
Hay un tipo de inteligencia que no se nota hasta que falta. Es la capacidad de detenerse un segundo, imaginar qué ocurrirá si hacemos A o si probamos B, y solo después actuar. En humanos y animales esa pausa mínima evita metidas de pata. En agentes de inteligencia artificial, esa habilidad marca la diferencia entre un asistente que aporrea botones y otro que resuelve tareas con criterio. El trabajo Dyna-Mind propone justamente eso: enseñar a los modelos a simular el futuro antes de tocar nada, y hacerlo usando su propia experiencia para que esa simulación sea útil y barata.
En los últimos años los grandes modelos de lenguaje aprendieron a escribir, programar, traducir, analizar y hasta a demostrar teoremas sencillos. Sin embargo, cuando entran en terrenos interactivos, les cuesta navegar una web con formularios, usar un teléfono, completar una misión en un videojuego o moverse con soltura por una interfaz. La explicación corta es simple: responden bien a preguntas, pero no anticipan con detalle qué cambiará en el entorno después de cada acción. Sin anticipación, se vuelven reactivos, cometen errores repetidos y se pierden en menús.
La idea de anticipar no es una metáfora romántica. La psicología clásica mostró que los mamíferos no aprenden solo por refuerzo ciego. Construyen mapas mentales del entorno y ensayan mentalmente alternativas. Ese ensayo silencioso se vuelve visible cuando el animal duda en una bifurcación, mira a un lado y al otro, como si comparara finales posibles. En lenguaje moderno, el agente genera simulaciones internas de lo que vendrá si elige una acción u otra. Esa es la intuición biológica que recupera Dyna-Mind para el mundo de la IA contemporánea.
Pero una intuición no alcanza. Hace falta un método que la convierta en procedimiento. Dyna-Mind arma ese procedimiento en dos etapas complementarias. Primero fabrica, a partir de datos reales, razonamientos donde la simulación no es un adorno sino el corazón de la decisión. Después afina ese comportamiento en línea, con aprendizaje por refuerzo, para que la simulación se vuelva cada vez más certera mientras el agente opera. El resultado práctico, explicado de manera llana, es un agente que piensa con evidencia de futuro y que corrige esa imaginación usando lo que le va pasando.
Este artículo recorre la motivación, la arquitectura y los resultados con un objetivo claro: que cualquier lector no especializado entienda qué problema se resuelve, cómo se consigue y por qué importa para la vida diaria. Para eso, cada concepto técnico se define al paso con palabras comunes, se ofrecen ejemplos concretos y se mantiene un tono narrativo sin perder precisión.
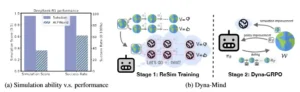
Se observa que el rendimiento de los modelos de razonamiento fuerte se ve considerablemente afectado por su capacidad de simulación en diferentes entornos (izquierda). Se presenta Dyna-Mind, un marco de entrenamiento en dos etapas para integrar y mejorar la capacidad de simulación de los agentes de IA (derecha).
Qué problema resuelve
Si un modelo conversa bien, ¿por qué tropieza al usar un teléfono o al moverse en una interfaz? La razón es que la conversación ocurre en una línea, mientras que las interfaces exigen decisiones secuenciales con consecuencias encadenadas. Cada toque cambia la pantalla, cada clic altera el contexto, cada error cuesta tiempo porque hay que deshacer, buscar, reintentar. Un agente que no simula el efecto de sus pasos empieza a probar al tuntún. Un par de equivocaciones no importan, diez errores seguidos hunden cualquier tarea real.
Para bajar esto a tierra, pensemos en dos escenas diarias. En un rompecabezas de empujar cajas, si muevo una caja hacia una esquina, quizá ya no pueda sacarla. En un teléfono, si abro una app y toco un botón escondido, puede aparecer un diálogo inesperado que tapa todo. En ambos casos conviene anticipar dos o tres pasos por delante. La simulación resuelve precisamente eso: recrear en la cabeza una secuencia corta de acciones, mirar el final probable y elegir lo que más conviene, sin gastar intentos reales.
