
En la conversación global sobre el futuro, pocas tecnologías generan tanta fascinación y controversia como la inteligencia artificial. Vivimos rodeados de sus manifestaciones más visibles, los asistentes virtuales y los modelos de lenguaje que conversan con nosotros, redactan textos o generan imágenes asombrosas. Estas herramientas, cada vez más integradas en nuestra cotidianidad digital, han alcanzado un nivel de sofisticación que hace apenas unos años pertenecía al dominio de la ciencia ficción. Sin embargo, detrás de esta fachada de competencia casi humana, subsiste una pregunta fundamental, una cuestión que obsesiona a los científicos y desarrolladores que trabajan en la vanguardia de este campo: ¿cómo medimos realmente su inteligencia? ¿Cómo sabemos si estos sistemas están volverse no solo más potentes, sino genuinamente más útiles, fiables y adaptables para las complejidades del mundo real?
La respuesta a esta pregunta ha sido, hasta ahora, insatisfactoria. Las pruebas tradicionales, conocidas en la jerga técnica como benchmarks, se han centrado en evaluar capacidades aisladas, como responder preguntas de conocimiento general, resolver problemas matemáticos o escribir código. Son como los exámenes de opción múltiple de la escuela: útiles para medir un conocimiento específico en un momento dado, pero insuficientes para evaluar la capacidad de un estudiante para navegar por la vida, colaborar con otros, gestionar su tiempo y adaptarse a imprevistos. Los actuales asistentes de inteligencia artificial, a pesar de sus proezas, a menudo se muestran frágiles. Fracasan ante la ambigüedad, se pierden en tareas que requieren múltiples pasos y son incapaces de reaccionar si las condiciones iniciales cambian a mitad del proceso. Su inteligencia, en gran medida, es estática y se desenvuelve en un vacío digital que no se parece en nada al flujo constante y caótico de nuestra realidad.
En este contexto de estancamiento evaluativo, un equipo de investigadores de Meta Superintelligence Labs ha presentado un trabajo que promete cambiar radicalmente las reglas del juego. Su propuesta, detallada en una publicación titulada “ARE: scaling up agent environments and evaluations”, no es simplemente un nuevo examen para la IA, sino una filosofía completamente nueva sobre cómo debemos concebir, entrenar y evaluar a los agentes inteligentes. El proyecto introduce dos conceptos revolucionarios: ARE (Meta Agents Research Environments) y Gaia2. Juntos, representan un salto cualitativo desde la medición de una inteligencia artificial teórica hacia la evaluación de una inteligencia artificial verdaderamente práctica.
Para entender la magnitud de esta propuesta, debemos familiarizarnos con su vocabulario. Un agente de inteligencia artificial es un sistema diseñado para actuar en nuestro nombre en un entorno digital, utilizando herramientas como el correo electrónico, el calendario o aplicaciones de mensajería para cumplir objetivos. El entorno es, precisamente, ese mundo digital en el que opera. Hasta ahora, la mayoría de los entornos de prueba eran simplificaciones extremas, escenarios congelados en el tiempo. La gran innovación de ARE es la creación de entornos dinámicos y persistentes. ARE es una especie de simulador de vuelo avanzado, pero en lugar de entrenar a pilotos, entrena y evalúa a agentes de IA en simulaciones increíblemente realistas y complejas de nuestra vida digital.
La clave de bóveda de ARE es un principio que los investigadores denominan asincronía. A diferencia de las pruebas convencionales, donde el mundo se detiene a esperar que el agente “piense” y actúe, en los entornos de ARE el tiempo fluye sin descanso. Mientras el agente delibera, pueden llegar nuevos correos, un amigo puede cancelar una cita o el estado de un pedido en línea puede cambiar. El mundo no se detiene, y el agente debe ser capaz de percibir, procesar y reaccionar a estos cambios en tiempo real. Esta característica, por sí sola, acerca las pruebas a un nivel de realismo nunca antes visto.
