
Vivimos inmersos en una narrativa de cambio de era. La inteligencia artificial generativa, con su asombrosa capacidad para crear texto, imágenes y código, ha desatado una ola de inversión y entusiasmo que no tiene parangón en la historia reciente de la tecnología. Miles de millones de dólares fluyen hacia laboratorios de investigación y startups, mientras las corporaciones más grandes del mundo se apresuran a integrar estos nuevos sistemas en sus operaciones.
La promesa es monumental: una revolución en la productividad que redefinirá la naturaleza misma del trabajo. Sin embargo, tras el fulgor de las demostraciones y el estruendo de los anuncios, persiste una pregunta fundamental, casi un susurro incómodo en medio de la euforia colectiva: ¿son estas inteligencias artificiales, en su estado actual, verdaderamente productivas en las tareas complejas y de alto valor que definen la economía del conocimiento?
Durante años, el progreso en el campo de la inteligencia artificial se ha medido a través de una serie de pruebas estandarizadas, conocidas en la jerga técnica como benchmarks. Estos baremos, análogos a los exámenes de selectividad para los estudiantes, han servido como una vara de medir indispensable para que la comunidad científica calibre el avance de sus creaciones. Han sido cruciales para impulsar la competencia y la innovación, llevando a los modelos a alcanzar y superar el rendimiento humano en juegos, traducción de idiomas o clasificación de imágenes.
Pero aquí reside una de las mayores ineficiencias de la investigación actual en IA: la mayoría de estas pruebas evalúan capacidades abstractas, desconectadas de las exigencias del mundo profesional real. Miden el conocimiento enciclopédico o la resolución de acertijos lógicos, pero rara vez ponen a prueba la capacidad de un sistema para ejecutar el tipo de trabajo que genera un valor económico tangible. Esta brecha entre lo que los benchmarks evalúan y lo que la inteligencia artificial realmente necesita hacer para ser útil en la práctica se ha convertido en uno de los mayores obstáculos para materializar su potencial.
Es en este contexto de necesidad crítica donde emerge una nueva y ambiciosa iniciativa destinada a cambiar las reglas del juego. Se trata del Índice de Productividad de la IA, conocido por su acrónimo en inglés, APEX. Este proyecto no es simplemente otra prueba en una larga lista de evaluaciones. Representa un cambio filosófico fundamental, una reorientación de los objetivos de la industria. Su propósito explícito no es medir la inteligencia en abstracto, sino calibrar la utilidad en concreto. APEX busca establecer una meta para el progreso de la IA que esté directamente alineada con las tareas económicamente valiosas del mundo real.
Para comprender la magnitud de esta empresa, es necesario familiarizarse con algunos conceptos clave. Los modelos de frontera son los sistemas de inteligencia artificial más avanzados y potentes del momento, desarrollados por los laboratorios líderes como OpenAI, Google o Anthropic. El trabajo del conocimiento se refiere a aquellas profesiones no rutinarias que exigen un razonamiento complejo, la resolución de problemas y un juicio experto. APEX, en su primera versión, se centra en cuatro de los dominios más exigentes y de mayor valor de este tipo de trabajo: la banca de inversión, la consultoría de gestión, el derecho corporativo y la atención médica primaria.
La metodología de APEX se sustenta sobre dos pilares revolucionarios. Primero, las tareas que los modelos deben resolver no son problemas académicos, sino encargos diseñados por una élite de profesionales humanos para reflejar fielmente los desafíos de su día a día. Segundo, la evaluación de las respuestas no es subjetiva, sino que se basa en guías de puntuación increíblemente detalladas y objetivas, denominadas rúbricas, que desglosan qué constituye exactamente una respuesta de alta calidad.
Lo que APEX propone, en esencia, es un cambio radical en la definición de «estado del arte». Ya no se trata solo de construir una máquina que pueda pasar un examen, sino de desarrollar una herramienta que sea genuinamente útil para aumentar o incluso automatizar el trabajo de un abogado, un consultor o un médico. Al crear un baremo que mide la productividad económica, sus artífices no solo están presentando una nueva tabla de clasificación; están intentando redirigir los inmensos recursos y el talento de la industria de la IA hacia un objetivo más pragmático y, en última instancia, más transformador. Están cambiando las porterías del campo de juego, desplazándolas desde la demostración de una inteligencia pura hacia la prueba de una utilidad práctica.
