
Agentes eficientes: el punto de equilibrio entre inteligencia y costo
El ecosistema de agentes basados en modelos de lenguaje ha crecido hasta convertirse en una de las áreas más dinámicas y prometedoras de la inteligencia artificial contemporánea. Ya no se trata de simples chatbots que responden preguntas, sino de sistemas con capacidad de planificación, razonamiento multi-paso y uso de herramientas externas, capaces de resolver desde búsquedas documentales complejas hasta problemas lógicos que requieren varias iteraciones. La imagen más precisa para describirlos podría ser la de un investigador incansable, que combina memoria, intuición estadística y la capacidad de probar hipótesis en tiempo real.
Pero, como señala el equipo de OPPO AI en su artículo Efficient Agents: Building Effective Agents While Reducing Cost, publicado en arXiv en agosto de 2025, esta inteligencia distribuida no es gratuita. Cada consulta procesada por un gran modelo de lenguaje consume recursos económicos y energéticos considerables, y la suma se vuelve insostenible cuando un agente ejecuta decenas o cientos de pasos para alcanzar un objetivo. La pregunta que guía el trabajo de He Zhu, Wangchunshu Zhou y colaboradores es, entonces, tan simple como crucial: ¿cómo diseñar agentes potentes sin arruinarse en el intento?
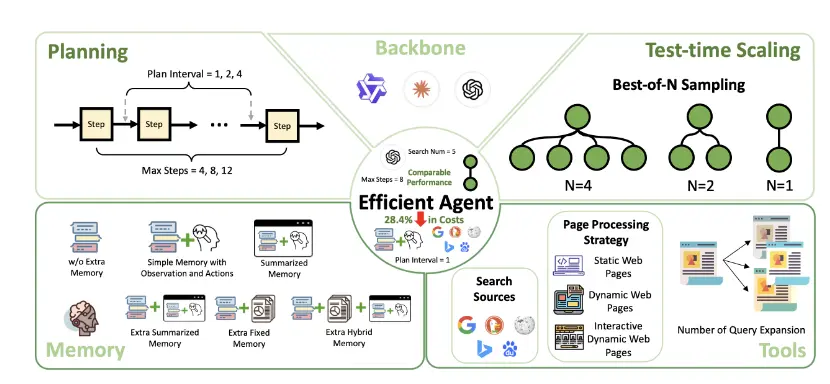
El estudio se apoya en un análisis sistemático que busca medir, con precisión quirúrgica, la relación entre efectividad y coste. Para ello emplean GAIA, un benchmark que exige razonamiento multi-etapa, y una métrica propia, cost-of-pass, que calcula el coste medio de alcanzar una respuesta correcta. No se limitan a medir la tasa de aciertos, sino que introducen un indicador que relaciona ese éxito con el consumo real de tokens, ponderado por el precio que cobran los proveedores de IA comercial. El resultado es una visión más realista de qué significa “eficiencia” en un contexto donde cada token equivale a una fracción de centavo… y a una pequeña cantidad de carbono emitido.
Los hallazgos cuestionan la idea de que un modelo más grande siempre es mejor. Si bien opciones como Claude-3.7 Sonnet logran cifras altas de precisión, su coste por acierto puede multiplicarse varias veces frente a alternativas más modestas. GPT-4.1 emerge como una opción equilibrada: sin ser el más barato ni el más preciso, ofrece un rendimiento suficientemente alto con un coste contenido. Incluso modelos abiertos como Qwen3-30B-A3B, aunque menos precisos, se vuelven atractivos en tareas simples donde la complejidad inherente es baja y no se justifica un gasto mayor.
En la experimentación con estrategias de ejecución, el equipo evalúa configuraciones que van desde aumentar el número de intentos (Best-of-N) hasta variar la frecuencia de planificación y el uso de múltiples motores de búsqueda. Las conclusiones son claras: más intentos no siempre implican mejoras proporcionales; de hecho, a menudo se paga un sobrecoste por incrementos marginales en precisión. La diversidad en las fuentes de información, en cambio, sí ofrece mejoras sustanciales sin disparar el consumo. El mensaje implícito es que la optimización no está en añadir capas indiscriminadamente, sino en seleccionar con cuidado qué componentes se ajustan mejor a la naturaleza de cada tarea.
Un hallazgo particularmente interesante es que la memoria resumida, que en teoría debería agilizar la toma de decisiones, a veces introduce distorsiones que afectan la calidad de la respuesta. En muchos casos, una memoria sencilla —que almacena las acciones y observaciones relevantes sin procesamientos intermedios— logra el mejor balance entre coste y acierto. Esto recuerda que la búsqueda de eficiencia no es solo técnica, sino también conceptual: simplificar puede ser, paradójicamente, una estrategia de sofisticación.
