
La inteligencia artificial está transitando de un paradigma puramente reactivo hacia uno proactivo y autónomo, donde los sistemas no solo responden a las solicitudes del usuario, sino que también interpretan objetivos complejos y los traducen en acciones secuenciales para alcanzarlos.
Este salto cualitativo es liderado por los agentes de IA, sistemas sofisticados que combinan el poder de los modelos de lenguaje grande (LLM), el procesamiento del lenguaje natural (NLP), el aprendizaje automático (ML) y la visión por computadora para percibir su entorno, razonar sobre él, planificar una estrategia y actuar con el fin de lograr metas preestablecidas.
A diferencia de los sistemas de automatización tradicionales basados en reglas estrictas, los agentes de IA son capaces de manejar flujos de trabajo dinámicos y contextos complejos sin intervención humana constante.
Su capacidad para aprender de forma continua a través de mecanismos como el aprendizaje por refuerzo les permite mejorar sus decisiones con el tiempo, acumulando recompensas por resultados exitosos. Ejemplos cotidianos de esta tecnología abarcan desde asistentes virtuales como Siri o Alexa hasta vehículos autónomos como los de Tesla, pasando por sistemas empresariales avanzados como Copilot en Microsoft Dynamics 365 Business Central, que puede interpretar datos para agilizar la creación de pedidos de venta.
El corazón de cualquier agente autónomo reside en su arquitectura, que define cómo se estructuran sus componentes fundamentales. Estos sistemas pueden clasificarse según diferentes criterios.
Por un lado, existen agentes basados en reflejos, que responden a estímulos mediante reglas predefinidas; agentes basados en modelos, que mantienen un modelo interno del mundo para anticipar los resultados de sus acciones; agentes basados en objetivos, que planean acciones para alcanzar metas específicas; y agentes basados en utilidad, que buscan maximizar una medida de «deseabilidad» o beneficio, como en el comercio financiero.
Además, se pueden categorizar por su nivel de autonomía, desde reactivos hasta deliberativos (de planificación) e híbridos que combinan ambas capacidades. En términos de aplicación, los agentes se despliegan en diversos dominios: desde robots de servicio y quirúrgicos, hasta asistentes financieros como PortfolioPilot, que gestiona activos por valor de 20 mil millones de dólares, y sistemas de optimización de rutas como Pidge. Plataformas como Astera AI Agent Builder o Botpress están democratizando el acceso a estas tecnologías, permitiendo a organizaciones crear soluciones personalizadas sin necesidad de una profunda experiencia técnica.
A pesar de su potencial transformador, la implementación de estos agentes enfrenta obstáculos significativos. El mercado global de agentes de IA, aunque prometedor —con una previsión de Gartner de alcanzar los 47.100 millones de dólares para 2030—, presenta desafíos operativos y estratégicos importantes.
Forrester pronostica que tres de cada cuatro empresas que intenten construir sus propias arquitecturas de agentes autónomos por su cuenta podrían fracasar. Entre los principales escollos se encuentran la gobernanza y calidad de los datos, la escasez de perfiles profesionales con la doble competencia en IA y dominio de negocio, y un elevado consumo energético. Otro factor crítico es la necesidad de supervisión humana y gobernanza ética, asegurando que los agentes operen dentro de marcos legales como el GDPR y CCPA, evitando sesgos y garantizando la privacidad.
La integración con sistemas existentes, como ERP o CRM, mediante APIs, es otro punto clave para una implementación exitosa. La transición hacia una adopción generalizada requiere no solo avances técnicos, sino también la construcción de marcos organizacionales sólidos, la formación de talento especializado y la establecimiento de políticas de control y responsabilidad.
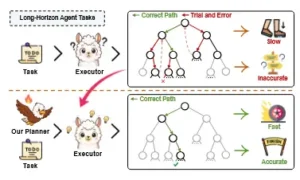
Planificación tradicional de agentes vs. planificación de agentes con nuestro planificador EAGLET. De esta forma, los agentes ejecutores pueden completar mejor las tareas con menos interacciones.
