
El sueño de una mente artificial capaz de dominar cualquier desafío intelectual ha sido el motor de la ciencia de la computación durante más de medio siglo. Es una ambición que resuena en nuestra cultura, desde los autómatas calculistas de la ciencia ficción hasta las batallas épicas libradas en tableros de ajedrez y Go. Estas contiendas, más que meros espectáculos, han servido como hitos, como faros que iluminan el progreso y la dirección de la inteligencia artificial (IA). Cada una de estas confrontaciones entre el hombre y la máquina ha revelado una faceta distinta de la inteligencia, obligándonos a redefinir constantemente lo que significa pensar, aprender y comprender.
La historia de esta búsqueda puede contarse a través de sus campeones. En 1997, el mundo contuvo la respiración mientras Deep Blue, la supercomputadora de IBM, derrotaba al campeón mundial de ajedrez Garry Kasparov. Fue un momento sísmico, la culminación de décadas de investigación. Sin embargo, la inteligencia de Deep Blue era de una naturaleza particular, casi ajena. No aprendía ni intuía.
Su poder residía en la fuerza bruta computacional, la capacidad de evaluar doscientos millones de posiciones por segundo, guiada por reglas y heurísticas meticulosamente programadas por sus creadores humanos. Deep Blue no entendía el ajedrez en el sentido humano; lo calculaba. Su victoria fue un triunfo de la ingeniería, una demostración de que un conjunto de reglas bien definidas, ejecutado a una velocidad sobrehumana, podía superar la intuición y la experiencia del mejor cerebro humano en un dominio cerrado y lógico.
Casi dos décadas después, en 2016, la historia se repitió, pero el protagonista era radicalmente diferente. AlphaGo, una creación de DeepMind, se enfrentó a Lee Sedol, uno de los más grandes jugadores de Go de todos los tiempos, y lo venció. El Go, con su tablero expansivo y sus posibilidades astronómicas, que superan el número de átomos en el universo, era inmune a la fuerza bruta que había coronado a Deep Blue. La victoria de AlphaGo representó un cambio de paradigma. Su mente no estaba programada con las estrategias de los grandes maestros; había aprendido a jugar por sí misma.
Utilizando una técnica conocida como aprendizaje por refuerzo (Reinforcement Learning), AlphaGo jugó millones de partidas contra sí misma, descubriendo patrones y estrategias que ningún humano había concebido. Su inteligencia no era explícita y programada, sino emergente y estadística. Aprendió a través de la experiencia, de un proceso de ensayo y error a una escala monumental, ajustando las conexiones en su vasta red neuronal para predecir los movimientos más prometedores.
Este salto de Deep Blue a AlphaGo marcó una evolución fundamental: pasamos de máquinas que seguían reglas a máquinas que aprendían patrones. Sin embargo, incluso la mente de AlphaGo permanecía, en esencia, como una caja negra. Sus decisiones surgían de un complejo cálculo probabilístico distribuido a través de millones de parámetros, una red tan intrincada que ni sus propios creadores podían explicar por completo el porqué de un movimiento específico. Su «comprensión» del juego era una forma de intuición estadística, poderosa pero inescrutable.
Ahora, un nuevo capítulo se está escribiendo, uno que promete unificar la lógica explícita de la era de Deep Blue con la capacidad de aprendizaje flexible de AlphaGo, superando las limitaciones de ambas. Un trabajo de investigación reciente, titulado «Code World Models for General Game Playing», presenta un enfoque revolucionario que podría redefinir una vez más nuestra concepción de la inteligencia artificial. La idea central es tan elegante como potente: ¿qué pasaría si, en lugar de aprender patrones estadísticos opacos, una IA pudiera aprender a escribir un programa de ordenador, un simulador, que represente las reglas y la dinámica del mundo que observa?