Dentro de estos mundos simulados, los agentes se enfrentan a escenarios diseñados en Gaia2, un nuevo y exigente benchmark que va mucho más allá de la simple ejecución de comandos. Gaia2 no solo pide al agente que realice una tarea, sino que lo pone a prueba en un espectro de capacidades mucho más humanas. Por ejemplo, la adaptabilidad, que es la habilidad de cambiar de plan sobre la marcha cuando surge un imprevisto. La gestión del tiempo, que implica realizar acciones en momentos específicos o dentro de plazos determinados. El manejo de la ambigüedad, que consiste en reconocer cuándo una petición es confusa o contradictoria y pedir una aclaración en lugar de ejecutar una acción errónea. E incluso la colaboración entre agentes, un fascinante escenario en el que el asistente principal debe interactuar con otros agentes de IA especializados para completar una tarea, aprendiendo a delegar y coordinar esfuerzos.
Finalmente, para que todo este sistema funcione, se necesita un juez implacable y preciso. El mecanismo de verificación de ARE es otra de sus joyas. En lugar de limitarse a comprobar si el resultado final es correcto, este sistema analiza la secuencia completa de acciones de escritura del agente (como enviar un correo o crear un evento) y la compara con una solución óptima predefinida por humanos. Este “árbitro” digital es capaz de discernir no solo si la tarea se completó, sino si se hizo de la manera correcta, en el orden correcto y respetando todas las dependencias. Es la diferencia entre saber que un estudiante resolvió un problema matemático y poder ver cada paso de su razonamiento para asegurarse de que no llegó a la respuesta por casualidad.
La presentación de ARE y Gaia2 no es solo un avance técnico; es una declaración de intenciones. Sugiere que la próxima fase en el desarrollo de la inteligencia artificial ya no dependerá únicamente de construir modelos más grandes y potentes, sino de definir tareas más significativas y crear evaluaciones más robustas que impulsen a estas tecnologías a desarrollar las capacidades que realmente importan para ser asistentes útiles y fiables en el complejo tejido de nuestras vidas. Es el comienzo de un nuevo horizonte, uno donde la inteligencia artificial se mide no por lo que sabe, sino por lo que puede hacer.

El problema de la vara de medir
Para apreciar la verdadera dimensión del avance que suponen ARE y Gaia2, es necesario sumergirse en las limitaciones fundamentales que han frenado la evolución de los agentes inteligentes. Durante años, el progreso en la inteligencia artificial ha estado impulsado por una carrera armamentística computacional: modelos de lenguaje cada vez más grandes, entrenados con cantidades de datos cada vez más astronómicas. Esta estrategia de escalado ha producido resultados espectaculares en tareas de lenguaje puro, pero ha mostrado rendimientos decrecientes a la hora de crear agentes autónomos competentes. La razón de este estancamiento no reside tanto en los modelos en sí, sino en la manera en que los hemos estado evaluando.
Las plataformas de evaluación existentes adolecen de tres grandes debilidades. La primera es su naturaleza estática. La mayoría de los benchmarks funcionan bajo un paradigma de petición y respuesta secuencial. Un usuario o un sistema plantea una tarea, y el entorno digital se congela, esperando pacientemente a que el agente complete su cadena de razonamiento y ejecute una acción. Una vez realizada la acción, el entorno avanza un paso y vuelve a detenerse. Este modelo es una abstracción burda de la realidad. El mundo digital, al igual que el físico, es un sistema dinámico y en constante cambio. Utilizar un entorno estático para evaluar a un agente es como evaluar la habilidad de un cirujano pidiéndole que opere sobre un maniquí inerte en lugar de sobre un paciente vivo cuyos signos vitales fluctúan. Se pierden por el camino capacidades cruciales como la monitorización constante, la gestión de interrupciones y la proactividad.
