
La evolución de DeepSeek es una historia de especialización gradual, construida sobre una base sólida de innovación arquitectónica y una estrategia comercial claramente definida. En lugar de ofrecer un único modelo genérico, la empresa ha desarrollado una gama de productos diseñada para abordar diferentes segmentos del mercado de la IA, desde el investigador individual hasta la aplicación empresarial. Esta diversificación estratégica permite a DeepSeek competir en múltiples frentes, aprovechando las fortalezas de su tecnología central mientras se adapta a las necesidades específicas de cada usuario. Al analizar esta escalera de modelos, desde el V3 básico hasta el experimento radical del V3.2, emerge una visión coherente de una organización que no solo busca emular, sino también rediseñar los estándares de la industria.
El pilar de esta jerarquía es DeepSeek V3, lanzado en diciembre de 2024 . Este modelo representa el hito inicial de su arquitectura de vanguardia. Con 671 mil millones de parámetros en total, activa aproximadamente 37 mil millones por token mediante su arquitectura de Mezcla de Expertos (Mixture-of-Experts, MoE) . Su principal característica es la incorporación del mecanismo Multi- Head Latent Attention (MLA), una innovación clave que reduce drásticamente el uso de memoria durante la inferencia . Fue entrenado en una vasta cantidad de datos, unos 14.8 billones de tokens, lo que le confiere un conocimiento profundo y versátil . Sus métricas de rendimiento son impresionantes: supera a GPT-4o y Claude 3.5 Sonnet en tareas como MMLU y GPQA-Diamond, y alcanza un notable 82.6 en HumanEval, demostrando una capacidad superior en la generación de código en comparación con modelos de código cerrado de la talla de GPT-4o y Claude 3.5 Sonnet. Ofrece una ventana de contexto de 128.000 tokens, suficiente para procesar largas secuencias de texto, aunque fue predecesor de versiones con capacidades aún mayores.
Avanzando en la escala, encontramos DeepSeek V3.1-Terminus, presentado en marzo de 2025. Este modelo marca un salto cuantitativo en la capacidad de contexto, siendo el primer modelo de código abierto en soportar una ventana de hasta 1 millón de tokens. Esta expansión masiva permite procesar volúmenes de información sin precedentes, ideal para tareas como el resumen de libros completos o el análisis de bases de conocimiento extensas. Además de su contexto monumental, V3.1 destaca por mejorar la eficiencia de inferencia, reducir las alucinaciones en un 38% y expandir su soporte multilingüe a más de 100 idiomas Su rendimiento sigue siendo formidable, obteniendo cerca del 87.1% en MMLU y entre el 67% y 70% en HumanEval, situándolo como un competidor directo para los modelos cerrados más avanzados del mercado. Sin embargo, su alto consumo de recursos de hardware lo orienta principalmente a investigadores y desarrolladores experimentados.
Para aquellos cuyas necesidades se centran en el razonamiento lógico y matemático de alta precisión, DeepSeek R1 ofrece una solución altamente especializada. A diferencia de otros modelos, R1 ha sido entrenado específicamente para el razonamiento complejo, utilizando una salida estructurada como JSON para facilitar la integración con sistemas externos . Su principal ventaja competitiva reside en su bajo costo de entrenamiento; según afirma la empresa, se entrenó con solo $6 millones, una fracción del presupuesto de sus competidores estadounidenses. Esto demuestra un enfoque diferente en la optimización, priorizando la eficiencia operativa sobre la escala de parámetros. R1 es una opción open-weight bajo licencia MIT, lo que significa que puede ser utilizado libremente para investigación y desarrollo comercial, aunque con restricciones éticas específicas en su modelo multimodal Janus .