Este concepto introduce una nueva arquitectura cognitiva para las máquinas, basada en tres pilares fundamentales. El primero es el ya mencionado aprendizaje por refuerzo, el motor de ensayo y error que impulsa a la IA a mejorar. El segundo es una idea que ha fascinado a los investigadores durante años: los modelos de mundo (World Models). Un modelo de mundo es, en esencia, una simulación interna que una mente, ya sea biológica o artificial, construye para predecir el futuro. Es la capacidad de imaginar, de preguntarse «¿qué pasaría si…?».
Un jugador de ajedrez que visualiza los próximos cinco movimientos está usando un modelo de mundo. Un físico que calcula mentalmente la trayectoria de una pelota antes de lanzarla está haciendo lo mismo. Para una IA, tener un modelo de mundo le permite planificar y aprender de forma mucho más eficiente, ensayando acciones en su «imaginación» sin necesidad de interactuar costosa y lentamente con el mundo real.
El tercer y más novedoso pilar es el poder de los grandes modelos de lenguaje (Large Language Models o LLMs), los sistemas que han asombrado al mundo con su capacidad para generar texto, traducir idiomas y mantener conversaciones coherentes. Una de sus habilidades emergentes más sorprendentes es su aptitud para entender y escribir código informático funcional. Han aprendido, en cierto sentido, el lenguaje de la lógica pura.
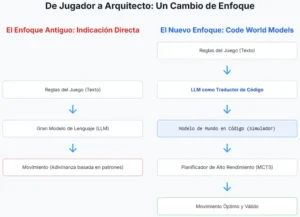
El trabajo de investigación fusiona estos tres elementos en una síntesis brillante. Propone un agente de IA que, al observar un juego, no se limita a aprender qué acciones conducen a una recompensa. En su lugar, utiliza un LLM para realizar una tarea mucho más profunda: inferir las reglas subyacentes del juego y articularlas en forma de código. La IA aprende a programar su propio simulador del mundo. Este enfoque, denominado Modelo de Mundo en Código (Code World Model o CWM), representa un salto cualitativo.
La comprensión de la IA ya no es meramente procedimental (Deep Blue) ni puramente estadística (AlphaGo). Se convierte en una comprensión estructural y causal. La máquina no solo aprende qué hacer, sino que aprende y puede expresar cómo funciona el mundo. Este artículo explorará en profundidad esta nueva arquitectura de la inteligencia, desentrañando su funcionamiento, sus logros, sus limitaciones y las profundas implicaciones que tiene para el futuro de la IA, un futuro en el que las mentes artificiales podrían ser no solo más inteligentes, sino también, por primera vez, verdaderamente comprensibles.
La arquitectura de la imaginación artificial
Para comprender la magnitud del avance que representan los Modelos de Mundo en Código, primero debemos sumergirnos en el concepto de la imaginación artificial y por qué ha sido un objetivo tan codiciado y elusivo en el campo de la IA. La inteligencia, en su forma más fundamental, es la capacidad de tomar decisiones acertadas para alcanzar un objetivo. Sin embargo, los caminos para llegar a esa capacidad son muy distintos.
Imaginemos dos enfoques para aprender a navegar por un laberinto. El primer enfoque, conocido en IA como «libre de modelo» (model-free), consiste en vagar sin rumbo. Cada vez que llegamos a un callejón sin salida, nos damos la vuelta. Cada vez que encontramos un camino que nos acerca a la salida, reforzamos esa elección. Con suficientes intentos, miles o millones de ellos, eventualmente memorizaríamos la ruta correcta. Este método es robusto, pero increíblemente ineficiente. Es aprender a través de la experiencia directa y cruda, como tocar un fogón caliente mil veces para asociarlo con el dolor. La mayoría de los primeros éxitos del aprendizaje por refuerzo, incluido el dominio de muchos videojuegos de Atari, se basaron en esta estrategia.
