
En el corazón de la inteligencia artificial contemporánea late una aspiración fundamental: crear sistemas que no solo calculen, sino que comprendan y actúen en el mundo con un propósito. Imaginemos un robot doméstico cuya tarea es tan simple como recoger una taza de la mesa de la cocina y llevarla al fregadero. Para nosotros, es un acto casi inconsciente. Para la máquina, es un universo de complejidad.
El robot debe procesar un torrente de datos visuales, distinguir la taza de otros objetos, entender su propia posición y la de su objetivo, y luego coreografiar una secuencia de movimientos precisos para cumplir la orden. Ahora, compliquemos el escenario. La iluminación cambia, un gato cruza la escena, o en el televisor del fondo parpadea un anuncio con colores vibrantes.
¿Cómo sabe el robot qué información es relevante y cuál es mero ruido de fondo? Más aún, ¿cómo puede aprender a realizar no solo esta tarea, sino cualquier otra que le pidamos, como guardar un libro en la estantería o regar una planta?
Este desafío monumental es el campo de batalla de una disciplina dentro de la inteligencia artificial conocida como aprendizaje por refuerzo. A grandes rasgos, este paradigma de aprendizaje se inspira en la forma en que los seres vivos aprenden: a través de la prueba y el error. Un agente, ya sea un programa informático que juega al ajedrez o un brazo robótico, explora su entorno realizando acciones.
Cada acción produce un resultado y, ocasionalmente, una recompensa o un castigo. Con el tiempo, a través de innumerables intentos, el agente aprende a asociar ciertas acciones en determinados contextos con resultados positivos, forjando así una estrategia, o «política», para maximizar sus recompensas futuras. Es un proceso elegante en su simplicidad, pero que se enfrenta a un obstáculo formidable cuando las metas no son fijas, sino variables. Aquí es donde entra en juego el aprendizaje por refuerzo condicionado a metas (GCRL, por sus siglas en inglés), una subárea más sofisticada donde el objetivo no es una recompensa abstracta, sino alcanzar un estado específico y deseado. La orden ya no es «maximiza tu puntuación», sino «ve a la cocina» o «recoge la taza roja».
Para que un sistema de GCRL funcione eficazmente, debe superar dos problemas interconectados. El primero es la eficiencia de los datos. Entrenar a un robot en el mundo real es lento, costoso y potencialmente peligroso. Por ello, una de las fronteras más prometedoras es el aprendizaje fuera de línea, u «offline». En este enfoque, el agente no aprende explorando activamente el mundo, sino analizando un vasto conjunto de datos de experiencias pasadas, como si un piloto novato aprendiera a volar estudiando miles de horas de grabaciones de vuelo de pilotos expertos. El segundo problema, y quizás el más profundo, es el de la percepción o «representación».
¿Cómo debe el agente interpretar la avalancha de datos sensoriales que recibe? ¿Debe centrarse en los píxeles de una cámara, en las coordenadas de un mapa, en los ángulos de sus articulaciones? La elección de la representación es crítica, pues una mala elección puede hacer que el aprendizaje sea imposible, ahogando la información útil en un océano de datos irrelevantes.
Es en este intrincado cruce de caminos donde un trabajo reciente de investigadores de la Universidad de California, Berkeley, titulado «Dual Goal Representations», propone una solución tan radical como elegante. El estudio, firmado por Seohong Park, Deepinder Mann y el reconocido Sergey Levine, no ofrece un nuevo algoritmo de aprendizaje, sino algo más fundamental: una nueva forma de ver.
Plantean que la manera más robusta y eficaz de que un agente entienda su entorno no es caracterizando cada estado por sus propiedades intrínsecas (sus coordenadas, su apariencia visual), sino por sus relaciones con todos los demás estados.
En lugar de definir una ciudad por su latitud y longitud, proponen definirla por el tiempo que se tarda en viajar desde ella a todas las demás ciudades del mapa. Esta perspectiva, que denominan «representación dual», se basa en la «distancia temporal», es decir, el número mínimo de acciones necesarias para ir de un punto a otro.
