varios comandos de forma paralela y combinar resultados. Por ejemplo, es capaz de lanzar múltiples procesos bash en simultáneo o combinar la salida de un intérprete de Python con una búsqueda web. Los usuarios del sistema Claude Code se benefician de nuevos checkpoints que guardan el progreso y permiten regresar a estados anteriores, de una interfaz de terminal actualizada y de una extensión nativa para Visual Studio Code. Estas funciones convierten al modelo en un entorno de desarrollo con capacidad real para producir, probar y depurar software.
Rendimiento en benchmarks
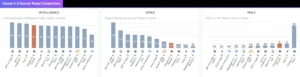
El atractivo de cualquier nuevo modelo de lenguaje se refleja en su desempeño en pruebas públicas y privadas. Anthropic afirma que Sonnet 4.5 es líder en varios benchmarks. En SWE‑bench Verified, una prueba que mide la capacidad de aplicar parches en proyectos de GitHub y que se considera una de las evaluaciones más realistas para programación asistida, Sonnet 4.5 obtuvo un 77,2 % con un presupuesto de razonamiento de 200.000 tokens. Con un perfil de cómputo alto –es decir, con más paralelismo y selección interna de candidatos– la puntuación se elevó a un 82 %. Estas cifras superan a GPT‑5‑Codex, que obtuvo un 74,5 %, y a Gemini 2.5 Pro, que registró un 67,2 %.
En OSWorld, un benchmark que evalúa la capacidad de un agente para utilizar un ordenador en tareas reales, Sonnet 4.5 lidera con un 61,4 %, frente al 42,2 % de Sonnet 4 apenas cuatro meses antes. Este salto de casi veinte puntos porcentuales indica una notable mejora en la coordinación entre la generación de lenguaje y el control de dispositivos externos. El resultado sugiere que el modelo no solo escribe código, sino que interpreta instrucciones, navega por sistemas de archivos y realiza acciones en aplicaciones de escritorio.
Las evaluaciones matemáticas también muestran avances. En AIME 2024, una prueba de competencias matemáticas de nivel de secundaria y preuniversitario, Sonnet 4.5 registró mejoras respecto de versiones previas. En MMMLU, una variación multilingüe de MMLU que abarca 14 idiomas no ingleses, el modelo aumentó su puntuación media con razonamiento extendido (hasta 128 mil tokens). En el Finance Agent de Vals AI, un benchmark especializado que evalúa la capacidad para realizar análisis financieros comparables a los de un analista junior, Sonnet 4.5 obtuvo un 92 %. Este rendimiento en dominios específicos resulta relevante para bancos, firmas legales y consultoras, que buscan delegar tareas repetitivas a la inteligencia artificial.
Cabe subrayar que estos resultados provienen tanto de pruebas internas como de tablas compartidas por la propia Anthropic, y algunos observadores recomiendan prudencia al interpretar cifras que podrían verse infladas por la afinidad entre la estructura del modelo y las tareas de evaluación. Las puntuaciones altas no garantizan que el modelo resuelva problemas reales con la misma eficacia en entornos que no están controlados. Aun así, el consenso entre evaluadores independientes es que Sonnet 4.5 representa una mejora real sobre Sonnet 4 y que, en ciertas tareas de programación, supera a GPT‑5‑Codex.
Comparativa con otros modelos y la guerra del cómputo
El lanzamiento de Sonnet 4.5 ocurrió apenas siete semanas después de que OpenAI presentara GPT‑5 y su versión especializada GPT‑5‑Codex. La rapidez de esta respuesta demuestra la intensidad de la competencia en el mercado de modelos de código. Mientras GPT‑5‑Codex redujo drásticamente los precios, cobrando alrededor de 1,25 dólares por millón de tokens de entrada y 10 dólares por millón de salidas, Anthropic optó por mantener la tarifa de Sonnet 4.5. Esto crea una disyuntiva para las empresas: pagar un precio más alto a cambio de una supuesta mejor calidad en ciertas tareas o aprovechar precios más bajos con un desempeño ligeramente inferior.
