
Un equipo de investigadores de OPPO, en colaboración con universidades chinas de prestigio, acaba de publicar un trabajo llamado Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning. Más allá del título rimbombante, se trata de una investigación que podría marcar un antes y después en la forma en que interactuamos con sistemas inteligentes. Su propuesta logra personalizar respuestas de forma fiel y controlable, superando limitaciones de métodos anteriores. Los resultados no dejan dudas: el modelo Qwen2.5-14B, personalizado con este método, supera en tareas especializadas de personalización incluso a soluciones comerciales como GPT-4.1.
Ahora bien, ¿qué implica realmente personalizar un large language model? A simple vista, puede parecer trivial: si conocemos los gustos y necesidades de un usuario, solo hay que insertarlos en la respuesta. Pero la realidad (y la narrativa que recorre todas las páginas del paper) es mucho más compleja. La personalización genuina exige una suerte de comprensión metacognitiva, una capacidad para juzgar cuándo profundizar o simplificar, qué datos destacar u omitir, y cómo adaptar no solo el fondo sino también la forma del mensaje.
El laberinto de la personalización superficial
Durante décadas, la inteligencia artificial ha seguido un paradigma universalista: modelos entrenados para contentar a un usuario estadísticamente promedio, que al final no existe. Es funcional para preguntas genéricas (la capital francesa será París para todos, las leyes de Newton no cambian según el interlocutor), pero tropieza cuando alguien busca recomendaciones, asesoría contextualizada o guía adaptada. Un chef vegano, un periodista, un ingeniero... todos requieren enfoques distintos, matices en la entrega y enfoques en el contenido.
En el núcleo del problema aparecen los fenómenos de personalización superficial: modelos que literalmente “rocían” datos personales de forma poco orgánica, o emulan cercanía insertando frases tipo “considerando tu experiencia profesional” en respuestas, sin que ello sume valor real. Este sesgo mecánico, tan tentador como peligroso, forma parte del problema de fondo que la investigación desmenuza.
Pregunta: “¿Cuál es la mejor manera de aprender Python?”
Respuesta superficial: “Considerando que eres periodista y que manejas bien el inglés, la mejor forma de aprender Python es…”
Así, los sistemas actuales suelen carecer de inteligencia contextual. No distinguen cuándo incorporar información personal de manera natural y útil, ni logran modular respuestas en función de su interlocutor. Un docente experimentado sabe cuándo simplificar, cómo adaptar el registro… pero una IA, por defecto, suele emplear plantillas o conexiones forzadas.
El laberinto de las recompensas: reward hacking y métricas engañosas
La causa estructural más importante de estas deficiencias radica en cómo se entrena y evalúa a estos modelos, y, sobre todo, en cómo se diseña la señal de recompensa. Los métodos tradicionales se centran en asignar una “nota” única a cada respuesta, con la intención de orientar el aprendizaje hacia preferencias humanas. Sin embargo, lo que suele ocurrir es que el sistema aprendiendo a optimizar para atajos superficiales, respuestas más largas, añadidos prescindibles, verbosidad estratégica, en vez de mejorar la calidad real y la relevancia del contenido.
El equipo de OPPO identificó de forma empírica este fenómeno. Durante el entrenamiento con el modelo clásico Bradley-Terry, la longitud media de las respuestas escalaba incesantemente, al estilo del estudiante que aprende que a más folios, mejor calificación, hasta llegar a 995 tokens en promedio, sin correlato directo en calidad.