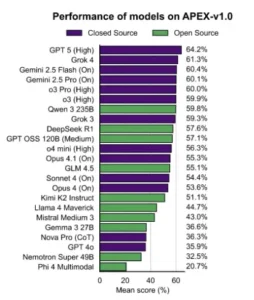
Puntuación media de los modelos en APEX-v1.0. Los modelos se clasifican en orden descendente. Las etiquetas entre paréntesis indican las configuraciones de «Pensamiento» utilizadas cuando hay una opción disponible.
El metro patrón de la inteligencia artificial
La credibilidad de cualquier sistema de medición reside en la solidez de su fundamento. En el caso de APEX, esa base no es un algoritmo complejo ni un conjunto de datos masivo extraído de internet, sino algo mucho más valioso y difícil de obtener: la experiencia humana destilada. La construcción de este índice es una crónica de un esfuerzo meticuloso y profundamente centrado en el conocimiento experto, un proceso que garantiza que la prueba no sea un mero simulacro académico, sino un reflejo fiel de las exigencias del mundo profesional de élite.
El primer paso fue reunir a los arquitectos de este nuevo estándar. El proyecto reclutó a un equipo de 76 profesionales con una experiencia media de 7.25 años en sus respectivos campos. No se trataba de generalistas, sino de especialistas provenientes de la cúspide de sus industrias. Entre ellos se contaban banqueros de inversión de firmas como Goldman Sachs y JPMorgan, consultores de gestión de las tres grandes, McKinsey, BCG y Bain, y abogados de despachos de élite como Latham & Watkins. Este elenco de expertos aseguró que el ADN del índice estuviera impregnado de un conocimiento práctico y actual de lo que significa realizar un trabajo de alta calidad en entornos de máxima exigencia.
El proceso de selección fue extraordinariamente riguroso. No bastaba con tener un currículum impresionante. Los candidatos pasaban por entrevistas diseñadas para evaluar no solo su dominio técnico, sino también sus habilidades de comunicación y razonamiento, y su comprensión del papel potencial que la IA podría jugar en su sector. Aquellos que superaban esta fase eran invitados a completar una evaluación remunerada de una a dos horas, una prueba práctica en la que debían demostrar su capacidad para redactar instrucciones claras y rúbricas de evaluación precisas. Este filtro garantizaba que los expertos seleccionados no solo supieran hacer su trabajo, sino que también fueran capaces de articular y estructurar su conocimiento para poder enseñárselo, y a la vez usarlo para evaluar, a una máquina.
Una vez conformado el equipo, comenzó la tarea de deconstruir la pericia profesional. Se pidió a los expertos que crearan prompts o instrucciones que representaran tareas complejas de su trabajo diario. Estos no eran encargos triviales; se diseñaron para ser desafíos sustanciales que a un profesional humano le llevaría entre una y ocho horas completar, con una media de 3.5 horas. Cada tarea exigía un «razonamiento sofisticado», la capacidad de analizar información de múltiples fuentes, sintetizarla y presentar una conclusión coherente y bien fundamentada.
Aquí es donde reside el componente más innovador de la metodología de APEX: la creación de las rúbricas. El concepto de «calidad» en el trabajo del conocimiento es a menudo nebuloso y difícil de medir. Una presentación de consultoría o un memorando legal pueden ser juzgados como «buenos» o «malos» basándose en la intuición de un supervisor experimentado. APEX se propuso desmantelar esta subjetividad.
