
La inteligencia artificial ha irrumpido en el panorama de la investigación científica con una fuerza transformadora que promete redefinir cómo concebimos el descubrimiento y la innovación algorítmica. En el corazón de esta revolución se encuentra DeepEvolve, un sistema que representa un salto cualitativo en la capacidad de las máquinas para no solo ejecutar algoritmos existentes, sino para crearlos, mejorarlos y perfeccionarlos de manera autónoma. Este avance, documentado en el paper «Scientific Algorithm Discovery by Augmenting AlphaEvolve with Deep Research», constituye un hito en la evolución de los agentes científicos automatizados que trasciende las limitaciones de los enfoques previos.
Para comprender la magnitud de este logro, es esencial contextualizar el estado actual del campo. Los modelos de lenguaje de gran escala han demostrado capacidades extraordinarias en tareas de razonamiento, síntesis de información y generación de código, estableciendo los cimientos para el desarrollo de asistentes científicos automatizados. Sin embargo, los sistemas existentes adolecen de limitaciones fundamentales que restringen su aplicabilidad en dominios científicos complejos.
Por un lado, los enfoques basados puramente en evolución algorítmica, como AlphaEvolve, dependen exclusivamente del conocimiento interno de los modelos de lenguaje, lo que resulta en un estancamiento rápido cuando se enfrentan a problemas en dominios especializados como la química, la biología o la ciencia de materiales. Por otro lado, los métodos de investigación profunda tradicionales se centran en la generación de hipótesis sin mecanismos de validación experimental, produciendo propuestas que frecuentemente resultan poco realistas o imposibles de implementar en la práctica.
DeepEvolve surge como una respuesta innovadora a esta dicotomía, integrando de manera sinérgica la investigación profunda con la evolución algorítmica bajo un marco unificado. El sistema combina tres elementos fundamentales que lo distinguen de sus predecesores: la recuperación de conocimiento externo a través de búsquedas web especializadas, la edición de código across múltiples archivos simultáneamente, y la depuración sistemática mediante retroalimentación iterativa.
Esta arquitectura permite que cada iteración no solo proponga nuevas hipótesis, sino que también las refine, las implemente como código funcional y las valide experimentalmente, evitando tanto las mejoras superficiales como los refinamientos improductivos que caracterizan a los sistemas anteriores.
La metodología subyacente de DeepEvolve se fundamenta en un bucle de retroalimentación continua que opera a través de seis componentes interconectados. El proceso inicia con una fase de planificación que genera preguntas de investigación específicas destinadas a guiar la dirección de las mejoras algorítmicas. Estas preguntas se procesan posteriormente mediante agentes de búsqueda especializados que consultan fuentes académicas como PubMed y arXiv, sintetizando la información relevante en resúmenes estructurados.
Un agente escritor integra entonces esta evidencia externa con el contexto del problema específico, produciendo propuestas algorítmicas que incluyen pseudocódigo detallado para facilitar la implementación posterior. La fase de codificación implementa estas propuestas mediante la modificación precisa de múltiples archivos de código, mientras que un agente de depuración especializado resuelve errores durante la ejecución. Finalmente, la evaluación automática proporciona métricas de rendimiento que retroalimentan al sistema para la siguiente iteración evolutiva.
Una característica distintiva del sistema radica en su capacidad para mantener una base de datos evolutiva que preserva el conocimiento acumulado a lo largo de las iteraciones. Esta base implementa algoritmos inspirados tanto en MAP-Elites como en modelos poblacionales basados en islas, permitiendo la exploración eficiente del espacio de soluciones mientras mantiene la diversidad algorítmica.
El sistema samplea candidatos prometedores y algoritmos inspiradores basándose en tres dimensiones críticas: puntuación de rendimiento, diversidad de código y complejidad computacional. Esta estrategia evolutiva asegura que el proceso de búsqueda mantenga un equilibrio óptimo entre la explotación de soluciones exitosas y la exploración de nuevas direcciones algorítmicas.
Los resultados experimentales validan la efectividad del enfoque a través de nueve benchmarks que abarcan dominios científicos diversos, desde la predicción de propiedades moleculares hasta la resolución de ecuaciones diferenciales parciales, pasando por problemas geométricos de empaquetado y análisis de patentes.