La segunda debilidad es la falta de control y reproducibilidad, especialmente en las pruebas que utilizan la web como entorno. La web es un campo de pruebas fantástico por su diversidad y realismo, pero es también un ecosistema caótico y efímero. Una página web puede cambiar su diseño de un día para otro, una API puede ser actualizada o un servicio puede dejar de estar disponible. Esto convierte la evaluación científica en una pesadilla. Un agente que hoy supera una prueba con éxito podría fracasar mañana no por una regresión en su capacidad, sino porque el entorno ha cambiado. Es imposible reproducir un experimento con exactitud, lo que dificulta enormemente el análisis comparativo entre diferentes modelos o la medición del progreso a lo largo del tiempo. Además, realizar operaciones de escritura en la web real (como hacer una compra o reservar un vuelo) para una prueba a gran escala es simplemente inviable.
Finalmente, la tercera debilidad es la estrechez de las tareas propuestas. Los entornos existentes suelen estar diseñados para evaluar un conjunto muy limitado de habilidades, como la búsqueda de información o el uso de una herramienta específica. Este enfoque especializado ha llevado a la creación de agentes que son muy buenos en una cosa pero inútiles para todo lo demás. La inteligencia general, sin embargo, no consiste en la suma de habilidades especializadas, sino en la capacidad de integrar y orquestar un amplio repertorio de competencias para resolver problemas complejos y novedosos. Los benchmarks actuales saturan rápidamente a medida que los modelos mejoran, lo que obliga a los investigadores a crear constantemente nuevos entornos y tareas desde cero, un proceso costoso y lento que fragmenta los esfuerzos de la comunidad científica.
Estas limitaciones en conjunto han creado un techo de cristal para el desarrollo de agentes verdaderamente autónomos. Los modelos de IA, por muy potentes que sean, solo pueden aprender y mejorar en la medida en que los entornos de entrenamiento y evaluación se lo permitan. Si la vara de medir es corta, estática y unidimensional, los sistemas que desarrollemos reflejarán inevitablemente esas mismas carencias. ARE y Gaia2 nacen precisamente para romper ese techo, proponiendo una vara de medir que es, por diseño, dinámica, controlada, reproducible y multidimensional.
Construyendo mundos para la IA: así funciona ARE
Meta Agents Research Environments, o ARE, es la respuesta directa a los problemas que acabamos de describir. No es un simple entorno, sino una plataforma de investigación, un sofisticado andamiaje de software diseñado para permitir a los científicos construir, ejecutar y analizar mundos digitales simulados con un nivel de detalle y control sin precedentes. La filosofía que subyace a ARE es tan elegante como poderosa: todo lo que ocurre en el entorno es un evento.
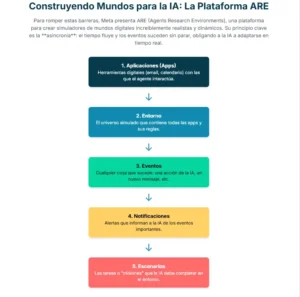
Esta concepción, basada en eventos y gobernada por el tiempo, es lo que permite a ARE simular la asincronía del mundo real. La plataforma se sustenta sobre cinco conceptos fundamentales que trabajan en conjunto. El primero son las aplicaciones (Apps). Al igual que en un teléfono móvil, estas son interfaces con estado que ofrecen un conjunto de herramientas para interactuar con una fuente de datos. Por ejemplo, una aplicación de correo electrónico tendría herramientas como <span class="selected">enviar_correo</span> o <span class="selected">buscar_correos</span>, todas operando sobre una base de datos de emails simulada. Este diseño permite estudiar tareas que modifican el estado del mundo de forma consistente y reproducible.
El segundo concepto es el entorno, que es esencialmente una colección de aplicaciones, sus datos y las reglas que gobiernan su comportamiento. El entorno es el universo completo en el que vive el agente. Mantiene el estado global de todas las aplicaciones, gestiona el paso del tiempo y define las leyes de la física de ese universo digital, como qué acciones están permitidas o cómo afectan al estado del sistema.
El corazón del dinamismo de ARE reside en el tercer concepto: los eventos. Un evento es cualquier cosa que sucede en el entorno, desde una acción del agente (como hacer clic en un botón) hasta un cambio programado en el estado del sistema (como la llegada de un mensaje de un amigo a una hora determinada). Cada evento lleva una marca de tiempo y se registra meticulosamente. Lo más interesante es que los eventos pueden programarse con complejas relaciones de dependencia, formando grafos que permiten simular escenarios con múltiples hilos de actividad paralelos y condicionales. Por ejemplo, se puede programar un evento para que solo se active si otros dos eventos previos han concluido con éxito.