Finalmente, llegamos a DeepSeek-V3.2-Exp, el objeto de estudio central de este informe. Lanzado el 29 de septiembre de 2025, este es un modelo experimental basado en V3.1-Terminus. Su propósito no es introducir una mejora radical en el razonamiento, sino revolucionar la eficiencia computacional, especialmente para contextos largos. Se posiciona como la elección ideal para despliegues API sensibles al coste, aplicaciones web y móviles, y para la investigación que requiera prototipado rápido. Mantiene la robustez de su predecesor en la mayoría de los benchmarks, pero introduce un nuevo mecanismo de atención que promete reducir los costos de inferencia en más de un 50% y mejorar la velocidad de procesamiento hasta tres veces. La existencia de este modelo experimental es crucial: actúa como un campo de pruebas para las futuras versiones oficiales, permitiendo a la comunidad validar la nueva tecnología antes de su implementación generalizada.
|
Característica |
DeepSeek V3 |
DeepSeek V3.1- Terminus |
DeepSeek R1 |
DeepSeek-V3.2- Exp |
|
Fecha de Lanzamiento |
Dic ’24 6 |
Mar ’25 8 |
Ene ’25 10 |
|
Característica |
DeepSeek V3 |
DeepSeek V3.1- Terminus |
DeepSeek R1 |
DeepSeek-V3.2- Exp |
|
Parámetros Totales |
671B 6 17 |
671B 20 |
No disponible |
685B 16 |
|
Parámetros Activados |
~37B 6 17 |
~37B 20 |
No disponible |
~37B 16 |
|
Arquitectura Principal |
MoE + MLA 8 |
Razonamiento Especializado 2 |
||
|
Longitud de Contexto |
1M 8 |
No disponible |
128K – 163.840 |
|
|
Mejoras Clave |
Eficiencia de inferencia, reducción de alucinaciones 8 |
Gran contexto, soporte multilingüe ampliado 8 |
Bajo costo de entrenamiento, salida estructurada 2 |
Reducción de costos >50%, velocidad x2-3 |
|
Modelo Multimodal |
No |
No |
Sí (Janus) 4 |
Sí (Janus) 4 |
Esta pirámide de modelos demuestra una estrategia sofisticada. DeepSeek no solo está compitiendo en el pódium de la inteligencia, sino que también está construyendo las rampas que conducen allí, proporcionando soluciones escalonadas que equilibran rendimiento, costo y especialización. El V3.2- Exp es el último peldaño en esta escalera, diseñado para asegurar que la próxima generación de IA sea no solo más inteligente, sino también más práctica y accesible.
Innovación arquitectónica
El éxito de la familia de modelos DeepSeek no se debe a una simple acumulación de parámetros, sino a una serie de innovaciones arquitectónicas profundas y bien pensadas que abordan los cuellos de botella fundamentales de los grandes modelos de lenguaje: el consumo exponencial de memoria y la lentitud computacional durante la inferencia. Dos de estos mecanismos, Multi-Head Latent Attention (MLA) y la reciente DeepSeek Sparse Attention (DSA), son los protagonistas de esta revolución de la eficiencia. Comprender cómo funcionan es clave para apreciar el valor disruptivo de la oferta de DeepSeek.
El corazón de la eficiencia de los modelos V3 y posteriores es el Multi-Head Latent Attention (MLA). Para entender su importancia, primero debemos visualizar el proceso de inferencia en un modelo de lenguaje autoregresivo. A medida que el modelo genera una oración palabra por palabra, necesita recordar todo lo que ha leído hasta ese momento para mantener el contexto. Este historial se almacena en dos estructuras llamadas «caché de claves» (KV cache), que crecen linealmente con la longitud de la secuencia de entrada. En modelos con atención multi-cabeza estándar (MHA), este caché consume una enorme cantidad de memoria, convirtiéndose rápidamente en el factor limitante para la longitud máxima del contexto y la velocidad de procesamiento.
MLA aborda este problema con una idea elegante: la compresión. En lugar de almacenar todas las claves y valores originales, MLA utiliza matrices de proyección aprendidas para comprimir cada uno de ellos en un vector latente de baja dimensión. Por ejemplo, si originalmente cada clave y valor ocupa 1024 dimensiones, MLA los proyecta a un espacio de solo 128 dimensiones . Esto reduce drásticamente el tamaño del caché KV. En modelos pequeños, se puede lograr una reducción de hasta un 14%, y en modelos de mayor escala, la reducción es del 4%. Sin embargo, la ganancia va más allá de la simple reducción de tamaño. La implementación de MLA incluye un «truco de absorción de pesos» (weight absorption trick). Este truco permite que toda la computación de atención se realice directamente en el espacio latente comprimido, sin tener que reconstruir las claves y valores completos. Esto no solo ahorra memoria, sino que también acelera los cálculos, mejorando la velocidad de inferencia. Sorprendentemente, MLA no sacrifica el rendimiento; incluso supera a la atenta multi-cabeza tradicional (MHA) en ciertos benchmarks, lo que sugiere que la compresión selectiva captura las características más importantes del contexto sin perder información crítica.
