
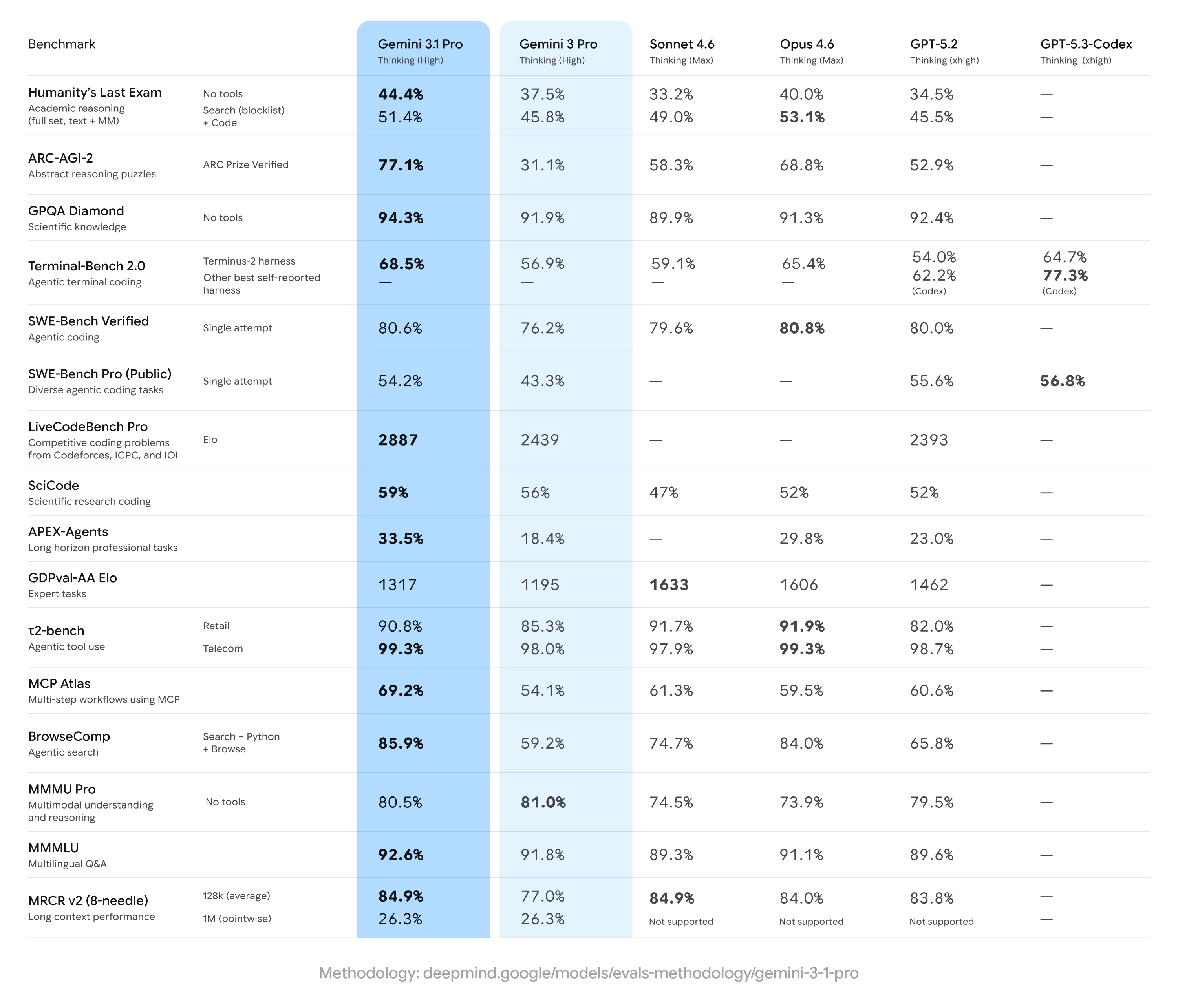
Hay marcadores que uno espera ver moverse despacio. El ARC-AGI-2, diseñado como una prueba deliberadamente resistente a la memorización, es uno de ellos. No mide cuánto sabe un sistema; mide cuánto puede razonar sobre algo que nunca antes vio. Cuando Gemini 3 Pro, lanzado en noviembre de 2025, obtuvo un 31,1% en ese test, el resultado fue considerado sólido para los estándares del campo. Tres meses después, Gemini 3.1 Pro no lo mejoró marginalmente: lo duplicó, con un 77,1% verificado por el ARC Prize.
La cifra fue publicada este 19 de febrero de 2026 junto al lanzamiento oficial del modelo. Logan Kilpatrick, responsable de producto para la API de Gemini en Google, describió a 3.1 Pro no como una versión de mantenimiento sino como "la inteligencia central actualizada que hace posibles los avances recientes", una formulación que el mercado tardó minutos en traducir a términos más directos: el modelo más capaz que Google ha puesto en circulación amplia hasta la fecha. La cadencia del progreso resulta tan comprimida que cuesta distinguir si se está ante una actualización incremental o ante un salto cualitativo disfrazado de número de versión.