El framework adaptativo que proponen como síntesis de su análisis se comporta como un agente que “elige” su configuración ideal según la complejidad del problema. Frente a benchmarks como GAIA, obtiene resultados cercanos a los mejores agentes de referencia pero con una reducción de coste de casi un tercio. Esto no es un detalle menor: en un escenario de uso masivo, la diferencia puede significar la viabilidad de un proyecto o su inviabilidad económica.
Más allá de sus cifras y tablas, el aporte del paper reside en introducir una métrica que obliga a pensar en términos de sostenibilidad. No basta con lograr el máximo puntaje en un benchmark; el verdadero reto es mantener ese rendimiento sin que cada respuesta tenga un coste desproporcionado. En un momento en que la IA se proyecta como infraestructura global, la eficiencia deja de ser un valor secundario para convertirse en una condición de diseño.
Para quienes trabajan en IA aplicada, la lección es directa: antes de escalar un sistema, hay que conocer su coste real por acierto. Para quienes investigan, el desafío es desarrollar agentes que ajusten su propio consumo de recursos a las exigencias de cada tarea, sin sacrificar la calidad del resultado. Y para la comunidad en general, este tipo de trabajos abre la puerta a un futuro en el que la inteligencia artificial no sea un lujo, sino una herramienta de acceso amplio y sostenido.
La investigación de OPPO AI es, en definitiva, un recordatorio de que el progreso tecnológico no puede medirse solo en términos de capacidad, sino también en su economía interna. La IA que sobrevivirá no será necesariamente la más brillante, sino la que sepa brillar sin derrochar.
Cuando menos es más: casos concretos de eficiencia aplicada
En la teoría, hablar de optimización puede parecer una cuestión de ajustes menores en parámetros y arquitecturas. En la práctica, como evidencia el trabajo de OPPO AI, cada optimización acertada puede significar el salto de un proyecto experimental a una herramienta viable en producción. Veamos algunos escenarios reales donde las conclusiones del paper publicado en arXiv pueden marcar la diferencia.
Un laboratorio farmacéutico que utilice un agente de IA para analizar miles de papers biomédicos y generar hipótesis de nuevas combinaciones de compuestos podría estar gastando cientos de dólares al día en consultas a modelos de lenguaje de gama alta. Adoptar un framework adaptativo que identifique cuándo es suficiente un modelo de menor tamaño —por ejemplo, para filtrar literatura irrelevante antes de pasar a un modelo más potente para el análisis final— puede reducir drásticamente los costes sin perder calidad en los hallazgos críticos. En términos operativos, esto significa que la investigación puede ampliarse en alcance sin multiplicar la factura mensual.
Un caso análogo aparece en el periodismo de investigación, donde un agente diseñado para rastrear información en registros públicos, bases de datos judiciales y hemerotecas podría consumir grandes volúmenes de tokens simplemente intentando validar datos redundantes. Un sistema que, como propone el equipo de He Zhu y Wangchunshu Zhou, detecte tareas de bajo nivel y las derive a modelos más ligeros —o incluso a procesos offline— mantiene el flujo informativo ágil y reduce el gasto de procesamiento.
En empresas de atención al cliente, donde se integran agentes para resolver consultas complejas y gestionar incidencias, el equilibrio entre coste y efectividad se vuelve aún más relevante. Un agente que emplea siempre el modelo más caro para responder a un cliente que solo pide restablecer una contraseña es un desperdicio. Aquí, la adopción de memoria simple y estrategias de planificación optimizadas, tal como recomienda el estudio, puede evitar que miles de interacciones triviales consuman recursos reservados para casos que sí requieren razonamiento complejo.
Implicaciones técnicas y arquitectónicas
El análisis del paper va más allá de la mera comparación de modelos. Su valor está en cómo articula una metodología de experimentación que puede integrarse en cualquier ciclo de desarrollo de agentes. Al aislar variables —cambiando solo un componente a la vez—, permite identificar el impacto real de cada decisión de diseño, desde el número máximo de pasos de planificación hasta el conjunto de fuentes de búsqueda utilizadas. Este enfoque modular es crucial porque rompe con la lógica de “todo o nada” que domina en muchos despliegues de IA.