Esta idea, aparentemente sencilla, tiene consecuencias transformadoras. Una representación dual es, por naturaleza, inmune al ruido irrelevante. La distancia temporal entre la mano de un robot y una taza no cambia si el color de la pared del fondo varía o si un anuncio parpadea en una pantalla. Además, este enfoque es indiferente a la forma en que se presentan los datos inicialmente; la red de distancias temporales es la misma tanto si el robot ve el mundo a través de una cámara de alta definición como si solo recibe las coordenadas de los objetos.
El sistema aprende la estructura funcional intrínseca del entorno, su «mapa de posibilidades», filtrando todo lo demás. Los investigadores de Berkeley han demostrado empíricamente que este enfoque no solo es teóricamente sólido, sino que mejora de manera consistente el rendimiento de los algoritmos existentes en una veintena de tareas complejas, desde la navegación en laberintos hasta la manipulación de objetos. Este artículo se adentra en los conceptos que sustentan esta investigación, explorando cómo una redefinición de la percepción podría ser la brújula que guíe a la próxima generación de inteligencias artificiales autónomas.
Una inmersión en el refuerzo condicionado a metas
Para apreciar la magnitud de la propuesta de las representaciones duales, es imprescindible comprender primero el terreno sobre el que se construye. El aprendizaje por refuerzo es una de las tres grandes familias del aprendizaje automático, junto al aprendizaje supervisado (aprender de ejemplos etiquetados) y el no supervisado (encontrar patrones en datos sin etiquetar). Su esencia es el aprendizaje a través de la interacción. El marco conceptual es simple y poderoso: un «agente» se encuentra en un «entorno» que puede ocupar diferentes «estados».
En cada estado, el agente puede elegir una «acción» de un conjunto de opciones disponibles. Al ejecutar esa acción, el entorno transita a un nuevo estado y proporciona al agente una «recompensa», que puede ser positiva, negativa o nula. El objetivo último del agente es aprender una «política», que es esencialmente un mapa que le dice qué acción tomar en cada estado para maximizar la suma acumulada de recompensas a lo largo del tiempo.
Pensemos en un programa que aprende a jugar al Pac-Man. El agente es el propio Pac-Man. El entorno es el laberinto, con sus pasillos, píldoras y fantasmas. Un estado podría ser la posición de Pac-Man, las píldoras restantes y la ubicación y dirección de los fantasmas. Las acciones son moverse arriba, abajo, izquierda o derecha. La recompensa es positiva al comer una píldora, muy positiva al comer una píldora de poder, y muy negativa al ser atrapado por un fantasma.
Al principio, Pac-Man se moverá al azar, sin ton ni son. Pero con el tiempo, después de miles de partidas, comenzará a asociar el hecho de moverse hacia una píldora con una pequeña recompensa y el de moverse hacia un fantasma con un castigo. Lentamente, construirá una política sofisticada: «si hay una píldora cerca y ningún fantasma, acércate a ella»; «si un fantasma está cerca, huye en dirección opuesta».
El aprendizaje por refuerzo condicionado a metas (GCRL) añade una capa de complejidad y generalización a este esquema. En lugar de una función de recompensa fija, el objetivo se convierte en un parámetro más del problema. La meta, g, es un estado particular que el agente debe alcanzar. La política del agente, por lo tanto, no solo depende del estado actual s, sino también de la meta g. La pregunta que el agente se hace ya no es «¿qué hago ahora para obtener la máxima recompensa?», sino «¿qué hago ahora, estando en s, para llegar a g?». Esto es fundamental para crear agentes versátiles. Un robot doméstico no tiene un único propósito, sino que debe ser capaz de cumplir una variedad de órdenes: «coge las llaves», «abre la puerta», «enciende la luz». Cada una de estas órdenes define una nueva meta.
El desafío del GCRL es la generalización. Es inviable entrenar al agente para cada posible meta por separado. El sistema debe aprender una política universal que funcione para cualquier meta que se le presente, incluso si nunca ha sido entrenado específicamente para ella. Debe entender la estructura general del entorno para poder planificar trayectorias hacia estados arbitrarios.
