
Por Benjamín Vidal, Periodista Especializado en Inteligencia Artificial y Ciencia y Datos, para Mundo IA
Cómo escalar agentes sin tocar el modelo base
Un equipo de UCL y Huawei Noah’s Ark presenta una arquitectura de agentes que mejora en operación sin reentrenar el LLM base. El progreso se apoya en memoria episódica, selección de casos guiada por aprendizaje por refuerzo y un ciclo planner–executor con herramientas. Reportan desempeño líder en GAIA, mejoras consistentes en DeepResearcher y resultados sólidos en SimpleQA y HLE.
La pregunta relevante no es cuántos parámetros tiene el modelo, sino cómo aprende a seguir aprendiendo cuando el entorno cambia. El camino clásico para refinar agentes es ajustar pesos con gradientes, ya sea por entrenamiento supervisado o refuerzo. Eso congela el comportamiento entre versiones y exige cómputo pesado. AgentFly propone otra ruta: adaptación continua sin modificar el LLM. La mejora vive en la orquestación y en la memoria, no en los parámetros. El sistema agrega una memoria episódica, aprende a recuperar experiencias útiles y las aplica para decidir, planificar y ejecutar. El resultado es un agente que incorpora lo que le funcionó y lo que falló, con un costo de iteración mucho menor que el de postentrenar.
Antecedentes y marco
Desde 2023 conviven dos familias de agentes. Por un lado, marcos con flujos fijos y reflexión prefabricada que resuelven tareas acotadas y apenas se adaptan tras el despliegue. Por otro, la actualización paramétrica del modelo base con SFT o RL, que abre posibilidades, aunque demanda curación de datos, infraestructura y controles estrictos para evitar degradaciones. Una tercera vía tomó fuerza: agentes no paramétricos con memorias explícitas, recuperación semántica y reglas tácticas que varían en tiempo de ejecución. AgentFly se instala ahí. Formula la mejora como un problema de selección de casos, trabaja con una política que decide qué experiencias de la biblioteca conviene traer al presente y, sobre esa base, conduce la planificación y la ejecución de subtareas con herramientas.
Cómo funciona
El sistema congela el LLM y desplaza el aprendizaje a una política de recuperación. Formaliza el agente como un proceso de decisión de Markov con memoria. Cada interacción deja una traza con estado, acción, recompensa y resultado. Esas trazas alimentan un banco de casos que se consulta en tiempo real. La política de recuperación se entrena con soft Q-learning sobre ese espacio de experiencias. En la práctica, el flujo tiene dos niveles. Un planificador descompone la meta en subtareas, consulta la memoria para encontrar análogos relevantes y propone un curso de acción. Un ejecutor corre cada subproceso con acceso controlado a herramientas: búsqueda, lectura de documentos, cálculos, ejecución de código, análisis de medios. Al finalizar, el agente escribe de vuelta un resumen de lo que hizo y cómo le fue. Esa disciplina de lectura y escritura mantiene vivo el aprendizaje sin tocar los pesos del modelo base.
El diseño evita dos trampas habituales. Primero, la reflexión rígida. En lugar de forzar cadenas de pensamiento estáticas, selecciona recordatorios concretos de la propia experiencia que son pertinentes a la situación actual. Segundo, el crecimiento caótico de contexto. La política no apila trazas sin criterio. Pondera utilidad y diversidad, limita el número de casos recuperados y favorece ejemplos que, en episodios previos, aportaron señales claras de mejora. La memoria puede ser diferenciable o no diferenciable, con prioridades que se ajustan al dominio.
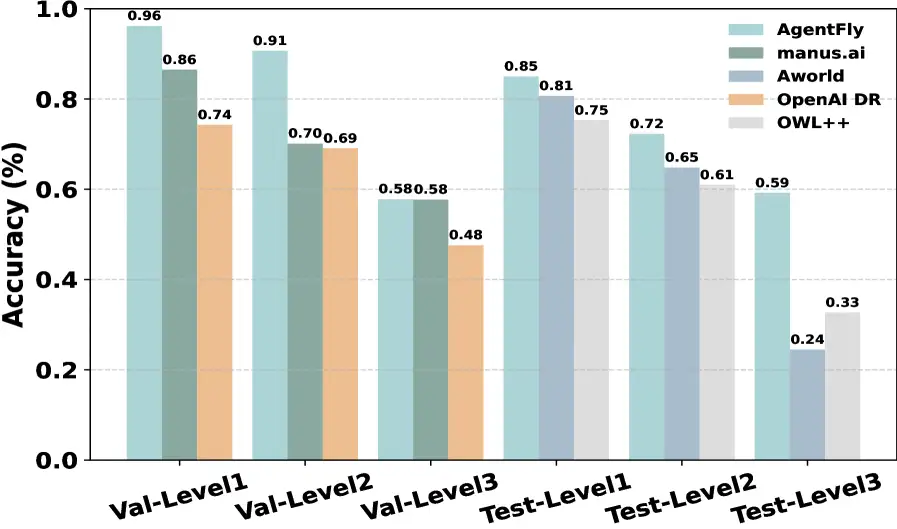
AgentFly logra un rendimiento de vanguardia en el benchmark GAIA, demostrando una precisión superior en diferentes niveles de dificultad en comparación con otros frameworks de código abierto.
