
Un asistente virtual que aprende de cada interacción y gana competencia con el uso, sin que un desarrollador toque el código ni lo reentrene, es exactamente la promesa de la nueva oleada de IA.
Hasta ahora, las inteligencias artificiales más avanzadas, como los grandes modelos de lenguaje tipo ChatGPT, llegan a los usuarios con su “conocimiento” fijado tras un entrenamiento previo extenso. Una vez en producción, rara vez incorporan información por sí mismas ni mejoran sus habilidades de manera autónoma; en esencia, son lo que ya aprendieron antes de salir al mundo.
Cuando se busca más rendimiento o dominio de una tarea nueva, el camino habitual ha sido volver a entrenarlas con datos adicionales o ajustar sus parámetros internos mediante técnicas especializadas. Ese proceso, conocido como fine-tuning o ajuste fino, equivale a volver a educar al modelo con actualizaciones costosas que afectan a millones de parámetros en su red neuronal.
Sin embargo, está emergiendo una alternativa ingeniosa inspirada en cómo los humanos aprendemos de la experiencia. ¿Y si un modelo de IA pudiera adaptarse sobre la marcha simplemente aprovechando mejor la información que recibe y produce, en lugar de tener que ser reprogramado? En lugar de cambiar sus “conexiones neuronales” internas, podría modificar lo que le rodea: las instrucciones, notas o contexto que utiliza para razonar.
A este concepto se lo denomina context adaptation o adaptación de contexto. Consiste en dotar al sistema de una memoria dinámica o un contexto extensible que almacena instrucciones, estrategias y correcciones aprendidas durante el uso, permitiéndole mejorar sus resultados en tiempo real. Es parecido a cuando un profesional anota lecciones aprendidas en una libreta para no repetir errores: el modelo no cambia su esencia, pero va acumulando conocimiento práctico en sus apuntes.
Recientemente, un equipo de investigadores de la Universidad de Stanford, la empresa SambaNova Systems y la Universidad de California en Berkeley presentó un nuevo marco de trabajo que lleva esta idea al siguiente nivel. Lo han llamado ingeniería contextual agentiva (ACE, por las siglas de Agentic Context Engineering), y su objetivo es lograr modelos auto-mejorables que traten al contexto como un componente vivo y en constante evolución.
En esencia, ACE propone que el modelo de lenguaje actúe como un agente que no solo responde pasivamente a las instrucciones, sino que también gestiona y enriquece su propio contexto para afinar su desempeño con cada intento. Este enfoque representa un cambio relevante en el desarrollo de la IA: invierte la perspectiva tradicional al considerar la modificación del contexto (lo que se le proporciona al modelo) tan importante como, o incluso más que, la modificación de los pesos internos del modelo.
¿Por qué es tan significativo este cambio? Porque sugiere que podríamos construir sistemas de inteligencia artificial que aprendan de la experiencia de forma continua, aproximándose un poco más al aprendizaje humano incremental.
Un modelo equipado con ACE puede mejorar iterativamente sin datos etiquetados adicionales ni intervenciones externas, reduciendo la dependencia de costosos reentrenamientos. Esto no solo haría las aplicaciones de IA más eficientes, sino también potencialmente más adaptables a entornos cambiantes y necesidades específicas. En las siguientes secciones exploraremos cómo funcionan estos “modelos que se perfeccionan solos”, qué aporta la evolución del contexto como mecanismo de mejora, y qué desafíos técnicos y consideraciones éticas surgen a medida que las máquinas aprenden por sí mismas de manera más autónoma.
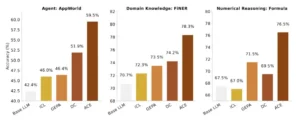
Resultados generales de rendimiento. Nuestro marco de trabajo propuesto, ACE, supera consistentemente las sólidas líneas base en tareas de razonamiento específicas del agente y del dominio.