Para lograrlo, los algoritmos de GCRL a menudo intentan aprender una «función de valor» que estima el costo o la facilidad de alcanzar una meta g desde un estado s. Esta función es la que guía la toma de decisiones, permitiendo al agente elegir siempre la acción que, en su estimación, lo acerca más a su objetivo. La calidad de esta estimación depende críticamente de cómo el agente percibe, o representa, tanto su estado actual como su meta. Si la representación está contaminada por información irrelevante, la capacidad del agente para planificar y generalizar se verá severamente comprometida.

El paradigma del aprendizaje fuera de línea
El método tradicional de entrenamiento en aprendizaje por refuerzo es «en línea» y activo. El agente interactúa directamente con el entorno, recopilando experiencias a medida que explora. Este proceso, aunque efectivo, presenta serios inconvenientes en el mundo real. Entrenar un coche autónomo mediante prueba y error en carreteras reales sería catastróficamente peligroso.
De manera similar, entrenar a un agente para que ofrezca recomendaciones médicas interactuando con pacientes reales sería éticamente inconcebible. Además, la exploración activa puede ser extremadamente lenta y requerir millones de interacciones, lo que resulta prohibitivo para sistemas robóticos complejos cuyo hardware se desgasta.
Aquí es donde el aprendizaje por refuerzo fuera de línea, también conocido como «aprendizaje por lotes», emerge como una alternativa transformadora. La premisa es aprender de un conjunto de datos estático y preexistente de interacciones. En lugar de explorar el mundo por sí mismo, el agente recibe un gran «libro de historia» que contiene secuencias de estados, acciones y recompensas recopiladas previamente, posiblemente por otros agentes o incluso por humanos. La tarea del agente es extraer la mejor política posible a partir de estos datos fijos, sin la posibilidad de realizar nuevos experimentos para resolver ambigüedades.
Este paradigma ofrece ventajas inmensas. Permite aprovechar los enormes volúmenes de datos que se registran constantemente en innumerables campos: historiales de navegación web, registros de transacciones financieras, datos de sensores de procesos industriales o grabaciones de vídeo de cámaras de seguridad. Permite entrenar políticas en simulaciones y luego aplicarlas en el mundo real con mayor seguridad. Sin embargo, el aprendizaje fuera de línea introduce un desafío fundamental conocido como el «cambio distribucional».
El conjunto de datos preexistente fue generado por alguna política de comportamiento que puede ser muy diferente, y probablemente subóptima, a la política que se está intentando aprender. El agente podría evaluar una acción que parece prometedora pero que nunca o rara vez se tomó en los datos en esa situación. Estimar el resultado de tales acciones «fuera de distribución» es notoriamente difícil y propenso a errores de extrapolación que pueden llevar a políticas desastrosas.
Por ejemplo, si un conjunto de datos de conducción autónoma fue recopilado principalmente en carreteras secas y soleadas, un agente que aprenda de él podría tener dificultades para evaluar correctamente los riesgos de conducir a alta velocidad en una carretera helada, simplemente porque carece de suficientes ejemplos de esa situación. Para mitigar esto, los algoritmos de aprendizaje fuera de línea deben ser conservadores. Deben evitar desviarse demasiado de las acciones y estrategias presentes en el conjunto de datos, limitando sus decisiones a aquello que pueden respaldar con la evidencia disponible.
En este contexto de datos fijos y la imposibilidad de exploración, la calidad de la representación del estado se vuelve aún más crucial. El agente debe ser capaz de exprimir hasta la última gota de información útil del conjunto de datos, identificando patrones sutiles y, sobre todo, distinguiendo las correlaciones causales de las espurias. Si la representación es deficiente, el agente puede ser engañado fácilmente por el «ruido» presente en los datos, llevándolo a aprender políticas ineficaces o peligrosas.
El problema de la representación del estado
Todo agente de inteligencia artificial interactúa con el mundo a través de un prisma: su representación del estado. Esta representación es la traducción del desordenado y continuo mundo real al lenguaje estructurado y numérico que un algoritmo puede procesar. La forma de esta traducción determina fundamentalmente lo que el agente puede aprender y cuán eficientemente puede hacerlo.