Comparaciones y resultados
Los autores reportan mediciones en cuatro bancos de prueba. En GAIA, un benchmark de asistentes con herramientas y tareas de horizonte largo, el sistema alcanza posición de punta en validación y mantiene resultados competitivos en el test público. En DeepResearcher, un conjunto centrado en investigación en la web, muestra mejoras frente a métodos de entrenamiento intensivo, con ganancias adicionales cuando se activa la memoria basada en casos en escenarios fuera de distribución. En SimpleQA, orientado a precisión factual, obtiene un rendimiento alto y estable. En HLE, un conjunto de preguntas académicas de cola larga y cobertura desigual, logra resultados que acercan el desempeño a sistemas de frontera en esa métrica específica. Más allá de los números, el patrón importa: con política de recuperación y memoria explícita, el agente compite contra enfoques que sí actualizan pesos.
Voces y fuentes
El trabajo se presenta como una propuesta de aprendizaje continuo no paramétrico. En los materiales técnicos, la arquitectura planner–executor aparece instrumentada con un planificador de alta capacidad y un ejecutor eficiente, además de un conjunto de herramientas conectadas por una capa MCP. La documentación pública ofrece detalles sobre el banco de casos, las curvas de aprendizaje continuo y ablations que comparan tamaños de memoria, número de casos recuperados y variantes de planificación. También hay un repositorio abierto que, en su documentación, nombra a la implementación como Memento, pese a que el artículo refiere al sistema como AgentFly. El dato práctico para equipos: la canalización está pensada para incorporar nuevas herramientas sin reentrenar, con configuración separada para búsqueda, código, documentos y análisis de medios.
Impactos por sector
En educación, un tutor que mejora a partir de intentos previos puede evolucionar sin presupuestos de entrenamiento. Conserva el modelo congelado y aprende a elegir, de su propia biblioteca de experiencias, qué camino seguir en una nueva consulta. En salud, donde mover datos sensibles para postentrenar representa un riesgo, una arquitectura que no toca pesos minimiza superficies de exposición y traslada el foco a gobernar la memoria y las trazas. En gobierno, un asistente ciudadano puede corregir respuestas imprecisas y reforzar protocolos de verificación sin someterse a ciclos de entrenamiento costosos. En empresas, el ahorro es doble. Bajan los costos de iteración y se gana velocidad para probar nuevos flujos, ya que los cambios viven en políticas, herramientas y memoria, no en el modelo subyacente.
Controversias y vacíos
El enfoque traslada el problema desde el ajuste de parámetros a la gestión de conocimiento operacional. La calidad de la memoria lo es todo. Si las trazas se guardan con etiquetas erróneas, si se seleccionan casos poco representativos o si el banco de experiencias replica sesgos, el agente puede aprender a equivocarse más rápido. La ventana de contexto también es un límite. Aunque la política evita el relleno grosero, el uso de memoria alarga prompts y aumenta la latencia. Conviene medir, para cada dominio, el equilibrio entre más casos recuperados y tiempo de respuesta aceptable. Otro punto a vigilar es la robustez fuera de distribución. GAIA y DeepResearcher presionan esa frontera, pero todavía falta evidencia en entornos híbridos, con humanos en el loop, datos ruidosos y objetivos que cambian sobre la marcha. Por último, la literatura no se ha puesto de acuerdo en cómo auditar memorias de agentes. Qué se almacena, por cuánto tiempo y con qué criterios de expurgado no es un tema resuelto.