Sin embargo, la longitud del contexto sigue siendo un reto. Si bien MLA gestiona eficientemente el caché para una secuencia larga, la primera pasada a través de toda la secuencia es lenta y costosa.
Aquí es donde entra en juego la última innovación, DeepSeek Sparse Attention (DSA), el núcleo del modelo V3.2-Exp. DSA está diseñada específicamente para optimizar las operaciones en contextos extremadamente largos. Su objetivo es reducir la complejidad computacional de la atención, que en los modelos tradicionales es O(Lx), donde L es la longitud de la secuencia. DSA logra esto al realizar una «atención dispersa de grano fino». En lugar de calcular la similitud entre la consulta actual y todas las claves en el caché, DSA primero identifica los fragmentos más relevantes del contexto largo y luego selecciona los tokens individuales dentro de esos fragmentosque son realmente pertinentes para la decisión inmediata. Esto se logra mediante un sistema de «indexador de relámpago» (lightning indexer) y un «sistema de selección de tokens finamente granulados».
La analogía de DeepSeek es útil aquí: imagina intentar encontrar una aguja en un pajar inmensamente grande. Un enfoque de fuerza bruta sería examinar cada hilo del pajar uno por uno, lo cual es muy lento. DSA, en cambio, divide el pajar en secciones, identifica rápidamente las secciones más probables donde podría estar la aguja y luego inspecciona solo unos pocos hilos cuidadosamente seleccionados en esas secciones. Este método radicalmente reduce el número de operaciones matemáticas necesarias, lo que se traduce directamente en una mayor velocidad, menor consumo de memoria y, fundamentalmente, un coste de inferencia mucho más bajo. Según los propios datos de la empresa, DSA puede acelerar la inferencia hasta 2-3 veces, reducir el uso de memoria entre un 30% y un 40% y mejorar la eficiencia del entrenamiento en un 50%. Es importante destacar que, a pesar de esta simplificación drástica, la calidad de salida se mantiene prácticamente intacta, ya que el sistema está diseñado para preservar la información crucial, manteniendo un rendimiento comparable al de su predecesor V3.1-Terminus en la mayoría de los benchmarks críticos.
Estas dos tecnologías, MLA y DSA, trabajan en capas. MLA optimiza la gestión del caché para cualquier secuencia larga, mientras que DSA optimiza la computación misma en la primera pasada a través de un contexto masivo. Juntas, representan un enfoque sistemático para derribar las barreras físicas que han limitado a los modelos de lenguaje durante años. Son las piezas de ingeniería que transforman un monstruo computacional en una herramienta ágil y económicamente viable.
Evaluación de la capacidad intelectual y la estabilidad
Más allá de las innovaciones arquitectónicas, el verdadero valor de un modelo de lenguaje grande reside en su rendimiento en tareas del mundo real. Los benchmarks (pruebas estandarizadas que evalúan habilidades como el razonamiento, la comprensión del lenguaje y la generación de código) son la métrica universal para medir la capacidad intelectual de estos sistemas. La familia de modelos DeepSeek ha demostrado un rendimiento excepcional y constante, estableciendo un nuevo umbral de competencia en el ámbito de los modelos de código abierto. El modelo V3.2-Exp, en particular, se somete a un crucible riguroso para garantizar que sus mejoras de eficiencia no provengan de un sacrificio inaceptable en la calidad.
