
En las silenciosas arenas del más alto rendimiento intelectual, donde las mentes jóvenes más brillantes del planeta se enfrentan a los misterios del cosmos, ha surgido un nuevo competidor. No es un prodigio de ninguna nación, no ha pasado noches en vela estudiando con la única ayuda de un telescopio y una calculadora, y sin embargo, su desempeño ha sido extraordinario.
Este nuevo contendiente es una inteligencia artificial, un modelo de lenguaje grande que, por primera vez, ha demostrado ser capaz de razonar en el complejo campo de la astronomía y la astrofísica a un nivel que le habría valido una medalla de oro en la competición más prestigiosa del mundo: la Olimpiada Internacional de Astronomía y Astrofísica. Este hito, detallado en un reciente y revelador estudio, no solo marca un punto de inflexión en las capacidades de la inteligencia artificial, sino que nos obliga a reconsiderar la naturaleza misma del pensamiento científico y el futuro de la investigación.
Para comprender la magnitud de este logro, primero debemos despojarnos de las concepciones populares sobre la inteligencia artificial, a menudo moldeadas por la ciencia ficción. Los sistemas que hoy nos asombran, conocidos como modelos de lenguaje grandes o LLMs, no son mentes conscientes en el sentido humano. Son, en esencia, sistemas computacionales de una complejidad abrumadora, entrenados con una cantidad de información textual y de datos tan vasta que equivale a la práctica totalidad del conocimiento humano digitalizado.
Pensemos en ellos como aprendices universales que han leído cada libro, cada artículo científico, cada página web, y han aprendido a identificar patrones, relaciones y estructuras lógicas en todo ese océano de información. Su habilidad no reside en comprender o sentir, sino en predecir, generar y manipular el lenguaje y los símbolos con una fluidez que a menudo resulta indistinguible de la de un experto humano.
El escenario elegido para poner a prueba a estas mentes digitales no fue uno cualquiera. La Olimpiada Internacional de Astronomía y Astrofísica, conocida por sus siglas en inglés IOAA, es el equivalente a los Juegos Olímpicos para la astrofísica de bachillerato. Es una prueba extenuante que va mucho más allá del simple conocimiento enciclopédico.
No basta con saber la distancia a la galaxia de Andrómeda o recitar las leyes de Kepler. Los participantes deben resolver problemas multifacéticos que exigen una profunda comprensión de la física, un dominio de las matemáticas avanzadas y, lo que es más importante, una capacidad de razonamiento creativo para conectar conceptos dispares y trazar un camino lógico desde una pregunta compleja hasta una solución justificada. Es una evaluación que mide la habilidad para pensar como un científico.
Aquí yace la cuestión central que un equipo de investigadores de la Universidad Estatal de Ohio se propuso abordar. Durante años, la forma de medir el progreso de la inteligencia artificial se ha basado en pruebas estandarizadas, conocidas como benchmarks. Sin embargo, muchos de estos exámenes, aunque útiles, se asemejan más a un test de cultura general que a una verdadera evaluación de la inteligencia. A menudo consisten en preguntas de opción múltiple que miden la capacidad de un modelo para recuperar información, es decir, su conocimiento, pero no su capacidad para razonar.
La ciencia, en su esencia, no es un examen de opción múltiple. Es un proceso de formulación de hipótesis, de derivación matemática, de análisis de datos y de construcción de argumentos coherentes. Los investigadores se dieron cuenta de que para saber si la inteligencia artificial estaba realmente lista para contribuir a la ciencia, necesitaban un examen mucho más exigente. Necesitaban un estándar de oro. Y lo encontraron en la IOAA.
El estudio, por tanto, se erigió sobre una premisa audaz: utilizar los problemas de esta olimpiada de élite como un nuevo y riguroso marco de referencia para evaluar a los modelos de lenguaje más avanzados del momento. Para ello, compilaron un conjunto de datos único con problemas de ediciones pasadas de la competición y diseñaron un meticuloso sistema de evaluación que no solo premiaba la respuesta final correcta, sino que analizaba la calidad y la corrección de cada paso en el razonamiento.