El hilo histórico ayuda a entender el enfoque. Primero aparece la idea de mapas cognitivos, esas representaciones internas que permiten planificar sin moverse. Mucho después, en aprendizaje por refuerzo, se distinguen dos familias. En una, el agente aprende una política directamente, es decir, una regla simple del tipo “si ves tal estado, hace tal acción” que maximiza la recompensa, sin aprender cómo funciona el mundo. En la otra, el agente aprende un modelo del entorno, algo así como “si estás en este estado y haces esta acción, así cambia la situación y esta es la recompensa”. Con un modelo del entorno se puede planificar, porque el agente simula resultados y elige.
Ese puente entre experiencia y planificación se formalizó en su momento con métodos conocidos como Dyna. La idea era aprovechar cada episodio real para, además de actualizar la política, practicar actualizaciones adicionales con transiciones imaginadas. En lenguaje llano, cada vivencia real se multiplica con pequeñas prácticas mentales para acelerar el aprendizaje. Dyna-Mind retoma ese espíritu en clave contemporánea, con modelos de lenguaje modernos y tareas que van desde rompecabezas de texto hasta la operación de un teléfono con capturas de pantalla.
Cómo piensa dyna-mind
El marco se apoya en una noción sencilla: si queremos que un modelo razone con simulaciones, mostremos ejemplos de buen razonamiento donde la simulación sea explícita, y entrenémoslo para producir ese estilo de respuesta por sí solo. Luego, dejémoslo actuar y premiemos aquellas decisiones que demuestren, con resultados, que su imaginación estaba bien encaminada.
Para hablar con propiedad, definamos cuatro términos al vuelo:
- Simulación o rollout: una pequeña secuencia de pasos imaginados, por ejemplo tres toques que el agente prevé hacer y sus efectos probables.
- Valor: una medida de qué tan prometedora es una secuencia. Puede pensarse como una puntuación que estima si ese camino lleva al objetivo.
- Política: la manera concreta de decidir la próxima acción en el estado actual.
- Ventaja: cuánto mejor fue una trayectoria con respecto al promedio de las que se probaron en la misma tanda. Sirve para ajustar la política hacia lo que rinde más.
La gracia está en combinar estas piezas de un modo que sea entrenable y que resulte útil en ejecución real. Dyna-Mind lo hace en dos etapas coordinadas.
Etapa 1: resim, imaginar con datos
La primera etapa funciona como una escuela de razonamiento. El equipo construye árboles de posibilidades a partir de interacciones reales con el entorno. No le pide al modelo que imagine desde cero, le entrega candidatos de futuro generados por un motor de simulación y una estimación de su valor. Con ese material, un modelo de lenguaje actúa como agregador: lee varios futuros posibles, los resume, compara alternativas y escribe una explicación ordenada que incluye dos cosas, un plan con pasos a seguir y la próxima acción concreta.
Ese razonamiento no es una lista de ocurrencias. Está escrito para que la simulación sea el centro de la decisión. El modelo no dice solo “voy a tocar el botón azul”, explica qué pasará después, por qué ese futuro conviene y cómo encaja con el objetivo. Así se crean ejemplos de “buen pensar”. Luego se destilan esos ejemplos, es decir, se entrena al modelo con supervisión para que genere por sí solo ese tipo de salida sin depender del motor externo. La consecuencia práctica es doble. Por un lado, el agente aprende a producir razonamientos compactos con simulación integrada. Por otro, el costo de inferencia baja, porque ya no hace falta expandir un árbol completo cada vez, alcanza con que el modelo adopte ese estilo de pensar.
Este detalle es crucial para el público no técnico: la destilación convierte un proceso caro en un hábito del modelo. A partir de ahí, cuando el agente debe actuar, puede generar, en pocas frases, una mini-simulación útil que ordena su siguiente paso.