En términos de arquitectura, el concepto de framework adaptativo que proponen podría convertirse en un patrón de diseño recurrente en la próxima generación de agentes. En lugar de ejecutar siempre con la configuración máxima de potencia, el agente evaluaría la complejidad de la tarea en tiempo real y ajustaría dinámicamente variables como el modelo base, el número de pasos o el uso de herramientas. Esto, además de ahorrar recursos, introduce un comportamiento más “humano” en la toma de decisiones: usar la fuerza bruta solo cuando es estrictamente necesario.
La métrica de cost-of-pass también tiene implicaciones estratégicas. Hasta ahora, muchos benchmarks de IA se han centrado exclusivamente en la precisión o la cobertura. Incorporar el coste por acierto como parámetro de evaluación cambia las prioridades y pone la eficiencia en el centro del diseño. Para desarrolladores de modelos open-source, esto abre un espacio de competencia frente a los modelos propietarios: no siempre se podrá igualar su precisión, pero sí ofrecer una relación coste-beneficio imbatible para tareas específicas.
Un cambio cultural en el desarrollo de agentes
El trabajo de OPPO AI no solo propone mejoras técnicas, sino que señala un cambio cultural necesario. En los últimos años, la comunidad ha estado impulsada por una carrera hacia la mayor capacidad posible, donde los hitos se miden en tokens procesados y capas añadidas. Este estudio recuerda que en muchos contextos reales, la pregunta clave no es “¿podemos hacerlo mejor?” sino “¿podemos hacerlo suficientemente bien… de forma sostenible?”.
Este cambio de enfoque se alinea con las preocupaciones emergentes sobre el impacto ambiental de la IA. Cada token procesado implica consumo eléctrico y emisiones indirectas. Si un framework puede reducir el número total de tokens utilizados sin sacrificar la utilidad de la respuesta, no solo se mejora la rentabilidad, sino también la huella ecológica del sistema. En un escenario donde gobiernos y organismos internacionales empiezan a considerar regulaciones para el uso intensivo de computación, esta eficiencia puede convertirse en un argumento de cumplimiento y responsabilidad corporativa.
No es difícil imaginar cómo las ideas de Efficient Agents pueden integrarse en proyectos actuales. Plataformas como LangChain, LlamaIndex o AutoGen podrían adoptar módulos inspirados en este estudio para seleccionar automáticamente el modelo y la estrategia de ejecución más adecuados para cada tarea. De hecho, frameworks open-source ya han empezado a experimentar con sistemas de enrutamiento de modelos, pero carecen de la base empírica y de la métrica unificada que propone OPPO AI.
En entornos corporativos, la implementación de este tipo de optimizaciones puede ser gradual. Comenzar por medir el cost-of-pass de los agentes existentes ya permitiría identificar áreas de mejora sin rediseñar todo el sistema. A partir de ahí, se pueden introducir cambios como reducir el número de pasos máximos o diversificar las fuentes de búsqueda, siguiendo las recomendaciones extraídas de los experimentos de GAIA.
Hacia dónde se dirige la conversación
Si el procesamiento eficiente se convierte en norma, podríamos ver una bifurcación en el desarrollo de agentes: por un lado, los sistemas de alta potencia reservados para problemas extremadamente complejos; por otro, agentes modulares, más ligeros y especializados, optimizados para tareas concretas. La coexistencia de ambos tipos no sería una limitación, sino una señal de madurez tecnológica: saber cuándo usar una herramienta y cuándo otra es, en sí mismo, un signo de inteligencia.
El artículo de OPPO AI en arXiv no cierra la discusión, sino que abre un campo fértil para futuras investigaciones: métricas de coste ajustadas a dominios específicos, frameworks que aprendan de su propio historial de ejecuciones para refinar configuraciones y, en el plano social, la democratización de agentes que antes solo estaban al alcance de empresas con presupuestos millonarios.
En última instancia, la relevancia de este trabajo radica en que plantea la eficiencia no como una concesión, sino como una virtud central del diseño de IA. Si los próximos años confirman esta tendencia, podríamos asistir a una transición similar a la que se dio en la informática personal: de superordenadores exclusivos a dispositivos accesibles que, con menos potencia bruta, cambiaron radicalmente la forma en que interactuamos con la tecnología.
De DistilBERT a los agentes eficientes: una genealogía de la optimización
Cuando se observa la historia reciente de la inteligencia artificial, salta a la vista que los momentos de ruptura no siempre vinieron por el camino más obvio. En muchos casos, no fueron las arquitecturas más grandes las que marcaron el rumbo, sino aquellas que demostraron que era posible alcanzar resultados competitivos con menos recursos. En 2019, el lanzamiento de DistilBERT por Hugging Face mostró que se podía conservar más del 95% de la precisión de BERT recortando la mitad de sus parámetros. Lo que comenzó como una curiosidad técnica terminó influyendo en toda una ola de modelos más compactos y accesibles.