Ahora consideremos un segundo enfoque, denominado «basado en modelo» (model-based). En lugar de vagar sin rumbo, después de unos pocos pasos por el laberinto, nos detenemos, sacamos un lápiz y un papel, y empezamos a dibujar un mapa. A medida que exploramos, añadimos más detalles a nuestro mapa. Pronto, ya no necesitamos explorar físicamente cada rincón. Podemos mirar nuestro mapa, nuestro modelo interno del laberinto, y planificar la ruta óptima hacia la salida sin dar un solo paso más. Esta es la esencia de un modelo de mundo: una representación interna y predictiva del entorno que permite la simulación y la planificación. Es la diferencia entre aprender por repetición y aprender por comprensión.
El poder de los modelos de mundo es inmenso. Permiten una eficiencia de datos drásticamente mayor. El agente no necesita experimentar todas las situaciones posibles en el mundo real; puede imaginarlas. Esto es crucial para aplicaciones en el mundo real, donde la recopilación de datos es costosa o peligrosa. No queremos que un coche autónomo choque mil veces para aprender a no chocar; queremos que pueda simular miles de escenarios de colisión en su «mente» y aprender de ellos de forma segura.
La idea de dotar a las máquinas de esta capacidad de imaginación no es nueva. Los primeros intentos en la IA simbólica trataban de construir estos modelos a mano, programando explícitamente las reglas de la física y la lógica. Sin embargo, este enfoque resultó ser frágil y difícil de escalar a la complejidad del mundo real. Con el advenimiento del aprendizaje profundo, surgieron nuevos métodos. Sistemas como Dreamer aprendieron a construir modelos de mundo utilizando redes neuronales.
Estos modelos toman el estado actual del entorno (por ejemplo, los píxeles de una pantalla de videojuego) y predicen cómo se verá la pantalla en el siguiente instante de tiempo si se realiza una acción determinada. Al encadenar estas predicciones, la IA puede «soñar» con secuencias enteras de posibles futuros, aprendiendo comportamientos complejos enteramente dentro de su simulación interna.
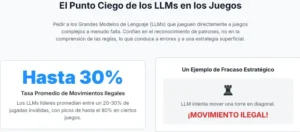
A pesar de su éxito, estos modelos de mundo neuronales sufren de una limitación fundamental: el problema de la caja negra. El «mapa» que construyen no es un diagrama legible, sino un vasto conjunto de números, los pesos y sesgos de una red neuronal de millones de parámetros. La simulación que se ejecuta en su interior es un patrón de activación eléctrica que fluye a través de esta red. Es como un sueño humano: sabemos que estamos simulando una realidad, pero no podemos inspeccionar fácilmente el «código fuente» de ese sueño para entender sus reglas. Esta opacidad es una barrera formidable.
Si el modelo de mundo de un robot comete un error en su simulación, es extremadamente difícil diagnosticar por qué. No podemos simplemente «mirar» su comprensión de la gravedad para ver si es correcta. Esta falta de interpretabilidad genera problemas de confianza, seguridad y depuración, limitando severamente la aplicación de estos sistemas en dominios críticos.
Es en este punto donde la convergencia de diferentes campos de la IA se vuelve crucial para entender el surgimiento de los Modelos de Mundo en Código. Este avance no es el producto de una única línea de investigación, sino el resultado de la colisión casi inevitable de tres trayectorias que han madurado en paralelo. Por un lado, el aprendizaje por refuerzo ha estado lidiando durante años con el problema de la eficiencia de los datos, identificando los modelos de mundo como la solución teórica, pero luchando por construir modelos que sean a la vez precisos y comprensibles.
Por otro lado, el campo del procesamiento del lenguaje natural ha evolucionado hasta crear modelos generativos a gran escala, cuya capacidad para escribir código funcional surgió como una propiedad emergente casi inesperada. Finalmente, las técnicas de planificación y búsqueda, perfeccionadas desde los días de Deep Blue, estaban listas para ser aplicadas sobre cualquier modelo de mundo que fuera lo suficientemente rápido y preciso.