Etapa 2: dyna-grpo, aprender mientras actúa
La segunda etapa enseña al agente a corregir su imaginación con realidad. El procedimiento alterna dos momentos. Primero, el agente actúa como siempre. Genera su plan, avanza un poco, observa los estados reales que aparecen y produce una versión refinada de su propio razonamiento, ahora con esa información fresca. Segundo, el algoritmo de aprendizaje por refuerzo ajusta la política para que favorezca aquellas trayectorias que tuvieron ventaja con respecto al resto, no solo porque lograron la tarea, también porque su razonamiento refinado mostró que anticiparon bien lo que iba a pasar.
Para decirlo sin jerga: el sistema premia pensar bien y acertar, y penaliza pensar mal aunque el resultado haya sido por azar. Esa señal de aprendizaje empuja al modelo hacia simulaciones que predicen con más precisión, lo que en la práctica se traduce en menos pasos inútiles, menos toques innecesarios y más soluciones limpias.
Hay un último matiz útil. La etapa de refuerzo no reemplaza a la destilación, la completa. La escuela de razonamiento da estilo, el refuerzo lo ancla a la realidad cotidiana. Juntas, ambas fases convierten la imaginación en una herramienta fiable.

RESIM integra la simulación en el razonamiento (aReSim t) mediante árboles de búsqueda expandidos, generados a partir de interacciones con entornos reales (izquierda). RESIM entrena a un agente para generar directamente dicho rastro de razonamiento guiado por simulación (aReSim t) sin necesidad de algoritmos (derecha).
Qué significan los resultados
Los contextos de evaluación ayudan a dimensionar la propuesta. En rompecabezas de texto como Sokoban, donde hay que empujar cajas hasta ubicarlas en objetivos sin bloquear salidas, la planificación a dos o tres pasos es la vida misma del juego. Un agente que simula corta camino, porque puede descartar a tiempo los movimientos que generan bloqueos irreversibles. En entornos domésticos de texto, como aquellos donde el agente navega habitaciones, toma objetos y ejecuta instrucciones básicas, la simulación también ordena las prioridades: qué abrir primero, qué buscar, qué acción habilita la siguiente.
Los resultados muestran aumentos significativos en tasas de éxito y, además, una caída en la longitud de las respuestas. Esa combinación es importante. No se trata solo de acertar más, se trata de acertar con menos tokens, es decir, con menos palabras y menos pasos. Ajustado a la vida real, significa un asistente que te hace ganar tiempo, no que te inunda con explicaciones largas o intentos superfluos.
La lectura para no técnicos es directa. Cuando el modelo incorpora simulaciones útiles, aumenta su porcentaje de tareas resueltas y disminuye la verborragia. La correlación entre ambas cosas no es casual. Al imaginar con criterio, el agente elimina caminos muertos antes de ejecutarlos, así evita enredos que después exigirían diez líneas para salir del laberinto.
La prueba en un teléfono Android ficticio, con aplicaciones reales y tareas variadas, es el paso natural. Aquí la observación no es texto, son capturas de pantalla. El agente debe reconocer qué hay en la imagen, decidir dónde tocar, deslizar, escribir, aceptar o cancelar. Es un mundo más ruidoso que un rompecabezas de letras. Cambian los tamaños de botón, aparecen diálogos inesperados, hay notificaciones que tapan contenido. En esa complejidad, simular dos o tres pasos es aún más valioso.
Un ejemplo alcanza para entender la ganancia. Tarea: compartir una foto por una aplicación de mensajería. Un agente sin simulación abre la galería, toca la primera miniatura, queda en otro álbum y se enreda. Un agente con simulación imagina: abrir galería, filtrar por recientes, seleccionar, tocar compartir, elegir la app, confirmar. Si en el tercer paso aparece un diálogo de permisos, lo incorpora a la versión refinada de su plan y ajusta. Ese pequeño ciclo, imaginar, ver, corregir, vuelve la navegación elástica frente a lo imprevisto.