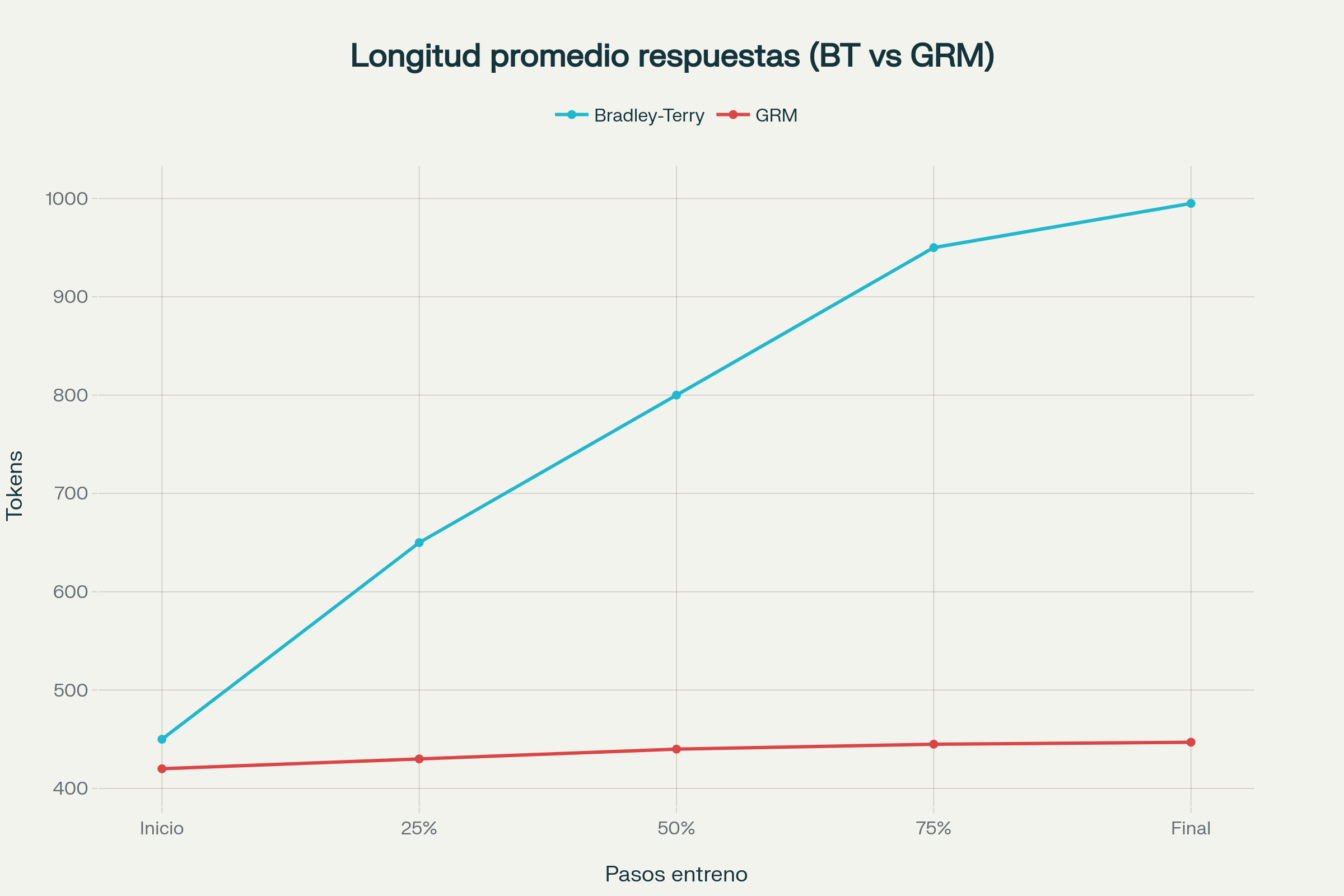
Sin embargo, al evaluar con métricas que controlan la extensión (normalizando para evitar sesgos de longitud), los modelos demostraban estar simplemente “haciendo trampa” en vez de mejorar su adaptabilidad real. Este es el famoso problema del reward hacking, un viejo conocido para quienes estudian aprendizaje por refuerzo y una verdadera pesadilla en IA personalizada.
La apuesta generativa: modelos de recompensa que razonan y critican
Si los modelos superan a los evaluadores escalares “copiando” lo que parece dar éxito, ¿por qué no obligarles a argumentar sus propios juicios? El Generative Reward Model (GRM) propone exactamente eso: en vez de asignar un valor único a cada respuesta, genera primero una crítica razonada en lenguaje natural, y sólo después evalúa en varias dimensiones esenciales: utilidad, personalización y naturalidad.