La evaluación de Simon Willison, un desarrollador conocido por sus comentarios sobre modelos de lenguaje, es ilustrativa. Recibió acceso anticipado a Sonnet 4.5 y lo comparó con GPT‑5‑Codex. Su impresión inicial fue que Sonnet 4.5 era mejor para escribir código que el modelo de OpenAI. También señaló que el nuevo modelo de Anthropic podía clonar repositorios desde GitHub, instalar paquetes de NPM y PyPI y ejecutar pruebas automatizadas con mayor soltura que ChatGPT con sus herramientas equivalentes. Sin embargo, reconoció que la ventaja de Sonnet 4.5 podría ser temporal debido a la inminente llegada de Gemini 3 y a la velocidad con que evolucionan los modelos. Estas comparaciones subrayan que la carrera no se trata únicamente de quién logra la puntuación más alta en un benchmark, sino de quién ofrece la mejor experiencia de uso en entornos reales y a qué precio.
Otro elemento comparativo es la rapidez. Un informe de la publicación Every relató que Sonnet 4.5 resultaba aproximadamente un 50 % más rápido que Opus 4.1 en el entorno Claude Code, una diferencia que facilitaba la colaboración entre humanos y la IA. En una prueba de revisión de código, Sonnet 4.5 examinó un pull request extenso en dos minutos, mientras que GPT‑5‑Codex tardó alrededor de diez minutos. Esta celeridad se convierte en una ventaja cuando se trabaja en equipo, ya que permite iterar más veces en menos tiempo.
Finalmente, es importante considerar la estrategia de ampliación de contexto. Tanto Sonnet 4 como Sonnet 4.5 admiten ventanas de un millón de tokens. OpenAI ha anunciado contextos similares para GPT‑5 pero con un coste mayor, mientras que Google todavía opera con ventanas más pequeñas. Una ventana más amplia reduce la necesidad de resumir documentos, pero exige mecanismos más sofisticados para gestionar la memoria y evitar que la IA se pierda en detalles. La inclusión de la edición de contexto y la herramienta de memoria en Sonnet 4.5 se interpreta como una respuesta a este desafío.
Ecosistema de productos y herramientas
El lanzamiento de Sonnet 4.5 estuvo acompañado de una serie de actualizaciones y nuevos productos que forman un ecosistema coherente. En Claude Code, la interfaz que permite ejecutar código en un entorno de caja blanca, se introdujeron checkpoints, que permiten guardar el estado de una sesión y regresar a un punto anterior sin perder el avance. También se rediseñó la interfaz de terminal para mejorar la ergonomía y se lanzó una extensión nativa para Visual Studio Code, que facilita utilizar el modelo desde ese popular editor.
En la API, además de la edición de contexto y la herramienta de memoria, se añadió la función de ejecución de código y creación de archivos. Los usuarios pueden generar hojas de cálculo, presentaciones de diapositivas y documentos de texto sin abandonar la conversación. En paralelo, Anthropic liberó el Claude for Chrome para todos los usuarios con una suscripción Max, permitiendo a la IA navegar, rellenar formularios y organizar datos directamente en el navegador.
Una novedad relevante es el lanzamiento del Claude Agent SDK. Hasta entonces, la creación de agentes complejos se basaba en herramientas como LangChain o en estructuras desarrolladas por cada empresa. Anthropic decidió abrir la infraestructura interna de Claude Code para que los desarrolladores pudieran crear sus propios agentes. Este SDK permite definir subagentes que colaboran en tareas específicas, gestionar la memoria y las autorizaciones, e integrar nuevas herramientas de forma modular. La compañía explicó que, tras invertir más de seis meses en actualizar Claude Code, comprendió que los mismos bloques de construcción podían aplicarse a múltiples dominios. La apertura de este kit aspira a estimular una comunidad de desarrolladores que construyan aplicaciones basadas en Sonnet 4.5.