El resultado de este experimento ha sido tan sorprendente como revelador. Uno de los modelos probados no solo aprobó el examen, sino que lo hizo con una puntuación que, en una competición real, lo habría colocado en el selecto grupo de los medallistas de oro. Este artículo explorará en profundidad cómo se gestó este hito, qué nos dice sobre las fortalezas y debilidades de la inteligencia artificial actual, y qué significa para el futuro de la exploración científica.
Nos adentraremos en el desafío de medir la inteligencia, analizaremos por qué la olimpiada de astronomía representa el examen definitivo, conoceremos a los contendientes digitales y diseccionaremos tanto sus espectaculares éxitos como sus instructivos fracasos. El cosmos siempre ha sido la última frontera para la humanidad; ahora, parece que también lo es para nuestras creaciones más inteligentes.

El desafío de medir la inteligencia artificial
La historia del desarrollo de la inteligencia artificial es también la historia de su medición. Desde los primeros días de la computación, los pioneros del campo buscaron formas de cuantificar el progreso y comparar diferentes enfoques. El famoso Test de Turing, por ejemplo, proponía que una máquina podría considerarse inteligente si era capaz de conversar con un humano sin que este pudiera distinguir si su interlocutor era una persona o un programa.
Con el tiempo, a medida que los sistemas se volvieron más complejos, también lo hicieron los métodos para evaluarlos. Surgieron así los benchmarks, pruebas estandarizadas diseñadas para medir capacidades específicas en áreas como el procesamiento del lenguaje, el reconocimiento de imágenes o el juego estratégico.
En la era moderna de los modelos de lenguaje grandes, los benchmarks se han convertido en una herramienta indispensable para la comunidad investigadora. Pruebas como el MMLU (Massive Multitask Language Understanding) se han popularizado como una forma rápida de obtener una puntuación que refleje la capacidad general de un nuevo modelo. Este tipo de evaluación presenta al sistema miles de preguntas de opción múltiple que abarcan docenas de temas, desde la historia del arte hasta la física cuántica.
Una puntuación alta en el MMLU indica, sin duda, que un modelo ha asimilado una cantidad prodigiosa de conocimiento y puede acceder a él de forma fiable. Sin embargo, esta metodología, aunque valiosa, posee una limitación fundamental cuando se trata de evaluar el potencial científico de una inteligencia artificial.
El principal inconveniente es que estos benchmarks favorecen la recuperación de información sobre la generación de conocimiento. Una pregunta de opción múltiple ofrece al modelo una serie de respuestas predefinidas, una de las cuales es correcta. El sistema solo necesita identificar cuál de las opciones es la más probable según los patrones aprendidos durante su entrenamiento. Este proceso es fundamentalmente diferente del que realiza un científico ante un problema real. Un científico no elige una respuesta de una lista; la construye desde cero. Comienza con los principios fundamentales, aplica herramientas matemáticas, interpreta datos, y articula una solución paso a paso, justificando cada una de sus decisiones. Esta capacidad, la de generar una cadena de razonamiento lógico y coherente, es precisamente lo que los benchmarks tradicionales no logran medir de manera efectiva.
Esta brecha entre el conocimiento factual y el razonamiento aplicado es crucial. Imaginemos un estudiante de medicina que ha memorizado todos los libros de texto, pero es incapaz de diagnosticar a un paciente con síntomas ambiguos. O un ingeniero que conoce todas las fórmulas, pero no puede diseñar un puente para un terreno complicado. El conocimiento es la materia prima, pero el razonamiento es el motor que lo transforma en soluciones.