Consideremos de nuevo al robot doméstico. Su estado podría representarse de varias maneras:
- Una representación de bajo nivel, como la matriz de píxeles en bruto de su cámara. Esta opción es rica en detalles, pero también abrumadoramente compleja y llena de información redundante. El brillo de una ventana o la sombra de una silla son visualmente prominentes, pero a menudo irrelevantes para la tarea de coger una taza.
- Una representación de alto nivel, como un conjunto de coordenadas
(x, y, z)para el robot, la taza y otros objetos clave. Esta opción es mucho más compacta y directa, pero requiere un sistema de percepción previo que identifique los objetos y estime su posición, lo cual puede ser propenso a errores.
El problema se agrava con la presencia de «factores de variación exógenos», comúnmente denominados ruido. Se trata de cualquier elemento dentro de la observación del estado que no afecta a la dinámica subyacente del entorno ni a la tarea en cuestión. El ejemplo del televisor parpadeante en el fondo es paradigmático. Para el sistema visual del robot, el televisor es una parte significativa de la entrada de datos. Un algoritmo de aprendizaje ingenuo podría encontrar correlaciones espurias entre los cambios en la pantalla y el éxito o fracaso de sus acciones.
Podría, por ejemplo, concluir erróneamente que solo puede coger la taza cuando en la pantalla aparece un color determinado, una conclusión absurda que impediría cualquier generalización robusta.
Este es un problema endémico en el aprendizaje automático. Los sistemas son expertos en encontrar patrones, pero no distinguen inherentemente entre correlaciones significativas y coincidencias fortuitas. Si la representación del estado no filtra activamente esta información exógena, la tarea de aprendizaje se vuelve exponencialmente más difícil. El agente debe dedicar una parte considerable de su capacidad a aprender a ignorar el ruido, en lugar de centrarse en la dinámica relevante del problema.
Los métodos tradicionales para abordar esto a menudo se basan en técnicas de aumento de datos (por ejemplo, alterando aleatoriamente los colores o fondos de las imágenes de entrenamiento) o en el aprendizaje de representaciones «disentangled» (desenredadas), donde se intenta que diferentes neuronas de la red se especialicen en capturar factores de variación independientes.
Sin embargo, estos enfoques a menudo requieren un ajuste manual considerable y no garantizan que el sistema aprenda a ignorar precisamente los factores correctos. La necesidad de una representación que sea intrínsecamente robusta al ruido y que capture la esencia funcional del entorno es, por tanto, uno de los santos griales de la disciplina.
Una nueva forma de entender el espacio
La propuesta de Park, Mann y Levine es un cambio de paradigma en la forma de abordar este problema. En lugar de intentar limpiar o desenredar una representación basada en las características intrínsecas de un estado, proponen abandonarla por completo en favor de una basada en relaciones. Su concepto de «representación dual» se fundamenta en la idea de que la identidad de un estado se define mejor por su conexión con todos los demás estados.
La métrica que utilizan para medir esta conexión es la «distancia temporal». En el contexto del aprendizaje por refuerzo, la distancia temporal d*(s, g) entre un estado s y una meta g se define como el número mínimo de pasos o acciones que una política óptima necesitaría para transitar de s a g. No es una distancia geométrica en el espacio, sino una distancia funcional en el «gráfico de estados» del entorno. Dos estados pueden estar físicamente cerca pero temporalmente distantes si, por ejemplo, hay un muro entre ellos que obliga a dar un largo rodeo.
Con esta herramienta, la representación dual de un estado s (o de una meta g) se construye como un vector, una larga lista de números, donde cada número es la distancia temporal desde s a otro estado del entorno. Así, la representación φ(s) sería [d*(s, s_1), d*(s, s_2), d*(s, s_3), ...], abarcando todos los estados posibles s_i. Esta perspectiva relacional conlleva propiedades teóricas de enorme calado.