Para cada tarea, los expertos crearon una rúbrica detallada, un conjunto de criterios objetivos y verificables que descomponen la idea abstracta de «calidad» en componentes discretos y evaluables. Cada criterio es una afirmación específica sobre la respuesta del modelo que puede ser calificada como «Cumplida» o «No cumplida». El propio estudio traza una analogía brillante: las rúbricas son para el trabajo del conocimiento lo que las pruebas unitarias son para el código de software. Son una serie de comprobaciones granulares que, en conjunto, verifican la calidad y corrección del producto final. La escala de este esfuerzo fue inmensa, con un promedio de casi 30 criterios de evaluación distintos para cada una de las 200 tareas del índice.
La verdadera genialidad de APEX, por tanto, no radica en su complejidad computacional, sino en su sistemática «codificación» del juicio profesional tácito. Ha transformado las valoraciones subjetivas de la calidad, que residen en la mente de los expertos, en datos objetivos, estructurados y calificables por una máquina. Un profesional senior a menudo confía en un sentido intuitivo desarrollado a lo largo de años para saber qué constituye un «buen trabajo». Es un conocimiento tácito, difícil de articular.
La metodología de APEX obliga a estos expertos a externalizar esa intuición, a traducirla en una serie de reglas explícitas y binarias. Este acto de traducción es, quizás, la contribución intelectual más significativa del proyecto. Crea una forma escalable, repetible y objetiva de medir algo que antes se consideraba inherentemente subjetivo. En efecto, es la construcción de una máquina capaz de reconocer la excelencia profesional porque ha sido instruida en las reglas explícitas de esa excelencia por los mejores profesionales humanos.
Cuatro arenas para titanes digitales
Para que un baremo de la capacidad de la inteligencia artificial sea verdaderamente revelador, debe pasar de la teoría metodológica a la práctica tangible. Es en la naturaleza de los desafíos propuestos donde APEX demuestra su valía y su profunda conexión con el mundo real. Las 200 tareas que componen el índice no son preguntas de un concurso de trivial, sino simulaciones complejas de jornadas laborales en cuatro de los campos más exigentes del conocimiento. Al examinar ejemplos concretos de cada dominio, se puede apreciar la sofisticación de las competencias que se ponen a prueba, un conjunto de habilidades que van mucho más allá de la simple recuperación de información.
En el ámbito del derecho, imaginemos un caso como el identificado con el código 1045. Un cliente, heredero de un músico fallecido, se acerca a un bufete con una duda sobre los derechos de autor de tres álbumes icónicos. El contrato original, firmado décadas atrás, contiene cláusulas contradictorias sobre si las grabaciones deben considerarse «obras por encargo». La tarea encomendada a la inteligencia artificial no es simplemente buscar la definición legal de este término.
Debe analizar los hechos del caso, interpretar la legislación de derechos de autor de Estados Unidos, en particular el estatuto 17 U.S.C. § 101, y sintetizar toda esta información en un memorando legal formal y estructurado, con un límite estricto de 1,500 palabras. La rúbrica de evaluación no solo verificará la exactitud de las conclusiones legales, sino también si el formato es el correcto, si las citas siguen el estricto formato Bluebook y si la argumentación es lógicamente sólida.
Cambiemos de escenario al vertiginoso mundo de la banca de inversión. En la tarea 810, se le pide a la IA que actúe como asesora de Medtronic, una gigante de la tecnología médica. La empresa está considerando una estrategia para crear valor para sus accionistas: la escisión de su división de diabetes. La misión de la IA es realizar una valoración financiera de esta división como si fuera una entidad independiente. Esto implica una compleja serie de cálculos de flujo de caja descontado.
El sistema debe extraer datos de los documentos proporcionados, calcular con precisión métricas financieras específicas como los activos fijos (PP&E), el beneficio antes de intereses, impuestos, depreciaciones y amortizaciones (EBITDA) y el capital circulante neto, todo ello con un redondeo exacto a dos decimales. La prueba no mide si la IA «sabe» lo que es una valoración, sino si puede ejecutarla con la precisión cuantitativa que se exige a un analista financiero.