El cuarto pilar son las notificaciones. Estas son el principal canal a través del cual el entorno comunica los eventos al agente. De forma similar a las notificaciones de un smartphone, el sistema puede configurarse para informar al agente solo de ciertos tipos de eventos, creando diferentes niveles de observabilidad del entorno. Esto permite investigar capacidades como la proactividad: un agente puede no recibir una notificación sobre un nuevo correo, pero si es suficientemente proactivo, puede decidir revisar su bandeja de entrada por sí mismo. Las notificaciones son las que despiertan al agente y le obligan a reaccionar a un mundo en movimiento.
Finalmente, el quinto concepto son los escenarios. Un escenario es la encapsulación de una tarea completa. Define el estado inicial del entorno, la secuencia de eventos programados que ocurrirán y, crucialmente, el mecanismo de verificación para determinar si el agente ha tenido éxito. Los escenarios transforman la evaluación desde tareas de un solo paso a misiones dinámicas que se desarrollan a lo largo del tiempo, con múltiples turnos de interacción y posibles imprevistos. Un escenario puede ser tan simple como “pide una pizza” o tan complejo como “organiza un viaje de fin de semana para tres personas, teniendo en cuenta sus calendarios, preferencias de vuelo y presupuesto, y adapta la reserva si la aerolínea cambia el horario del vuelo”.
Esta arquitectura no solo permite crear entornos de una riqueza y realismo extraordinarios, sino que también es increíblemente flexible. ARE está diseñado para ser extensible, permitiendo integrar aplicaciones reales a través de protocolos estándar o conectar nuevas bases de datos. Los investigadores ya no tienen que reinventar la rueda cada vez que quieren probar una nueva idea; pueden utilizar los bloques de construcción de ARE para configurar rápidamente un entorno a medida. Es una plataforma que democratiza la creación de benchmarks de alta calidad, liberando a la comunidad científica para que se concentre en lo que de verdad importa: definir los desafíos que llevarán a la inteligencia artificial al siguiente nivel.
Gaia2, el examen definitivo para los agentes inteligentes
Si ARE es el teatro de operaciones, Gaia2 es la primera gran obra que se representa en él. Se trata de un benchmark de nueva generación, construido íntegramente sobre la plataforma ARE, y diseñado para medir un espectro de capacidades de los agentes inteligentes que hasta ahora habían sido ignoradas. Gaia2 abandona las preguntas de trivial y los rompecabezas abstractos para centrarse en tareas que, aunque sencillas para un ser humano, resultan diabólicamente complejas para los modelos de IA actuales precisamente porque requieren una comprensión holística del contexto, el tiempo y la interacción.
El banco de pruebas consta de cientos de escenarios verificables y anotados por humanos que se desarrollan en un entorno simulado llamado Mobile, una réplica funcional de un dispositivo móvil con sus aplicaciones típicas: correo, mensajería, calendario, contactos, mapas, compras, etc. Este entorno está densamente poblado con datos sintéticos coherentes, creando un microcosmos digital realista donde un agente puede operar.
Lo que distingue a Gaia2 es su enfoque en un conjunto de capacidades fundamentales para la inteligencia práctica. La primera es la búsqueda y ejecución, habilidades ya presentes en otros benchmarks pero que aquí se evalúan en un entorno más complejo y realista. Un escenario de búsqueda podría requerir cruzar información de la aplicación de contactos y la de chats para responder a la pregunta: “¿En qué ciudad viven la mayoría de mis amigos?”. Una tarea de ejecución podría ser: “Actualiza la edad de todos mis contactos menores de 24 años para que tengan un año más”.