Los creadores del CWM reconocieron que la habilidad de los LLMs para generar código podría ser la pieza que faltaba para resolver el problema central de los modelos de mundo en el aprendizaje por refuerzo. En lugar de pedirle a una red neuronal que aprenda un modelo predictivo opaco, le pidieron a un LLM que realizara una tarea de abstracción mucho más elevada: observar el comportamiento de un sistema y deducir y escribir el programa que lo gobierna. El CWM es, por tanto, un punto de encuentro, una síntesis que utiliza la capacidad de razonamiento simbólico de un modelo de lenguaje para crear el simulador explícito que un agente de aprendizaje por refuerzo necesita para aprender de manera eficiente y transparente.
Cuando la máquina aprende a programar el mundo
El mecanismo central del Modelo de Mundo en Código es una danza elegante entre la observación, la hipótesis y la experimentación, un proceso que refleja sorprendentemente el propio método científico. La IA, a la que llamaremos CWM-1, no se limita a consumir datos pasivamente; se convierte en un detective digital, un físico computacional que busca descubrir las leyes fundamentales que rigen su pequeño universo de píxeles. El proceso se desarrolla en un bucle iterativo de refinamiento, una conversación entre el agente y su propio modelo generativo.
Todo comienza con la observación. A CWM-1 se le presenta una pequeña cantidad de datos de un juego, quizás solo unos pocos minutos de una partida jugada por un humano o por otro agente. Estos datos consisten en secuencias de fotogramas (los píxeles de la pantalla) y las acciones correspondientes que se tomaron (por ejemplo, «joystick a la izquierda», «botón de salto presionado»). Para una IA tradicional, este sería el comienzo de un largo proceso de búsqueda de correlaciones estadísticas. Para CWM-1, es la evidencia inicial a partir de la cual debe formular una teoría del mundo.
A continuación, entra en juego el corazón del sistema: un potente modelo de lenguaje grande, preentrenado en un vasto corpus de texto y código. El agente procesa los datos observados y los utiliza para formular una pregunta, un «prompt», dirigido al LLM. Esta no es una pregunta simple. Es una meta-pregunta que le pide al modelo que actúe como un programador y un físico a la vez: «Dadas estas secuencias de observaciones y acciones, escribe un programa simple en Python que simule la dinámica de este entorno. Identifica los objetos clave, sus propiedades (como posición y velocidad) y las reglas que gobiernan sus interacciones (como la gravedad o las colisiones)».
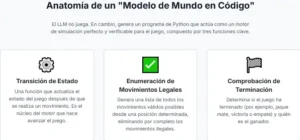
El LLM, aprovechando su conocimiento abstracto del mundo y su dominio de la sintaxis de la programación, genera una primera hipótesis en forma de código. Para un juego como Pong, podría generar un programa que defina dos objetos pala y un objeto bola, cada uno con atributos posicion_x, posicion_y, velocidad_x y velocidad_y. El código incluiría funciones para actualizar estas posiciones en cada paso de tiempo y lógica condicional para gestionar los rebotes con las palas y los bordes de la pantalla. Este programa es el primer borrador del modelo de mundo, una teoría explícita y legible sobre cómo funciona el juego.
El paso crucial es la verificación y el refinamiento. CWM-1 no confía ciegamente en este primer borrador. Se convierte en su propio experimentador. Utiliza el programa recién generado como un simulador para ejecutar miles de partidas en su «imaginación», mucho más rápido de lo que podría hacerlo en el entorno real del juego. Luego, compara los resultados de estas simulaciones internas con los datos reales que observó inicialmente. ¿Coinciden las trayectorias de la bola? ¿Se comportan los rebotes como en el juego real? Inevitablemente, habrá discrepancias. Quizás la «gravedad» en su modelo es demasiado fuerte, o la velocidad de la bola es incorrecta.
Cuando se detecta una discrepancia, el bucle se cierra. CWM-1 identifica el error y formula un nuevo prompt para el LLM, esta vez mucho más específico: «Mi simulación actual, basada en el código que generaste, no coincide con los datos observados en este punto. La bola en mi simulación se mueve más lento que en la realidad. Por favor, refina la función actualizar_bola en el código para que el modelo se ajuste mejor a la evidencia empírica». El LLM recibe esta retroalimentación y genera una versión corregida del código. Este ciclo de generar código, probarlo, encontrar errores y refinarlo se repite una y otra vez. Con cada iteración, el programa-simulador se vuelve una representación más fiel de la realidad del juego.