El modelo base, DeepSeek V3, sentó un precedente elevado. En el benchmark MMLU (Massive Multitask Language Understanding), obtuvo una puntuación de 88.5, y en su versión más difícil, MMLU-Pro, alcanzó el 87.1%. Estos resultados lo sitúan a la cabeza de los modelos de código abierto y lo acercan al nivel de los modelos cerrados de élite como GPT-4o y Claude 3.5 Sonnet. Su dominio es aún más evidente en tareas de razonamiento matemático. Obtuvo un 59.1 en GPQA- Diamond (una prueba de razonamiento lógico complejo) y lideró LiveCodeBench con un 40.5% de precisión. En la generación de código, superó a la competencia en benchmarks tan exigentes como Codeforces y LiveCodeBench, y obtuvo un 82.6 en HumanEval. Versiones posteriores como V3 0324 mostraron una mejora continua, aumentando su puntuación en inteligencia de 46 a 53, y mejorando su velocidad de salida a 31.7 tokens por segundo, aunque con una latencia ligeramente mayor.
Cuando DeepSeek lanzó V3.1-Terminus con su increíble contexto de 1 millón de tokens, muchos temían que la complejidad adicional pudiera afectar negativamente al rendimiento estándar. Sin embargo, la empresa logró un equilibrio notable. Mantuvo una puntuación de rendimiento de alrededor del 87.1% en MMLU, compitiendo directamente con GPT-4.5, y demostró mejoras consistentes en la generación de código, alcanzando entre el 67% y el 70% en HumanEval. Su capacidad para manejar contextos masivos se complementó con una reducción de alucinaciones del 38% y una expansión lingüística que lo hace útil en más de 100 idiomas. Esta capacidad de escalar sin comprometer el núcleo del rendimiento es una muestra de la madurez de su arquitectura.
Aquí es donde el DeepSeek-V3.2-Exp juega un papel crucial. Como un modelo experimental, su principal misión es probar la fiabilidad de su nueva arquitectura de atención dispersa (DSA) sin asumir riesgos comerciales. Para ello, se somete a una evaluación exhaustiva en una batería de benchmarks comunes. Los resultados, publicados por DeepSeek, demuestran una estabilidad asombrosa. El modelo mantiene un rendimiento casi idéntico a su predecesor, V3.1-Terminus, en la mayoría de las pruebas críticas. En MMLU-Pro, ambos modelos se sitúan en torno al 85.0%, con V3.2-Exp ligeramente por detrás en algunas iteraciones. En GPQA-Diamond, la prueba de razonamiento lógico, V3.1-Terminus tiene una ligera ventaja (80.7 vs 79.9), pero la diferencia es mínima. En tareas de matemáticas de alto nivel como AIME 2025, V3.2-Exp incluso muestra una pequeña mejora (89.3 vs 88.4).
La siguiente tabla resume el rendimiento de V3.2-Exp frente a V3.1-Terminus en varios benchmarks:
| Benchmark | V3.1-Terminus Score |
V3.2-Exp Score |
Observaciones | Citas |
| MMLU-Pro | 85.0 | 85.0 | Rendimiento prácticamente idéntico. | |
| GPQA-Diamond | 80.7 | 79.9 | Ligero descenso en una prueba de razonamiento complejo. | |
| Humanity’s Last Exam | 21.7 | 19.8 | Disminución leve. | |
| LiveCodeBench | 74.9 | 74.1 | Rendimiento estable. | |
| AIME 2025 | 88.4 | 89.3 | Mejora ligeramente en problemas de matemáticas avanzados. | |
| HMMT 2025 | 86.1 | 83.6 | Ligero retroceso. | |
| Codeforces | 2046 | 2121 | Mejora en la generación de código. | |
| BrowseComp | 38.5 | 40.1 | Mejora en tareas con herramientas. | |
| SWE Verified | 68.4 | 67.8 | Ligera disminución. |
Análisis detallado de estos datos revela un patrón crucial. Las regresiones observadas (como en GPQA-Diamond o SWE Verified) son, en su mayoría, insignificantes, probablemente dentro del margen de error estadístico. Por otro lado, V3.2-Exp muestra mejoras notables en tareas específicas, como la generación de código (Codeforces) y las tareas agenticas que involucran el uso de herramientas (BrowseComp). Esto sugiere que la nueva arquitectura de atención dispersa, aunque está optimizada para la eficiencia, puede tener un ligero sesgo positivo en ciertas áreas de trabajo. La estabilidad general es, por tanto, excepcional. La conclusión es inequívoca: DeepSeek ha logrado su objetivo dual. Han creado un modelo que es hasta tres veces más rápido y usa hasta un 40% menos de memoria, pero que sigue siendo un competidor fiable y poderoso en el campo de la inteligencia artificial. Este resultado valida la arquitectura y abre la puerta a su despliegue en aplicaciones del mundo real donde la eficiencia es tan importante como el rendimiento.