En cada caso, DeepEvolve demostró mejoras consistentes sobre los algoritmos iniciales, con incrementos de rendimiento que oscilan desde el 0.39% hasta el extraordinario 666.02% en problemas específicos. Estas mejoras no son meramente cuantitativas; representan avances cualitativos en la comprensión algorítmica, incorporando técnicas sofisticadas como el aprendizaje contrastivo, la estimación de incertidumbre bayesiana, el enmascaramiento consciente de motivos moleculares y la regularización físicamente informada.
La arquitectura técnica del sistema refleja un diseño meticulosamente orquestado donde cada componente cumple una función especializada mientras contribuye al objetivo colectivo del descubrimiento algorítmico. Los agentes de investigación profunda emplean modelos de lenguaje especializados para diferentes tareas: planificación, búsqueda, reflexión y escritura de propuestas. Esta especialización permite que cada fase del proceso de investigación se optimice independientemente, mejorando la calidad y relevancia de las hipótesis generadas.
Los agentes de codificación, por su parte, implementan capacidades avanzadas de análisis multi-archivo, localizando con precisión las regiones de código que requieren modificación y aplicando cambios específicos sin alterar la funcionalidad existente.
El mecanismo de depuración representa una innovación técnica significativa, abordando uno de los desafíos más persistentes en la generación automática de código complejo. Mediante el análisis de mensajes de error y advertencias durante la ejecución, el sistema puede identificar y corregir problemas sintácticos, lógicos y de integración de manera autónoma. Esta capacidad es particularmente crucial cuando se implementan ideas algorítmicas novedosas que involucran múltiples componentes interdependientes, una situación común en aplicaciones científicas reales.
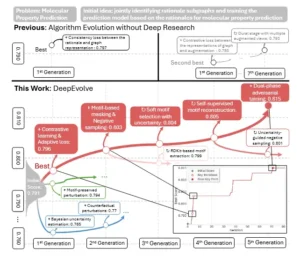
El panel superior muestra la evolución del algoritmo puro al estilo AlphaEvolve sin investigación exhaustiva, donde la mayor mejora se observa en la primera generación y las iteraciones posteriores presentan mejoras marginales. El panel inferior muestra DeepEvolve, que integra investigación exhaustiva. DeepEvolve evita evoluciones superficiales o excesivamente profundas pero improductivas, logrando un progreso sostenido con claros saltos de rendimiento en iteraciones clave. + indica la adición de una nueva idea y ⟳ indica el refinamiento de una idea previa.
La arquitectura revolucionaria de DeepEvolve
El marco metodológico de DeepEvolve representa una convergencia sofisticada entre la investigación científica tradicional y la optimización algorítmica automatizada. El sistema opera mediante un operador de actualización que transforma iterativamente los algoritmos candidatos a través de seis módulos especializados aplicados secuencialmente: planificación, búsqueda, escritura, codificación, evaluación y selección evolutiva. Esta arquitectura modular permite que cada componente se optimice independientemente mientras mantiene la coherencia sistémica necesaria para el descubrimiento científico efectivo.
La fase de planificación constituye el núcleo estratégico del sistema, generando preguntas de investigación que orientan la exploración algorítmica hacia direcciones prometedoras. El agente planificador, implementado con modelos de lenguaje especializados, analiza el contexto del problema, el historial evolutivo previo y los algoritmos inspiradores para formular entre cinco y diez consultas de investigación diversas y específicas. Esta diversidad es crucial para evitar la convergencia prematura hacia soluciones localmente óptimas, un problema común en los sistemas de optimización tradicionales.
El módulo de búsqueda ejecuta estas consultas mediante acceso directo a bases de datos académicas especializadas, incluyendo PubMed para investigación biomédica y arXiv para trabajos en matemáticas, física e informática. Esta capacidad de recuperación de conocimiento externo distingue fundamentalmente a DeepEvolve de sistemas previos que dependían exclusivamente del conocimiento preentrenado en los modelos de lenguaje. Los resultados de búsqueda se procesan y sintetizan en resúmenes estructurados que capturan los hallazgos más relevantes para el problema específico en cuestión.
La síntesis de propuestas representa quizás el componente más sofisticado del sistema. El agente escritor integra la evidencia recuperada con el contexto del problema y los algoritmos inspiradores, evaluando múltiples direcciones algorítmicas potenciales según criterios de originalidad, potencial futuro y dificultad de implementación. Este proceso de evaluación multicritério asegura que las propuestas seleccionadas representen un equilibrio óptimo entre ambición científica y viabilidad práctica. Las propuestas incluyen pseudocódigo detallado y notas de implementación específicas que guían la fase subsiguiente de codificación.