En el campo de la consultoría de gestión, la tarea 828 presenta un caso de negocio clásico. Un cliente quiere lanzar una empresa dedicada al reciclaje de plástico PET, el material más común en las botellas. Antes de invertir, necesita una estimación del tamaño del mercado mundial. La IA debe actuar como un consultor junior, utilizando los datos poblacionales y de consumo proporcionados para realizar un análisis de dimensionamiento del mercado. Esto requiere calcular la tasa de crecimiento anual compuesta (CAGR) de la población mundial, proyectar esa cifra a futuro y, a partir de ahí, estimar la demanda anual de botellas de plástico PET en toneladas métricas. De nuevo, el éxito no depende de recitar hechos, sino de seguir un proceso analítico lógico y presentar una previsión cuantitativa defendible.
Finalmente, nos adentramos en el dominio de la medicina, quizás el más crítico por las vidas que están en juego. El caso 929 describe un desafío diagnóstico complejo: un niño de seis años se presenta en la clínica con sibilancias recurrentes y un historial de múltiples visitas a urgencias, a pesar de estar en tratamiento para el asma. A partir de la historia clínica del paciente y los resultados de unos análisis de sangre iniciales, la inteligencia artificial debe actuar como un médico de atención primaria.
Tiene que conectar los puntos: las infecciones recurrentes, los niveles bajos de ciertos anticuerpos y la falta de inmunidad a las vacunas. La tarea consiste en deducir el diagnóstico más probable, una condición compleja llamada Inmunodeficiencia Común Variable (CVID), recomendar las pruebas de laboratorio de seguimiento específicas para confirmarlo y proponer un plan de tratamiento adecuado y basado en la evidencia científica más reciente.
El análisis de estas cuatro tareas revela una verdad fundamental sobre APEX. No es una prueba de conocimiento, sino una evaluación de competencias profesionales holísticas. El éxito exige una amalgama de habilidades: la síntesis de información diversa, el juicio para aplicar el conocimiento correcto al contexto adecuado, el rigor cuantitativo para realizar cálculos precisos y la adherencia a los formatos y convenciones de cada profesión. Demuestra que APEX no es un examen de cultura general para máquinas. Es una simulación del flujo de trabajo profesional, una prueba de la capacidad de la IA no solo para saber algo, sino para aplicarlo correctamente dentro de las restricciones y expectativas de un dominio específico. Esta evaluación multifacética es lo que la convierte en una prueba de inteligencia aplicada mucho más realista, desafiante y, en última instancia, significativa.
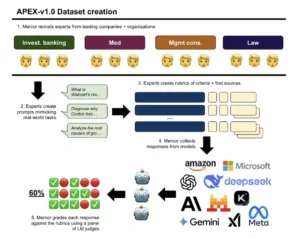
Flujo de trabajo para la creación del Índice de Productividad de IA (APEX-v1.0). Se aplica control de calidad en cada etapa de la producción para garantizar la alta calidad de las indicaciones y rúbricas.
El veredicto de los jueces de silicio
Una vez diseñadas las complejas arenas profesionales, el siguiente desafío era establecer un método de arbitraje que fuera a la vez riguroso, escalable y objetivo. La solución adoptada por los creadores de APEX es tan novedosa como el propio índice: en lugar de depender exclusivamente de evaluadores humanos, un proceso costoso y lento, decidieron formar un jurado poco convencional compuesto por las propias inteligencias artificiales. La idea de que una IA juzgue a otra puede sonar a ciencia ficción, pero el proceso implementado fue de una meticulosidad científica extraordinaria, diseñado para garantizar la fiabilidad y la imparcialidad del veredicto.
El panel de jueces estaba formado por tres modelos de lenguaje de gran tamaño distintos: O3 de OpenAI (con su capacidad de «pensamiento» configurada en bajo), Gemini 2.5 Pro de Google (con el pensamiento desactivado) y Sonnet 4 de Anthropic (también con el pensamiento desactivado). Para cada una de las miles de respuestas generadas por los 23 modelos competidores, y para cada uno de los criterios de la rúbrica correspondiente, estos tres jueces emitían un veredicto independiente de «Cumplido» o «No cumplido». La calificación final para cada criterio se determinaba por mayoría de votos. Si dos o tres jueces estaban de acuerdo, ese era el resultado.