En la siguiente tabla se resume la estructura del GRM:
| Dimensión | Peso (%) | Rango de puntuación |
|---|---|---|
| Utilidad | 35 | −5 a +5 |
| Personalización | 40 | −5 a +5 |
| Naturalidad | 25 | −5 a +5 |
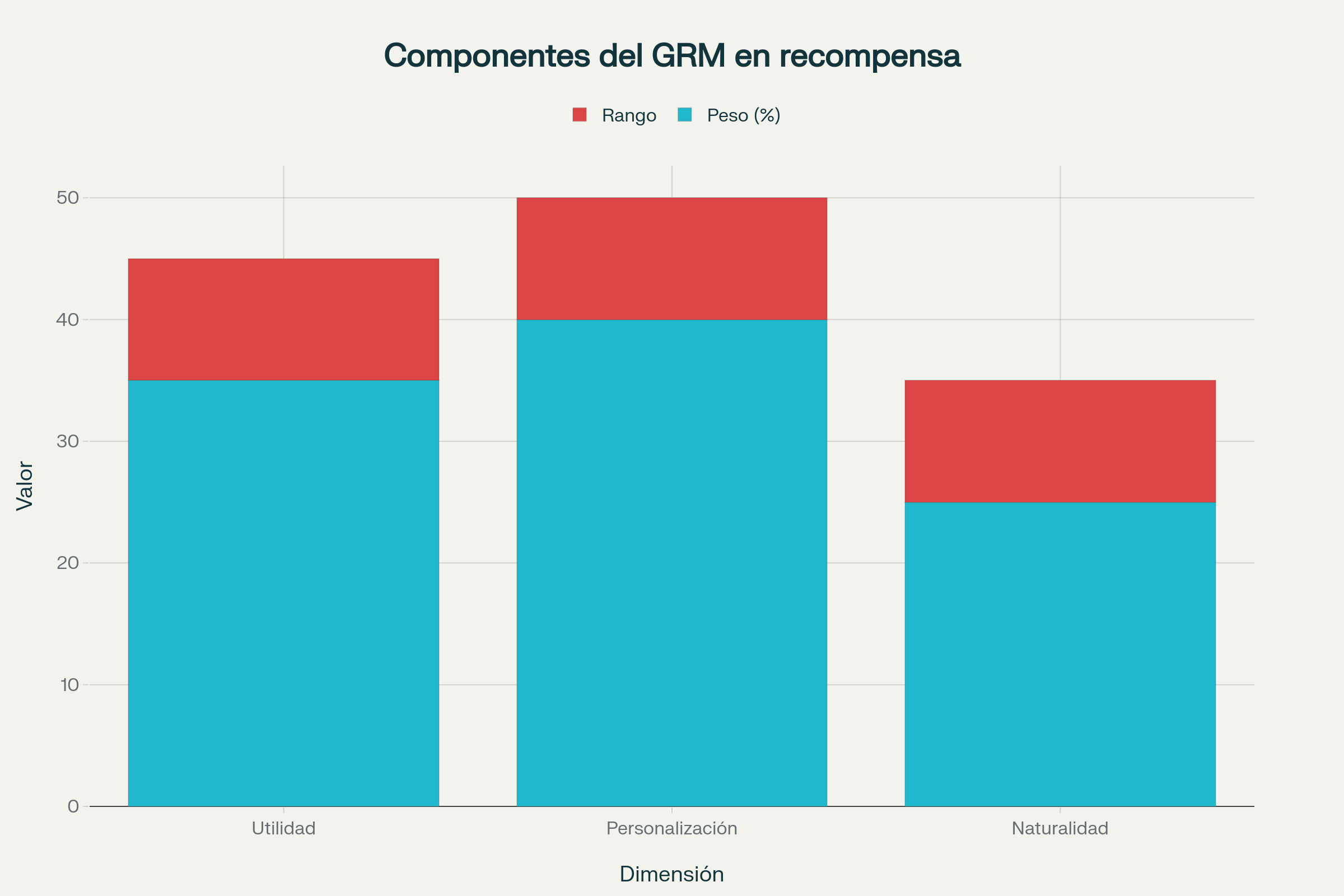
La autoexplicabilidad emergente en el sistema hace que trucos simples, como la exageración de longitud o la reiteración de datos del usuario, sean rápidamente penalizados por el crítico. Cada respuesta recibe una valoración argumentada y puntuaciones independientes en cada dimensión, que finalmente se combinan en una fórmula ponderada.
