
Por Benjamín Vidal, Periodista Especializado en Inteligencia Artificial y Ciencia y Datos, para Mundo IA
El agente que prueba agentes: cómo ATA convierte el QA de IA en un proceso medible
Un estudio propone Agent-Testing Agent, un meta-agente que audita agentes conversacionales con código, búsqueda y tests adversariales que se adaptan solos. Promete más cobertura que rondas humanas y reportes accionables en media hora. La pregunta es si este enfoque puede estandarizar el QA de agentes sin perder los matices que detectan las personas.
Primera mirada
ATA (Agent-Testing Agent) es, en una frase, un agente que prueba agentes. Sirve para revisar, con método y en poco tiempo, si un agente conversacional que usa herramientas (buscar, llamar APIs, escribir código, reservar, etc.) hace bien su trabajo cuando la conversación se complica. En vez de depender solo de planillas con casos de prueba escritos a mano o de rondas largas con anotadores humanos, ATA automatiza gran parte del control de calidad: lee cómo está construido tu agente, imagina por dónde puede fallar y genera diálogos “difíciles” para comprobarlo. Al final entrega un informe con puntajes, ejemplos y recomendaciones concretas.
¿Por qué existe? Porque evaluar agentes reales es más difícil que medir un modelo que solo completa texto. Los agentes combinan memoria, reglas, herramientas y varios pasos de decisión; los problemas aparecen en la interacción: pedidos ambiguos, restricciones que chocan entre sí, precios que cambian, entradas mal formateadas, o usuarios que cambian de objetivo a la mitad. Los benchmarks fijos se quedan cortos para cubrir tanta variación y las evaluaciones humanas tardan días. ATA intenta cubrir ese hueco con un proceso que se puede correr cada vez que hay un cambio.
¿Cómo lo hace? Primero “se empapa” del sistema bajo prueba. Revisa la estructura estática del agente (código, nodos, transiciones, llamadas a herramientas, manejo de errores), hace un cuestionario breve al creador para entender objetivos y límites, y consulta bibliografía y repositorios para traer fallas típicas del dominio. Con esa información arma una lista ordenada de debilidades probables, por ejemplo: “puede confundir dos ciudades con el mismo nombre”, “no resuelve bien restricciones imposibles” o “no cita fuentes cuando resume”. Cada debilidad tiene condiciones de disparo y señales de que la cosa salió mal.
Después llega la parte “adversa”. Para cada debilidad, ATA inventa una persona creíble y un pedido diseñado para tensar la cuerda. Arranca en una dificultad media y sostiene una conversación completa con el agente, sin aclarar que está probando. Si el agente cumple, sube la dificultad; si tropieza, la baja para encontrar exactamente dónde empieza a fallar. Cada diálogo se puntúa con un juez automático que aplica una rúbrica clara (por ejemplo, éxito de la tarea, manejo de restricciones, comunicación, uso de fuentes). Ese juez no solo da un número: deja observaciones que ATA usa para ajustar el siguiente intento. El ciclo se repite durante varias rondas.
¿Qué entrega al final? Un reporte accionable. Incluye cuántos escenarios se probaron, el promedio de puntajes por criterio, una tabla de debilidades ordenadas por severidad y ejemplos de conversaciones que muestran el fallo y cómo reproducirlo. También sugiere arreglos, como “validar formato antes de llamar a la API”, “pedir confirmación cuando hay conflicto de restricciones” o “bajar a paso a paso cuando el usuario mezcla objetivos”.
Características sobresalientes:
• Entiende la estructura de tu agente. No genera tests al azar: analiza el grafo de estados, las herramientas y el manejo de errores para apuntar donde más duele.
• Ajusta la dificultad en vivo. Los casos de prueba suben o bajan el nivel según cómo responde tu agente, para perfilar con precisión el límite de capacidad.
• Cubre más variedad en menos tiempo. En una sola corrida puede tocar categorías de fallas que las pruebas manuales suelen pasar por alto (conflictos de restricciones, entradas malformadas, saltos bruscos de tema, alucinación de disponibilidad o precios).
• Da métricas comparables. Usa rúbricas consistentes, lo que permite ver progreso entre versiones y detectar regresiones.
• Produce ejemplos reproducibles. No se queda en “falló”: guarda el diálogo y las condiciones para que tu equipo lo repita y lo arregle.
• Se apoya en evidencia. Antes de testear, busca patrones conocidos en papers y foros técnicos del dominio para no “redescubrir la rueda”.