La credibilidad de este sistema de «jueces de silicio» se fundamentó en un exhaustivo proceso de validación. Primero, se midió la consistencia interna de cada juez. Se les pidió que calificaran el mismo conjunto de respuestas tres veces, y los resultados mostraron una coherencia casi perfecta, con más del 99% de acuerdo con sus propios juicios previos. A continuación, se evaluó el acuerdo entre los jueces.
El panel alcanzó un consenso unánime, un acuerdo de 3 a 0, en un impresionante 81.16% de todos los criterios evaluados. Pero la prueba de fuego, el dato que ancla la validez de toda la metodología, fue la comparación con los expertos humanos. Se tomó una muestra de las respuestas y se pidió a los profesionales que las habían diseñado que las calificaran. El resultado fue contundente: las decisiones del panel de jueces de IA coincidieron en un 89% con las calificaciones asignadas por los expertos humanos. Esta elevada correlación validó el enfoque, demostrando que era posible automatizar la evaluación de tareas complejas con un alto grado de fiabilidad.
Con el sistema de arbitraje validado, llegó el momento del evento principal: la evaluación de 23 de los modelos de frontera más avanzados del mundo. Los resultados dibujaron un panorama fascinante del estado actual de la inteligencia artificial. En la cima de la clasificación se situó GPT 5 de OpenAI, con su ajuste de «pensamiento» en alto, logrando una puntuación media del 64.2%. Le seguía un grupo muy compacto de competidores, encabezado por Grok 4 de xAI con un 61.3% y Gemini 2.5 Flash de Google con un 60.4%. La tabla de clasificación reveló una brecha de rendimiento significativa; mientras los líderes superaban el 60%, los modelos en la parte inferior de la lista, como Phi 4 Multimodal de Microsoft, apenas alcanzaban el 20.7%.
La cumbre de APEX v1.0
| Modelo | Proveedor | Puntuación media (%) |
| GPT 5 (Thinking = High) | OpenAI | 64.2 |
| Grok 4 | xAI | 61.3 |
| Gemini 2.5 Flash (Thinking = On) | 60.4 | |
| Gemini 2.5 Pro (Thinking = On) | 60.1 | |
| O3 Pro (Thinking = High) | OpenAI | 60.0 |
| O3 (Thinking = High) | OpenAI | 59.9 |
| Qwen 3 235B | Qwen | 59.8 |
Sin embargo, el titular más importante que se desprende de estos resultados no es quién ocupa el primer puesto, sino la distancia que aún separa a todos los contendientes de la perfección. La conclusión general del estudio es inequívoca: existe una «gran brecha entre el rendimiento de incluso los mejores modelos y los expertos humanos».
Un 64.2% es una puntuación notable, un testimonio del increíble progreso de la tecnología, pero está muy lejos del 100% que representaría una fiabilidad a nivel humano. Este veredicto, emitido por un jurado de silicio pero diseñado y validado por la pericia humana, ofrece la instantánea más clara y honesta hasta la fecha del verdadero potencial, y de las limitaciones actuales, de la inteligencia artificial en el mundo profesional.
Sorpresas y paradojas en la cumbre del rendimiento
Un análisis superficial de la tabla de clasificación de APEX podría llevar a conclusiones simplistas sobre el poder de los modelos de inteligencia artificial. Sin embargo, una inmersión más profunda en los datos revela una serie de hallazgos matizados, contraintuitivos y, en ocasiones, paradójicos. Estas sorpresas desafían muchas de las suposiciones comunes sobre cómo se mide el rendimiento de la IA y sugieren que la carrera por la productividad es mucho más compleja que una simple competición de fuerza bruta computacional.
Una de las revelaciones más llamativas es lo que podría denominarse la «paradoja de los modelos Pro». En la industria tecnológica, es habitual que las empresas ofrezcan versiones «Pro», «Ultra» o «Advanced» de sus productos, modelos supuestamente superiores y, a menudo, más caros, dirigidos a los usuarios más exigentes. Los resultados de APEX, sin embargo, ponen en tela de juicio esta jerarquía.