El papel del LLM en este proceso es fundamental. Actúa como un motor de abstracción. La IA no está simplemente mapeando píxeles a acciones. Está realizando un salto conceptual extraordinario: transforma datos brutos y de alta dimensión (los píxeles de la pantalla) en una representación simbólica, compacta y de bajo nivel (el código). Para poder escribir una línea de código como jugador.y += jugador.velocidad_y, el sistema primero debe haber inferido la existencia de conceptos como «jugador», «posición vertical» y «velocidad vertical» a partir de un flujo de imágenes sin estructura.
Esta capacidad de abstracción automática es una de las piedras angulares de la inteligencia superior. Los humanos no percibimos el mundo como una matriz de valores de color; lo percibimos como un conjunto de objetos con propiedades y relaciones. Cuando vemos un juego, vemos un «personaje» que «salta» sobre «plataformas». CWM-1 está aprendiendo a hacer exactamente lo mismo, pero formalizando esa comprensión en el lenguaje inequívoco de la programación.
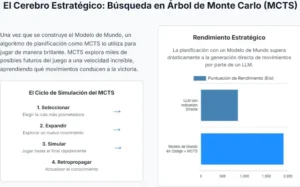
Esto sugiere un camino hacia inteligencias artificiales que no solo reconozcan patrones, sino que construyan activamente sus propios marcos conceptuales para entender el mundo. No son meros aprendices, sino constructores de modelos, científicos en miniatura que descubren el «código fuente» de la realidad que se les presenta. Una vez que el simulador es lo suficientemente preciso, el agente puede utilizarlo para aprender a jugar de forma óptima, planificando sus acciones dentro de este mundo imaginado, seguro y ultrarrápido, antes de aplicarlas en el entorno real.
CWM-1 en acción: más allá del tablero
La verdadera prueba de cualquier nueva arquitectura de IA no reside en su elegancia teórica, sino en su rendimiento en el mundo real, o en este caso, en los mundos virtuales de los videojuegos. Los investigadores detrás del Modelo de Mundo en Código sometieron a su agente, CWM-1, a un riguroso conjunto de desafíos diseñados para evaluar su flexibilidad, eficiencia y los límites de su comprensión. Utilizaron una amplia gama de entornos, desde los clásicos del Arcade Learning Environment hasta juegos de estrategia por turnos más simples, creando un campo de pruebas diverso para su nueva creación.
Los resultados, según se informa en el estudio, son notables en varios frentes. En juegos con reglas claras y una física determinista, como Pong o Breakout, CWM-1 demostró una capacidad de aprendizaje asombrosa. Tras observar apenas unos miles de fotogramas de juego, una cantidad trivial en comparación con los millones o decenas de millones que requieren los agentes tradicionales, el sistema fue capaz de generar un simulador casi perfecto. Una vez que tuvo este «código fuente» del juego, podía entrenarse dentro de su propia simulación a una velocidad vertiginosa, generando cantidades ilimitadas de datos perfectos y alcanzando un rendimiento sobrehumano en un tiempo récord.
Quizás más impresionante fue su desempeño en juegos con una complejidad causal más profunda, como el infame Montezuma’s Revenge, un juego de plataformas conocido por ser una prueba de fuego para la IA debido a su necesidad de planificación a largo plazo. Los agentes tradicionales a menudo luchan en este entorno porque las recompensas son escasas y requieren una larga secuencia de acciones precisas para ser alcanzadas. CWM-1 abordó el problema de una manera diferente.
En lugar de aprender ciegamente una política de acción, se centró en modelar la física del juego: cómo salta el personaje, cómo caen las llaves, cómo se mueven los enemigos. Al generar un modelo de código de estas mecánicas, pudo planificar secuencias de acciones complejas en su simulación, superando obstáculos que habrían requerido millones de intentos de ensayo y error para un agente libre de modelo.