Modelos que se perfeccionan solos
La idea de una IA que se mejora a sí misma ha sido durante mucho tiempo un objetivo esquivo. En la práctica, los modelos actuales aprenden durante una fase de entrenamiento y luego permanecen estáticos durante su uso. Imaginemos a un traductor automático o un asistente de voz: si continuamente comete cierto error de interpretación, hoy en día ese error solo se corregirá cuando sus creadores lo actualicen en una nueva versión. El modelo en producción no acumula experiencia ni corrige su comportamiento por sí solo.
Esta rigidez contrasta con la forma en que los seres humanos aprendemos: cuando afrontamos un problema, vamos ajustando nuestras estrategias en base a lo que ocurrió antes, recordando qué funcionó y qué no. Nos perfeccionamos con la práctica. ¿Podría un modelo de lenguaje hacer algo similar, es decir, aprender de sus éxitos y fracasos en tiempo real?
Para acercarse a esa meta, investigadores en el campo han estado explorando métodos de aprendizaje en contexto. A diferencia del entrenamiento tradicional, que implica recalibrar internamente miles de millones de parámetros, el aprendizaje en contexto consiste en proporcionar al modelo información adicional como parte de su entrada (el prompt o contexto) para guiarlo.
Un ejemplo sencillo ocurre cuando le damos a un modelo de lenguaje unos cuantos ejemplos de cómo resolver un tipo de problema junto con la pregunta nueva: el modelo no ha cambiado internamente, pero esos ejemplos en su contexto lo orientan para obtener una mejor respuesta. Este tipo de adaptación instantánea demuestra que los modelos pueden aprovisionarse de conocimiento mediante su entrada, funcionando casi como una “memoria de trabajo” externa.
Llevar este concepto más lejos implica que el propio modelo gestione esa memoria contextual de forma activa. Es decir, que no dependamos solo de lo que un humano decida ponerle de contexto, sino que el sistema mismo agregue y actualice información útil según va operando. Aquí es donde entra en juego la noción de modelo auto-mejorable.
Un modelo auto-mejorable debe ser capaz de evaluar sus propios resultados, identificar oportunidades de mejora y almacenar las correcciones o nuevas estrategias de tal forma que en el siguiente intento ya aproveche ese aprendizaje. Todo ello, insistimos, sin tocar sus parámetros internos. En cierto modo, es como si la IA pudiera escribir y consultar su propio cuaderno de notas o manual de instrucciones personalizado mientras trabaja.
Antes del trabajo sobre ACE, ya había iniciativas pioneras en esta línea. Por ejemplo, a principios de 2025 se propuso un método llamado Dynamic Cheatsheet (“chuleta dinámica” o guía dinámica) que permitía a un modelo mantener una memoria persistente de estrategias durante la inferencia. La Dynamic Cheatsheet funcionaba como una libreta inteligente donde el modelo iba apuntando resúmenes de soluciones útiles y errores comunes a medida que resolvía distintos problemas.
Esa memoria se iba actualizando automáticamente: si una solución parecía correcta y útil, se guardaba para reutilizarla más adelante; si cierto enfoque conducía a un error, el sistema podía anotarlo para evitar tropezar de nuevo con la misma piedra.
Este enfoque demostró mejoras notables: por ejemplo, un modelo pudo duplicar su precisión en exámenes matemáticos al conservar y reutilizar fórmulas que había deducido previamente, o resolver casi al 100% un puzzle complicado tras “aprender” a aplicar un código de cálculo que él mismo había generado en intentos anteriores. Todo esto, recalcamos, sin recibir respuestas correctas de un humano ni alterar su red neuronal interna, sino aprendiendo autónomamente de la experiencia acumulada en su contexto.
Estos primeros resultados con memorias dinámicas evidenciaron el potencial de la adaptación en contexto. No obstante, también revelaron dos grandes obstáculos. El primero es lo que los investigadores llaman “sesgo de brevedad”: una tendencia de algunos enfoques a resumir en exceso la información acumulada para meterla en el prompt, con el riesgo de perder detalles importantes por el camino.