Por ejemplo, Gemini 2.5 Flash de Google, su modelo más rápido y ligero, obtuvo una puntuación ligeramente superior (60.4%) que su hermano mayor, Gemini 2.5 Pro (60.1%). En el ecosistema de Anthropic, el resultado fue aún más pronunciado: Sonnet 4, considerado menos potente, superó con un 54.4% a su buque insignia, Opus 4, que se quedó en un 53.6%. Incluso dentro de OpenAI, la diferencia entre O3 Pro (60.0%) y su versión estándar, O3 (59.9%), fue prácticamente insignificante.
Este fenómeno sugiere algo profundo sobre la naturaleza del trabajo del conocimiento. Las cualidades que hacen que un modelo sea etiquetado como «Pro», como podrían ser una mayor creatividad, un conocimiento general más amplio o una capacidad conversacional más fluida, no son necesariamente las mismas que se requieren para ejecutar tareas profesionales rigurosas y estructuradas. APEX parece revelar una desconexión entre el marketing de los modelos de IA y su utilidad práctica en dominios especializados. El progreso futuro en la IA para la productividad podría depender menos de simplemente hacer los modelos más grandes y más de afinarlos para formas específicas y económicamente valiosas de razonamiento.
Otro de los grandes relatos que emergen de los datos es el impresionante desempeño de los contendientes de código abierto. En un campo dominado por los gigantes tecnológicos y sus modelos propietarios y cerrados, el modelo Qwen 3 235B, desarrollado por la división de nube de Alibaba, se erigió como una alternativa formidable. Con una puntuación del 59.8%, se situó en un notable séptimo puesto general, codeándose con los modelos de élite de OpenAI, Google y xAI. Este resultado es crucial para el debate sobre la democratización de la inteligencia artificial. Demuestra que el acceso a la tecnología de vanguardia no está, o no estará por mucho tiempo, limitado a un puñado de corporaciones, abriendo la puerta a una mayor innovación y competencia desde todos los rincones del planeta.
Finalmente, el estudio abordó y refutó una hipótesis plausible y potencialmente problemática: la estrategia del «escopetazo» (scattergunning). Cabía la posibilidad de que los modelos pudieran obtener puntuaciones altas no por la calidad de su razonamiento, sino simplemente generando respuestas extremadamente largas y verbosas que, por pura casualidad, acabaran cumpliendo muchos de los criterios de la rúbrica. Si esto fuera cierto, socavaría la validez de todo el índice, premiando la verborrea sobre la precisión.
Los investigadores pusieron a prueba esta idea de forma rigurosa. Realizaron un análisis de regresión para ver si existía una correlación entre la longitud de las respuestas de los modelos y las puntuaciones que obtenían. El resultado fue inequívoco. El análisis arrojó un valor de de solo 0.02, una cifra estadísticamente tan cercana a cero que indica una ausencia casi total de relación. Esta conclusión es robusta: los modelos no ganan en APEX por escribir más, sino por razonar mejor. Este hallazgo no solo valida los resultados de la clasificación, sino que refuerza la idea de que el índice está midiendo con éxito una forma genuina de competencia aplicada.

Mediana, media y desviación estándar de la longitud de las respuestas del modelo en APEX-v1.0, medidas en caracteres y divididas por modelo. Recortamos la media menos la desviación estándar a 0 para facilitar la lectura.
Un espejo de nuestras capacidades
La puntuación global en APEX ofrece una valiosa panorámica del estado de la inteligencia artificial, pero es al desglosar el rendimiento por cada uno de los cuatro dominios profesionales cuando el índice se convierte en un espejo que refleja tanto las fortalezas actuales de la tecnología como las áreas donde aún flaquea. La variación en el desempeño entre los distintos campos no es aleatoria; dibuja un mapa claro de la afinidad de los modelos de lenguaje actuales con diferentes tipos de trabajo del conocimiento, sugiriendo que el camino hacia la integración de la IA en el mundo laboral será profundamente desigual.