El agente de codificación implementa capacidades avanzadas de análisis y modificación multi-archivo, una funcionalidad ausente en sistemas previos como AlphaEvolve. Mediante delimitadores específicos, el sistema puede parsear bases de código complejas, localizar las regiones precisas que requieren modificación e implementar cambios específicos sin comprometer la funcionalidad existente. Esta capacidad es esencial para aplicaciones científicas reales, donde las mejoras algorítmicas frecuentemente involucran modificaciones coordinadas en múltiples componentes del sistema.
La depuración sistemática aborda uno de los desafíos más significativos en la generación automática de código científico. El agente de depuración analiza mensajes de error y advertencias durante la ejecución, aplicando correcciones específicas basadas en patrones aprendidos y retroalimentación del programa. Con un presupuesto configurable de intentos de corrección, el sistema puede resolver la mayoría de los problemas de implementación de manera autónoma, incrementando sustancialmente la tasa de éxito en la ejecución de algoritmos novedosos.
La base de datos evolutiva implementa una combinación innovadora de algoritmos MAP-Elites e islas poblacionales, proporcionando un mecanismo sofisticado para la gestión del conocimiento a largo plazo. MAP-Elites mantiene un archivo de los mejores algoritmos organizados según tres dimensiones: rendimiento, diversidad y complejidad. Este archivo se actualiza continuamente, preservando soluciones de alta calidad mientras explora regiones diversas del espacio de búsqueda. El modelo de islas poblacionales, por su parte, mantiene múltiples poblaciones independientes que migran soluciones prometedoras a intervalos regulares, promoviendo tanto la especialización como la diversidad genética algorítmica.
Resultados experimentales que redefinen el panorama
La validación experimental de DeepEvolve abarca nueve benchmarks cuidadosamente seleccionados que representan desafíos significativos en dominios científicos diversos. Estos problemas van desde la predicción de propiedades moleculares en química hasta la segmentación de núcleos celulares en biología, pasando por la resolución de ecuaciones diferenciales parciales en matemáticas y el análisis semántico de patentes. La diversidad de modalidades de datos incluye moléculas pequeñas, imágenes microscópicas, secuencias de ARN, series temporales, estructuras geométricas y contenido multimodal, proporcionando una evaluación comprehensiva de la capacidad de generalización del sistema.
En el dominio de predicción de propiedades moleculares, DeepEvolve demostró mejoras consistentes sobre el método inicial de racionalización de grafos GREA, incrementando el rendimiento desde 0.7915 hasta 0.8149, lo que representa una mejora del 2.96%. Más significativamente, el sistema desarrolló algoritmos que incorporan aprendizaje contrastivo con vistas aumentadas duales, enmascaramiento consciente de motivos moleculares y entrenamiento adversarial de fase dual. Estas innovaciones no solo mejoran la precisión predictiva, sino que también incrementan la interpretabilidad de las predicaciones mediante la identificación de subestructuras moleculares relevantes.
El problema de traducción molecular, que requiere convertir imágenes de estructuras químicas en cadenas InChI, mostró mejoras dramáticas del 35.94%, elevando el rendimiento desde 0.1885 hasta 0.2562. El algoritmo evolucionado integra arquitecturas transformer preentrenadas con decodificación consciente de gramática química, técnicas de aumento de datos sofisticadas incluyendo rotación, desplazamiento y perturbaciones de iluminación, y programación adaptativa de pérdidas múltiples. Esta combinación permite al sistema manejar la complejidad inherente de la traducción imagen-a-secuencia en el contexto químico especializado.
El empaquetado de círculos presentó quizás los resultados más dramáticos, con una mejora del 666.02% que eleva el rendimiento desde 0.3891 hasta 2.9806. Esta mejora extraordinaria se debe principalmente a que el algoritmo inicial estaba diseñado para configuraciones fijas y frecuentemente producía soluciones inválidas para tamaños variables. DeepEvolve desarrolló un enfoque basado en diagramas de poder que garantiza empaquetados válidos, incorporando múltiples puntos de inicio, técnicas de optimización estables y verificación matemática de restricciones. El algoritmo resultante no solo es más robusto sino que proporciona garantías formales de validez.