La primera es la invarianza a la representación original. La red de distancias temporales es una propiedad intrínseca de la dinámica del entorno, no de cómo lo percibimos. El número de pasos para ir de la cocina al salón es el mismo, independientemente de si estamos viendo la casa a través de una cámara, un plano arquitectónico o un sensor LiDAR. Al transformar la percepción a este espacio dual, el agente se deshace de la dependencia de la modalidad sensorial original. Aprende una descripción del mundo que es puramente funcional.
La segunda propiedad es la robustez al ruido exógeno. La distancia temporal entre la mano del robot y la taza es una función de la física del robot y la disposición de los objetos. Esta distancia no se ve afectada en absoluto por el contenido del televisor del fondo, la hora del día o el color de las paredes. Por lo tanto, una representación dual filtra de forma natural e inherente toda la información que no es causalmente relevante para la interacción con el entorno. Las correlaciones espurias simplemente desaparecen.
La tercera propiedad es la suficiencia. Los autores demuestran matemáticamente que esta representación, a pesar de descartar tanta información (como la apariencia visual), retiene toda la información necesaria para reconstruir una política óptima. Conocer el «mapa de distancias» completo es suficiente para poder navegar eficientemente por el entorno. La representación dual logra el equilibrio perfecto: es lo suficientemente abstracta para ser robusta, pero lo suficientemente rica para ser funcional.
En la práctica, calcular las distancias a todos los demás estados es inviable en entornos complejos. Los investigadores proponen una solución pragmática: aprender un codificador que mapea las observaciones de estado a un espacio latente donde la distancia euclidiana en ese espacio se aproxima a la distancia temporal real.
Este codificador se entrena utilizando técnicas de aprendizaje auto-supervisado sobre el conjunto de datos fuera de línea, aprendiendo a predecir la distancia temporal entre pares de estados extraídos de las trayectorias registradas. El resultado es un «módulo de percepción» que puede conectarse a cualquier algoritmo de GCRL existente para proporcionarle una visión del mundo más limpia, estructurada y funcional.

El método y la validación empírica
Una idea, por elegante que sea en teoría, debe demostrar su valía en el campo de pruebas de la experimentación. Los investigadores de Berkeley sometieron su método a una rigurosa evaluación utilizando OGBench, una suite de benchmarks diseñada específicamente para probar algoritmos de aprendizaje por refuerzo fuera de línea en tareas de manipulación y navegación robótica. Un benchmark es un conjunto estandarizado de problemas que sirve como una vara de medir común para comparar el rendimiento de diferentes enfoques de manera justa y reproducible.
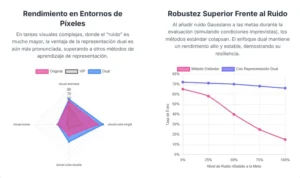
Los experimentos abarcaron un espectro de veinte tareas con diferentes niveles de dificultad. Algunas de ellas se basaban en «estados», donde el agente recibe información limpia y estructurada como las coordenadas de los objetos. Otras, mucho más desafiantes, se basaban en «píxeles», obligando al agente a interpretar imágenes en bruto, un escenario mucho más cercano a las aplicaciones del mundo real y donde los problemas de ruido exógeno son especialmente agudos.
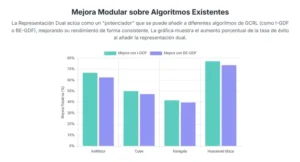
El equipo integró su módulo de representación dual con varios de los algoritmos de GCRL más avanzados hasta la fecha y comparó su rendimiento con el de los mismos algoritmos utilizando sus mecanismos de representación originales.
Los resultados fueron notablemente consistentes y positivos. La incorporación de las representaciones duales mejoró el rendimiento en prácticamente todas las tareas. En los entornos basados en estados, el nuevo método demostró ser más robusto y eficiente. Pero fue en los entornos basados en píxeles donde el impacto fue más espectacular. En estas tareas, donde los algoritmos tradicionales a menudo se ven confundidos por la complejidad visual y el ruido, el enfoque dual permitió a los agentes aprender políticas significativamente mejores, logrando un mayor porcentaje de éxito en la consecución de sus metas.