En números redondos, los experimentos muestran que el enfoque de simulación con destilación y refuerzo eleva de forma clara el porcentaje de tareas resueltas en el teléfono y mantiene ventajas fuera de los casos vistos durante el entrenamiento. Traducido a impacto: de cada 50 tareas, el agente con simulación soluciona varias más que un agente que actúa sin anticipar, con menos toques basura y menos idas y vueltas.
Dos ideas clave que conviene retener
- Simular no es agregar prosa, es reducir errores antes de cometerlos.
- Aprender a simular se puede entrenar, primero como estilo, después como hábito contrastado con la realidad.
El lector no técnico quiere efectos concretos. Quiere que el asistente encuentre el archivo correcto, complete un formulario sin perder el tiempo, programe una reunión sin confundir horarios, compre un pasaje sin omitir datos. En todas esas acciones hay ramas de decisión, campos obligatorios, verificaciones. Un agente que imagina dos o tres pasos adelante evita el clásico ciclo de prueba y error que tanto agota. Si el modelo, además, aprende de sus propias ejecuciones, la siguiente vez acierta más rápido.
Pensemos en una gestión cotidiana. Renovar un documento digital implica entrar a un portal, loguearse, navegar una sección, cargar datos, confirmar. Un agente que simula puede prever que la confirmación final exige haber subido un PDF con tal nombre, que la sesión caduca si tarda, que el captcha aparece justo después de aceptar términos. Ese mapa mental evita pantallas en blanco y errores tontos. El valor no está en que “sepa todo”, está en que anticipa lo relevante y prioriza con criterio.

DYNA-GRPO itera entre la mejora de políticas (izquierda) y la mejora del modelo global (derecha), optimizado por GRPO. Durante la mejora de políticas, realizamos implementaciones agrupadas de políticas con GRPO. Durante la mejora de la simulación, realizamos implementaciones de políticas y refinamientos de la simulación y entrenamos el modelo para generar directamente una política mejorada, así como para optimizar el refinamiento de la simulación al proporcionar información sobre estados futuros.
Qué cambia para los desarrolladores de agentes
Para equipos técnicos, el aprendizaje es doble. Primero, se comprueba que enseñar a razonar con simulación se puede, siempre que las muestras de razonamiento sean de buena calidad y estén ancladas en datos reales. Segundo, se verifica que reforzar ese estilo en línea consolida la habilidad en contextos nuevos. En términos prácticos, la arquitectura sugiere que conviene invertir en tres componentes: un generador de candidatos de futuro decente, una manera razonable de puntuar esas opciones y un modelo de lenguaje capaz de sintetizar, comparar y decidir.
La distinción operativa es relevante. El agregador no tiene que convertirse en un planificador pesado, no necesita correr búsquedas profundas. Su valor está en leer alternativas, resumir y elegir con sentido común. Es un rol natural para un modelo de lenguaje, que brilla al evaluar explicaciones y al producir una salida compacta con pasos claros.
Nada de esto es magia. Hay dos cuellos de botella. Primero, la calidad del modelo que genera candidatos. Si propone futuros poco realistas, el agregador elegirá entre opciones mediocres. Segundo, el costo de generar y puntuar alternativas, que hay que mantener acotado si se quiere un sistema ágil. La destilación reduce ese costo, pero optimizar la generación de candidatos sigue siendo fundamental.
Además, en entornos visuales complejos, la percepción de la interfaz manda. Si el modelo no entiende bien la pantalla, no hay simulación que salve la decisión. Por eso, mejorar la comprensión visual del entorno y la capacidad de recuperación después de errores se vuelve prioritario. Otra línea abierta es la interpretabilidad. Si el agente explica por qué elige un camino, los humanos pueden auditar mejor los sesgos, descubrir atajos peligrosos y establecer reglas de seguridad.