En problemas biológicos, los resultados varían según la complejidad y madurez de los algoritmos iniciales. La predicción de progresión de Parkinson mostró mejoras del 11.82%, incorporando modelos de ecuaciones diferenciales controladas neurales para modelado continuo de trayectorias de enfermedad y preprocesamiento adaptativo wavelet para datos de series temporales. La segmentación de núcleos celulares logró un incremento del 6.91% mediante la introducción de PointRend para refinamiento de bordes ambiguos y módulos de estimación de incertidumbre calibrada que refinan selectivamente regiones de baja confianza.
Los resultados cualitativos, evaluados mediante LLMs como jueces especializados, demuestran que DeepEvolve genera consistentemente algoritmos con mayor originalidad y potencial futuro comparados con los métodos iniciales. Las puntuaciones de originalidad oscilan entre 4 y 8 puntos sobre 10, mientras que el potencial futuro alcanza niveles similares. Significativamente, aunque la dificultad de implementación se incrementa debido a la sofisticación de los algoritmos propuestos, el sistema de depuración automática mejora las tasas de éxito de ejecución desde rangos de 0.13-0.96 hasta 0.49-1.00 across diferentes tareas.
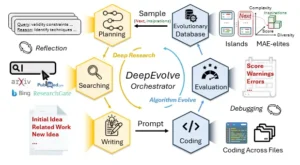
DeepEvolve se estructura en torno a seis módulos colaborativos que alternan entre la investigación profunda y la evolución de algoritmos. La investigación profunda genera hipótesis fundamentadas mediante la planificación, la recuperación y la síntesis, mientras que la evolución de algoritmos traduce estas hipótesis a código, las evalúa y aplica estrategias evolutivas para la selección.
Innovaciones técnicas y arquitectura del sistema
La implementación técnica de DeepEvolve revela una arquitectura cuidadosamente diseñada donde cada componente contribuye a la funcionalidad colectiva del descubrimiento algorítmico. Los agentes de investigación profunda emplean una especialización modelo-específica que optimiza cada fase del proceso investigativo. El agente planificador utiliza o4-mini para generar estrategias de búsqueda, mientras que gpt-4o ejecuta las consultas especializadas y o3-mini sintetiza los hallazgos en propuestas algorítmicas coherentes. Esta especialización permite que cada modelo opere dentro de sus fortalezas específicas, maximizando la efectividad del proceso investigativo.
El agente de codificación implementa un sistema de análisis multi-archivo sofisticado que puede parsear bases de código complejas mediante delimitadores específicos. Esta capacidad trasciende las limitaciones de sistemas previos que operaban exclusivamente sobre archivos individuales. El sistema localiza con precisión las regiones de código que requieren modificación, aplicando cambios específicos mientras preserva la funcionalidad existente. Los bloques DEEPEVOLVE proporcionan trazabilidad clara de las modificaciones, permitiendo la auditoría y reversión de cambios específicos cuando sea necesario.
La depuración automática representa una innovación técnica significativa que aborda los desafíos inherentes de la generación de código científico complejo. El agente de depuración analiza mensajes de error, advertencias y comportamientos inesperados durante la ejecución, aplicando correcciones basadas en patrones aprendidos y heurísticas específicas del dominio. Con presupuestos configurables de intentos de corrección, el sistema puede resolver la mayoría de los problemas de implementación autónomamente, incrementando las tasas de éxito desde niveles base de 13-65% hasta rangos de 49-100% según el dominio específico.
La base de datos evolutiva combina elementos de MAP-Elites con modelos poblacionales de islas para crear un sistema de gestión de conocimiento de largo plazo particularmente sofisticado. El archivo MAP-Elites organiza algoritmos según tres dimensiones clave: puntuación de rendimiento, diversidad de código medida por distancia Levenshtein, y complejidad computacional evaluada por longitud de código y dependencias. Cada dimensión se normaliza al rango y se discretiza en 10 bins, creando un espacio de coordenadas 3D donde cada celda contiene el mejor algoritmo para esa combinación específica de características.
El modelo de islas mantiene hasta 25 algoritmos distribuidos across cinco islas independientes, cada una evolucionando especializaciones particulares. La selección de candidatos equilibra explotación y exploración con probabilidades 0.7 y 0.3 respectivamente, donde la explotación samplea el mejor algoritmo en la isla actual. La migración entre islas ocurre a intervalos fijos, transfiriendo los mejores programas a islas vecinas con una tasa de migración del 10%. Este diseño promueve tanto la especialización local como la diversidad global, evitando la convergencia prematura mientras mantiene la capacidad de exploración continua.