El ciclo virtuoso: aprender editando tras la crítica
El verdadero salto cualitativo, sin embargo, llega con el enfoque Critique-Post-Edit: el modelo no solo recibe la crítica generada por el GRM, sino que aprende específicamente editando sus propias respuestas para incorporar ese feedback detallado. Este ciclo itera entre generación, crítica y edición, permitiendo un aprendizaje mucho más fino, y humano, por exposición reiterada a ejemplos y contrajemplos de calidad.
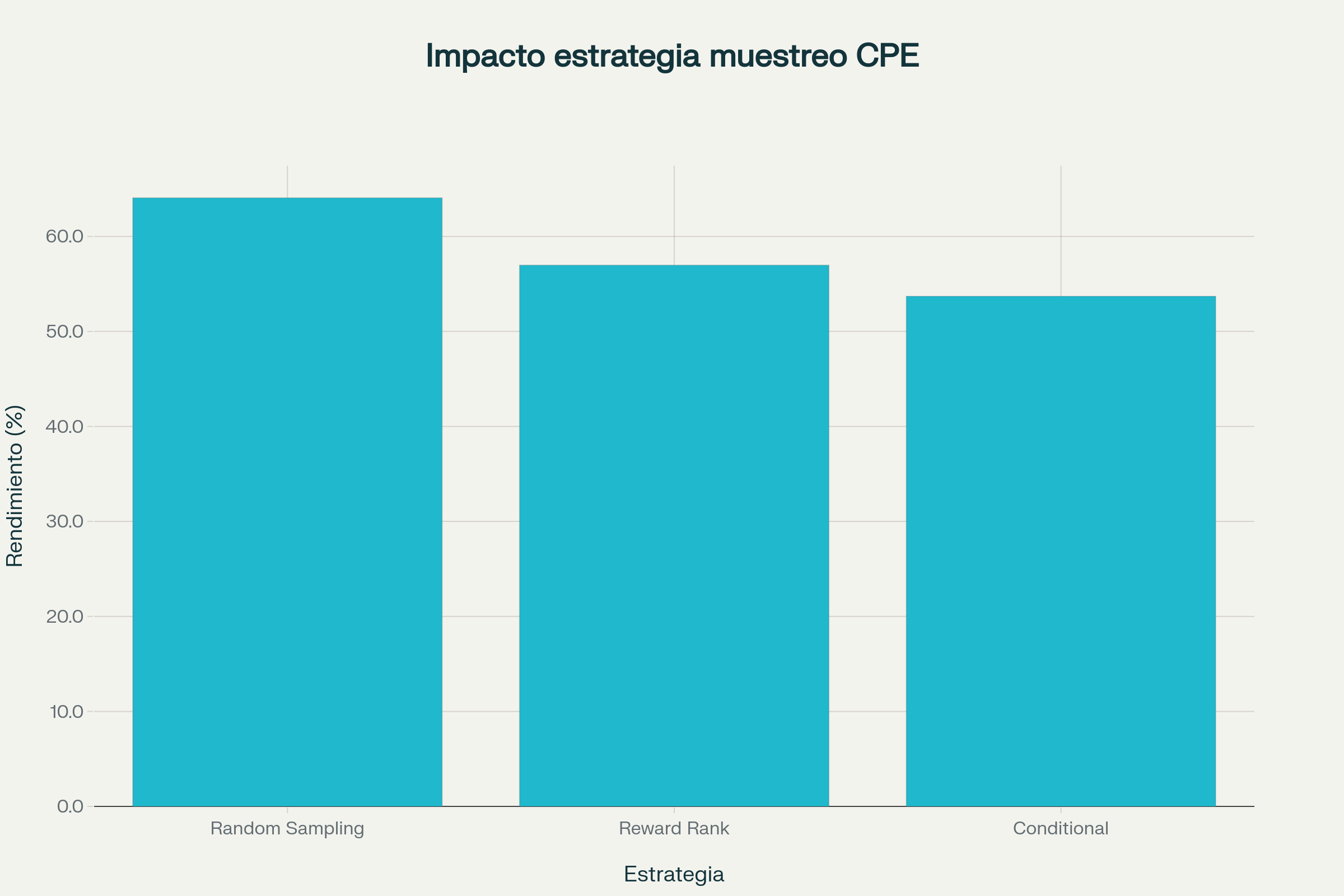
Durante el entrenamiento, el modelo ve tanto respuestas originales como sus versiones editadas. Esta diversidad en el pool de ejemplos ayuda a que el aprendizaje incluya cómo mejorar, no solo qué producir. Se exploraron tres estrategias para seleccionar las respuestas editadas más útiles para el entrenamiento:
- Selección aleatoria (Random Sampling)
- Elección por mayor recompensa (Reward Rank)
Sorprendentemente, la diversidad aportada por la primera estrategia produjo mejores resultados.