Sin embargo, tan importante como sus éxitos son sus fracasos, ya que estos delinean las fronteras de la tecnología actual y señalan el camino para futuras investigaciones. El estudio informa honestamente sobre las limitaciones de CWM-1. El sistema encontró dificultades significativas en entornos que no se prestaban a una descripción programática simple y discreta. Por ejemplo, en simuladores de carreras con una física de vehículos muy compleja y continua, el LLM luchó por capturar las sutiles dinámicas en un código conciso. Su modelo del mundo era una aproximación burda, lo que llevaba a un rendimiento deficiente.
De manera similar, los juegos con elementos estocásticos o aleatorios significativos plantearon un desafío. Si un enemigo tiene un comportamiento impredecible, es difícil capturarlo en un código determinista. El modelo de CWM-1 asumía un mundo ordenado y regido por leyes, y se confundía cuando la aleatoriedad rompía esas leyes. Además, el enfoque se mostró completamente inadecuado para juegos que requieren razonamiento social, engaño o teoría de la mente, como los juegos de póquer o estrategia compleja con información imperfecta. La comprensión de CWM-1 se basa en la física y la lógica del entorno, no en la psicología de sus oponentes.
Para contextualizar el salto cualitativo que representa CWM-1, es útil compararlo con sus predecesores históricos en una serie de dimensiones clave.
| Parámetro | Deep Blue (Simbólico/Experto) | AlphaGo (Deep Reinforcement Learning) | CWM-1 (Modelo de Mundo en Código) |
| Método Principal | Búsqueda en árbol con heurísticas codificadas por humanos. | Redes neuronales profundas y Búsqueda de Árbol Monte Carlo. | Generación de código por LLM para crear un simulador interno y planificación. |
| Generalización | Nula. Específico para ajedrez. | Limitada. Requiere reentrenamiento masivo para nuevos juegos. | Alta. Capaz de adaptarse a cualquier juego con una estructura lógica subyacente. |
| Eficiencia de Muestra | No aplicable (basado en reglas). | Muy baja. Requiere millones de partidas para aprender. | Muy alta. Requiere una cantidad mínima de datos para inferir las reglas. |
| Interpretabilidad | Muy alta. Su lógica es explícita y programada. | Muy baja. Es una «caja negra» de parámetros neuronales. | Muy alta. Su «mente» es un programa de código legible por humanos. |
| Mecanismo de «Comprensión» | Ejecución de reglas pre-programadas. | Reconocimiento de patrones estadísticos en los datos. | Inferencia de la lógica causal y las reglas del entorno. |
Esta tabla ilustra una clara trayectoria. Pasamos de un sistema con una comprensión explícita pero frágil (Deep Blue), a uno con una comprensión flexible pero opaca (AlphaGo), y finalmente a un sistema que aspira a combinar lo mejor de ambos mundos: una comprensión flexible, generalizable y, lo que es más importante, transparente. CWM-1 no es el jugador de juegos definitivo, pero su rendimiento y sus limitaciones pintan un cuadro claro de una nueva y poderosa herramienta en el arsenal de la inteligencia artificial.
La promesa de una mente transparente
Más allá de la destreza en los videojuegos, la implicación más profunda del enfoque del Modelo de Mundo en Código es la promesa de una inteligencia artificial interpretable. Durante la última década, a medida que las redes neuronales profundas se han vuelto más potentes y omnipresentes, una creciente inquietud ha permeado el campo: estamos construyendo sistemas cada vez más inteligentes que no entendemos del todo.
El problema de la caja negra no es una mera curiosidad académica; es una barrera fundamental para el despliegue seguro y responsable de la IA en áreas de alto riesgo. ¿Cómo podemos confiar en el diagnóstico de una IA médica si no puede explicar su razonamiento? ¿Cómo podemos certificar la seguridad de un coche autónomo si sus decisiones surgen de un cálculo inescrutable?