Los mecanismos de reflexión proporcionan checkpoints críticos tanto en la investigación profunda como en la implementación de código. Para la investigación, un agente de reflexión determina si continuar la planificación, extender la búsqueda o actualizar el reporte de escritura, sujeto a un número máximo de reflexiones. Para la codificación, la reflexión verifica la alineación del código implementado con la propuesta algorítmica original y detecta errores sintácticos potenciales antes de la evaluación formal.
Casos de estudio reveladores
El análisis detallado de casos específicos ilustra cómo DeepEvolve navega la complejidad de dominios científicos diversos, adaptando su estrategia evolutiva a las características particulares de cada problema. En predicción molecular, el sistema evolucionó desde algoritmos básicos de racionalización de grafos hacia enfoques sofisticados que integran múltiples paradigmas de aprendizaje automático. La trayectoria evolutiva comenzó estableciendo pérdidas contrastivas sobre vistas aumentadas de rationales, progresando hacia enmascaramiento consciente de motivos que dirige la atención hacia subestructuras químicamente significativas.
Las iteraciones subsiguientes introdujeron selección suave de motivos basada en incertidumbre, permitiendo al modelo priorizar dinámicamente subgrafos informativos. La incorporación de objetivos de reconstrucción autosupervisados encouragió al modelo a recuperar motivos enmascarados, mientras que el entrenamiento adversarial de fase dual mejoró la robustez bajo desplazamientos de distribución. Esta progresión demuestra cómo el sistema puede construir complejidad algorítmica incrementalmente, donde cada innovación se fundamenta sobre descubrimientos previos.
En traducción molecular, DeepEvolve navegó la complejidad del procesamiento multimodal imagen-a-texto, evolucionando desde arquitecturas básicas encoder-decoder hacia sistemas que aprovechan modelos foundation preentrenados. La primera versión utilizó un encoder ViT congelado con un decoder GPT-2 small, incorporando tokenización consciente de moléculas para manejar la generación estructurada. Las iteraciones posteriores agregaron técnicas de aumento de datos incluyendo rotaciones, desplazamientos y perturbaciones de iluminación, junto con decodificación consciente de gramática química.
Las versiones avanzadas implementaron pérdidas duales combinando entropía cruzada con distancia de edición suave, equilibradas mediante programación lambda dinámica. Esta evolución ilustra cómo el sistema puede integrar conocimiento específico del dominio (gramática química) con técnicas generales de aprendizaje automático, produciendo soluciones que son tanto técnicamente sofisticadas como prácticamente viables.
El empaquetado de círculos presentó desafíos únicos de optimización combinatoria que DeepEvolve abordó mediante una transición fundamental desde colocación geométrica básica hacia métodos que garantizan soluciones válidas. La primera versión utilizó diagramas de poder para colocación sin superposición, refinando posiciones mediante optimización. Versiones posteriores incorporaron múltiples puntos de inicio y técnicas de optimización estables para mejorar la confiabilidad.
Las iteraciones avanzadas introdujeron ajustes controlados pequeños para corregir estimaciones iniciales pobres y verificación matemática para certificar que los resultados finales satisfacen completamente las restricciones de empaquetado.
En ecuaciones de Burgers, el sistema progresó a través de tres etapas evolutivas distintas. La primera etapa introdujo un solver de diferencias finitas Euler explícito con aceleración GPU y stepping adaptativo, mejorado posteriormente con control basado en error y salida densa para precisión y registro de snapshots. La segunda etapa transicionó hacia métodos espectrales con integración temporal IMEX-Euler, integrando fusión de kernels GPU y FFTs autoajustados para soluciones más rápidas y precisas. La tercera etapa se enfocó en evaluación avanzada de funciones φ, interpolación Hermite de alto orden y stepping adaptativo refinado, formando un solver espectral robusto y de alta precisión.

Cambios de puntuaciones a lo largo de las iteraciones.
Implicaciones transformadoras para el futuro científico
Las implicaciones de DeepEvolve trascienden los logros técnicos específicos documentados en la investigación, señalando hacia un futuro donde la inteligencia artificial no solo asiste sino que lidera activamente el descubrimiento científico. El sistema demuestra que es posible automatizar el ciclo completo de investigación científica, desde la generación de hipóteses hasta la implementación y validación experimental, estableciendo un precedente para el desarrollo de científicos artificiales completamente autónomos.