En el ámbito de la astronomía y la astrofísica, esta distinción es aún más pronunciada. Los problemas en este campo raramente tienen respuestas directas que se puedan encontrar en un libro. Requieren la habilidad de visualizar sistemas en tres dimensiones, de aplicar aproximaciones físicas cuando es adecuado, y de construir complejas derivaciones matemáticas. Depender exclusivamente de pruebas que no evalúan estas habilidades es como intentar medir la capacidad de un atleta olímpico pidiéndole que complete un crucigrama. Se estaría midiendo una habilidad, sí, pero no la que define su excelencia. Los investigadores detrás del estudio entendieron perfectamente esta limitación y buscaron un desafío que reflejara la verdadera práctica científica, un examen donde mostrar el trabajo fuera tan importante como llegar al resultado final.
La olimpiada de astronomía como el nuevo estándar de oro
La búsqueda de un examen más adecuado para medir el razonamiento científico de la inteligencia artificial llevó al equipo de la Universidad Estatal de Ohio a la Olimpiada Internacional de Astronomía y Astrofísica. Fundada en 2007, la IOAA se ha consolidado como la competición más rigurosa y prestigiosa para estudiantes preuniversitarios en estas disciplinas. A diferencia de un examen escolar tradicional, su diseño tiene como objetivo emular los desafíos a los que se enfrenta un investigador profesional. Las preguntas son abiertas, complejas y a menudo requieren más de una hora de trabajo concentrado para ser resueltas.
La estructura de la olimpiada es una de las claves de su idoneidad como benchmark. Se divide en varias rondas que evalúan un espectro completo de habilidades. La ronda teórica presenta problemas que exigen profundas derivaciones matemáticas y físicas, como calcular la evolución de una estrella o determinar la trayectoria de un cuerpo celeste bajo la influencia de múltiples fuerzas gravitatorias.
La ronda de análisis de datos proporciona a los concursantes datos astronómicos reales, a menudo en forma de tablas o gráficos, y les pide que los interpreten, extraigan conclusiones y formulen modelos, un proceso idéntico al que realizan los astrónomos en su día a día. Finalmente, la ronda de observación, aunque más difícil de replicar para un modelo de lenguaje, pone a prueba el conocimiento práctico del cielo nocturno y el manejo de instrumentación.
Lo que hace que estos problemas sean un estándar de oro para la evaluación de la inteligencia artificial es su naturaleza integradora. Para resolverlos, no basta con consultar una base de datos de hechos. Es necesario sintetizar conocimientos de múltiples áreas: la mecánica celeste, la termodinámica, la óptica y la física de partículas, entre otras. Se requiere una fluidez matemática para manipular ecuaciones complejas. Y, sobre todo, se necesita una intuición física para saber qué principios son relevantes, qué factores se pueden ignorar y qué camino es el más prometedor para llegar a una solución. Es esta combinación de conocimiento, habilidad y estrategia lo que define el razonamiento científico de alto nivel.
Conscientes de este potencial, los investigadores se embarcaron en la monumental tarea de transformar una década de problemas de la IOAA en un conjunto de datos estructurado y evaluable, al que llamaron AstroOlympiad. Recopilaron, tradujeron y estandarizaron cientos de preguntas de competiciones celebradas entre 2012 y 2022. Pero la verdadera innovación no residió en la recopilación, sino en el protocolo de evaluación que desarrollaron. En lugar de una simple calificación binaria de correcto o incorrecto, diseñaron un sistema de puntuación granular inspirado en las propias rúbricas de la olimpiada. Cada problema se descompuso en una serie de pasos lógicos o hitos de razonamiento.
Un modelo de lenguaje recibiría puntos no solo por alcanzar la respuesta final, sino por identificar correctamente los principios físicos aplicables, por plantear las ecuaciones adecuadas y por ejecutar correctamente las derivaciones matemáticas intermedias. Este enfoque les permitiría no solo saber qué tan bien lo hacía un modelo, sino, y más importante, entender por qué fallaba cuando lo hacía, proporcionando un diagnóstico preciso de sus fortalezas y debilidades.