El patrón se repite: después del auge de los grandes transformadores, llegaron las variantes mixture-of-experts, que distribuyen la carga entre submodelos especializados, activando solo los necesarios en cada consulta. Google, DeepMind y Meta han apostado fuerte por esta idea, que no busca romper récords de tamaño, sino modular el uso de recursos. El estudio de OPPO AI se inscribe en esa misma tradición: demostrar que la inteligencia no es solo una cuestión de fuerza bruta, sino de estrategia.
El problema de desplegar siempre el modelo más caro es una especie de “paradoja de la potencia desaprovechada”. La mayoría de las tareas no requieren toda la capacidad de un LLM de última generación, y, sin embargo, las implementaciones actuales rara vez discriminan. Esto es como conducir un coche de Fórmula 1 para ir al supermercado: impresiona, pero es ineficiente y costoso.
En el caso de los agentes, esta sobrecarga no es solo económica, sino que introduce latencias innecesarias y desperdicia oportunidades de respuesta más ágil. La propuesta de Efficient Agents rompe con esta inercia: medir el coste real por acierto (cost-of-pass) fuerza a cuestionar la necesidad de mantener la potencia máxima siempre encendida.
La eficiencia como motor de adopción masiva
Si la primera etapa de la IA moderna estuvo marcada por la fascinación con lo posible, la siguiente lo estará por la responsabilidad de lo viable. Un asistente autónomo capaz de planificar y ejecutar tareas complejas no es útil si su coste lo hace inviable para una pyme o para un equipo de investigación con presupuesto limitado. El salto cualitativo que propone OPPO AI es doble: por un lado, permite a organizaciones medianas acceder a herramientas antes reservadas a corporaciones; por otro, abre la puerta a modelos de negocio sostenibles en el tiempo.
En este sentido, el paralelismo con la historia de la computación personal es claro. En los años 70 y 80, el avance no fue crear supercomputadoras más potentes, sino dispositivos lo suficientemente capaces para llegar a millones de usuarios. La democratización de la IA podría seguir ese mismo camino: menos ostentación en métricas máximas, más atención a la relación entre coste, utilidad y disponibilidad.
Mirando hacia adelante, no es difícil imaginar una siguiente generación de agentes que integren aprendizaje metacognitivo: sistemas capaces de analizar su propio rendimiento y ajustar sus configuraciones en tiempo real según el tipo de problema, la disponibilidad de recursos y el nivel de precisión exigido. Un agente podría decidir, por ejemplo, empezar con un modelo liviano para explorar soluciones rápidas y, solo si detecta que la tarea se complica, escalar automáticamente a un modelo más potente.
La infraestructura necesaria para esto ya está en gestación. Lenguajes y frameworks como LangChain o AutoGen ofrecen la modularidad que permitiría implementar esta adaptabilidad. Lo que falta es estandarizar métricas como el cost-of-pass para que estas decisiones no dependan de intuiciones o aproximaciones, sino de datos cuantificables y replicables.
La huella invisible: sostenibilidad y ética
En un momento en que la IA empieza a ser examinada no solo por lo que puede hacer, sino por su impacto ambiental y social, la eficiencia deja de ser un criterio técnico para convertirse en un valor ético. Cada optimización que reduce el consumo de tokens no solo ahorra dinero, sino que disminuye la huella de carbono asociada al uso de centros de datos. Esto, en contextos donde la regulación sobre el impacto climático de la computación empieza a ser considerada, podría marcar la diferencia entre una tecnología permitida y una restringida.
El punto de inflexión
En definitiva, Efficient Agents no es solo un estudio técnico: es una declaración sobre el futuro del diseño de IA. Al igual que DistilBERT mostró que se podía comprimir sin destruir la esencia, y las arquitecturas mixture-of-experts enseñaron que se podía seleccionar sin perder coherencia, este trabajo abre una ruta para que los agentes sean tan inteligentes en su uso de recursos como en su capacidad de razonar.
Si la IA de la próxima década va a estar presente en todas partes —desde dispositivos domésticos hasta sistemas críticos de infraestructura—, no será por el tamaño de sus modelos, sino por la inteligencia con la que se diseñen. En ese sentido, este paper de OPPO AI es, más que una optimización, una lección de humildad tecnológica: el futuro no se gana con músculo, sino con precisión.