Pero es en las nuevas capacidades donde Gaia2 realmente brilla. La adaptabilidad pone a prueba la flexibilidad del agente. Imagina que le pides que reserve una cita para ver una propiedad con un amigo. El agente envía el mensaje de confirmación, pero entonces el amigo responde sugiriendo otra propiedad a otra hora. Un agente adaptable debe ser capaz de detectar este cambio inesperado, procesar la nueva información y modificar el plan original, cancelando la cita anterior y creando una nueva. Esta capacidad de reaccionar a las consecuencias de sus propias acciones es vital para cualquier sistema que opere en el mundo real.
La capacidad de gestionar el tiempo introduce una dimensión completamente nueva. Los escenarios de Gaia2 no solo transcurren en el tiempo, sino que a menudo lo utilizan como una restricción fundamental. Por ejemplo: “Envía un mensaje a mis compañeros de reunión preguntando quién va a pedir el taxi. Si en tres minutos nadie ha respondido, pide tú un taxi por defecto”. Esta tarea requiere que el agente comprenda una restricción temporal, monitorice el entorno en busca de un evento (la respuesta de un compañero) y ejecute una acción condicionada por el paso del tiempo.
Otra capacidad crucial es el manejo de la ambigüedad. Muchas de las instrucciones que damos en la vida real son imperfectas: pueden ser contradictorias, incompletas o tener múltiples interpretaciones válidas. Los modelos actuales tienden a lanzarse a ejecutar la primera interpretación que les parece plausible, lo que puede tener consecuencias negativas. Un escenario de ambigüedad en Gaia2 podría ser: “Programa un evento de yoga de una hora cada día a las 18:00 desde el 16 hasta el 21 de octubre. Pregúntame si hay conflictos”. Si el agente detecta que uno de esos días ya hay una cita a esa hora, lo correcto no es sobreescribirla, sino informar al usuario del conflicto y pedir una aclaración. Esta es la diferencia entre un autómata y un verdadero asistente.
Quizás la capacidad más futurista que evalúa Gaia2 es la colaboración entre agentes (Agent2Agent). En estos escenarios, algunas de las aplicaciones del entorno Mobile son reemplazadas por otros agentes de IA autónomos y especializados. El agente principal ya no puede usar directamente las herramientas de, por ejemplo, la aplicación de compras. En su lugar, debe comunicarse con el “agente de compras” mediante lenguaje natural, explicándole lo que necesita, interpretando sus respuestas y coordinando acciones. Esto simula un futuro emergente en el que las APIs tradicionales serán reemplazadas por agentes inteligentes, y nuestros asistentes personales deberán convertirse en excelentes gestores de equipos de IAs.
Finalmente, Gaia2 evalúa la robustez frente al ruido. El mundo real es imperfecto. Las herramientas a veces fallan, las conexiones se caen y recibimos información irrelevante constantemente. Los escenarios de ruido simulan estas condiciones introduciendo fallos aleatorios en las herramientas o eventos ambientales que no tienen nada que ver con la tarea en curso, para medir si el agente es capaz de mantener el rumbo y no distraerse.
La creación de estos escenarios es un proceso artesanal y riguroso. Equipos de anotadores humanos diseñan cada tarea y su solución óptima, que luego es validada por otros anotadores en un proceso de revisión por pares para garantizar su coherencia y dificultad. Gaia2 no es solo un examen más difícil; es un examen más inteligente, diseñado para medir las cualidades que separan a una herramienta potente de un compañero digital verdaderamente capaz.
El veredicto: lo que nos dicen los resultados
Una vez construido el teatro de operaciones (ARE) y escrita la obra (Gaia2), llega el momento de ver actuar a los protagonistas: los modelos de inteligencia artificial más avanzados del mundo. Los investigadores de Meta sometieron a una amplia gama de sistemas, tanto propietarios como de código abierto, al riguroso examen de Gaia2. Los resultados, lejos de coronar a un único vencedor, pintan un panorama fascinante y lleno de matices sobre el estado actual de la inteligencia artificial y los desafíos que quedan por delante.