Tabla 1: Comparación del rendimiento de los LLM con el rendimiento humano en los exámenes teóricos de la IOAA (2022-2025)
Tabla 2: Comparación del rendimiento de los LLM con el rendimiento humano en los exámenes de análisis de datos de la IOAA (2022-2025)
Los contendientes digitales en el escenario cósmico
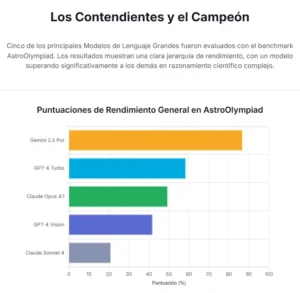
Una vez establecido el campo de batalla, el riguroso examen de la olimpiada, era el momento de presentar a los competidores. El equipo de investigación seleccionó a cinco de los modelos de lenguaje más potentes y reconocidos de la actualidad, representando la vanguardia de la tecnología desarrollada por las principales compañías del sector. Entre ellos se encontraban modelos de la familia GPT de OpenAI, como el GPT-4, y sus variantes más avanzadas; modelos de la familia Claude de Anthropic, conocidos por su capacidad para manejar contextos extensos y seguir instrucciones complejas; y el modelo más reciente de Google, Gemini. Cada uno de estos sistemas, con sus arquitecturas y filosofías de entrenamiento ligeramente diferentes, fue puesto a prueba frente al mismo conjunto de desafiantes problemas del cosmos.
Los resultados, al ser analizados, dibujaron un panorama fascinante y lleno de matices. No hubo un rendimiento homogéneo; por el contrario, las diferencias entre los modelos fueron notables, revelando distintas especializaciones y carencias. Algunos modelos demostraron tener un vasto conocimiento factual, respondiendo correctamente a preguntas que dependían de la recuperación de datos específicos, pero flaqueaban cuando se requería una manipulación matemática sostenida. Otros mostraban una mayor aptitud para el cálculo, pero a veces partían de premisas físicas incorrectas. Era una demostración clara de que no todos los «cerebros» digitales están construidos de la misma manera.
Sin embargo, entre todos ellos, un contendiente se alzó de manera decisiva. El modelo Gemini 2.5 Pro de Google no solo superó a sus rivales, sino que alcanzó una puntuación total que, de acuerdo con los umbrales históricos de la IOAA, lo habría hecho merecedor de una medalla de oro. Para poner esto en perspectiva, las medallas de oro en esta competición se otorgan a un porcentaje muy pequeño de los participantes, típicamente a aquellos que representan la élite absoluta de los jóvenes talentos en astrofísica a nivel mundial.
Que un sistema de inteligencia artificial, sin una formación específica para esta tarea, fuera capaz de operar a ese nivel, es un logro que redefine los límites de lo posible.
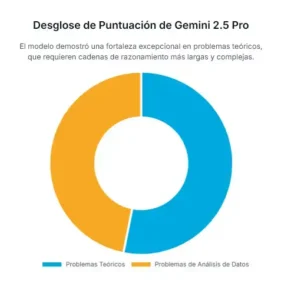
El rendimiento del modelo ganador fue especialmente destacable en los problemas teóricos, aquellos que requerían cadenas de razonamiento largas y complejas. Demostró una habilidad sorprendente para descomponer un problema en sub-problemas más manejables, para seleccionar las ecuaciones físicas pertinentes de entre las muchas posibles, y para llevar a cabo derivaciones algebraicas con un alto grado de precisión.
Su éxito no se basó en la suerte o en la memorización de problemas similares, sino en una aparente capacidad para generalizar principios y aplicarlos a situaciones novedosas, una habilidad que hasta ahora se consideraba un bastión del intelecto humano.