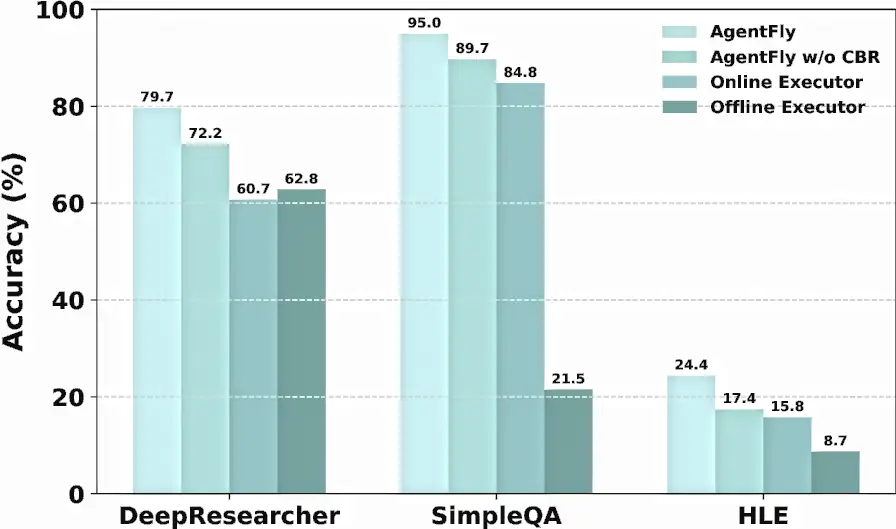
Estudio de ablación que muestra los beneficios incrementales de cada componente en la arquitectura de AgentFly a través de diferentes benchmarks.
Profundización técnica
El corazón del método es una política de recuperación que aprende a elegir ejemplos. Esa política no intenta emular al LLM. Se acopla como una pieza adicional que propone memoria útil. La optimización con soft Q-learning incorpora entropía para favorecer diversidad en la selección y evitar que el agente se quede con una sola plantilla mental. La formulación como M-MDP agrega un espacio de memoria explícito a la dinámica del agente. El estado no es solo el historial inmediato, también incluye el espacio de casos disponibles. La acción no es solo producir texto, también es decidir qué experiencia recuperar. El refuerzo no mide solo acierto final, incorpora señales intermedias que permiten evaluar si el caso elegido ayudó a avanzar.
En el plano de la ingeniería, el sistema separa roles. El planificador descompone y decide. El ejecutor actúa con herramientas, escribe resultados y devuelve observaciones estructuradas. La memoria conserva al menos dos clases de experiencias. Éxitos que conviene replicar y fracasos que conviene evitar. El diseño más efectivo, según los ablations, prefiere memorias pequeñas de alta calidad y recuperaciones concisas. Recuperar cuatro casos bien elegidos supera, de manera consistente, estrategias que inundan el contexto con muchos recordatorios.
Escenarios de adopción
- Corto plazo. Laboratorios y startups que construyen agentes de investigación, soporte y automatización pueden probar una ruta de mejora sin cómputo de entrenamiento. El retorno depende de la disciplina para registrar episodios, etiquetar resultados y medir latencia.
- Mediano plazo. Plataformas que hoy venden agentes parametrizados sumarán la variante de aprendizaje continuo basado en memoria. Aparecerán prácticas de ingeniería dedicadas a gobernar bancos de casos, con políticas de caducidad y limpieza.
- Largo plazo. Si los modelos incorporan memorias paramétricas más maleables, la frontera entre lo paramétrico y lo no paramétrico se va a difuminar. Aun así, la modularidad seguirá siendo valiosa. Separar planificación, ejecución y memoria reduce acoplamientos y simplifica auditoría.
Ética y regulación
Si el modelo no cambia, pero el comportamiento sí, la responsabilidad se desplaza. Habrá que auditar orquestación, memoria y herramientas con el mismo rigor con que se audita el entrenamiento. La memoria puede guardar datos sensibles. Por eso hacen falta políticas de minimización, anonimización y borrado. En servicios públicos y salud, el consentimiento informado debe incluir el uso de interacciones previas como guía para decisiones futuras. Transparencia no es opción. Los usuarios tienen derecho a saber que el sistema usa su historial para decidir y a pedir que su contribución se elimine. La trazabilidad de decisiones exige registros que permitan reconstruir qué casos se recuperaron y por qué se eligieron. El cumplimiento regulatorio deberá reconocer esta clase de agentes. No basta con normar modelos y datasets. Las arquitecturas de memoria y sus políticas también requieren estándares.