El motor de la acción autónoma: la planificación en agentes de IA
Si el objetivo es el destino, la planificación es el itinerario que guía al viajero. En el mundo de los agentes de IA, la planificación emerge como el componente central que actúa como puente indispensable entre el razonamiento abstracto y la ejecución tangible.
Se trata de la capacidad de un agente para definir un objetivo, generar una secuencia ordenada de acciones para alcanzarlo y, finalmente, ejecutar dicha secuencia mientras reflexiona sobre su progreso y se adapta a imprevistos. Esta función es fundamental para transformar a los modelos de lenguaje grande, que son excelentes para entender y generar texto, en colaboradores autónomos capaces de resolver problemas complejos.
Un agente autónomo, por definición, recibe una meta y debe decidir por sí mismo las acciones necesarias para cumplirla, sin una guía paso a paso constante del usuario. La planificación le proporciona el método para hacerlo, descomponiendo tareas gigantescas en pasos atómicos manejables, estableciendo dependencias entre ellos y mapeando cada paso a una herramienta o API específica disponible en su repertorio.
Los agentes de IA emplean diversos patrones o arquitecturas para llevar a cabo este proceso de planificación. Uno de los más conocidos es ReAct (Razonar-Actuar iterativamente), donde el agente realiza una pequeña acción, reflexiona sobre el resultado, y luego decide la siguiente acción basándose en esa nueva información.
Otra aproximación es el ciclo Plan-then-Execute, en el que el agente genera un plan completo y detallado antes de comenzar a ejecutar ninguna acción, lo que puede ser más eficiente pero menos flexible ante cambios inesperados. Un tercer patrón es el bucle de auto-crítica, donde el agente evalúa su propio plan antes de ejecutarlo, buscando posibles fallos o áreas de mejora. La elección del patrón adecuado depende de la naturaleza de la tarea y del equilibrio deseado entre la planificación exhaustiva y la adaptabilidad en tiempo real.
La arquitectura de un agente autónomo moderno suele incluir componentes adicionales que complementan la planificación, como memoria integrada para almacenar información a corto y largo plazo, una selección estratégica de herramientas o APIs que puede invocar para interactuar con el mundo, y salvaguardas como límites de costo y tiempo para evitar comportamientos indeseados.
La importancia de la planificación se extiende a la evaluación de la efectividad de los agentes. Para medir con precisión si un agente está actuando de manera inteligente, es necesario evaluar no solo si alcanza el objetivo final, sino también la calidad del camino tomado. Las métricas utilizadas para este propósito son variadas y reflejan diferentes aspectos del rendimiento del planificador.
Entre ellas destacan la tasa de éxito, que mide el porcentaje de veces que el agente logra completar su misión; el número promedio de re-planificaciones, que indica la flexibilidad y robustez del agente frente a imprevistos; el coste total asociado a la ejecución (ya sea en tiempo, recursos computacionales o monetarios); y la latencia, que es el tiempo que tarda en llegar a una solución.
Por ejemplo, un agente podría llegar a la meta, pero si lo hace invocando innecesariamente miles de veces una API costosa o tardando horas, su eficiencia sería baja. Por lo tanto, un planificador eficaz no busca únicamente el éxito, sino el éxito óptimo, utilizando el menor recurso posible. Este enfoque multifactorial es crucial para comparar diferentes algoritmos de planificación y para guiar el entrenamiento y la mejora continua de los agentes autónomos.
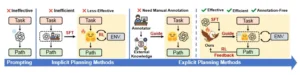
EAGLET frente a métodos anteriores: presentamos un planificador global listo para usar, eficiente y eficaz que proporciona una guía explícita para mitigar las alucinaciones de planificación sin intervención humana.