Los otros modelos, aunque no alcanzaron este nivel de excelencia, también mostraron destellos de capacidades avanzadas, logrando en muchos casos puntuaciones que los habrían situado en una posición respetable dentro de la competición, equivalentes a medallas de plata, bronce o menciones de honor. El experimento, en su conjunto, probó de manera concluyente que la barrera entre el simple conocimiento y el razonamiento complejo estaba empezando a desmoronarse.
Tabla 3: Rendimiento de los modelos por categoría de problema en las rondas teóricas de la IOAA
Anatomía de un éxito y las raíces del fracaso
El verdadero valor científico del estudio no reside únicamente en la noticia de la medalla de oro, sino en el análisis minucioso de qué hicieron bien los modelos y, sobre todo, dónde y por qué fallaron. Esta disección de los procesos de pensamiento digitales nos ofrece una ventana sin precedentes a la arquitectura cognitiva de estas inteligencias artificiales y nos marca el camino para futuras mejoras.
El éxito del modelo de mejor rendimiento se puede atribuir a una confluencia de factores. En primer lugar, una capacidad superior para la planificación de la solución. Ante un problema complejo, como determinar el tiempo que un satélite pasa sobre el hemisferio norte de un planeta, el modelo demostró ser capaz de trazar una estrategia general antes de sumergirse en los cálculos.
Identificaba la necesidad de trabajar con conceptos como la anomalía excéntrica y la anomalía verdadera, establecía las relaciones geométricas correctas y planteaba la integral necesaria. Esta habilidad para estructurar el pensamiento es fundamental en la resolución de problemas científicos. En segundo lugar, mostró una notable robustez matemática. Las largas derivaciones algebraicas, un punto débil para muchos modelos anteriores que a menudo cometen pequeños pero fatales errores de cálculo, fueron manejadas con una precisión sorprendente.
Finalmente, exhibió una forma de intuición física. Por ejemplo, en problemas que involucraban aproximaciones, como la aproximación de ángulo pequeño en trigonometría, el modelo fue capaz de discernir correctamente cuándo era válido y físicamente significativo aplicar dicha simplificación, un matiz que escapó a otros sistemas que o bien la aplicaban incorrectamente o la evitaban por completo.
Sin embargo, el análisis de los errores es quizás aún más instructivo. Los investigadores identificaron varios modos de fallo recurrentes que afectaban, en mayor o menor medida, a todos los modelos. Uno de los más significativos fue la dificultad con el razonamiento espacial tridimensional. La astronomía es una ciencia inherentemente geométrica, que requiere visualizar órbitas, orientaciones y proyecciones en el espacio.
Para los modelos de lenguaje, que operan en el dominio abstracto del texto, traducir una descripción verbal de una configuración espacial a una representación mental precisa sigue siendo un desafío formidable. Esto se manifestaba en errores a la hora de establecer relaciones angulares correctas o al interpretar diagramas.
Otro punto débil recurrente fue la tendencia a producir lo que los investigadores denominaron «respuestas centradas en la solución». En lugar de construir una derivación rigurosa desde los principios básicos, algunos modelos parecían «saltar» directamente a una fórmula conocida o a la expresión final, sin justificar los pasos intermedios. Este comportamiento sugiere que su entrenamiento, optimizado para encontrar la respuesta correcta de la manera más eficiente posible, a veces entra en conflicto con el rigor y la exhaustividad que exige la comunicación científica. Un científico no solo debe encontrar la respuesta, sino que debe convencer a sus pares de que su camino hacia ella es lógicamente sólido.
- Completitud matemática: Algunos modelos, incluso al llegar a la expresión matemática correcta, omitían la derivación, simplemente afirmando que el resultado se obtenía «después de resolver la integral», sin mostrar el trabajo.
- Razonamiento físico: La aplicación de principios físicos a veces era superficial, demostrando conocimiento de la fórmula pero no una comprensión profunda de su contexto o sus limitaciones.