Impacto social, tecnológico y científico
La sociedad digital demanda asistentes que hagan trámites, organicen tareas, acompañen procesos educativos, faciliten compras, naveguen plataformas y sean cuidadosos con los datos personales. Dotarlos de imaginación útil los vuelve menos torpes y más confiables. Tecnológicamente, la lección es concreta: en vez de solo escalar el tamaño de los modelos, conviene enseñar hábitos de pensamiento y consolidarlos con señales de refuerzo bien diseñadas. Científicamente, el mérito es integrar la intuición biológica de imaginar antes de actuar con una metodología reproducible que combina supervisión, búsqueda acotada y aprendizaje por refuerzo.
Para quienes diseñan productos, esto se traduce en experiencias menos frustrantes. Un agente que anticipa no borra formularios por accidente, no confunde botones que están cerca, no pide permiso cuando no hace falta, no insiste diez veces con lo mismo. Ese tipo de ahorro, aunque invisible, es lo que construye confianza. La confianza trae adopción, y la adopción empuja la mejora continua.
Supongamos un estudiante que necesita cargar certificados en un campus virtual. Un asistente sin simulación abre el sitio, se loguea, llega a la sección equivocada y pierde minutos. El que simula sabe que, si entra a “Mis cursos”, no verá el formulario. En su mini-plan anota: ir a “Perfil”, abrir “Documentación”, subir PDF con tamaño menor al límite, confirmar. Imagina que el sistema puede pedir aceptación de términos, lo incluye. Cuando aparece el aviso real, ajusta su razonamiento, sube el documento y listo.
Otro caso, un trabajador social que programa recordatorios en un calendario. El agente que simula prevé que ciertos eventos exigen zona horaria distinta, que hay que añadir dirección y un campo de notas. Imagina que, si no se define la franja, el evento se crea mal. Esa simple anticipación evita notificaciones a horas equivocadas y reduce la necesidad de correcciones posteriores.
En un comercio, al registrar un reclamo, el asistente que simula contempla que el sistema pedirá número de orden y correo del cliente. Imagina que, si no tiene el dato, conviene abrir primero la página de historial de compras. Esa preparación ahorra pasos y reduce la tasa de reclamos mal cargados.
¿Hace falta un modelo enorme para beneficiarse? No. La destilación permite que un modelo de tamaño medio aprenda el estilo de razonamiento con simulación y lo ejecute con bajo costo. ¿La simulación empeora la velocidad? No necesariamente. Si se diseña bien, la mini-simulación reduce toques inútiles, por lo tanto acorta el tiempo total. ¿Qué pasa si el entorno cambia? La etapa de refuerzo enseña a ajustar la imaginación con estados reales, por lo que el sistema conserva elasticidad.
Síntesis final
Dyna-Mind ofrece una lección simple y poderosa. La inteligencia que importa en contextos interactivos no es la que recita, es la que ensaya. Enseñar a un modelo a imaginar lo que pasará y a ajustar esa imaginación con lo que efectivamente ocurre produce agentes que se pierden menos, hablan menos y resuelven más. La metodología lo consigue en dos movimientos fáciles de recordar. Primero, muestra ejemplos de buen pensar, con simulación al centro, y los convierte en hábito por destilación. Después, afina ese hábito en línea, premiando trayectorias que demuestran previsión y resultado.
Para un lector no especialista, el mensaje es claro. Simular no es adornar con palabras, es evitar errores antes de cometerlos. Y esa habilidad, que creemos tan natural en nosotros, también se puede enseñar a las máquinas. Si queremos asistentes que de verdad nos ahorren tiempo, que completen tareas sin marearnos, que naveguen interfaces con criterio, el camino pasa por dotarlos de imaginación útil y verificable. No es cuestión de hacerlos más grandes, es cuestión de hacerlos pensar mejor.
Referencias
Ericsson. (2023). Comparing model-based and model-free reinforcement learning: characteristics and applicability.
Sutton, R. S. (2018). Reinforcement Learning: An Introduction. MIT Press. Capítulos sobre Dyna y planificación.
Tolman, E. C. (1948). Cognitive Maps in Rats and Men. Psychological Review, 55(4), 189–208.
Yu, X., et al. (2025). Dyna-Mind: Learning to Simulate from Experience for Better AI Agents. ArXix 2510.09577