Los múltiples niveles de la razón: paradigmas de planificación en agentes de IA
La planificación en agentes de IA ha evolucionado más allá de simples secuencias lineales de pasos, adoptando arquitecturas sofisticadas inspiradas tanto en la informática clásica como en los hallazgos de la psicología cognitiva. Dos de los enfoques más prominentes y poderosos son la planificación basada en LLMs y la planificación basada en redes jerárquicas de tareas (HTN), que representan dos caras de una misma moneda: la manipulación del lenguaje natural para la comprensión y la descomposición estructurada de problemas para la gestión.
La planificación basada en LLMs opera directamente en el dominio del lenguaje natural, lo que la hace extremadamente práctica para agentes modernos. Permite a los agentes descomponer metas abstractas o ambiguas en subtareas más concretas, inferir restricciones implícitas del entorno y generar instrucciones interactivas para el usuario cuando sea necesario.
Por otro lado, la planificación HTN organiza el razonamiento en una estructura jerárquica, donde una tarea compleja se descompone recursivamente en sub-tareas más simples hasta llegar a primitivas que el agente puede ejecutar directamente. Esta aproximación modular facilita la organización del conocimiento y la reutilización de planes, especialmente en dominios bien estructurados.
Para gestionar la complejidad inherente a tareas largas y ambiciosas, los investigadores han desarrollado paradigmas aún más sofisticados, como la planificación cognitiva multinivel (MCP). Inspirada en la manera en que los humanos pensamos y resolvemos problemas, la MCP organiza el razonamiento en múltiples niveles de abstracción. Este enfoque divide la cognición en al menos tres niveles distintos: estratégico, táctico y operativo.
En el nivel estratégico, el agente se enfoca en las metas abstractas y de alto nivel, como «entregar medicinas a tiempo en un hospital». En el nivel táctico, estas metas se traducen en subtareas más específicas y estructuradas, a menudo utilizando formalismos como PDDL (Planning Domain Definition Language) para describir estados y acciones. Finalmente, en el nivel operativo, se generan los comandos físicos o digitales concretos, como «moverse hacia el punto A», «abrir la puerta B» o «girar la rueda C».
Este diseño modular permite una mayor trazabilidad, ya que cada decisión se puede atribuir a un nivel específico del proceso de pensamiento, y aumenta la robustez del sistema, ya que la recuperación de errores puede ser más localizada y eficiente. Casos de estudio reales, como los proyectos de colaboración entre NVIDIA y NTU con ThinkAct (2025) o el Toyota Research Institute (TRI, 2024), demuestran la viabilidad de estas arquitecturas en entornos del mundo real.
La integración de los LLMs con estos paradigmas estructurados es un área de investigación activa y vital. Los LLMs aportan una capacidad excepcional para comprender el lenguaje humano y navegar en problemas mal definidos, mientras que los planificadores simbólicos ofrecen la estructura necesaria para la planificación de largo alcance. Un agente que combina ambos mundos podría usar un LLM en su nivel estratégico para interpretar una solicitud vaga como «necesito organizar una conferencia» y generar un plan de alto nivel.
Luego, un planificador simbólico en el nivel táctico tomaría ese plan y lo desglosaría en una serie de sub-tareas bien definidas («reservar sala», «enviar invitaciones», «gestionar registro»). Finalmente, en el nivel operativo, el agente podría invocar herramientas específicas (APIs de servicios de reserva, plataformas de correo electrónico) para ejecutar cada una de esas sub-tareas. Frameworks como CrewAI, LangChain Agents y AutoGen están diseñados para facilitar la implementación de estas estrategias híbridas, permitiendo a los desarrolladores construir sistemas que aprovechan las fortalezas de cada enfoque. Esta convergencia representa el futuro de los agentes autónomos: sistemas que no solo son inteligentes en el procesamiento del lenguaje, sino también estructurados y eficientes en la toma de decisiones secuenciales.
Limitaciones de los enfoques tradicionales en tareas de largo horizonte
Aunque los agentes de IA han demostrado un gran progreso, enfrentan una brecha fundamental al abordar tareas de largo horizonte: la dificultad para realizar una planificación global coherente y eficiente. Una tarea de largo horizonte es aquella que exige una secuencia prolongada y compleja de acciones para alcanzar un objetivo distante, superando la capacidad de los agentes para mantener una perspectiva holística.