• Es rápido y repetible. Una pasada completa entra en la cadencia de un ciclo de desarrollo; se puede correr en cada release candidate.
• Es complementario a humanos. Automatiza la exploración de fallas funcionales y estructurales; deja a personas el pulido de tono, cortesía o matices de marca.
¿Qué no es? No es un reemplazo de la evaluación humana ni un “sello de calidad” mágico. Si tu agente debe sonar empático, cumplir guías de estilo o navegar temas sensibles, seguís necesitando ojos humanos. Tampoco es un benchmark genérico: su valor está en “leer” tu agente concreto y construir pruebas a medida.
Básicamente, ATA toma una tarea que hoy suele ser artesanal, lenta y difícil de comparar, y la convierte en un proceso: entender cómo está armado el agente, imaginar dónde fallaría, intentar romperlo con conversaciones realistas y medir con criterios claros. Para equipos que ya viven con agentes en producción o que están por lanzarlos, eso significa menos sorpresas, menos regresiones y un backlog de mejoras basado en evidencia, no en anécdotas.
Antecedentes y marco
Los agentes conversacionales con herramientas no son nuevos. Los vimos en planificación, búsqueda y redacción con memoria y APIs. El cuello de botella es medirlos cuando cambia el dominio, crecen las funciones o aparece ruido. Los benchmarks curados sirven de línea base, pero envejecen rápido y rara vez cubren la mezcla de restricciones, ambigüedades y errores de herramientas que aparecen en producción. Al mismo tiempo, creció la familia de “LLM como juez”, con rúbricas que puntúan salidas y sistemas de evaluación multiagente. Faltaba un puente: generar pruebas adaptativas que estén informadas por la arquitectura del agente, no solo por listas de prompts humanas, y hacerlo en un pipeline que produzca métricas y un informe para el equipo.
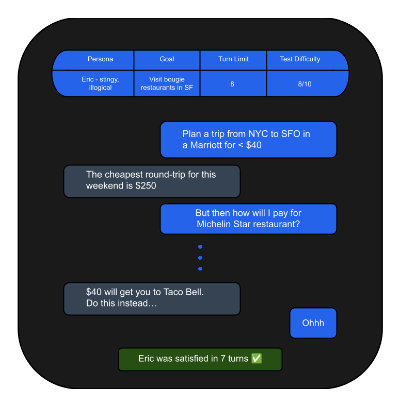
Esta imagen muestra un ejemplo de interacción entre el ATA y el agente bajo prueba (AUT), con los detalles de la prueba en la parte superior. El ATA planteó la hipótesis de que el AUT podría tener problemas para manejar restricciones conflictivas o imposibles de satisfacer, así que generó una persona “difícil” con una solicitud imposible. El AUT, sin saber que hablaba con un agente, explicó correctamente por qué esa solicitud es imposible.
Cómo funciona
El Agent-Testing Agent (ATA) se organiza en dos etapas con piezas modulares que comparten un estado global.
-
Planificación de debilidades. El evaluador arma una teoría de dónde y cómo puede fallar el agente bajo prueba. Para eso:
-
Escanea el código de punta a punta. Detecta nodos, transiciones, llamadas a herramientas, patrones de memoria y flujos de excepción. Con eso construye un grafo simbólico del diálogo y señala ramas problemáticas.
-
Interroga al diseñador. En una conversación de una pregunta por vez recolecta objetivo, criterios y prioridades. Corta cuando deja de ganar información.
-
Revisa literatura y datasets. Ejecuta ciclos de búsqueda para traer bugs frecuentes y estilos de evaluación del dominio.
-
Con todo el contexto, induce una lista priorizada de debilidades con nombre, condiciones de disparo, comportamiento esperado y cómo se manifestarían en diálogo. Pide confirmación y ajustes al usuario.
-
Testeo adversarial. Por cada debilidad validada lanza un hilo de ejecución independiente con tres nodos clave:
-
Generación de casos. Crea una persona y un prompt que ata objetivo del usuario, tono lingüístico, límite de turnos y criterios de evaluación. Arranca con dificultad media. Tiene ejemplos de fácil, medio y difícil por tipo de debilidad para calibrar.
-
Ejecución de diálogo. Habla con el agente bajo prueba sin avisarle que es un test. Corta si la persona alcanza su objetivo antes del límite. Registra fallas tempranas y éxitos parciales.