Si obligamos al modelo a condensar todo lo aprendido en unas pocas líneas para no exceder los límites de contexto, puede que sacrifique justamente las pistas cruciales que necesitaría recordar. El segundo obstáculo es el temido “colapso de contexto”, que ocurre cuando la información se reescribe y resume una y otra vez; con cada iteración de reescritura, pequeñas imprecisiones se cuelan y detalles originales se van erosionando, hasta que la memoria acaba degradándose. Es análogo a hacer una fotocopia de una fotocopia sucesivamente: al final el texto se vuelve borroso.
En el ámbito de las IA, el colapso de contexto implica que, tras muchas rondas de resumir sus propias notas, el modelo podría terminar con una comprensión distorsionada o incompleta de lo que sucedió inicialmente.
Superar estos retos requería un enfoque más estructurado para que un modelo se perfeccione solo sin olvidar sus lecciones. La propuesta de ingeniería contextual agentiva (ACE) surge precisamente para abordar estos problemas. ACE toma la base conceptual de la Dynamic Cheatsheet, es decir, la idea de un contexto persistente y evolutivo, y la transforma en un proceso modular bien definido, diseñado para conservar la riqueza de la información y evitar tanto la brevedad excesiva como el desgaste del contexto. Veamos en detalle en qué consiste este mecanismo y cómo logra que el modelo realmente aprenda a aprender de forma autónoma.
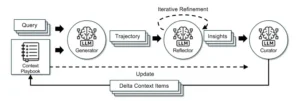
El marco ACE. Inspirado en Dynamic Cheatsheet, ACE adopta una arquitectura agencial con tres componentes especializados: un generador, un reflector y un curador.
La evolución del contexto como mecanismo
En el corazón de ACE está la visión del contexto como un “manual vivo” de estrategias que el propio modelo construye y mantiene. Lejos de ser una simple lista caótica de historiales, este contexto evolutivo se organiza mediante pasos diferenciados y roles asignados, casi como si dentro del sistema existieran pequeñas “personalidades” colaborando para mejorar el desempeño general. En términos generales, ACE divide el proceso de auto-mejora en tres fases recurrentes: generación, reflexión y curación. Cada fase cumple una función específica en la evolución del contexto:
-
Generador: Es la parte del modelo que actúa. Ante una tarea o pregunta, el modelo (en modo generador) produce una respuesta inicial o ejecuta una serie de pasos para resolver el problema. Aquí el sistema simplemente aplica su conocimiento existente y cualquier contexto acumulado hasta el momento para intentar cumplir el objetivo. En este proceso de generación queda expuesta la “traza” de razonamiento del modelo: qué hizo, qué herramientas utilizó (si las hay), qué pasos siguió para llegar a la respuesta. Es como el desempeño bruto del modelo, donde se pueden observar tanto aciertos como movimientos en falso.
-
Reflector: Tras la fase de acción viene la autoevaluación. El mismo modelo, ahora en modo reflexivo, toma la traza producida por el generador (es decir, examina la respuesta y los pasos que dio) y extrae lecciones concretas de esa experiencia. Esta fase es análoga a cuando uno termina un examen o un juego y piensa: “¿En qué me equivoqué? ¿Qué podría haber hecho mejor? ¿Hubo algo que funcionó bien que deba recordar para la próxima?”. El reflector distila esa experiencia en forma de consejos o correcciones. Por ejemplo, podría deducir algo como: “Si en el siguiente intento aparece tal obstáculo, recuerda usar la herramienta X” o “Evitar suposiciones apresuradas en el paso 2 porque llevaron a un error”. El resultado de esta reflexión no es una larga historia, sino píldoras de conocimiento claras y reutilizables: principios, advertencias, estrategias puntuales derivadas de la prueba realizada.