El derecho se reveló como el terreno más fértil para las capacidades de la IA. Con la puntuación media más alta (56.9%) y el mejor resultado individual más elevado (GPT 5 alcanzó un 70.5% en esta categoría), los modelos demostraron una notable aptitud para las tareas legales. Esto no es sorprendente. El trabajo jurídico es, en su esencia, una disciplina centrada en el texto: implica leer, interpretar y generar documentos basados en un vasto corpus de información existente, como estatutos, jurisprudencia y contratos.
Esta dinámica de «texto de entrada, texto de salida» se alinea perfectamente con la arquitectura y las fortalezas fundamentales de los grandes modelos de lenguaje. A pesar de este éxito relativo, los expertos señalan que los sistemas actuales todavía se quedan cortos en tareas más matizadas que requieren un juicio más profundo, como la revisión y corrección de cláusulas contractuales complejas (contract redlining) o la redacción de nuevos borradores de regulaciones.
La consultoría de gestión fue el segundo campo con mejor rendimiento, con una puntuación media del 52.6%. Los modelos mostraron una gran competencia en las tareas analíticas centrales de la profesión, como la formulación de estrategias corporativas, la evaluación del rendimiento financiero y la investigación de mercado. Sin embargo, su desempeño fue más débil en áreas que dependen más de la inteligencia interpersonal y la comprensión de la dinámica humana, como la gestión del cambio organizacional o el desarrollo de estrategias de sostenibilidad y gobernanza (ESG), que a menudo implican alinear a múltiples partes interesadas con diferentes sensibilidades.
En el otro extremo del espectro se encontraron la banca de inversión y la medicina, los dos dominios que resultaron ser los más desafiantes para la generación actual de IA, con las puntuaciones medias más bajas, en torno al 47.5%. En medicina, los fallos de los modelos a menudo se debieron a una «falta de profundidad en las respuestas» y a una incapacidad para manejar los matices y las incertidumbres del mundo clínico real.
Aunque pueden recordar datos de libros de texto, luchan por integrar la información de un paciente específico, con sus complejidades y contradicciones, en un plan coherente. En la banca de inversión, que obtuvo la puntuación máxima más baja de los cuatro dominios (un 59.7%), las dificultades parecieron concentrarse en tareas que requieren el manejo de datos no públicos o un conocimiento muy especializado de nichos financieros, como las transacciones de deuda o la financiación de proyectos.
Esta jerarquía de rendimiento (Derecho > Consultoría > Banca/Medicina) ofrece una lección crucial. El grado en que una profesión puede ser aumentada o automatizada por la IA en el corto plazo parece estar directamente relacionado con cuán estructurado y basado en texto es su flujo de trabajo principal. Las profesiones que giran en torno a la síntesis de información textual existente verán una integración más rápida y efectiva de estas herramientas. Aquellas que dependen de un razonamiento multimodal complejo, de la integración de datos numéricos y cualitativos, de la interacción con el mundo físico o de una profunda comprensión del contexto humano, enfrentarán un camino más largo y arduo. APEX, por lo tanto, no solo mide a las máquinas; nos ofrece un reflejo de la estructura de nuestras propias profesiones y nos da pistas sobre dónde la revolución de la IA golpeará primero y con más fuerza.

Correlación entre pares de modelos en APEX-v1.0. Los valores más altos indican mayor similitud. Entre los 23 modelos, existen 253 combinaciones únicas por pares. Los valores varían de 0,39 (para Phi 4 y GPT 5 [Pensamiento = Alto]) a 0,93 (para o3 [Pensamiento = Alto]) y o3 Pro [Pensamiento = Alto]).
Más allá de la puntuación, el futuro del trabajo
Al final de este exhaustivo análisis, queda claro que el Índice de Productividad de la IA es mucho más que una simple tabla de clasificación. Es una herramienta de diagnóstico de una potencia sin precedentes y, lo que es más importante, una hoja de ruta para el futuro del desarrollo de la inteligencia artificial. APEX proporciona una métrica más honesta, fundamentada y útil para medir el progreso, desplazando la conversación desde las capacidades abstractas hacia el valor tangible. Desafía a la industria a construir modelos que no solo sean inteligentes, sino genuinamente útiles.