La secuencia de lanzamientos del último trimestre da contexto a lo que ese porcentaje significa en perspectiva histórica. Gemini 3 Pro llegó en noviembre con un rendimiento en GPQA Diamond de 91,9%, superando por primera vez el umbral de expertos humanos en razonamiento científico profundo, y se convirtió en el primer sistema en superar los 1.500 puntos en el índice LMArena Elo. En diciembre, Deep Think, el modo de razonamiento iterativo que evalúa múltiples hipótesis en paralelo antes de entregar una respuesta, elevó la puntuación en ARC-AGI-2 a 45,1% con ejecución de código. Luego llegó febrero y 3.1 Pro borró ese techo sin que nadie en el sector lo hubiera anunciado con suficiente anticipación.
El examen que los modelos no pueden estudiar
La razón por la que ARC-AGI-2 ocupa un lugar tan central en el debate técnico es precisamente su naturaleza. A diferencia de los benchmarks convencionales, no puede ser "aprendido" acumulando más datos de entrenamiento. Cada tarea presenta un conjunto de patrones visuales abstractos que el sistema nunca antes vio y debe resolver por inferencia pura, sin atajos mnemónicos ni memorización encubierta. François Chollet, el ingeniero que diseñó el test original, lo concibió como una aproximación mínima al tipo de generalización que distingue la inteligencia humana cotidiana: identificar reglas a partir de muy pocos ejemplos y aplicarlas a situaciones completamente nuevas.
Con un 77,1% verificado, Gemini 3.1 Pro coloca a Google en una posición nítidamente adelantada respecto de sus dos principales competidores en ese indicador. Claude Opus 4.6, el modelo de referencia de Anthropic en el segmento premium, registra un 68% en la misma prueba. GPT-5.2, la versión más reciente de OpenAI en el mercado, alcanza el 52,9%. La distancia no es marginal y en un campo donde las mejoras suelen medirse en décimas de punto porcentual, una separación de casi nueve puntos sobre el segundo lugar tiene un peso real que trasciende la estadística.
El panorama se replica en Humanity's Last Exam, una prueba de conocimiento académico profundo en áreas tan dispares como biología molecular, teoría de juegos y literatura comparada. Gemini 3.1 Pro obtiene un 44,4%, contra el 40% de Claude Opus 4.6 y el 34,5% de GPT-5.2. Hay matices relevantes que el marcador global no captura del todo: en generación de código aplicado a proyectos reales, medida por SWE-Bench Verified, Claude 4.5 Sonnet conserva un liderazgo propio con cifras cercanas al 77%. En velocidad de respuesta para tareas de alta frecuencia, GPT-5.2 mantiene ventajas operativas que importan en ciertos flujos de trabajo específicos. Pero en las dimensiones que los investigadores consideran más cercanas a un razonamiento genuinamente nuevo, la brecha abierta por 3.1 Pro es tan amplia que difícilmente se cierre sin una actualización de fondo por parte de sus rivales.
Del código al cosmos: lo que 3.1 Pro puede construir hoy
Las demostraciones publicadas por Google DeepMind el día del lanzamiento evitaron deliberadamente el tono de las presentaciones de laboratorio. En lugar de mostrar respuestas a preguntas académicas descontextualizadas, el equipo documentó cuatro casos de uso concretos, pensados para ilustrar cómo el salto en razonamiento abstracto se convierte en capacidad productiva tangible.
El más llamativo visualmente fue la generación de archivos SVG animados directamente desde instrucciones de texto. A diferencia de los formatos de video o las imágenes convencionales, estos archivos se construyen en código puro, lo que los mantiene nítidos a cualquier escala con tamaños de archivo mínimos, una ventaja concreta para desarrollo web. El segundo ejemplo fue más conceptualmente ambicioso: la construcción de un tablero aeroespacial en tiempo real que conecta con el flujo público de telemetría de la Estación Espacial Internacional. El modelo configuró la integración de la API, diseñó la interfaz y la desplegó en forma completamente funcional, una tarea que en condiciones normales requiere la coordinación de al menos dos perfiles técnicos distintos operando en secuencia.
La tercera demostración mostró una murmuración de estorninos en 3D con física de bandada, interacción mediante seguimiento de manos y una partitura generativa que responde al comportamiento del conjunto en tiempo real. El cuarto caso fue el más literario: construir un portfolio personal moderno para la protagonista de "Cumbres Borrascosas", razonando sobre el tono atmosférico de la novela antes de traducirlo en decisiones de diseño concretas. Lo que une a los cuatro ejemplos no es la complejidad técnica aislada de cada uno sino la capacidad de mantener coherencia a lo largo de múltiples pasos de razonamiento encadenado sin intervención humana intermedia. En el lenguaje del campo eso se denomina capacidad agéntica y constituye el eje competitivo sobre el que Google ha decidido apostar con más fuerza de aquí en adelante.