El impacto económico y operativo
Las innovaciones tecnológicas detrás de DeepSeek no son meras curiosidades académicas; tienen consecuencias profundas y tangibles para la economía de la IA. El costo de entrenar y ejecutar modelos de lenguaje de gran escala ha sido históricamente prohibitivo, actuando como una barrera de entrada que favorece a las grandes corporaciones con vastos presupuestos. La introducción de mecanismos como la DeepSeek Sparse Attention (DSA) representa una amenaza sistémica para este status quo, democratizando el acceso a la IA de alto rendimiento y redefiniendo las dinámicas de mercado. El impacto se manifiesta en tres áreas principales: la reducción de costos operativos, el aumento de la escalabilidad y la alteración de la competencia estratégica.
La consecuencia más directa e inmediata de la eficiencia de DSA es una drástica reducción en el coste de la inferencia. Los modelos de lenguaje consumen recursos computacionales a medida que procesan solicitudes, y la complejidad O(Lx) de la atención tradicional significa que cuanto más larga es la conversación o el documento que se está analizando, más caro se vuelve el servicio. DeepSeek afirma que su DSA puede reducir el coste de una llamada a la API en un 50% en situaciones de
contexto largo. Esta afirmación no es trivial. Por ejemplo, en el caso de un modelo de soporte al cliente que necesita consultar un manual técnico de miles de páginas, la diferencia de coste entre un modelo tradicional y uno optimizado con DSA podría determinar si la implementación es rentable o no. Esta reducción de costes no solo beneficia a los clientes, sino que también otorga a DeepSeek una ventaja competitiva significativa. Pueden ofrecer precios de API más bajos que sus rivales como OpenAI ($30/millón de tokens) y Anthropic (Claude-3.5 a $15/millón). Los precios de V3.2-Exp en plataformas como DeepInfra están en línea con estas afirmaciones, con tarifas de $0.27 por millón de tokens de entrada y $0.40 para la salida, lo que representa una disminución sustancial en comparación con otras opciones de vanguardia.
Más allá de la reducción de costes por solicitud, la eficiencia de V3.2-Exp tiene un impacto profundo en la escalabilidad. La capacidad de procesar secuencias de texto de hasta 163,840 tokens (aproximadamente 400 páginas) con una carga de memoria y CPU significativamente menor permite a las empresas desplegar servicios que antes eran inviables. Imagine una plataforma de investigación científica que puede analizar artículos completos en tiempo real, o un motor de búsqueda semántico que puede indexar y responder preguntas sobre libros enteros. Antes, estos escenarios requerían infraestructuras masivas y costosas. Ahora, gracias a una arquitectura más inteligente, pueden ser ejecutados en hardware más asequible. El repositorio de V3.2-Exp incluso proporciona kernels optimizados para GPUs de alta gama como las H200, indicando que el modelo está diseñado para aprovechar al máximo el hardware moderno, pero sin depender exclusivamente de él .
Este enfoque en la eficiencia también altera la naturaleza de la competencia en la industria de la IA. Tradicionalmente, la carrera ha estado marcada por una «barrera de la escala»: el presupuesto de entrenamiento. El hecho de que DeepSeek haya podido entrenar un modelo de 671 mil millones de parámetros por solo 5.576 millones de dólares en horas de GPU H800 es una demostración contundente de su eficiencia operativa. Y ahora, con V3.2, están extendiendo esa eficiencia a la fase de inferencia. Esto significa que nuevos participantes y organizaciones más pequeñas pueden competir en igualdad de condiciones. Un startup podría utilizar un cluster de servidores relativamente modesto para ofrecer un servicio basado en IA de alta calidad, algo impensable hace solo unos años. Esta democratización de la infraestructura de IA puede llevar a una explosión de innovación, con nuevas aplicaciones y servicios surgidos de comunidades globales de desarrolladores.
Además, la disponibilidad de los pesos del modelo bajo una licencia permissive como la MIT y la publicación de su código fuente en GitHub fomentan aún más la difusión de esta tecnología.