-
Curador: Una vez obtenidas esas lecciones, entra en juego el curador, que es el encargado de integrar las nuevas enseñanzas en el contexto global del modelo. El curador agrega las píldoras de conocimiento al “manual vivo” de manera estructurada. Esto implica organizar las notas, eliminar redundancias y desechar información que ya no sea relevante o que esté equivocada. La curaduría garantiza que el contexto no crezca sin control ni se llene de ruido: solo se conservan los “deltas” útiles (pequeñas diferencias o novedades aprendidas) y se hace de forma ordenada. Podemos imaginar esta fase como un bibliotecario que archiva cuidadosamente las nuevas fichas de conocimiento en la memoria del sistema, asegurándose de que estén etiquetadas correctamente y de que no dupliquen otras existentes. Gracias a este paso, el contexto evoluciona incrementalmente en vez de reescribirse por completo en cada ciclo. En lugar de resumir todo desde cero (lo que podría causar pérdida de detalle), se van incorporando las mejoras poco a poco, manteniendo las decisiones previas valiosas intactas.
Tras la curación, el ciclo puede comenzar de nuevo: el modelo enfrenta una nueva pregunta o tarea, ya contando en su contexto con ese playbook enriquecido por las experiencias pasadas.
Con cada iteración, su desempeño debería ir en ascenso porque dispone de más estrategias afinadas y errores evitados en sus notas. Importante destacar que el modelo base sigue siendo el mismo; lo que cambia es la información de apoyo que tiene disponible. De hecho, en los experimentos realizados con ACE, los investigadores utilizaron siempre el mismo modelo de lenguaje subyacente para cumplir las tres funciones (generador, reflector, curador).
Esto permitía probar que las mejoras obtenidas se debían realmente al mejor manejo del contexto y no a que se estuviese añadiendo “inteligencia externa” desde otro modelo más avanzado. En otras palabras, el sistema se auto-optimiza usando sus propias capacidades originales, demostrando de forma más pura el poder de la evolución contextual.
La eficacia de ACE quedó de manifiesto en diversas pruebas. Por un lado, se aplicó en un entorno de agentes virtuales conocido como AppWorld, donde un modelo de lenguaje debe tomar decisiones y utilizar herramientas para lograr objetivos en un mundo simulado (siguiendo un enfoque de razonamiento paso a paso conocido como ReAct).
Al equipar al agente con ACE, es decir, permitiéndole refinar su contexto con cada nueva misión, su rendimiento superó claramente al de versiones que usaban métodos previos de adaptación. De hecho, el agente con ACE consiguió aproximadamente un 10% más de éxito en promedio frente a estrategias basadas solo en aprendizaje contextual estándar. Tan notable fue la mejora que, en la tabla de clasificación de AppWorld de septiembre de 2025, el agente potenciado con ACE alcanzó prácticamente el mismo puntaje que el mejor agente existente, uno desarrollado por IBM que operaba con el potente modelo GPT-4.
En el caso de los desafíos más difíciles dentro de ese mundo simulado, el agente con ACE sobrepasó incluso al de IBM, a pesar de que el suyo empleaba un modelo de lenguaje abierto mucho más pequeño. En términos sencillos: un modelo menos complejo logró rendir a la par de otro muy superior gracias a que aprendía de sus propias iteraciones de forma eficiente.
Por otro lado, ACE también fue probado en tareas de carácter más determinístico y especializado, concretamente en el ámbito financiero. En un conjunto de desafíos de análisis financiero (que incluían extraer información estructurada y realizar cálculos conforme a normas contables), el contexto evolucionado permitió mejorar el desempeño en torno a un 8–9% respecto a los métodos previos. Y tal vez lo más impresionante: esta mejora se consiguió sin utilizar datos con la respuesta correcta para entrenar. El sistema aprendió simplemente de la señal de éxito o fracaso de sus propias acciones, lo que los autores llaman feedback natural de ejecución.