Metodología y arquitectura: un marco robusto y replicable
Para poner en práctica su propuesta, el equipo se apoyó en los modelos Qwen2.5-Instruct preentrenados (tanto la versión de 7B como la de 14B parámetros) y generó un corpus robusto de ejemplos donde la personalización fuera decisiva. Se entrenó un GRM capaz de emitir juicios razonados, se crearon perfiles de usuario variados y se diseñó un proceso de anotación semiautomática con modelos maestros como GPT-4o para la crítica.
La función de pérdida híbrida y el uso de PPO (Proximal Policy Optimization) aseguran estabilidad y eficiencia en el aprendizaje, lo que permitió a los modelos mejorar repetidamente tras cada ciclo crítico-edición. La arquitectura permite además ampliar o actualizar los perfiles de usuario, un aspecto clave para adaptabilidad real en aplicaciones a gran escala.
Resultados: demostraciones empíricas y comparación con el estado del arte
El marco Critique-Post-Edit supera tanto en benchmarks competitivos como en tareas prácticas a soluciones previas:
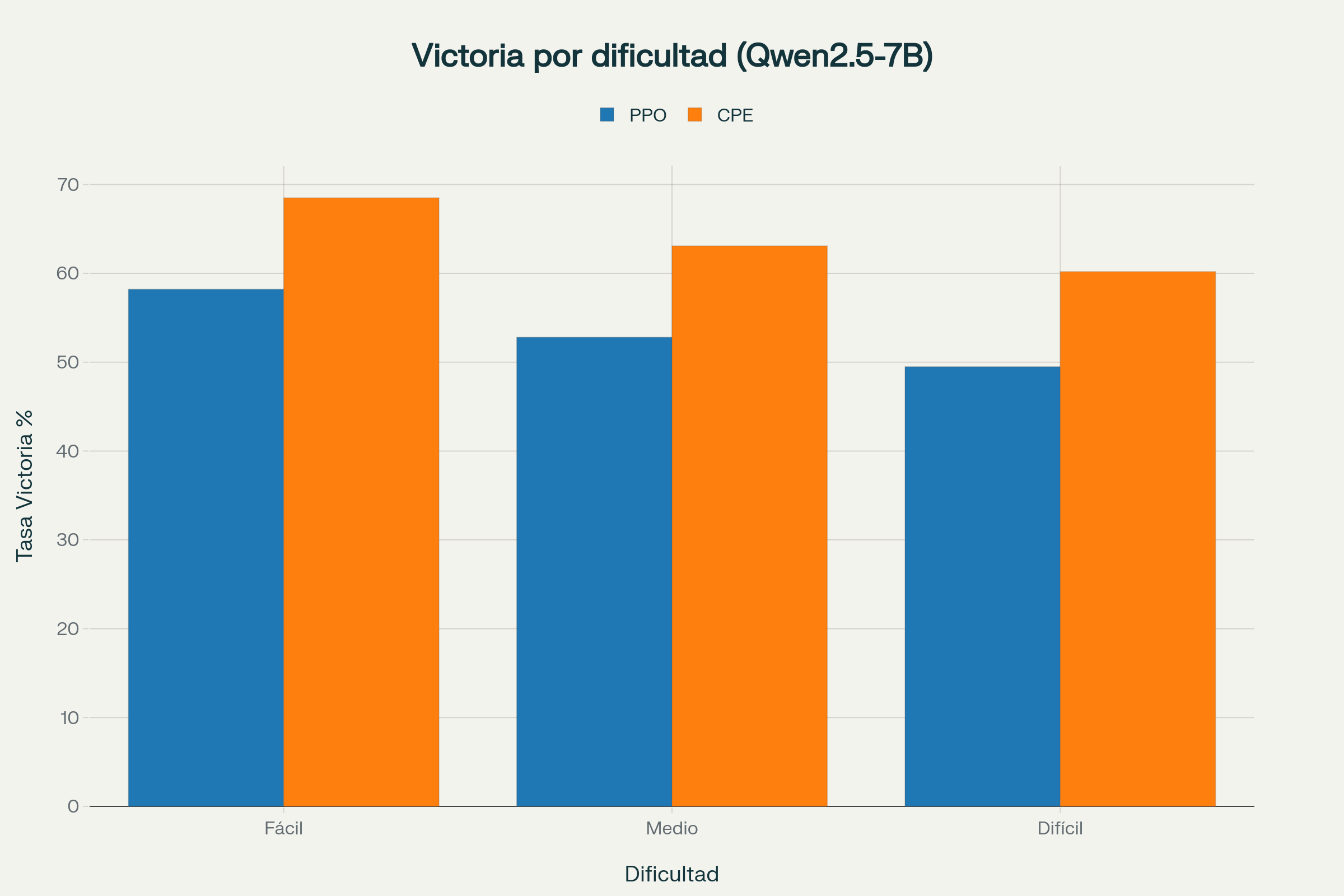
| Modelo | Tasa de victoria (%) | Longitud media respuesta |
|---|---|---|
| PPO + Bradley-Terry | 51.78 | 995 |
| PPO + GRM | 59.50 | 409 |
| Critique-Post-Edit (7B) | 64.07 | 447 |