Los Modelos de Mundo en Código ofrecen una alternativa radical a este paradigma. La «mente» de CWM-1, su conocimiento acumulado sobre cómo funciona el mundo, no está codificada en un mar de parámetros numéricos, sino en un programa de ordenador. Este programa puede ser leído, analizado, depurado y verificado por un experto humano. Si un agente CWM que controla un robot industrial comete un error, podríamos, en teoría, examinar su código de simulación física y descubrir que tiene una comprensión incorrecta de la fricción. Esta transparencia cambia las reglas del juego para la seguridad y la confianza en la IA. La depuración de la «comprensión» de una IA se convierte en un problema de ingeniería de software, un dominio que hemos dominado durante décadas, en lugar de un misterio neurocientífico.
Esta transparencia también abre la puerta a niveles de generalización y transferencia de conocimiento mucho más potentes. Un agente de aprendizaje por refuerzo tradicional que aprende a jugar a un juego de plataformas aprende un conjunto de patrones visuales y respuestas motoras. Si se le presenta un juego nuevo, incluso uno con una física similar, a menudo tiene que empezar a aprender desde cero.
En contraste, un agente CWM que aprende a jugar al primer juego lo hace generando un módulo de código que podría llamarse motor_de_fisica_plataformas.py, que incluye conceptos como gravedad, friccion y salto. Cuando se enfrenta a un nuevo juego de plataformas, podría reutilizar este módulo de código, adaptando solo los parámetros específicos. Está transfiriendo no solo patrones, sino conceptos abstractos y causales, una forma de aprendizaje mucho más cercana a la humana.
Además, este enfoque fomenta una nueva y poderosa simbiosis entre humanos y máquinas. En lugar de ser meros usuarios o entrenadores de sistemas de IA opacos, los humanos pueden convertirse en colaboradores directos en la construcción de su conocimiento. Un programador humano podría examinar el modelo de mundo generado por una IA, identificar un error sutil en su lógica, corregir el código directamente y reinsertarlo en el sistema. Esto crea un bucle de retroalimentación virtuoso en el que la intuición de la máquina para extraer modelos de los datos se combina con el profundo conocimiento del dominio y la capacidad de razonamiento abstracto del ser humano.
Las repercusiones de este cambio se extienden más allá de los laboratorios de investigación y podrían remodelar el panorama económico y regulatorio de la inteligencia artificial. Actualmente, el desarrollo de sistemas de IA de vanguardia es un campo dominado por un puñado de gigantes tecnológicos, debido en gran parte a los enormes recursos computacionales necesarios para entrenar modelos masivos y a los equipos de especialistas necesarios para intentar interpretar y validar su comportamiento. Un enfoque como el CWM, al ser mucho más eficiente en el uso de datos y inherentemente transparente, podría democratizar el campo. Equipos más pequeños, con presupuestos más modestos, podrían ser capaces de desarrollar sistemas de IA robustos y verificables para nichos específicos.
Desde una perspectiva regulatoria, legislar el comportamiento de una caja negra es casi imposible. Las regulaciones actuales a menudo se centran en los datos de entrenamiento o en los resultados estadísticos, pero no pueden abordar el proceso de toma de decisiones en sí. Sin embargo, auditar un programa de ordenador es una práctica estándar. El surgimiento de modelos de IA basados en código podría dar lugar a nuevos estándares de certificación.
Podríamos imaginar un futuro en el que, para ser desplegada en sectores críticos como las finanzas, la medicina o el transporte autónomo, una IA deba presentar su modelo de mundo en código para una auditoría pública o gubernamental. Esto crearía un marco para la rendición de cuentas que es simplemente inalcanzable con la tecnología actual, allanando el camino para una adopción más amplia y segura de la inteligencia artificial en la sociedad.

Horizontes de la inteligencia programada
Los videojuegos, con sus mundos autocontenidos y sus reglas claras, siempre han sido para la investigación en IA lo que la mosca de la fruta fue para la genética: un microcosmos ideal para experimentar, fallar y aprender en un entorno controlado. Son el campo de entrenamiento donde se forjan las tecnologías destinadas a transformar el mundo real.