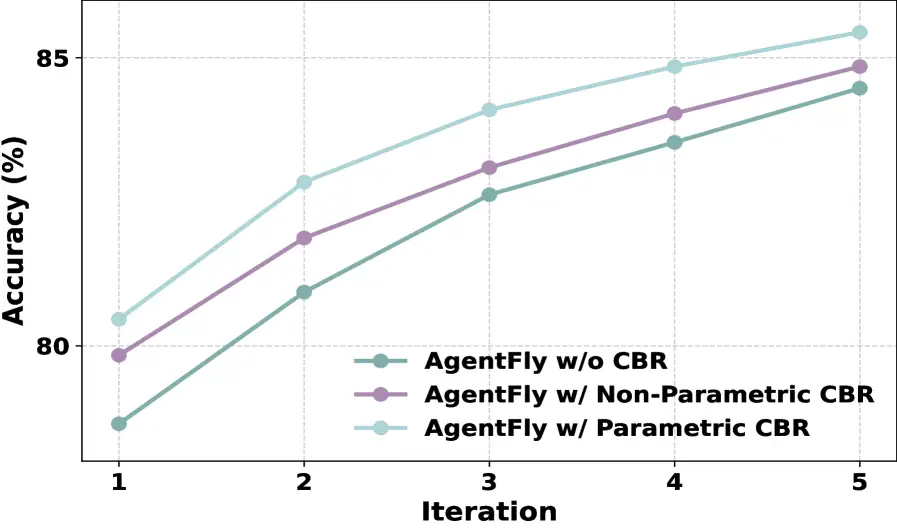
AgentFly muestra una mejora consistente a lo largo de las iteraciones, con el CBR paramétrico y no paramétrico contribuyendo a las ganancias de rendimiento.
Cierre interpretativo
AgentFly recuerda una idea simple. La inteligencia útil no es solo parámetros, también es memoria y método. Si se diseña bien la política de recuperación y el banco de casos, se puede crecer sin tocar el modelo. Ese giro cambia el costo de la mejora y acelera la experimentación. No resuelve todo. Requiere ingeniería paciente, gobierno de datos y métricas que miren más allá del acierto final. Aun así, abre una salida elegante a la hipertrofia de entrenamiento. Aprender en operación, con memoria y política, es una apuesta sensata para agentes que deben vivir en el mundo y no solo en el laboratorio.
Glosario
LLM. Modelo de lenguaje grande, preentrenado en textos masivos.
Ajuste fino. Actualización paramétrica posterior al preentrenamiento con datos específicos.
Agente. Sistema que percibe, decide y actúa con una meta en un entorno determinado.
Traza. Registro de estado, acción, recompensa y resultado de un episodio.
Memoria episódica. Banco de casos con experiencias concretas de éxito y fracaso.
Recuperación. Selección de experiencias relevantes para guiar una decisión actual.
Soft Q-learning. Variante de RL que maximiza una función de valor con término de entropía para promover diversidad de acciones.
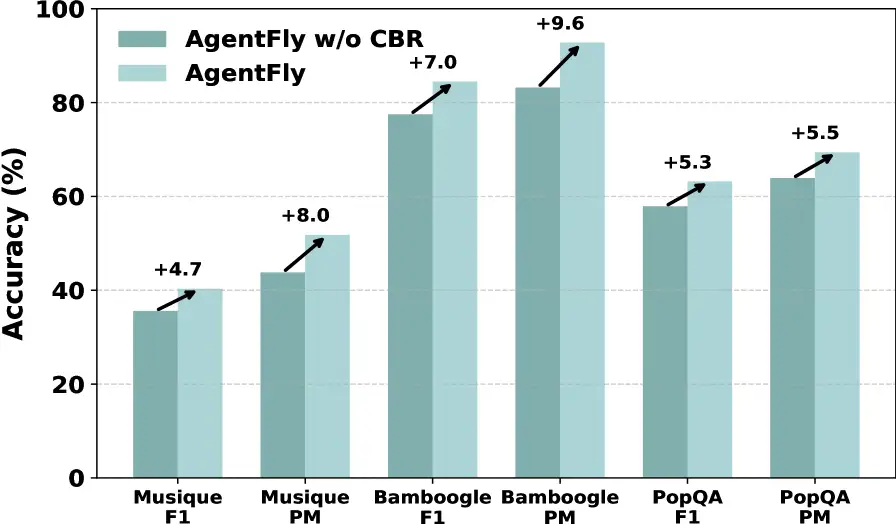
AgentFly demuestra una fuerte generalización a tareas fuera de distribución, con mejoras absolutas que van del 4.7% al 9.6%.
Métricas y benchmarks
GAIA. Desempeño de punta en validación y resultados competitivos en test para tareas con herramientas y horizonte extenso.
DeepResearcher. Mejora sobre sistemas entrenados, con ganancias adicionales en escenarios fuera de distribución al activar memoria basada en casos.
SimpleQA. Precisión alta y estable en consultas factuales.
HLE. Rendimiento comparable a sistemas de frontera en la métrica reportada para razonamiento académico de cola larga.