La mayoría de los agentes autónomos existentes operan de manera más bien reactiva o parcialmente planificada, careciendo de un «plan global» que les permita visualizar todo el camino desde el inicio. Esto se traduce en una tendencia a la improvisación, a tomar decisiones locales óptimas sin considerar sus consecuencias a largo plazo, lo que puede llevar a soluciones subóptimas o incluso al fracaso. Por ejemplo, un agente que intenta escribir un artículo de investigación podría empezar a redactar las conclusiones antes de haber realizado la recolección de datos o la revisión bibliográfica, un error de planificación que un plan global prevendría.
Esta limitación se manifiesta en las diferencias conceptuales y funcionales entre los planificadores globales y locales, un concepto heredado de la robótica. Un planificador global, como A* o RRT*, opera con un mapa precomputado del entorno para generar una ruta completa y optimizada desde un punto de partida hasta un objetivo final.
Es ideal para navegación, ya que proporciona una trayectoria que minimiza factores como la distancia o el riesgo. Sin embargo, su principal debilidad es la falta de flexibilidad: si el entorno cambia (por ejemplo, aparece un nuevo obstáculo), el plan global queda obsoleto y debe ser recalculado por completo, lo que puede ser ineficiente en tiempo real. En contraste, un planificador local, como DWA (Dynamic Window Approach), utiliza la percepción inmediata del robot para tomar decisiones sobre movimientos a corto plazo, conectando de forma segura los puntos de un plan global.
Si bien es altamente adaptable, su enfoque a corto plazo significa que puede quedar atrapado en óptimos locales, donde no ve una salida mejor porque no tiene una visión del panorama completo.
Esta dicotomía entre planificación global y local es paradigmática del problema que enfrentan los agentes de IA. La mayoría de los agentes basados en LLMs actúan de forma análoga a los planificadores locales: generan una acción siguiendo la secuencia actual de tokens y el contexto inmediato, sin un mapa mental del problema más allá de unos pocos pasos.
Algoritmos clásicos de planificación simbólica como STRIPS o GraphPlan, aunque poderosos en entornos bien definidos, son poco prácticos para agentes modernos debido a su dependencia de estructuras de datos formales y numéricas que no se adaptan bien al lenguaje natural.
Incluso FF planning, considerado moderadamente práctico, requiere adaptaciones significativas. La consecuencia de esta brecha es que los agentes autónomos actuales, a pesar de su sofisticación, a menudo se sienten «ciegos» a largo plazo. No pueden ponderar el costo temporal o de recursos de una decisión que parece beneficiarlos ahora pero podría bloquearles el camino en el futuro. Esta incapacidad para la planificación global es el cuello de botella que impide un salto cualitativo en la autonomía y la eficacia de los agentes, limitando su aplicación a problemas más pequeños y bien definidos.
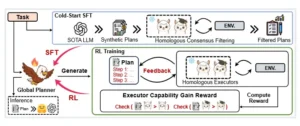
El proceso general de EAGLET, que incluye (1) SFT de inicio en frío: Sintetizamos planes globales de alta calidad mediante el método de filtrado por consenso homólogo para la etapa de SFT. (2) Entrenamiento de aprendizaje automático (RL): Refinamos aún más el planificador mediante un enfoque de aprendizaje automático basado en reglas con la recompensa de ganancia de capacidad del ejecutor diseñada.
Metodologías avanzadas para el entrenamiento del planificador global
Superar la limitación de la planificación a corto plazo requiere enseñar explícitamente a los agentes de IA a pensar de manera global. El paper A Goal Without a Plan Is Just a Wish aborda esta necesidad presentando metodologías innovadoras para entrenar un planificador global, un componente que permite al agente generar y evaluar planes completos desde el principio.