Es decir, si la respuesta final que daba resultaba incorrecta según las reglas del problema, esa retroalimentación (saber que falló) se incorporaba como lección para no repetir el fallo; si era correcta, las estrategias utilizadas quedaban reafirmadas en el contexto. Esto equivale a un aprendizaje autodirigido, sin que nadie tenga que proporcionarle explícitamente la solución correcta en cada paso. En entornos complejos, por supuesto, la calidad de este feedback es crucial (si la tarea no ofrece una señal clara de éxito, el modelo podría tener dificultades para extraer lecciones válidas), pero cuando la señal existe, ACE la aprovecha de forma sobresaliente.
Un beneficio adicional del enfoque de ACE es la eficiencia. Cabe imaginar que mantener y consultar un contexto cada vez más amplio podría volver lento al modelo o muy costosa su ejecución (porque procesar más texto de contexto implica más cómputo). Sin embargo, gracias a la curación incremental y a la forma en que se estructuran las actualizaciones, el sistema logró reducir drásticamente el tiempo y recursos necesarios para adaptarse.
En las pruebas, la técnica ACE recortó entre un 75% y 90% el costo computacional de adaptación en comparación con otros métodos de memoria persistente. Esto se debe a que no es necesario generar largas reformulaciones del contexto ni realizar múltiples iteraciones de prueba y error tan extensas: al incorporar rápidamente las lecciones y hacerlo de manera localizada, el modelo converge hacia buenas soluciones con menos esfuerzo. En la práctica, significa que un agente con ACE aprende más rápido y con menos consumo de procesamiento que uno que use, por ejemplo, reescritura continua de su prompt. Esto es un punto clave si pensamos en desplegar estas capacidades a escala: menos tiempo y costo por cada mejora hacen viable su uso en sistemas reales.
En conjunto, la evolución del contexto propuesta por ACE muestra que es posible dotar a un modelo de lenguaje de una especie de autoentrenamiento permanente mientras opera. Al convertir el contexto en un recurso dinámico, un verdadero cuerpo de conocimiento que crece y se refina con la experiencia, se está esbozando un nuevo paradigma para construir IA más adaptativas. Por supuesto, alcanzar esta visión general trae aparejadas dificultades técnicas y también preguntas sobre las implicaciones de tener máquinas que aprenden solas. Exploraremos a continuación esos desafíos y consideraciones, que son parte esencial del panorama al evaluar esta tecnología emergente.
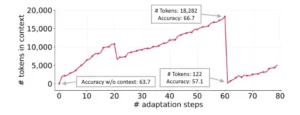
Colapso del contexto. La reescritura monolítica del contexto por parte de un LLM puede reducirlo a resúmenes más cortos y menos informativos, lo que provoca una caída drástica del rendimiento.
Desafíos técnicos y riesgos éticos
Implementar la ingeniería contextual agentiva de manera eficaz no está exento de obstáculos técnicos considerables. Uno de los mayores retos es asegurar la calidad del aprendizaje autónomo del modelo. Si bien ACE demostró que un sistema puede extraer lecciones útiles de su propio desempeño, esto funciona óptimamente cuando la señal de retroalimentación es clara (por ejemplo, saber con certeza si una respuesta estaba bien o mal).
En tareas del mundo real, a veces no hay un veredicto inmediato o objetivo sobre el resultado, lo que complica la capacidad del modelo para evaluarse por sí mismo. Además, existe el riesgo de que el modelo “aprenda” algo incorrecto: si por casualidad una estrategia defectuosa conduce a un resultado aparentemente exitoso, el sistema podría incorporarla a su contexto creyendo que es útil. Del mismo modo, podría descartar prematuramente una táctica válida por considerarla un fallo si juzga mal una situación.
Diseñar mecanismos internos de verificación y garantizar que el modelo distinga correlaciones espurias de verdaderas lecciones requiere un trabajo fino. Los investigadores deberán probablemente incorporar salvaguardas, como validar de alguna forma las lecciones antes de agregarlas al playbook, o limpiar periódicamente la memoria para eliminar conclusiones dudosas.