La capacidad del sistema para operar across dominios científicos diversos sugiere la emergencia de principios algorítmicos universales que trascienden disciplinas específicas. Los patrones metodológicos recurrentes identificados por DeepEvolve, incluyendo estimación de incertidumbre, reweighting dinámico de pérdidas y aprendizaje de representaciones autosupervisado, aparecen consistentemente across tareas en química, biología, matemáticas y ciencia de materiales. Esta convergencia indica que el sistema no solo extrae insights específicos del dominio sino que también identifica y aplica principios algorítmicos fundamentales de aplicabilidad general.
El impacto potencial en la educación científica y el entrenamiento de investigadores es igualmente significativo. DeepEvolve proporciona un laboratorio virtual donde estudiantes y investigadores pueden observar el proceso completo de descubrimiento científico, desde la formulación de preguntas de investigación hasta la implementación y validación de soluciones. Esta capacidad pedagógica podría revolucionar cómo se enseña la metodología científica, proporcionando ejemplos concretos y reproducibles de innovation algorítmica en acción.
Las implicaciones económicas del descubrimiento algorítmico automatizado son potencialmente transformadoras para industrias que dependen intensivamente de innovación computacional. Sectores como el farmacéutico, donde el desarrollo de nuevos medicamentos requiere algoritmos sofisticados para predicción molecular y diseño de fármacos, podrían experimentar aceleraciones dramáticas en sus ciclos de desarrollo. Similarmente, industrias de materiales avanzados, semiconductores y energía renovable podrían beneficiarse de algoritmos optimizados automáticamente para sus desafíos computacionales específicos.
El sistema también plantea cuestiones importantes sobre el futuro del trabajo científico y la colaboración humano-AI. Mientras que DeepEvolve demuestra capacidades impresionantes en automatización del descubrimiento, la supervisión humana permanece crucial para establecer objetivos científicos, interpretar resultados y tomar decisiones sobre direcciones de investigación. Esta complementariedad sugiere un futuro colaborativo donde científicos humanos y sistemas AI trabajan en partnership, combinando la creatividad y intuición humanas con la capacidad computacional y sistematicidad de la AI.
Las consideraciones éticas del descubrimiento científico automatizado requieren atención cuidadosa. La capacidad de generar algoritmos novedosos a velocidades sin precedentes plantea preguntas sobre validación, reproducibilidad y responsabilidad científica. El desarrollo de marcos regulatorios y estándares de calidad para algoritmos generados automáticamente será crucial para asegurar que estos avances beneficien a la sociedad mientras minimizan riesgos potenciales.
El futuro de DeepEvolve y sistemas similares likely involucrará integration con infraestructuras de investigación más amplias, incluyendo laboratorios automatizados, recursos computacionales distribuidos y bases de datos científicas globales. Esta integration podría facilitar la validación experimental automática de algoritmos descubiertos, cerrando el bucle entre descubrimiento computacional y verificación empírica. La perspectiva de sistemas que pueden no solo generar algoritmos sino también diseñar y ejecutar experimentos para validarlos representa la próxima frontera en automatización científica, prometiendo acelerar el ritmo del descubrimiento científico de maneras hasta ahora inimaginables.
Referencias
Liu, G., Zhu, Y., Chen, J., & Jiang, M. (2025). Scientific Algorithm Discovery by Augmenting AlphaEvolve with Deep Research. arXiv:2510.06056.
Novikov, A., V˜u, N., Eisenberger, M., Dupont, E., Huang, P. S., Wagner, A. Z., … & Balog, M. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131.
Romera-Paredes, B., Barekatain, M., Novikov, A., Balog, M., Kumar, M. P., Dupont, E., … & Fawzi, O. (2024). Mathematical discoveries from program search with large language models. Nature, 625(7995), 468-475.
Boiko, D. A., MacKnight, R., Kline, B., & Gomes, G. (2023). Autonomous chemical research with large language models. Nature, 624(7992), 570-578.
Chan, J. S., Chowdhury, N., Jaffe, O., Aung, J., Sherburn, D., Mays, E., … & Clune, J. (2024). MLE-bench: Evaluating machine learning agents on machine learning engineering. arXiv preprint arXiv:2410.07095.
Xu, R., & Peng, J. (2025). A comprehensive survey of deep research: Systems, methodologies, and applications. arXiv preprint arXiv:2506.12594.
Mouret, J. B., & Clune, J. (2015). Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909.
Tanese, R. (1989). Distributed genetic algorithms for function optimization. University of Michigan.