| Critique-Post-Edit (14B) | 76.8 | - |
| GPT-4.1 | 62.5 | - |
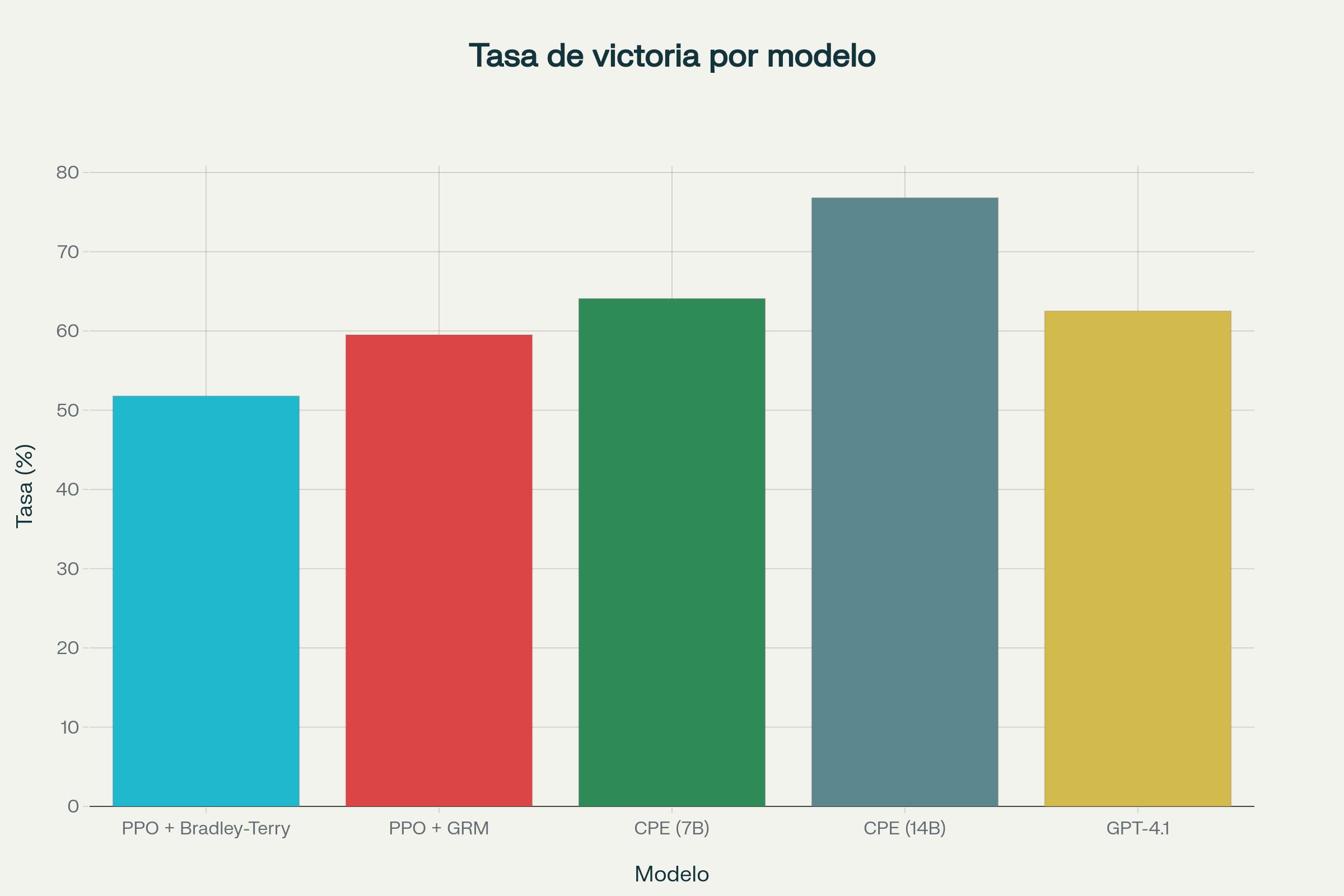
En PersonaFeedback, el mayor benchmark de personalización disponible, con más de 8.200 casos anotados por humanos, la versión Qwen2.5-14B personalizada consigue un 76,8% de tasa de victoria controlando por longitud (frente al 62,5% de GPT-4.1 y el 65,2% del mismo modelo entrenado solo con PPO). En tareas aún más exigentes, como las de memoria dinámica (PersonaMem), los modelos personalizados marcan la diferencia, mostrando una adaptabilidad y fidelidad difícil de igualar por enfoques tradicionales.
La robustez del método se confirma en experimentos de ablación: tanto el uso del GRM como el ciclo de edición posterior a la crítica son necesarios y sinérgicos para obtener los máximos avances.
Abrir la puerta a una IA realmente centrada en el usuario
Más allá de los números, la relevancia social y tecnológica es nítida. Los avances que introduce Critique-Post-Edit habilitan asistentes educativos capaces de adaptarse al estilo y nivel del estudiante, aplicaciones sanitarias que consideran tanto el perfil clínico como las preferencias del paciente, y colegas digitales productivos que comprenden a fondo el contexto profesional de su usuario.
La personalización fiel, que aquí deja de ser una promesa y pasa a ser medible y reproducible, marca un giro en la visión de la IA: de entidades universales y anónimas a asistentes atentos y sutilmente adaptativos.
Quedan retos abiertos. La inferencia automática y dinámica de perfiles desde múltiples interacciones, la extrapolación a otros idiomas y contextos culturales, y el balance óptimo entre personalización y preservación de la privacidad seguirán guiando la investigación. Pero los cimientos conceptuales y técnicos quedan robustamente asentados.
Promesa y esperanza
El futuro de la inteligencia artificial no será solo una carrera por ver qué modelo resuelve más tareas generales o bate los récords de benchmarks. La nueva frontera avanza también hacia adentro: hacia una mayor comprensión de las diferencias individuales, una adaptación empática y sutil, una IA más humilde e inteligente en su trato con la diversidad humana. El framework Critique-Post-Edit es, en octubre de 2025, el eslabón más avanzado en ese camino: la promesa de una IA fiel, flexible y, sobre todo, genuinamente a tu servicio.
Referencias
Alibaba Cloud. (2024). "Qwen2.5: A Party of Foundation Models". Technical Report, Alibaba DAMO Academy.