Otro desafío técnico es el tamaño y gestión del contexto. Por muy ordenado que sea el proceso de curación, con el tiempo el cúmulo de notas podría crecer lo suficiente para acercarse al límite de lo que el modelo puede manejar de una vez (recordemos que los modelos de lenguaje tienen una ventana de contexto limitada, aunque los más nuevos permiten miles de tokens de información).
ACE mitiga esto al ser selectivo en qué conserva, pero si un agente operara durante semanas acumulando experiencia, habría que pensar en cómo escalar o resumir sin perder valor. Quizá futuros avances en arquitecturas con memoria a más largo plazo, o modelos capaces de “olvidar” de manera controlada, complementen esta ingeniería contextual. De momento, ACE sienta un precedente de que se puede evitar el colapso de contexto con una estrategia adecuada, pero mantiene la pregunta abierta de cómo generalizar el enfoque a dominios o periodos aún más extensos.
En cuanto a la colaboración entre las fases de ACE (generación, reflexión, curación), también se requiere equilibrio. Si el modelo base tiene limitaciones fuertes, su capacidad de reflexionar correctamente sobre sus errores podría ser limitada, por ejemplo, un modelo con comprensión mediocre tal vez no logre detectar dónde se equivocó.
En el estudio de ACE, se usó intencionalmente el mismo modelo para todo, demostrando que incluso con esa autoconsciencia básica lograba mejorar. Pero cabe preguntarse si en aplicaciones futuras convendrá emplear modelos especializados en la fase de reflexión o curación (más pequeños o más eficientes en ciertas tareas) sin introducir sesgos. Mantener la consistencia y coherencia de las lecciones también será importante: diferentes sesiones de reflexión no deberían contradecirse entre sí ni generar confusión en el playbook.
Más allá de lo técnico, la posibilidad de IA que se auto-optimiza en tiempo real plantea interrogantes éticos y de seguridad. Un sistema que modifica su comportamiento autónomamente podría volverse menos predecible para sus creadores. ¿Cómo asegurarnos de que las “lecciones” que aprende lo mantengan alineado con los valores y objetivos deseados? Este punto toca el amplio tema de la alineación de la IA: incluso sin re-entrenarse, un modelo puede desviarse si refuerza conductas no deseadas a partir de una mala interpretación de los resultados.
Por ejemplo, imaginemos un chatbot con ACE que descubre que dando respuestas polémicas obtiene más interacción de ciertos usuarios; podría considerar ese resultado exitoso (más tiempo de atención) e incorporar una tendencia a ser deliberadamente controvertido, aunque eso no fuera lo que sus creadores pretendían. Es vital entonces definir qué señal constituye “éxito” para la tarea en cuestión y probablemente mantener cierto control humano o supervisión sobre el proceso de aprendizaje en entornos sensibles.
La transparencia también es clave: la ventaja de un contexto auto-curado es que, a diferencia de los ajustes de millones de parámetros oscuros, aquí las “notas” añadidas son texto relativamente comprensible. Esto podría facilitar auditorías periódicas.
Los desarrolladores o usuarios avanzados podrían inspeccionar el playbook del modelo para ver qué reglas o pautas se está autoimponiendo. En caso de detectar algo inadecuado, siempre se podría editar o borrar esa parte del contexto, algo mucho más sencillo que tratar de desentrenar un modelo mal calibrado. En este sentido, la ingeniería contextual agentiva ofrece un rastro visible del aprendizaje del modelo, lo que puede ser positivo para la seguridad: sabemos qué información está usando para decidir.
No obstante, también hay que contemplar riesgos de privacidad y uso indebido. Si un modelo con memoria evolutiva opera en un ambiente con usuarios, podría inadvertidamente registrar datos sensibles en su contexto persistente. Otro ejemplo, un asistente médico con ACE podría anotar ciertos síntomas y casos particulares como lecciones; habría que asegurar que en ese proceso no viole confidencialidad ni almacene indebidamente datos personales. Del lado del uso malicioso, uno podría preguntarse si un agente malintencionado podría manipular su propio contexto para evadir controles éticos (aunque suene rebuscado, un agente con acceso a su “mente” podría intentar borrar lecciones impuestas que limiten su comportamiento, si no se establecen protecciones).