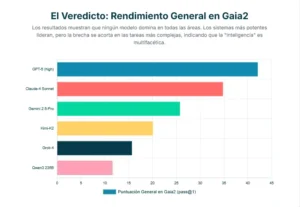
La primera gran conclusión es que ningún sistema domina en todo el espectro de capacidades. Mientras que los modelos más punteros, como GPT-5 (en su variante de alto razonamiento), Claude-4 Sonnet y Gemini 2.5-Pro, muestran un rendimiento superior en las tareas más tradicionales de ejecución y búsqueda, su ventaja se diluye, y a veces desaparece, en las nuevas y más complejas dimensiones. Este hallazgo es fundamental porque desafía la noción simplista de que existe una única escala lineal de “inteligencia” en la que los modelos pueden ser ordenados de peor a mejor. La realidad es que la inteligencia es multifacética, y diferentes arquitecturas y estrategias de entrenamiento producen sistemas con distintos perfiles de fortalezas y debilidades.
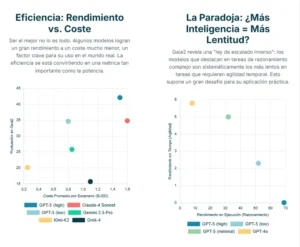
Quizás el descubrimiento más revelador y contraintuitivo es lo que podríamos llamar la ley de escalado inverso para el tiempo. Los experimentos demostraron que los modelos que obtenían las puntuaciones más altas en las tareas que requerían un razonamiento profundo y complejo (como la adaptabilidad y la ambigüedad) eran, sistemáticamente, los que peores resultados obtenían en los escenarios con restricciones de tiempo. En otras palabras, ser más “inteligente” a menudo significa ser más lento. Este compromiso entre capacidad de razonamiento y velocidad de respuesta no es sorprendente, ya que el pensamiento profundo consume tiempo y recursos computacionales. Sin embargo, Gaia2 proporciona la primera evidencia sistemática de este fenómeno y subraya una tensión crítica para el despliegue práctico de estos sistemas. Un asistente que tarda varios minutos en dar una respuesta, por muy brillante que esta sea, es inútil en una conversación en tiempo real o en una situación que requiere una acción inmediata.
Esta tensión nos lleva directamente a otra de las grandes lecciones del estudio: la importancia de evaluar los sistemas no solo por su rendimiento bruto, sino también en función de su eficiencia y coste. En el mundo real, las soluciones no solo tienen que ser correctas, sino también viables económicamente. Los gráficos de los resultados muestran claramente que existe un complejo equilibrio entre la puntuación obtenida, el coste computacional (medido en dólares por escenario) y el tiempo de resolución. Algunos modelos ofrecen un rendimiento excelente pero a un coste prohibitivo, mientras que otros, aunque ligeramente menos capaces, son mucho más eficientes. Esta perspectiva, que normaliza el rendimiento en función de los recursos consumidos, cambiará la forma en que la industria juzga el valor de un modelo. El objetivo ya no es solo construir el sistema más potente, sino el que ofrece el mejor rendimiento por cada dólar invertido o cada vatio consumido.
Los resultados en las categorías de colaboración (Agent2Agent) y robustez (Noise) también arrojaron luz sobre aspectos cruciales. En los escenarios de colaboración, se observó que los modelos más débiles se beneficiaban más de la posibilidad de delegar tareas a otros agentes, lo que sugiere que las arquitecturas multiagente podrían ser una vía para mejorar el rendimiento de sistemas menos potentes. Por otro lado, la mayoría de los modelos mostraron una degradación significativa de su rendimiento en presencia de ruido y fallos, lo que indica que la robustez sigue siendo una asignatura pendiente.
En resumen, el veredicto de Gaia2 es una llamada a la humildad y a la sofisticación. La era de medir la inteligencia artificial con métricas simples ha terminado. El futuro pasa por comprender los complejos perfiles de capacidad de cada sistema, analizar los equilibrios entre inteligencia, velocidad y coste, y reconocer que el camino hacia la superinteligencia no será una línea recta, sino un intrincado mapa de compensaciones y especializaciones.