El Modelo de Mundo en Código, aunque se ha demostrado en el dominio lúdico de los juegos, apunta hacia un horizonte de aplicaciones mucho más vasto y significativo. Su verdadero potencial no reside en crear mejores jugadores de videojuegos, sino en desarrollar una nueva clase de IA capaz de actuar como un socio en el descubrimiento científico y la resolución de problemas complejos.
Imaginemos una versión futura de esta tecnología aplicada a la biología. Un sistema de IA podría observar miles de horas de metraje de microscopía de interacciones celulares y, en lugar de simplemente clasificar comportamientos, podría generar un programa informático que simule el metabolismo de la célula, una teoría viva y comprobable de sus mecanismos internos. Los biólogos podrían entonces interactuar con este modelo, modificándolo y probando hipótesis, acelerando el ritmo del descubrimiento.
En el campo de la robótica, un robot equipado con un CWM podría interactuar con un objeto desconocido durante unos segundos, no para aprender una acción específica, sino para escribir un mini simulador de física para ese objeto. Con este modelo interno, podría predecir cómo rodará, se deslizará o caerá el objeto, permitiéndole manipularlo con una destreza y previsión sin precedentes.
Incluso el campo de la ingeniería de software podría ser transformado. Una IA podría observar a un usuario interactuando con una aplicación con errores y, en lugar de simplemente registrar el fallo, podría inferir la lógica subyacente del programa y generar el parche de código necesario para corregir el error lógico que causó el problema.
Más allá de estas aplicaciones tecnológicas, el enfoque del CWM representa un cambio filosófico sutil pero profundo en nuestra búsqueda de la inteligencia artificial. Durante años, el paradigma dominante del aprendizaje profundo se ha centrado en la correlación, en encontrar patrones estadísticos en enormes cantidades de datos. Este enfoque ha sido increíblemente exitoso, pero se aleja de la forma en que la ciencia tradicional ha progresado.
La ciencia no se trata solo de encontrar correlaciones; se trata de construir modelos, de formular teorías causales que expliquen las observaciones y hagan predicciones comprobables. El Modelo de Mundo en Código alinea a la IA mucho más estrechamente con este espíritu de la razón y el descubrimiento científico. Fomenta una inteligencia que no solo reconoce, sino que busca explicar.
No estamos ante el final del camino. Los Modelos de Mundo en Código son una tecnología incipiente, con limitaciones significativas que requerirán años de investigación para superar. La complejidad del mundo real, con su ruido, su incertidumbre y sus interacciones infinitamente ricas, es órdenes de magnitud mayor que la de cualquier videojuego. Sin embargo, el camino que señalan es inconfundiblemente emocionante.
Representa un movimiento que se aleja de la creación de oráculos opacos y se acerca a la construcción de herramientas transparentes, de socios intelectuales cuyo razonamiento podemos examinar, cuestionar y mejorar. El objetivo final de la inteligencia artificial no debería ser simplemente crear máquinas que nos den las respuestas correctas, sino crear máquinas que nos ayuden a comprender mejor el mundo.
Al aprender a programar el mundo, estas nuevas IA podrían, a su vez, darnos una nueva forma de leer su código fuente, abriendo una nueva era de colaboración entre la inteligencia humana y la artificial en la interminable búsqueda del conocimiento.
Referencias
Hafner, D., Lillicrap, T., Ba, J., & Norouzi, M. (2019). Dream to Control: Learning Behaviors by Latent Imagination. arXiv preprint arXiv:1912.01603.
Hassabis, D., & Silver, D. (2017). AlphaGo: A case study in AI research. AI Magazine, 38(2), 10-14.
Lehrach W. et al. (2025) Code world models for general game playing. arXiv preprint arXiv:2510.04542.
Schrittwieser, J., et al. (2020). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature, 588(7839), 604-609.