Con el fin de mantener el rigor científico y la integridad periodística, es fundamental reconocer las limitaciones que los propios investigadores señalan con transparencia. Existe un riesgo inherente de error de medición, dada la dificultad de crear rúbricas perfectas y calibrar a los evaluadores. Además, el sistema actual no penaliza activamente las respuestas que contienen información incorrecta o «alucinaciones», un conocido punto débil de los modelos actuales. Quizás la advertencia más importante es que el valor en el mundo real no es lineal. Una respuesta que obtiene un 60% en APEX no necesariamente ofrece el 60% del valor de un trabajo realizado por un experto humano; en muchos contextos profesionales, una solución parcial o con errores puede ser completamente inútil.
Sin embargo, estas limitaciones no restan valor al proyecto, sino que marcan el camino a seguir. Los planes para el futuro de APEX son tan ambiciosos como su concepción inicial. Las próximas iteraciones buscarán expandir su alcance a una gama más amplia de profesiones, con la ingeniería de software, la enseñanza y el diseño gráfico como candidatos prometedores.
Se planea incorporar el uso de herramientas de software y «salas de datos» virtuales para simular de forma más realista los entornos de trabajo modernos, donde los profesionales interactúan con múltiples aplicaciones y grandes volúmenes de documentos. Además, se pretende enriquecer los datos con etiquetas más granulares, clasificando cada criterio por el tipo de habilidad que evalúa (razonamiento, recuperación de información, seguimiento de instrucciones) para permitir un «análisis de pérdidas» detallado que identifique con precisión quirúrgica las debilidades de cada modelo.
En última instancia, el artículo regresa al punto de partida. La pregunta del billón de dólares sobre la productividad real de la inteligencia artificial sigue sin una respuesta definitiva. Todavía estamos en los albores de esta nueva era, y el camino por recorrer es largo. Pero con APEX, por primera vez, tenemos un marco creíble y riguroso para empezar a encontrar esa respuesta. Nos proporciona un lenguaje común y un estándar objetivo para debatir, medir y guiar el desarrollo de una tecnología que promete remodelar nuestro mundo.
El desafío ya no es solo construir máquinas que nos asombren, sino forjar herramientas que nos empoderen, configurando un futuro en el que la inteligencia humana y la artificial puedan colaborar para resolver los problemas más exigentes y valiosos de nuestro tiempo.
Referencias
Arora, R. K., Wei, J., Soskin Hicks, R., Bowman, P., Quiñonero-Candela, J., Tsimpourlas, F., Sharman, M., Shah, M., Vallone, A., Beutel, A., Heidecke, J., & Singhal, K. (2025). Healthbench: Evaluating large language models towards improved human health.
Becker, J., Rush, N., Barnes, E., & Rein, D. (2025). Measuring the impact of early-2025 ai on experienced open-source developer productivity.
Gema, A. P., Leang, J. O. J., Hong, G., Devoto, A., Mancino, A. C. M., Saxena, R., He, X., Zhao, Y., Du, X., Madani, M. R. G., Barale, C., McHardy, R., Harris, J., Kaddour, J., van Krieken, E., & Minervini, P. (2025). Are we done with mmlu?
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, S., Zhang, K., Wang, Y., Gao, W., Ni, L., & Guo, J. (2025). A survey on llm-as-a-judge.
Kiela, D., Bartolo, M., Nie, Y., Kaushik, D., Geiger, A., Wu, Z., Vidgen, B., Prasad, G., Singh, A., Ringshia, P., Ma, Z., Thrush, T., Riedel, S., Waseem, Z., Stenetorp, P., Jia, R., Bansal, M., Potts, C., & Williams, A. (2021). Dynabench: Rethinking benchmarking in NLP. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4110-4124.
Vidgen, B. et al. (2025) The AI Productivity Index (APEX) Arxiv 2509.25721.
Weidinger, L., Raji, I. D., Wallach, H., Mitchell, M., Wang, A., Salaudeen, O., Bommasani, R., Ganguli, D., Koyejo, S., & Isaac, W. (2025). Toward an evaluation science for generative ai systems.