El núcleo de este enfoque radica en la idea de separar la planificación de la ejecución y entrenar el planificador en un entorno de simulación o «sandbox». Este entorno de prueba actúa como un laboratorio seguro donde el agente puede practicar la creación de miles de planes, recibir retroalimentación instantánea sobre su calidad y aprender a distinguir entre buenos y malos caminos sin las consecuencias del mundo real. Esta separación es crucial: el planificador aprende a ser un estratega visionario, mientras que un ejecutor dedicado se encarga de llevar a cabo las acciones en el entorno principal.
Una de las estrategias centrales descritas en el paper es el uso de un ciclo de entrenamiento iterativo que combina la generación de planes con una evaluación rigurosa. En cada iteración, el agente recibe un objetivo y utiliza su planificador para generar una secuencia de acciones hipotéticas. En lugar de ejecutar estas acciones, el sistema de entrenamiento las simula y calcula una «puntuación de plan» basada en criterios predefinidos. Estos criterios pueden incluir la probabilidad de éxito, la eficiencia (tiempo y recursos consumidos), la seguridad y la elegancia del plan.
El planificador aprende a maximizar esta puntuación, internalizando así una noción de «buen plan». Este proceso se asemeja a cómo un jugador de ajedrez evalúa mentalmente varias jugadas antes de mover una pieza, ponderando las consecuencias futuras. Al repetir este ciclo millones de veces, el planificador desarrolla un profundo «instinto» para la planificación de largo alcance. El papel del ejecutor se simplifica en este modelo, ya que su única responsabilidad es seguir fielmente un plan generado por el planificador entrenado, liberando al sistema de la complejidad de tener que planificar y ejecutar simultáneamente.
Otra contribución clave del paper es la introducción de un planificador de alta calidad, como un experto humano o un algoritmo de planificación simbólica potente, como una fuente de «etiquetas de oro» para guiar el entrenamiento. En lugar de dejar que el planificador del agente aprenda desde cero, se le proporcionan ejemplos de planes perfectos o muy buenos para una variedad de tareas. Esto acelera drásticamente el proceso de aprendizaje, ya que el agente no tiene que reinventar la rueda cada vez.
Este enfoque de aprendizaje por imitación (imitation learning) o aprendizaje por refuerzo inverso (inverse reinforcement learning) permite transferir el conocimiento experto a la máquina. Además, el paper explora técnicas de aprendizaje por refuerzo para afinar aún más el planificador, incentivándolo a explorar nuevas estrategias y superar a los planes de referencia. El resultado es un sistema dual: un planificador entrenado que genera planes de alta calidad y un ejecutor que los lleva a cabo con eficacia. Este enfoque modular y sistemático no solo mejora la capacidad de los agentes para tareas de largo horizonte, sino que también abre la puerta a la creación de agentes más robustos, interpretables y fáciles de depurar, pues el proceso de planificación se convierte en un modelo de aprendizaje explícito.
| Característica | Enfoque Clásico de Planificación (Basado en LLMs) | Nuevo Enfoque de Planificador Global (Según el Paper) |
|---|---|---|
| Visión | Cortoplacista (acciones locales) | Holística (planificación de largo alcance) |
| Entorno de Entrenamiento | Entorno de ejecución real | Sandbox o entorno de simulación |
| Feedback | Retrasado (después de ejecutar la acción) | Inmediato (evaluación del plan completo) |
| Separación de Roles | Planificación y ejecución fusionadas | Separación clara entre planificador y ejecutor |
| Fuente de Conocimiento | Aprendizaje por refuerzo durante la ejecución | Uso de planes de expertos («etiquetas de oro») |
| Flexibilidad vs. Eficiencia | Alta flexibilidad, baja eficiencia global | Mayor eficiencia global, menor flexibilidad en cada paso |
Implicaciones transformadoras
El desarrollo de agentes de IA con planificación global no es meramente un avance técnico incremental; representa un cambio de paradigma con implicaciones profundas y transformadoras para la tecnología, la sociedad y la economía. La capacidad de un agente para concebir, evaluar y ejecutar un plan de largo alcance lo eleva de la categoría de una simple herramienta de automatización a la de un colaborador estratégico.