-
Evaluación y ajuste. Pasa el diálogo a un juez automático con rúbrica y obtiene un puntaje y observaciones detalladas. Con ese feedback actualiza la dificultad para “acercarse al borde” de falla. Si el agente va bien, sube dificultad. Si tropieza, baja a una variante más sencilla para perfilar el límite de capacidad. Repite en rondas y converge.
Cierra con un generador de reportes que consolida cuántos escenarios se probaron, los promedios de cada criterio, resúmenes por debilidad y recomendaciones. La interfaz incluye CLI y web. El objetivo es que un equipo técnico pueda iterar pruebas en ciclos cortos y ver señales útiles sin leer un paper de 30 páginas.
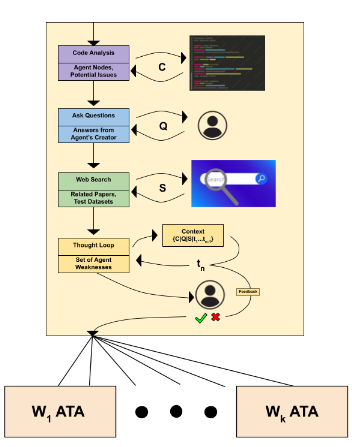
Planificación de debilidades: el ATA analiza la estructura estática (C), entrevista al creador del agente (Q) y reúne evidencia en corpus académicos/de búsqueda (S) para generar hipótesis de fallo priorizadas.
Comparaciones (benchmarks)
Los autores evalúan ATA en dos agentes de referencia. Un planificador de viajes que usa búsqueda en tiempo real y optimiza con restricciones de presupuesto. Un escritor de artículos estilo Wikipedia que investiga, cita fuentes y estructura secciones. En ambos casos se corrió un estudio espejo con diez anotadores humanos por agente. Para agregar fricción, comparan además contra una versión ablatida del evaluador que no analiza código ni hace búsqueda bibliográfica y por lo tanto genera pruebas solo desde descripciones del usuario.
Resultados por cobertura. ATA encuentra categorías de debilidades que el grupo humano no listó de forma sistemática. Por ejemplo, contradicción de restricciones, entradas malformadas, referencias ambiguas del usuario, manejo de cambios rápidos de tema o disponibilidad y precios alucinados. El hallazgo no es que las personas sean “peores”, sino que su foco varía. Los humanos tienden a remarcar tono, amabilidad y aspectos interpersonales. El meta-agente prioriza debilidades funcionales y estructurales que afectan éxito de la tarea de punta a punta.
Resultados por severidad y alineación. Al comparar rúbrica por rúbrica, emergen patrones. En el planificador, los humanos son más estrictos al puntuar cómo maneja restricciones. El evaluador automático es más generoso en ese punto, pero más exigente en comunicación. En el redactor tipo Wikipedia sucede lo contrario. ATA puntúa mejor uso de citas, completitud y estilo que los humanos. La lectura operativa es clara. El juez automático valora cumplimiento de estructura y cobertura. Las personas exigen más pulido estilístico y consistencia de tono. Como agregado, la ablatión sin análisis de código ni búsqueda muestra varianza más alta y calibra peor. Castiga en exceso en algunas rúbricas, es blando en otras y se aleja más del promedio humano.
Tiempo y costo. Hay un dato pragmático. El pase completo de ATA, con pruebas, evaluación y reporte, dura entre veinte y treinta minutos en una máquina de desarrollador. La ronda de diez anotadores humanos requiere días por coordinación y ejecución. Esa diferencia no elimina la necesidad de humanos, pero cambia el ritmo de iteración para equipos que depuran agentes con frecuencia.
Métricas concretas que vale la pena retener:
-
En el planificador de viajes, los promedios de rúbrica muestran que los humanos ponen 4,07 en manejo de restricciones y 3,63 en comunicación. ATA marca 3,53 y 4,11 respectivamente. La utilidad global queda en 3,78 para humanos y 3,36 para ATA.
-
En el escritor de Wikipedia, los humanos promedian 3,53 en uso de citas, 3,70 en completitud y 3,80 en estilo y organización. ATA marca 3,60, 4,00 y 4,10. La utilidad global queda en 3,60 para humanos y 3,80 para ATA.
-
La variante ablatida sin evidencia externa devalúa de forma sistemática criterios que dependen de grounding factual. Baja uso de citas hasta 2,24 de promedio y exhibe varianza de puntajes notablemente mayor que la versión completa.
-
La ablatión también penaliza de más el manejo de restricciones del planificador y exagera el contexto en el artículo largo. Señal de miscalibración cuando se recorta el análisis de código y la búsqueda.