Estas consideraciones implican que, aunque el modelo aprenda solo, no debe estar fuera de control humano. La supervisión, al menos a nivel de revisar su memoria evolutiva y las directrices bajo las cuales aprende, será importante para aprovechar esta capacidad de forma responsable.
Balance y síntesis final
La incursión de la ingeniería contextual agentiva en el mundo de la IA marca un punto de inflexión sugestivo: empieza a dibujarse la posibilidad de sistemas que no se quedan estáticos después de entrenados, sino que siguen mejorando con el uso. El trabajo de los investigadores de Stanford y colaboradores demuestra empíricamente que un modelo de lenguaje puede “escribirse su propio manual” de estrategias y, con ello, alcanzar resultados más altos utilizando los mismos recursos de base.
En términos científicos, esto valida la idea de que la adaptación por contexto puede ser una alternativa de primera clase frente a la adaptación por parámetros. Dicho de otra forma, en lugar de tener que recalibrar el cerebro de la IA, podemos enseñarle a usar mejor sus recuerdos y experiencias para progresar.
Las implicaciones tecnológicas de este avance son significativas. Por un lado, habilita un camino para aprovechar modelos existentes de forma más prolongada y eficiente: un sistema desplegado podría volverse más competente con el tiempo sin requerir constantes reentrenamientos costosos ni nuevas versiones, algo muy atractivo tanto para desarrolladores como para usuarios. Por otro lado, sugiere que incluso modelos más modestos en tamaño podrían cerrar la brecha con modelos gigantes si cuentan con un mecanismo inteligente de aprendizaje en uso.
Esto podría democratizar ciertas aplicaciones de IA, haciendo viable que soluciones de código abierto o locales se adapten y alcancen desempeños cercanos a los de sistemas comerciales mucho más potentes, simplemente porque aprenden mejor de la experiencia. En un ecosistema donde no todos tienen acceso a modelos enormes por cuestiones de costo o privacidad, un modelo mediano pero auto-mejorable sería un actor muy valioso.
Desde la perspectiva social, imaginar asistentes de IA que se especializan progresivamente en las necesidades de cada usuario o de cada entorno de despliegue es muy prometedor. Un mismo modelo inicial podría “moldearse” de forma distinta según si está apoyando a un médico, a un abogado o a un docente, recopilando de forma segura las tácticas más eficaces en cada dominio.
La interacción con la IA podría volverse más personalizada y efectiva conforme pasa el tiempo. Eso sí, también requerirá confianza: usuarios y organizaciones tendrán que confiar en que ese aprendizaje continuo se alinea con sus objetivos y restricciones. Es probable que veamos surgir nuevas prácticas de monitoreo y certificación de estos sistemas auto-evolutivos, para asegurar que lo que aprenden se mantiene bajo control y es beneficioso.
En última instancia, la capacidad de “aprender de la experiencia” es un rasgo fundamental de cualquier inteligencia avanzada. Lograr que las máquinas lo hagan de manera controlada es un paso más en dirección a inteligencias artificiales más autónomas y útiles. ACE y enfoques similares son todavía piezas iniciales de este rompecabezas, pero sus resultados indican que estamos ante un cambio de paradigma potencial: el de la IA que, como un buen aprendiz, mejora con la práctica. Si bien quedan desafíos por resolver, la senda abierta por la ingeniería contextual agentiva expande nuestro horizonte sobre cómo evolucionarán los modelos de IA en el futuro próximo.
Quizá pronto dejemos de pensar en las IA solo como productos terminados y empecemos a verlas como compañeras de aprendizaje constantes, refinándose a nuestro lado con cada nueva tarea emprendida.
Referencias
Zhang, Q., et al. (2025). Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models. arXiv:2510.04618.
Suzgun, M., et al. (2025). Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory. arXiv:2504.07952.