La relevancia de este trabajo va mucho más allá de la academia, impactando directamente en la viabilidad y el alcance de las aplicaciones prácticas de la IA autónoma. El mercado global de agentes de IA, impulsado por esta tecnología, se espera que crezca a una tasa compuesta anual del 44,8% entre 2024 y 2030, alcanzando un valor estimado de 47.1 mil millones de dólares para 2030. Este crecimiento será impulsado por la capacidad de los agentes para abordar problemas de mayor complejidad y valor.
En el ámbito empresarial, la planificación avanzada permitirá una automatización mucho más profunda. Las empresas podrán delegar tareas complejas y semi-estructuradas que hoy requieren una intervención humana significativa. Por ejemplo, un agente con planificación global podría gestionar completamente el ciclo de vida de una campaña de marketing digital, desde la investigación de mercado y la segmentación de audiencias hasta la creación de contenido, la publicación en múltiples canales y el análisis de resultados.
Gartner prevé que para 2028, los agentes de IA automatizarán hasta el 15% de las decisiones diarias en el trabajo. Esto no solo aumentará la productividad, sino que también liberará a los empleados de tareas repetitivas, permitiéndoles centrarse en actividades de mayor valor añadido como la creatividad, la estrategia y la empatía. Ya existen casos de estudio impresionantes, como Delivers.ai, que utilizó vehículos autónomos para completar 4000 entregas exitosas en un solo año, o PortfolioPilot, un asesor financiero autónomo que gestiona activos por valor de 20 mil millones de dólares.
Desde una perspectiva científica y metodológica, este enfoque marca un hito. Superar la brecha de la planificación global es un problema fundamental en la IA que ha resistido durante décadas. La solución propuesta (separar la planificación de la ejecución, entrenar en un sandbox y utilizar planes de expertos) ofrece un camino claro y replicable para otros investigadores. Abre la puerta a la creación de agentes multidominio, capaces de razonar sobre problemas complejos que involucran múltiples disciplinas, y a la colaboración entre múltiples agentes de IA para resolver problemas aún mayores.
Además, al hacer que los agentes sean más modulares y transparentes (pues el planificador se convierte en un modelo explícito), se facilita su depuración, verificación y validación, abordando una de las mayores preocupaciones sobre la confianza en la IA.
En última instancia, al equipar a las máquinas con la habilidad de la planificación, nos acercamos a un futuro en el que la tecnología no solo nos obedecerá, sino que también podrá ayudarnos a alcanzar nuestras metas más ambiciosas de manera más inteligente, rápida y eficiente.
Referencias
Anthropic. (2025). Claude 3.7 sonnet system card.
DeepSeek-AI et al. (2025). Deepseek-v3 technical report. Preprint, arXiv:2412.19437.
Feng, L., Xue, Z., Liu, T., & An, B. (2025). Group-in-group policy optimization for llm agent training. Preprint, arXiv:2505.10978.
Grattafiori, A. et al. (2024). The llama 3 herd of models. Preprint, arXiv:2407.21783.
Huang, X. et al. (2024). Understanding the planning of llm agents: A survey. Preprint, arXiv:2402.02716.
OpenAI. (2023). GPT-4 technical report. arXiv preprint arXiv:2303.08774.
OpenAI. (2025). GPT-5 technical report.
Shao, Z. et al. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models. Preprint, arXiv:2402.03300.
Si, S. et al. (2025). A Goal Without a Plan Is Just a Wish: Efficient and Effective Global Planner Training for Long-Horizon Agent Tasks. arXiv preprint arXiv:2510.05608.
Wang, L. et al. (2024). A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6).
Xiong, W. et al. (2025). MPO: Boosting llm agents with meta plan optimization. Preprint, arXiv:2503.02682.