Permite a la comunidad auditar, modificar y adaptar el modelo para sus propias necesidades, acelerando el ritmo de desarrollo. En resumen, la hoja de ruta de DeepSeek no es simplemente una lista de características técnicas. Es un plan estratégico para rebajar los costes de la frontera de la IA y abrir la puerta a una nueva era de aplicaciones prácticas, escalables y económicamente viables. Están cambiando no solo cómo se hacen los modelos de lenguaje, sino quién puede hacerlos y utilizarlos.
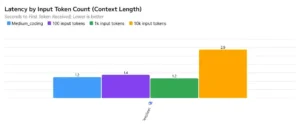
Herramientas para investigadores y desarrolladores
La liberación de un modelo de vanguardia no termina en la publicación de sus pesos. Para que tenga un verdadero impacto, debe ser accesible y fácil de usar para la comunidad de desarrolladores e investigadores que lo adoptarán. DeepSeek ha reconocido esta realidad y ha construido un ecosistema completo en torno a sus modelos, proporcionando múltiples canales de acceso y un conjunto de herramientas robusto para facilitar su despliegue local y en la nube. Este enfoque pragmático garantiza que la tecnología no permanezca confinada en laboratorios, sino que pueda ser integrada en una variedad de proyectos y entornos.
Para los usuarios que desean experimentar con los modelos de forma gratuita o para fines educativos, DeepSeek ofrece acceso a través de plataformas populares. Hugging Face, el epicentro del ecosistema de modelos de código abierto, aloja los pesos de DeepSeek-V3, V3.1-Terminus y V3.2-Exp, permitiendo a cualquier persona descargarlos y comenzar a jugar con ellos. Además, plataformas como DeepInfra ofrecen APIs públicas para acceder a V3.2-Exp, haciendo que la potencia del modelo esté a un paso de cualquier aplicación web o móvil. Esta disponibilidad en Hugging Face es particularmente valiosa, ya que permite a los usuarios crear sus propias aplicaciones interactivas y explorar el comportamiento del modelo en diferentes contextos.
Para los casos de uso más exigentes, como el despliegue en producción o la investigación intensiva, la opción de despliegue local es fundamental. DeepSeek ha proporcionado instrucciones detalladas y herramientas para ejecutar sus modelos en hardware propio. El repositorio oficial en GitHub contiene documentación para configurar el entorno, convertir los pesos del modelo y establecer el paralelismo de modelo necesario para una ejecución óptima. Se recomienda un despliegue local con 8 GPUs H200 o H100 para aprovechar al máximo el rendimiento de V3.2-Exp. El proyecto también se integra con bibliotecas de inferencia de alto rendimiento como vLLM y SGLang, que son esenciales para gestionar la carga de trabajo y maximizar la utilización de la GPU. vLLM, por ejemplo, utiliza la biblioteca DeepGEMM para cálculos de MoE y logits, optimizando aún más la inferencia.
Una de las características más prácticas de la oferta de DeepSeek es la compatibilidad con distintos formatos de precisión para el caché KV, lo que permite un ajuste fino del equilibrio entre rendimiento y consumo de memoria. El modelo V3.2-Exp soporta cachés KV en formato fp8 (punto flotante de 8 bits) o bfloat16 (punto flotante de 16 bits). El fp8 es altamente recomendado para secuencias largas, ya que reduce drásticamente la memoria requerida, mientras que el bfloat16 es más adecuado para peticiones cortas, ofreciendo una mayor precisión numérica. Esta flexibilidad da a los desarrolladores el control para optimizar sus aplicaciones según sus necesidades específicas.
La infraestructura de soporte detrás de todo esto es robusta. El modelo está respaldado por kernels de alto rendimiento en CUDA, incluyendo versiones paginadas para la indexación eficiente y logits, que se publican en repositorios como FlashMLA y DeepGEMM. Estos kernels son el pilar de la eficiencia de V3.2-Exp y son vitales para su rendimiento en la práctica. Además, se han creado imágenes de Docker para facilitar el despliegue en entornos contenedizados en diversos tipos de hardware, como las GPUs H200, MI350 y las NPU de Apple (A2/A3), demostrando un esfuerzo por cubrir una amplia gama de arquitecturas.