La disponibilidad del modelo en Antigravity, la plataforma de desarrollo agéntico de Google, junto con Android Studio y la Gemini CLI, subraya que la apuesta no es solo de rendimiento en benchmarks sino de posicionamiento arquitectónico dentro del ecosistema de herramientas para desarrolladores. Antigravity fue concebida como el entorno donde los flujos de trabajo más exigentes, aquellos que requieren que un sistema tome decisiones en cadena sobre múltiples herramientas y fuentes de datos simultáneos, encontrarán a 3.1 Pro como capa de razonamiento subyacente.
Un ecosistema que crece más rápido que sus propios planes
El lanzamiento de 3.1 Pro tiene una particularidad que lo distingue de las actualizaciones anteriores de la familia Gemini: ocurre en modo preventivo. En lugar de esperar a que el modelo esté disponible de forma general en todos los canales, Google lo publicó hoy en vista previa para validar las mejoras junto con la comunidad de desarrolladores antes de una distribución completa. El movimiento refleja tanto la velocidad del ciclo competitivo como una lección aprendida en ciclos anteriores: los modelos se afinan más rápido cuando miles de casos de uso reales los tensionan desde el primer día, con retroalimentación real en lugar de condiciones de laboratorio.
La cobertura es simultánea en múltiples vectores. Para consumidores, el modelo llega a la aplicación Gemini con límites más amplios para suscriptores de Google AI Pro y Ultra, y a NotebookLM exclusivamente para esos mismos planes. Los desarrolladores pueden acceder a través de la Gemini API en AI Studio, la Gemini CLI y la plataforma Antigravity. Las empresas cuentan con disponibilidad en Vertex AI y Gemini Enterprise. Para ser un lanzamiento en vista previa, la extensión del despliegue es inusualmente amplia.
NotebookLM merece una mención específica dentro de este mapa. La herramienta de análisis y síntesis de documentos extensos ha crecido sostenidamente desde su expansión en 2024, y la incorporación de 3.1 Pro como motor subyacente la convierte en uno de los productos más capaces del mercado para trabajo con información densa y de múltiples capas. Académicos, investigadores y equipos editoriales que ya utilizan la plataforma encontrarán un salto perceptible en la calidad de las síntesis y en la precisión de las respuestas ante preguntas complejas sobre documentos de gran extensión.
El paso siguiente, según lo anticipado por el propio equipo de DeepMind, es la disponibilidad general del modelo una vez completada la fase de validación en curso, con expansión de las capacidades agénticas prevista antes de ese lanzamiento definitivo. La señal es clara: el laboratorio considera el razonamiento extendido y autónomo como la característica estructural que definirá la frontera tecnológica en 2026, no como una función adicional de segundo orden sino como la columna vertebral de la competencia entre los sistemas más capaces del mercado. En un campo donde tres meses son suficientes para que un marcador se duplique, esa apuesta tiene fecha de vencimiento más corta de lo que cualquier hoja de ruta oficial podría garantizar con certeza.
Referencias
Google DeepMind, "Gemini 3.1 Pro: A smarter model for your most complex tasks" — blog.google, 19 de febrero de 2026. Anuncio oficial de lanzamiento con descripción de capacidades, casos de uso documentados y resultados en benchmarks.
Google DeepMind, página oficial del modelo Gemini 3.1 Pro — deepmind.google/models/gemini/pro. Tabla completa de resultados verificados en ARC-AGI-2, Humanity's Last Exam y otros indicadores de razonamiento.
Mashable, "Google releases Gemini 3.1 Pro: Benchmarks, how to try it" — 19 de febrero de 2026. Cobertura de los resultados comparativos frente a Claude Opus 4.6 y GPT-5.2.
Gemini Apps Release Notes — gemini.google/release-notes. Registro oficial de actualizaciones, incluyendo el despliegue de Gemini 3 Deep Think el 4 de diciembre de 2025 para suscriptores Google AI Ultra.
The Rift AI, "Google DeepMind Rolls Out Gemini 3 Deep Think Mode for Advanced Parallel Reasoning" — diciembre de 2025. Análisis del modo Deep Think, su arquitectura de hipótesis paralelas y su impacto competitivo inmediato.
Passionfruit, "GPT-5.1 vs Claude 4.5 vs Gemini 3 Pro vs DeepSeek-V3.2: The Definitive 2025 AI Model Comparison" — enero de 2026. Comparativa independiente de rendimiento entre los modelos de frontera en tareas de razonamiento, código y multimodalidad.
ARC Prize Foundation, Leaderboard público — arcprize.org/leaderboard. Registro de puntuaciones verificadas en ARC-AGI-1 y ARC-AGI-2, con metodología de validación independiente.