El mapa completo sugiere uso complementario. ATA para explorar con profundidad modos de falla por capacidad, sacar un promedio y reducir regresiones. Humanos para medir tono, expectativas interpersonales y pulido fino, más pruebas dirigidas en puntos delicados.
Voces y fuentes
El paper encuadra ATA en tres corrientes de trabajos previos. Jueces LLM con rúbricas y razonamiento, datasets para evaluar agentes en dominios como viajes y coordinación multiagente y generadores automáticos de tests para soporte al cliente o verificación factual. La diferencia específica de ATA está en subir de nivel la fase previa al test. No se limita a amasar prompts. Construye hipótesis informadas por arquitectura y literatura, y ajusta pruebas con un posterior de dificultad que se actualiza con cada diálogo.
En la metodología aparece además la herencia de agentes que alternan pensar y actuar. La ejecución encadena personas sintéticas creíbles y elige la siguiente prueba en función del feedback del juez. Lo novedoso no es cada pieza por separado. Es la orquestación y el objetivo de que el informe resultante sea útil para quien mantiene el agente.
Impactos por sector
Producto y growth. Cualquier equipo que lance un agente con herramientas enfrenta el mismo dilema. ¿Dónde falla y con qué frecuencia? ATA ofrece un camino para responder con cifras en dominios como viajes, comercio electrónico, educación o soporte técnico. Los reportes priorizan debilidades por severidad y entregan ejemplos reproducibles. Eso se traduce en backlogs que no nacen de anécdotas.
Calidad y MLOps. QA para agentes es más que unit tests. Es reunir trayectorias de diálogo que estresen el sistema sin depender de un benchmark fijo. Un evaluador que combina lectura de código, bibliografía y adversarios sintéticos es escalable cuando cambia el flujo. Conecta con prácticas de regresión y con SLAs de utilidad global.
Investigación aplicada. La ablatión deja una lección. Quitar el anclaje en evidencia externa y estructura del código no solo reduce cobertura. Descalibra. En entornos donde la factualidad importa, un generador de pruebas que no mira documentos ni arquitectura tiende a medir peor.
Ética y política pública. Un juez automático que puntúa conversaciones genera preguntas previsibles. Sesgo del juez, dependencia de un modelo específico, riesgo de “entrenar para pasar el test”. El aporte del paper es mantener la transparencia. Publica rúbricas, procedimientos y código. En entornos regulados, ese es el mínimo para auditar.
Controversias y vacíos
Juez y parte. Dentro del hilo de pruebas, el modelo que genera escenarios y el que juzga comparten contexto. Eso mejora la comprensión de la intención del test, pero también puede alinear sesgos. El trabajo lo defiende con un argumento razonable. Los humanos que diseñan pruebas también juzgan con conocimiento del propósito. Aun así, conviene experimentar con jueces alternativos para verificar robustez de puntajes.
Cobertura semántica. El sistema muestra fuerza para debilidades funcionales. Tono, cortesía, expectativas implícitas y sutiles formas de cooperación entre agentes siguen necesitando ojo humano. No es una falla del enfoque. Es una señal para diseñar pipelines híbridos.
Generalización a otros dominios. Planificar viajes y redactar artículos cubre un arco útil. Falta ver cómo rinde cuando hay acciones físicas en entornos simulados, control de GUI compleja o coordinación entre múltiples agentes con incentivos distintos. El camino está abierto, y el propio paper lo deja como trabajo a futuro.
Dependencia del stack. Hay nodos de razonamiento que llaman a modelos concretos y APIs de proveedores específicos. Eso facilita reproducibilidad, pero puede introducir efectos de versión. Los autores publican el código para que otros adapten la receta. Queda en cada equipo evaluar los cambios al migrar.
Escenarios en el tiempo
Corto. Naturalizar ATA como parte del ciclo de desarrollo de agentes. Incorporar un pase completo en cada release candidate con reporte de utilidades promedio y lista priorizada de debilidades. Ajustar el juez con rúbricas del dominio y contrastar con una tanda corta de humanos en áreas sensibles como tono y persuasion.
Mediano. Integrar ATA con plataformas de MLOps. Tratar debilidades como métricas de calidad de servicio. Medir cobertura de pruebas por categoría y establecer umbrales de bloqueo en CI. Acoplar a suites de regresión que vuelven a correr la misma familia de adversarios cuando se cambia una herramienta o un prompt del sistema.