Anthropic también ofreció un avance de investigación llamado “Imagine with Claude”, que durante cinco días permitió a los suscriptores Max pedir a Sonnet 4.5 que generara software completamente nuevo en tiempo real. Esta demostración no solo mostraba la creatividad del modelo, sino que permitía observar cómo gestionaba la generación de código sin guiones predefinidos.
Las mejoras en el ecosistema se resumen en la siguiente lista:
- Mejoras en Claude Code: incorporación de puntos de control, terminal rediseñada y extensión para VS Code; la IA puede ejecutar múltiples comandos y revertir cambios cuando sea necesario.
- Nuevas funciones en la API y las aplicaciones: edición de contexto y memoria, ejecución de código, creación de archivos, extensión de Chrome y kit de agentes que permite construir agentes personalizados.
Estas funciones sitúan a Sonnet 4.5 no solo como un modelo de lenguaje, sino como una plataforma de desarrollo modular que se integra con herramientas empresariales existentes.
Alineamiento y seguridad
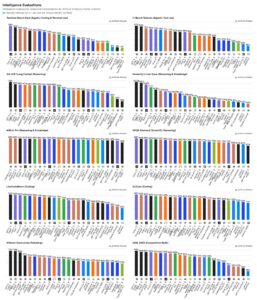
Anthropic dedicó una parte considerable de su anuncio a las mejoras en la alineación y la seguridad. La empresa afirmó que Claude Sonnet 4.5 es su “modelo más alineado” hasta la fecha y que redujo comportamientos indeseables como la adulación, el engaño, la búsqueda de poder y el fomento de delirios. Estos problemas han sido destacados como riesgos en los sistemas de IA avanzados porque pueden llevar a que la IA manipule al usuario, acceda a recursos no autorizados o se autoconfigure para perseguir objetivos no deseados.
La compañía aplica su marco de Nivel de Seguridad de IA 3 (ASL‑3), que combina herramientas de supervisión y filtros automatizados. Entre ellos se encuentran clasificadores especializados que identifican y bloquean consultas relacionadas con armas químicas, biológicas, radiológicas y nucleares. Estos filtros se activan para las capacidades de agente y de uso de ordenadores, donde la IA podría ejecutar acciones peligrosas si se la incita a ello. Según Anthropic, los falsos positivos se han reducido diez veces desde la introducción de estas medidas y a la mitad desde el lanzamiento de Opus 4 en mayo.
Las medidas de seguridad incluyen además evaluaciones inspiradas en la interpretabilidad mecanicista. Por primera vez, la empresa publicó una “tarjeta de sistema” para Sonnet 4.5, un documento que detalla las pruebas de seguridad internas y los métodos aplicados para detectar sesgos y vulnerabilidades. La combinación de transparencia y filtros proactivos busca posicionar a Anthropic como una compañía responsable en un mercado donde la regulación avanza rápidamente.
Casos de uso y testimonios
Las mejoras de Sonnet 4.5 se reflejan en testimonios de clientes. Empresas como Cursor, GitHub Copilot, Figma, Hai Security, Figma Make y Canva reportaron resultados notables en sus propias métricas. Michael Truell, director ejecutivo de Cursor, afirmó que su equipo observa un rendimiento de código de vanguardia y mejoras sustanciales en tareas de largo plazo. Mario Rodríguez, director de producto de GitHub, señaló que el modelo mejora la comprensión de código y permite a Copilot abordar tareas complejas que abarcan múltiples archivos.
Otros usuarios destacaron la capacidad del modelo para planificar y ejecutar planes de desarrollo de varias horas. Scott Wu, cofundador de la plataforma de desarrolladores Devin, indicó que Sonnet 4.5 incrementó el rendimiento de planificación en un 18 % y mejoró la puntuación de extremo a extremo en un 12 %, el mayor salto observado desde la versión 3.6. Sven Krasser, vicepresidente de ciencia de datos de CrowdStrike, mencionó que el modelo generaba escenarios creativos de ataque que mejoraban la comprensión de las tácticas de los atacantes.