En resumen, el acceso a los modelos de DeepSeek es deliberadamente multifacético. Desde la facilidad de uso de Hugging Face para principiantes, hasta la flexibilidad del despliegue local para expertos, y la potencia de las APIs para la producción. La provisión de kernels optimizados y la integración con herramientas de inferencia de vanguardia eliminan muchas de las barreras técnicas que solían impedir la adopción de modelos de esta escala. Esta estrategia de democratización del acceso es tan importante como la propia innovación arquitectónica, ya que garantiza que la tecnología pueda ser cultivada y extendida por una comunidad global de creadores, acelerando así el progreso colectivo en el campo de la IA.
La revolución de la eficiencia y su significado en el mercado global
El lanzamiento de DeepSeek-V3.2-Exp es más que una simple actualización de producto; es un evento paradigmático que refleja una tendencia estratégica más amplia en la industria de la inteligencia artificial. Simultáneamente, la trayectoria de DeepSeek AI, desde su modelo R1 hasta su portentoso V3.1-Terminus, ofrece una perspectiva única sobre las diversas facetas de la innovación en IA y sobre las dinámicas competitivas en un mercado global cada vez más fragmentado. Analizar estos desarrollos revela que la batalla por la supremacía en IA ya no se libra solo en los benchmarks de rendimiento, sino también en la eficiencia de la infraestructura, la estrategia de licenciamiento y la capacidad de adaptarse a un ecosistema de IA en rápida evolución.
En primer lugar, el énfasis de DeepSeek en la eficiencia es un movimiento estratégico de gran alcance. Al resolver los problemas de coste y escalabilidad, la compañía no solo está mejorando su propia posición competitiva, sino que está ayudando a expandir el mercado de la IA de manera general. Al hacer que los modelos de vanguardia sean más económicos, DeepSeek está creando
oportunidades para nuevas aplicaciones que antes eran financieramente inviables. Esto democratiza la tecnología, permitiendo que startups, universidades y empresas de todos los tamaños incorporen capacidades de IA avanzadas en sus productos y servicios. En este sentido, DeepSeek está actuando como un catalizador de la innovación, similar a cómo las compañías de hardware como NVIDIA han impulsado la evolución de la computación gráfica. Su éxito podría llevar a una revalorización general de los estándares de eficiencia en la industria, forzando a otros competidores a invertir en arquitecturas más inteligentes y menos voraces en recursos.
La existencia de una estrategia de «escalera» de modelos, con V3, R1 y Janus, es otra lección estratégica importante. En lugar de apostar todo por un único modelo monolítico, DeepSeek ha optado por una especialización modular. Esta táctica les permite abordar segmentos de mercado dispares con soluciones optimizadas. Mientras que V3 domina en rendimiento general, R1 se enfoca en el nicho de alto rendimiento para razonamiento, y Janus explora el creciente campo de la IA multimodal. Esta diversificación minimiza el riesgo y maximiza la penetración del mercado.
Demuestra una comprensión profunda de que no hay una solución única para todos los problemas de IA. Esta filosofía de especialización puede ser una guía para otras organizaciones que buscan competir con los gigantes de Silicon Valley, mostrando que el éxito no siempre requiere competir en la misma categoría.
Por otro lado, la trayectoria de DeepSeek también ilustra las complejidades de operar en un mercado global polarizado. Fundada en China por Liang Wenfeng, la empresa navega en un ecosistema tecnológico que está cada vez más separado del occidental. Su enfoque en modelos de código abierto con licencias permissive como la MIT es una estrategia astuta. Les permite participar plenamente en el ecosistema global de código abierto, colaborando con la comunidad internacional y beneficiándose de sus contribuciones, al tiempo que se adhiere a las normativas y expectativas de dicho ecosistema. Sin embargo, su modelo multimodal Janus tiene una licencia específica que prohíbe usos militares, de desinformación o dañosos, lo que refleja una toma de posición ética y una posible adaptación a regulaciones internacionales. Este doble rasgo —integración en el mundo de código abierto y adherencia a políticas locales— es el perfil de una empresa que opera en la intersección de dos mundos tecnológicos.