Largo. Extender el enfoque a coordinación multiagente. Diseñar personas que simulan roles con objetivos cruzados, evaluar negociación y formar un posterior de dificultad que capture no solo “qué tan difícil” sino “qué tipo de interacción social” falla. Incorporar jueces alternativos para triangulación. Publicar colecciones estandarizadas de personas y rúbricas por dominio para que surja un ecosistema comparable.
Ética y regulación
Transparencia. Un evaluador automatizado debe publicar sus rúbricas, pesos y ejemplos. El paper lo hace y sienta un precedente que otros deberían copiar. Sin esto, el riesgo de gaming del sistema es mayor.
Privacidad. Analizar código y logs de agentes puede rozar datos personales o secretos comerciales. La recomendación mínima es anonimizar antes de subir a la herramienta y mantener los reportes sin trazas sensibles.
Seguridad. Los adversarios sintéticos que prueban límites pueden generar consultas inseguras. El pipeline de testeo necesita los mismos filtros que el producto. Un crash o la ejecución de herramientas “fuera de rango” durante una prueba también es un hallazgo de seguridad.
Lectura final
El aporte de Agent-Testing Agent no es una promesa vaga. Es un método para convertir el QA de agentes en una práctica repetible. Analiza código, lee lo que ya aprendió la comunidad y fabrica conversaciones que suben o bajan la vara hasta encontrar límites reales. No reemplaza a las personas. Les quita trabajo repetitivo y deja que su tiempo se concentre en tono, cortesía y estilo. Si lo tomamos en serio, puede convertirse en el equivalente a las pruebas de regresión para sistemas conversacionales. Es el tipo de infraestructura que vuelve predecibles lanzamientos que hasta ayer dependían de suerte, anecdótica y capturas de pantalla.
Glosario
- ATA. Meta-agente que evalúa otros agentes con análisis de código, interrogatorio al diseñador y generación de diálogos adversariales.
- AUT. Agente bajo prueba. El sistema objetivo que se testea.
- LAAJ. LLM como juez. Rúbrica que puntúa cada diálogo y produce observaciones.
- Posterior de dificultad. Mecanismo que ajusta la dureza de la siguiente prueba en función del puntaje y observaciones del juez.
- Ablación. Versión del sistema que desactiva piezas para medir su aporte. En este paper, sin análisis de código ni búsqueda.
- Cobertura. Variedad de debilidades y escenarios que un evaluador logra tocar.
- Regresión. Reaparición de fallas tras cambios en código, prompts o herramientas.
Métricas y benchmarks (lista/tabla compacta)
- Cobertura de debilidades. ATA descubre categorías funcionales que el grupo humano no listó de forma sistemática.
- Rúbricas en planificador. Humanos 4,07 en manejo de restricciones y 3,63 en comunicación. ATA 3,53 y 4,11. Utilidad global 3,78 vs 3,36.
- Rúbricas en Wikipedia. Humanos 3,53 en citas, 3,70 en completitud, 3,80 en estilo. ATA 3,60, 4,00 y 4,10. Utilidad global 3,60 vs 3,80.
- Varianza de puntajes. La ablatión sube la varianza y se alinea peor con humanos.
- Tiempo de pase completo. Entre 20 y 30 minutos en equipo de desarrollador. Diez anotadores requieren días por coordinación.
- Hallazgos específicos. Contradicciones de restricciones, entradas malformadas, referencias ambiguas, cambios rápidos de tema, disponibilidad y precios alucinados.
Fuentes
-
Komoravolu, S.; Mrini, K. Agent-Testing Agent: A Meta-Agent for Automated Testing and Evaluation of Conversational AI Agents. arXiv, versión 1, 24/08/2025. Consulta: 26/08/2025. arXiv+4arXiv+4arXiv+4
-
Erisken, S. et al. LLM-as-a-Judge. Preprint 2025.
-
Chen, N. et al. JudgeLRM: Large reasoning models as a judge. Preprint 2025.
-
Xie, J. et al. Travelplanner: a benchmark for real-world planning with language agents. ICML 2024.
-
Agashe, S. et al. LLM-Coordination y CoordinationQA. NAACL 2025.
-
Arcadinho, S. et al. ALMITA: automatic test generation in customer support. arXiv 2024.
-
Lin, H. et al. FACT-AUDIT: fact-checking multiagent. ACL 2025.
-
Yao, S. et al. ReAct: razonamiento y acción en modelos de lenguaje. arXiv 2023.