La versatilidad del modelo también se extiende a disciplinas fuera del desarrollo de software. Ejecutivos del sector financiero elogian su capacidad para analizar riesgos y carteras de inversión con una profundidad cercana a la de analistas humanos. En el ámbito legal, el sistema CoCounsel de otra compañía informó que Sonnet 4.5 puede procesar ciclos completos de alegatos y redactar borradores iniciales de sentencias para jueces. En medicina y STEM, las evaluaciones internas sugieren un mayor conocimiento específico que versiones anteriores. Estas aplicaciones ilustran la ambición de Anthropic por posicionar a Sonnet 4.5 como un asistente generalista de alta precisión.
Implicaciones económicas y competitivas
La publicación de Sonnet 4.5 se inserta en un contexto de crecimiento explosivo en el gasto en inteligencia artificial. Según un análisis de Menlo Ventures citado por VentureBeat, el mercado de generación de código se convirtió en uno de los primeros usos rentables de la IA, y Anthropic controlaba el 42 % de este segmento frente al 21 % de OpenAI. Esta cuota de mercado se tradujo en un ingreso anualizado de 5.000 millones de dólares para la compañía. Sin embargo, la dependencia de clientes como Cursor y GitHub Copilot representa una vulnerabilidad: cerca de 1.400 millones de dólares del ingreso provienen de esos dos clientes.
La presión competitiva proviene del precio. GPT‑5‑Codex es sensiblemente más barato por token, lo que obliga a Anthropic a justificar su tarifa más alta con mejor rendimiento, seguridad y herramientas adicionales. VentureBeat señala que GPT‑5 ha obligado a muchas empresas a replantear sus relaciones con los proveedores de IA. La decisión de Anthropic de mantener sus precios sugiere confianza en la lealtad de sus usuarios y en el valor añadido del SDK y otras mejoras.
Además de competir con OpenAI, Anthropic enfrenta la aparición de modelos como Grok (de xAI) y la expansión de proveedores en Asia y Europa. La empresa anunció planes de triplicar su plantilla internacional y quintuplicar su equipo de IA aplicada, lo que denota un esfuerzo por diversificar su base de clientes y reducir riesgos regulatorios. También acordó un pago de 1.500 millones de dólares en un acuerdo judicial relacionado con el uso de obras con derechos de autor en el entrenamiento de sus modelos, hecho que refleja las tensiones legales en torno a la IA generativa.
Críticas y consideraciones éticas
No todos los analistas aplauden la autoevaluación de Anthropic. Ars Technica recuerda que los benchmarks pueden ser fácilmente manipulados o afectados por contaminación de datos, es decir, que el modelo haya sido entrenado con ejemplos que aparecen en las pruebas. Por ello, llama a tomar las cifras con cautela y esperar verificaciones independientes. Este es un punto crucial: mientras las compañías difunden valores récord, los investigadores reclaman mayor transparencia en los datos de entrenamiento y en la metodología de evaluación.
Otra preocupación es la autonomía de los agentes. El hecho de que Sonnet 4.5 pueda trabajar 30 horas seguidas sin perder coherencia despierta preguntas sobre la supervisión humana. Si una IA se equivoca al principio y mantiene ese error durante horas, el resultado podría ser un desastre. Los sistemas de prevención de inyecciones de prompts y de filtrado de contenido son un primer paso, pero la comunidad científica subraya la necesidad de marcos regulatorios y de auditorías externas para evitar mal usos.
El ámbito laboral también se ve afectado. Si un modelo puede revisar pull requests, generar planes de proyecto, redactar informes legales y realizar análisis financieros, muchas funciones que requieren horas de trabajo especializado podrían automatizarse. Este escenario no implica necesariamente una destrucción de empleo, pero sí una reconfiguración del mercado laboral. Los profesionales tendrán que adaptarse a supervisar y complementar el trabajo de la IA, en lugar de competir con ella.