Un experimento particularmente revelador fue diseñado para probar explícitamente la robustez al ruido. Los investigadores tomaron un entorno de manipulación robótica y añadieron un factor de ruido exógeno: un fondo de vídeo que cambiaba constantemente y sin relación alguna con la tarea.
Como era de esperar, el rendimiento de los algoritmos estándar se degradó notablemente. Sin embargo, el método de representación dual mantuvo su eficacia, demostrando en la práctica su capacidad para «ver a través» del ruido y centrarse en la estructura causal subyacente del problema. Los resultados empíricos validaron sólidamente las promesas teóricas del marco dual: invarianza, robustez y suficiencia.
Horizontes: el impacto más allá del laboratorio
El trabajo sobre las representaciones duales de metas no es simplemente una mejora incremental en un subcampo de la inteligencia artificial. Es una invitación a repensar uno de los pilares fundamentales del aprendizaje automático: la percepción. Al proponer un cambio de una visión del mundo basada en características a una basada en relaciones, abre nuevas vías para la creación de agentes más autónomos, robustos y generalizables.
La relevancia científica de esta investigación radica en su capacidad para conectar la teoría con la práctica de una manera elegante. Ofrece un marco con fundamentos matemáticos sólidos que aborda directamente el problema del ruido y la invarianza, y lo traduce en un método práctico que puede potenciar a toda una familia de algoritmos existentes.
Es un ejemplo de cómo un avance conceptual en la comprensión de la información puede tener un impacto más profundo que el mero desarrollo de arquitecturas de redes neuronales más grandes o complejas.
Tecnológicamente, las implicaciones son vastas. La robótica es el campo de aplicación más inmediato. Robots de almacén, asistentes domésticos o vehículos autónomos que operen en los entornos desordenados y dinámicos del mundo real se beneficiarían enormemente de una percepción que filtra lo irrelevante y se centra en lo funcional. Podrían adaptarse más fácilmente a nuevos entornos sin necesidad de un reentrenamiento masivo, ya que su comprensión del mundo se basaría en la «física» de las posibles acciones, no en la apariencia superficial de las cosas.
Más allá de la robótica, este enfoque podría mejorar sistemas en áreas como las finanzas, donde los modelos deben extraer señales de mercado de datos extremadamente ruidosos, o en la medicina, donde el análisis de historiales de pacientes podría beneficiarse de una representación que capture las trayectorias funcionales de las enfermedades en lugar de correlaciones superficiales.
A nivel social, cada paso hacia una inteligencia artificial más robusta y fiable es un paso hacia su integración segura y beneficiosa en nuestras vidas. Sistemas que son menos frágiles, menos susceptibles de ser engañados por datos extraños o maliciosos, son sistemas en los que podemos depositar una mayor confianza.
El enfoque dual representa un avance en esta dirección, promoviendo una IA que no solo memoriza patrones, sino que construye un modelo interno del mundo basado en lo que es posible hacer en él. Es una transición sutil pero crucial de la apariencia a la función, del qué al cómo.
En última instancia, el concepto de la representación dual resuena con ideas profundas de la ciencia cognitiva y la filosofía. Nos recuerda que nuestra propia comprensión del mundo no se basa únicamente en las propiedades sensoriales de los objetos, sino en la red de relaciones y posibilidades que nos conectan con ellos. No vemos una silla solo como una colección de madera y tela, sino como «algo en lo que sentarse».
Esta investigación nos proporciona una nueva y poderosa herramienta matemática para infundir una pizca de esa comprensión funcional en nuestras máquinas, equipándolas con una brújula interna para navegar por la abrumadora complejidad del mundo real.
Bibliografía
Park, S., Mann, D., & Levine, S. (2025). Dual Goal Representations. Preprint, arXiv:2510.06714.
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. The MIT Press.
Levine, S., Kumar, A., Tucker, G., & Fu, J. (2020). Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. Preprint, arXiv:2005.01643.
Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., … & de Freitas, N. (2018). Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. Proceedings of the 35th International Conference on Machine Learning.