En conclusión, el viaje de DeepSeek desde su modelo R1, entrenado con un presupuesto sorprendentemente bajo, hasta el arrollador V3.2-Exp, que combate la complejidad computacional con ingeniería de software brillante, es un testimonio de la agilidad y la creatividad en la innovación. La compañía no solo está construyendo mejores modelos; está construyendo un ecosistema más eficiente y accesible. El impacto de su enfoque en la eficiencia es tal que podría influir en la dirección de la investigación de IA a nivel mundial, moviendo el foco desde la simple escala hacia una inteligencia más sostenible y económica. El futuro de la IA no será solo más potente, sino también más práctico, y DeepSeek está jugando un papel fundamental en escribir esa próxima página.

Referencia
- Introducing DeepSeek-V3.2-Exp https://api-docs.deepseek.com/news/news250929
- DeepSeek 2 Explicado: Mejoras Clave y Comparación … https://chat4o.ai/es/blog/detail/ DeepSeek-V3-2-Explained-Key-Upgrades-and-Comparison-with-V3-and-R1-3d5687757a34/
- DeepSeek V3-0324: La «actualización menor» que está … https://milvus.io/es/blog/deepseek- v3-0324-minor-update-thats-crushing-top-ai-models.md
- DeepSeek Janus: Arquitectura, Capacidades y Comparativa … https://deepseek-espanol.chat/ blog/deepseek-janus/
- LLM Leaderboard – Comparison of over 100 AI models … https://artificialanalysis.ai/ leaderboards/models
- DeepSeek v3 Review: Performance in Benchmarks & Evals https://textcortex.com/post/ deepseek-v3-review
- deepseek-ai/DeepSeek-V3.2-Exp https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
- (PDF) The Most Advanced AI Models of 2025 -Comparative … https://www.researchgate.net/ publication/392160200_The_Most_Advanced_AI_Models_of_2025_- Comparative_Analysis_of_Gemini_25_Claude_4_LLaMA_4_GPT-45_DeepSeek_V31_and_Oth er_Leading_Models
- DeepSeek releases ‘sparse attention’ model that cuts API … https://techcrunch.com/ 2025/09/29/deepseek-releases-sparse-attention-model-that-cuts-api-costs-in-half/
- DeepSeek tests “sparse attention” to slash AI processing … https://arstechnica.com/ai/ 2025/09/deepseek-tests-sparse-attention-to-slash-ai-processing-costs/
- DeepSeek-V3.2-Exp https://deepinfra.com/deepseek-ai/DeepSeek-V3.2-Exp
- DeepSeek 2 Explicado: Mejoras Clave y Comparación … https://chat4o.ai/es/blog/detail/ DeepSeek-V3-2-Explained-Key-Upgrades-and-Comparison-with-V3-and-R1-3d5687757a34
- DeepSeek-V3 Explained 1: Multi-head Latent Attention https://towardsdatascience.com/ deepseek-v3-explained-1-multi-head-latent-attention-ed6bee2a67c4/
- DeepSeek + SGLang: Multi-Head Latent Attention — Blog https://datacrunch.io/blog/ deepseek-sglang-multi-head-latent-attention
- DeepSeek-V3.2-Exp Usage Guide – vLLM Recipes https://docs.vllm.ai/projects/recipes/en/ latest/DeepSeek/DeepSeek-V3_2-Exp.html
- AI on AI: DeepSeek-3.2-Exp and DSA https://champaignmagazine.com/2025/09/29/ai-on-ai- deepseek-3-2-exp-and-dsa/
- [2412.19437] DeepSeek-V3 Technical Report https://arxiv.org/abs/2412.19437
- DeepSeek Technical Analysis — (2)Multi-Head Latent Attention https:// medium.com/deepseek-technical-analysis-2-mla-74bdb87d4ad2
- DeepSeek-V3 Explained, Part 1: Understanding Multi … https://pub.towardsai.net/deepseek-v3- explained-part-1-understanding-multi-head-latent-attention-bac648681926
- DeepSeek-V3.2-Exp Complete Analysis: 2025 AI Model … https://dev.to/czmilo/deepseek-v32- exp-complete-analysis-2025-ai-model-breakthrough-and-in-depth-analysis-of-sparse-3gcl
- DeepSeek-V3 Technical Report https://arxiv.org/pdf/2412.19437