Estos fracasos son cruciales porque nos recuerdan que, a pesar de su impresionante rendimiento, estos sistemas no «piensan» como los humanos. Sus errores no suelen ser de distracción o de falta de conocimiento, sino que parecen derivarse de limitaciones fundamentales en su arquitectura. No poseen un modelo del mundo físico como el que construimos los humanos a través de la experiencia sensorial. Su universo es un universo de texto, y su razonamiento, por potente que sea, es en última instancia un ejercicio de manipulación simbólica basado en patrones estadísticos. Entender estas raíces del fracaso es el primer paso para diseñar la próxima generación de inteligencias artificiales, unas que puedan razonar de una manera más robusta, transparente y alineada con los métodos de la ciencia.
El futuro de la ciencia con la inteligencia artificial
El logro de una medalla de oro por parte de una inteligencia artificial en un escenario tan exigente como la Olimpiada de Astronomía y Astrofísica es mucho más que una simple curiosidad técnica. Es una señal inequívoca de que estamos entrando en una nueva era de descubrimientos, una en la que la colaboración entre la mente humana y la inteligencia artificial puede acelerar nuestra comprensión del universo de formas que apenas comenzamos a imaginar. Este hito no anuncia la obsolescencia del científico humano, sino la llegada de un nuevo y extraordinariamente potente colaborador.
Las implicaciones de este avance son profundas. Para los investigadores, la perspectiva de tener un asistente de inteligencia artificial capaz de realizar derivaciones matemáticas complejas, de analizar conjuntos de datos en busca de patrones sutiles o de proponer nuevas hipótesis basadas en la totalidad de la literatura científica existente, es revolucionaria.
Podría liberar a los científicos de tareas tediosas y propensas a errores, permitiéndoles centrarse en los aspectos más creativos de su trabajo: la formulación de preguntas audaces, el diseño de experimentos ingeniosos y la interpretación del significado más profundo de los resultados. Podríamos ver cómo el ritmo del descubrimiento científico se acelera drásticamente, abordando problemas que hoy parecen intratables, desde la naturaleza de la materia oscura hasta la búsqueda de vida más allá de la Tierra.
Al mismo tiempo, el estudio nos insta a proceder con un optimismo cauteloso. Los fallos analizados, las carencias en el razonamiento espacial y la tendencia a la superficialidad en las derivaciones, nos recuerdan que estas herramientas aún están en su infancia. No poseen una verdadera comprensión, y su fiabilidad no es absoluta. La supervisión de expertos humanos seguirá siendo indispensable para validar sus resultados, para guiar su razonamiento y para evitar que nos conduzcan por caminos equivocados basados en errores sutiles pero fundamentales. El desarrollo de estas inteligencias artificiales debe ir de la mano con el desarrollo de métodos para hacerlas más transparentes, interpretables y robustas.
En última instancia, este trabajo nos proporciona una hoja de ruta. Al utilizar la IOAA como un benchmark, los investigadores no solo han medido el estado actual de la tecnología, sino que han definido un objetivo claro para el futuro: construir sistemas de inteligencia artificial que no solo conozcan la ciencia, sino que puedan practicarla con el rigor, la creatividad y la integridad que esta exige. La verdadera medalla de oro no será para la máquina que pueda resolver un problema de examen por sí sola, sino para la sinergia entre humanos y máquinas que nos permita desvelar un misterio del cosmos que ninguno de los dos podría haber resuelto por separado.
La nueva frontera de la exploración no está solo en las estrellas, sino también en la fascinante y compleja inteligencia que estamos creando para ayudarnos a alcanzarlas.
Fuentes
Carrit Delgado Pinheiro, L., Chen, Z., Caixeta Piazza, B., Shroff, N., Liang, Y., Ting, Y. S., & Sun, H. (2025). Large Language Models Achieve Gold Medal Performance at the International Olympiad on Astronomy & Astrophysics (IOAA). arXiv:2510.05016 [astro-ph.IM].
Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
Hendrycks, D., et al. (2021). Measuring Massive Multitask Language Understanding. Proceedings of the International Conference on Learning Representations.