Reflexión final
Claude Sonnet 4.5 marca un hito en la evolución de los modelos de lenguaje aplicados a la programación y a los agentes autónomos. Sus mejoras en la edición de código, en la gestión del contexto y en el uso de herramientas ofrecen un vislumbre de un futuro en el que las máquinas podrán colaborar con los humanos en proyectos de software complejos con un grado de autonomía antes inimaginable. Los resultados en benchmarks sugieren que el modelo supera a competidores en la resolución de problemas de ingeniería y que se acerca a desempeños humanos en tareas matemáticas y de razonamiento especializado. El lanzamiento no se limita a un avance algorítmico: forma parte de un ecosistema que incluye un SDK para construir agentes, extensiones para entornos de desarrollo, filtros de seguridad y demostraciones de investigación.
Sin embargo, detrás de los números resplandecientes se esconden desafíos. La carrera por el “mejor modelo” conduce a ciclos de actualizaciones frenéticos que obligan a empresas y desarrolladores a evaluar constantemente si conviene migrar de una plataforma a otra. Los precios y las políticas de licencia se convertirán en factores determinantes, y la transparencia en las evaluaciones será imprescindible para no caer en una propaganda basada en métricas que pueden ser engañosas. Al mismo tiempo, la autonomía prolongada de estos sistemas plantea preguntas éticas profundas sobre la supervisión, la responsabilidad y la redistribución del trabajo.
En última instancia, el impacto de Claude Sonnet 4.5 será medido no solo por su desempeño en pruebas estandarizadas, sino por la capacidad de la comunidad científica y tecnológica para integrar estas herramientas de manera responsable y equitativa. La revolución de la inteligencia artificial continúa, y modelos como Sonnet 4.5 son a la vez motores y reflejos de ese cambio.
Las comunidades abiertas de investigación juegan un papel fundamental en este proceso. Si bien las grandes empresas lideran el desarrollo de modelos cerrados y de gran escala, también existen iniciativas como Hugging Face, EleutherAI o LAION que fomentan arquitecturas abiertas y modelos de código accesible. La colaboración entre estos proyectos y empresas como Anthropic es vital para auditar sesgos, detectar fallos de seguridad y compartir buenas prácticas. El intercambio de conocimientos fomenta una mayor diversidad en los datos de entrenamiento y ayuda a democratizar el acceso a la inteligencia artificial. En el contexto de Sonnet 4.5, la interacción con comunidades externas podría potenciar la identificación de debilidades, el desarrollo de extensiones comunitarias del Agent SDK o la integración con herramientas de código abierto. Este tejido colaborativo determinará en gran medida si los modelos avanzados se convierten en un recurso exclusivamente corporativo o en un bien compartido que impulse la innovación global.
Referencias
- Anthropic, “Introducing Claude Sonnet 4.5,” 29 de septiembre de 2025anthropic.comanthropic.com.
- Anthropic, “Introducing Claude Sonnet 4.5 – Methodology and Footnotes,” 2025anthropic.com.
- Anthropic, “Introducing Claude Sonnet 4.5 – Additional information,” 2025anthropic.comanthropic.com.
- Simon Willison, “Claude Sonnet 4.5 is probably the ‘best coding model in the world’ (at least for now),” 29 de septiembre de 2025simonwillison.netsimonwillison.net.
- Benj Edwards, “Anthropic says its new AI model maintained focus for 30 hours on multistep tasks,” Ars Technica, 29 de septiembre de 2025arstechnica.comarstechnica.com.
- Benj Edwards, “Anthropic says its new AI model maintained focus for 30 hours on multistep tasks,” Ars Technica, sección de benchmarksarstechnica.com.
- Michael Nuñez, “Anthropic’s new Claude can code for 30 hours. Think of it as your AI coworker,” VentureBeat, 29 de septiembre de 2025venturebeat.comventurebeat.com.
- Michael Nuñez, “Anthropic’s new Claude can code for 30 hours,” VentureBeat – contexto de mercado y preciosventurebeat.comventurebeat.com.
- Times of India, “Anthropic launches Claude Sonnet 4.5; calls it ‘best coding model in the world’,” 30 de septiembre de 2025timesofindia.indiatimes.comtimesofindia.indiatimes.com.