Más allá de la prueba: las implicaciones de un nuevo paradigma
El trabajo presentado por Meta con ARE y Gaia2 trasciende los confines de un simple artículo de investigación. Representa un cambio de paradigma, una nueva forma de pensar sobre el destino de la inteligencia artificial. Las implicaciones de este enfoque se extienden mucho más allá de la comunidad académica y apuntan hacia el futuro de la tecnología, la sociedad y nuestra propia relación con las máquinas inteligentes.
La consecuencia más inmediata es una redefinición de lo que significa “progreso” en este campo. La simple búsqueda de puntuaciones más altas en benchmarks estáticos ha llevado a un tipo de progreso unidimensional. ARE y Gaia2 proponen una visión mucho más rica y holística. El progreso ya no será solo construir un martillo más grande, sino desarrollar una caja de herramientas completa. Los futuros asistentes de IA no serán valorados por una única métrica de inteligencia, sino por su perfil de competencias: su agilidad para adaptarse, su fiabilidad bajo presión, su eficiencia en el uso de recursos y su capacidad para colaborar. Esto orientará la investigación hacia la creación de sistemas más equilibrados y, en última instancia, más útiles.
Este nuevo enfoque evaluativo inevitablemente impulsará cambios fundamentales en la arquitectura de los propios sistemas de IA. La demostración de la tensión entre el razonamiento profundo y la velocidad de respuesta pone sobre la mesa el concepto de computación adaptativa. Un agente verdaderamente inteligente no debería usar la totalidad de su capacidad de “pensamiento” para cada tarea. Debería ser capaz de evaluar la complejidad de un problema y asignar la cantidad justa de recursos computacionales para resolverlo. Las tareas triviales deberían resolverse de forma rápida y barata con modelos más pequeños y especializados, mientras que solo los problemas verdaderamente difíciles deberían activar los circuitos de razonamiento más profundos y costosos. Este principio de eficiencia computacional será esencial para que los agentes de IA puedan escalar y ser económicamente viables en aplicaciones del mundo real.
Asimismo, el énfasis en la asincronía y la interacción en tiempo real empuja a la industria a moverse más allá del paradigma secuencial de ReAct (Reasoning and Acting) que ha dominado el diseño de agentes hasta ahora. El futuro pertenece a los sistemas agenticos asíncronos, capaces de percibir, razonar y actuar de forma concurrente, fusionando múltiples flujos de información que llegan de un entorno en constante cambio. Este es un desafío de ingeniería y de ciencia fundamental, pero es un paso indispensable para pasar de los asistentes que responden a comandos a los agentes que gestionan proactivamente flujos de trabajo complejos.
A nivel social y tecnológico, la relevancia de este trabajo es inmensa. Al centrar la evaluación en capacidades prácticas y en un uso realista de las herramientas digitales, ARE y Gaia2 alinean el desarrollo de la IA con las necesidades humanas reales. Fomentan la creación de tecnologías que no son meramente demostraciones de fuerza bruta computacional, sino herramientas fiables, seguras y eficientes. El énfasis en la verificación rigurosa de las acciones de escritura, por ejemplo, es crucial para garantizar la seguridad y evitar que los agentes tomen decisiones perjudiciales. La capacidad de manejar la ambigüedad y pedir aclaraciones es fundamental para construir una relación de confianza entre humanos y máquinas.
En última instancia, la investigación sobre ARE y Gaia2 nos enseña que el camino hacia una inteligencia artificial avanzada y beneficiosa no se recorre solo a base de escalar el tamaño de los modelos. Se recorre a través de una comprensión más profunda de la propia naturaleza de la inteligencia práctica. Requiere que definamos con precisión las tareas que queremos que estas máquinas realicen y que construyamos los entornos y las métricas adecuadas para guiar su aprendizaje. Es una labor menos glamurosa que anunciar un nuevo modelo con billones de parámetros, pero es infinitamente más importante. Es la labor silenciosa y rigurosa de la ciencia que traza el mapa del futuro, asegurándose de que, cuando lleguemos a él, lo hagamos con herramientas que no solo sean poderosas, sino también sabias.
Referencias
Froger, R., Mialon, G., Scialom, T., et al. (2025). ARE: scaling up agent environments and evaluations. Meta Superintelligence Labs.