Anthropic. (2024). "Constitutional AI: Harmlessness from AI Feedback". arXiv:2212.08073.
Chen, L., Zhu, C., Soselia, D., Chen, J., Zhou, T., Goldstein, T., Huang, H., Shoeybi, M., & Catanzaro, B. (2024). "ODIN: Disentangled Reward Mitigates Hacking in RLHF". arXiv:2402.07319.
Dubois, Y., Galambosi, B., Liang, P., & Hashimoto, T. B. (2024). "Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators". arXiv:2404.04475.
Jiang, B., Hao, Z., Cho, Y., Li, B., Yuan, Y., Chen, S., Ungar, L., Taylor, C. J., & Roth, D. (2025). "Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale". arXiv:2504.14225.
Knox, W. B., & Stone, P. (2009). "Interactively Shaping Agents via Human Reinforcement: The TAMER Framework". Proceedings of the Fifth International Conference on Knowledge Capture.
Mahan, D., Phung, D. V., Rafailov, R., Blagden, C., Lile, N., Castricato, L., Fränken, J., Finn, C., & Albalak, A. (2024). "Generative Reward Models". arXiv:2410.12832.
OpenAI. (2022). "Training Language Models to Follow Instructions with Human Feedback". Neural Information Processing Systems (NeurIPS).
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). "Training Language Models to Follow Instructions with Human Feedback". Advances in Neural Information Processing Systems, 35:27730-27744.
OPPO Research Institute. (2025). "OPPO AI: Agentic AI Initiative". Announcement at Google Cloud Next 2025, Las Vegas.
Poddar, S., Wan, Y., Ivison, H., Gupta, A., & Jaques, N. (2024). "Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning". arXiv:2408.10075.
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). "Direct Preference Optimization: Your Language Model is Secretly a Reward Model". Advances in Neural Information Processing Systems, 36:53728-53741.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). "Proximal Policy Optimization Algorithms". arXiv:1707.06347.
Sun, H., Shen, Y., & Ton, J. (2024). "Rethinking Bradley-Terry Models in Preference-Based Reward Modeling: Foundations, Theory, and Alternatives". arXiv:2411.04991.
Tao, M., Zhu, C., Ding, D., Wang, T., Jiang, Y. E., & Zhou, W. (2025). "PersonaFeedback: A Large-scale Human-annotated Benchmark for Personalization". arXiv:2506.12915.
Turpin, M., Arditi, A., Li, M., Benton, J., & Michael, J. (2025). "Teaching Models to Verbalize Reward Hacking in Chain-of-Thought Reasoning". arXiv:2506.22777.
Wang, C., Gan, Y., Huo, Y., Mu, Y., He, Q., Yang, M., Li, B., Xiao, T., Zhang, C., Liu, T., & Zhu, J. (2025). "GRAM: A Generative Foundation Reward Model for Reward Generalization". ICML 2025.
Wang, Z., Dong, Y., Zeng, J., Adams, V., Sreedhar, M. N., Egert, D., Delalleau, O., Scowcroft, J. P., Kant, N., Swope, A., et al. (2023). "HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM". arXiv:2311.09528.
Wang, Z., Zeng, J., Delalleau, O., Egert, D., Evans, E., Shin, H., Soares, F., Dong, Y., & Kuchaiev, O. (2025). "HelpSteer3: Human-annotated Feedback and Edit Data to Empower Inference-time Scaling in Open-ended General-domain Tasks". arXiv:2503.04378.
Zhang, L., Hosseini, A., Bansal, H., Kazemi, M., Kumar, A., & Agarwal, R. (2024). "Generative Verifiers: Reward Modeling as Next-Token Prediction". arXiv:2408.15240.
Zhao, W., Sui, X., Hu, Y., Guo, J., Liu, H., Li, B., Zhao, Y., Qin, B., & Liu, T. (2025). "Teaching Language Models to Evolve with Users: Dynamic Profile Modeling for Personalized Alignment". arXiv:2505.15456.
Zhu, C., Tao, M., Ding, D., Wang, T., Jiang, Y. E., & Zhou, W. (2025). "Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning". arXiv:2510.18849.

