
Durante años, el paradigma dominante en el campo de la inteligencia artificial ha sido uno de escalada sin precedentes. La creencia generalizada era que el poder computacional y la capacidad de razonamiento de una máquina estaban directamente correlacionados con su tamaño; cuanto más grande fuera el modelo, con más parámetros y más datos para entrenarlo, mejor sería su rendimiento.
Esta filosofía impulsó la creación de modelos de lenguaje masivos (LLMs) como GPT-4 o BERT, que requieren enormes cantidades de energía, agua y recursos minerales para su desarrollo y operación. Sin embargo, este enfoque a gran escala no solo presenta barreras económicas y de infraestructura, sino que también genera un impacto ambiental considerable. El entrenamiento de un solo modelo de última generación puede generar una huella de carbono equivalente a la de cinco coches durante toda su vida útil, y los centros de datos que lo alojan consumen entre el 1% y el 1.5% de la electricidad mundial.
Es en este contexto de convenciones desafiadas donde emerge una nueva corriente de investigación que pone en jaque la idea de que «más es mejor». Este movimiento se basa en la premisa de que la eficiencia algorítmica podría ser un factor más determinante para el progreso de la inteligencia artificial que la pura escala computacional. El paper Less is More: Recursive Reasoning with Tiny Networks es un ejemplo paradigmático de esta tendencia, presentando un modelo llamado Tiny Recursive Model (TRM) que redefinirá cómo medimos el éxito en el razonamiento artificial.
A diferencia de los gigantes computacionales que dominan las noticias, el TRM es, por definición, modesto. Con apenas siete millones de parámetros, es aproximadamente diez mil veces más pequeño que los LLMs de vanguardia como DeepSeek R1, Gemini 2.5 Pro u o3-mini. Su diseño minimalista, basado en una única red neuronal de solo dos capas, parece ir directamente en contra de las estrategias de modelado actuales.
El concepto de simplicidad en el diseño de IA no es nuevo, pero su aplicación exitosa en tareas complejas como el razonamiento abstracto y la resolución de problemas es revolucionaria. La simplicidad, en este contexto, se refiere a una arquitectura con menos componentes, menor número de parámetros y, en consecuencia, menores requisitos de hardware y energía. Este enfoque tiene profundas implicaciones. Por un lado, democratiza el acceso a tecnologías avanzadas, ya que los modelos pequeños pueden ejecutarse en dispositivos más comunes y con costos operativos significativamente más bajos. Por otro, aborda de frente la crisis de sostenibilidad que amenaza a la industria de la IA.
El Foro Mundial de la Inteligencia Artificial celebrado en París en 2025 subrayó la importancia de equilibrar rendimiento y sostenibilidad, destacando el desarrollo de modelos pequeños y eficientes como una vía crucial para mitigar el impacto ambiental. El propio TRM demuestra que la agudeza del pensamiento no depende de la masa, sino de la estructura. Al simplificar radicalmente su diseño, eliminando elementos como justificaciones biológicas o teoremas matemáticos complejos presentes en sus predecesores, el TRM logra priorizar la eficiencia y la generalización, demostrando que la elegancia y la precisión pueden triunfar sobre la complejidad inherente.
La paradoja fundamental que el TRM explora es que la simplicidad no implica una falta de capacidad, sino una optimización de la misma. Mientras que los grandes modelos aprenden patrones de un mar de datos masivos, el TRM utiliza su pequeña superficie de parámetros para aprender a pensar de una manera mucho más profunda y sistemática. En lugar de intentar memorizar soluciones, el TRM está diseñado para resolver problemas mediante un proceso iterativo de ensayo y error interno.
Esta diferencia conceptual es crucial: mientras que un LLM grande puede responder preguntas basándose en estadísticas de texto, el TRM está diseñado para resolver problemas mediante un proceso iterativo de ensayo y error interno. Esta capacidad de reflexionar y mejorar su propia respuesta internamente es lo que le permite superar a sus contrapartes mucho más grandes en pruebas de razonamiento que exigen flexibilidad y comprensión, más allá de la simple recuperación de información.
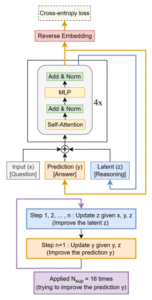
Este sistema funciona como un estudiante resolviendo un problema: empieza con la pregunta, escribe una primera respuesta tentativa y tiene en mente el razonamiento que usó. En lugar de conformarse, inicia un ciclo de autocorrección que repite hasta 16 veces para mejorar su trabajo. En cada ciclo, primero se detiene solo a pensar, revisando su lógica interna para encontrar una mejor manera de abordar el problema sin cambiar aún la respuesta en el papel. Una vez que ha refinado su pensamiento, usa esa nueva y mejorada lógica para corregir y escribir una respuesta actualizada. Al repetir este proceso de «pensar y luego corregir» una y otra vez, su respuesta se vuelve progresivamente más precisa. De esta forma, aunque la red neuronal es pequeña, su poder radica en usarla repetidamente para autocorregirse, logrando resultados excelentes de manera muy eficiente.
El motor del pensamiento: Cómo el razonamiento recursivo impulsa al TRM
El núcleo del éxito del Tiny Recursive Model (TRM) no reside en su tamaño, sino en la sofisticada mecánica que opera dentro de él. La innovación central del modelo es su capacidad para realizar un tipo de razonamiento conocido como recursivo. Para entender esta técnica, es útil recurrir a un paralelismo familiar: la programación recursiva. En informática, la recursividad es un método en el que una función se llama a sí misma para resolver un problema más grande, dividiéndolo en instancias más pequeñas del mismo problema.
Un ejemplo clásico es el cálculo del factorial de un número, donde n! = n × (n-1)!, y la función se llama a sí misma con un valor decreciente hasta alcanzar un caso base, como 1! = 1. De manera similar, el TRM no trata de resolver un rompecabezas de ajedrez o un acertijo lógico de una sola vez. En cambio, aplica un ciclo iterativo donde mejora repetidamente su suposición inicial, refinando su comprensión con cada vuelta.
Este proceso de mejora iterativa es el corazón del motor de pensamiento del TRM. Cuando se le presenta un problema, como un tablero de Sudoku extremadamente difícil, el modelo no busca la solución perfecta inmediatamente. En cambio, inicia un ciclo que puede repetirse hasta 16 veces. En cada iteración, el TRM realiza dos acciones fundamentales. Primero, actualiza un estado latente, representado por la variable z. Este estado z funciona como un «cuaderno de notas» o un «borrador mental» interno, donde el modelo anota sus observaciones, hipótesis y correcciones.
Dada la pregunta original x, su respuesta actual y y el estado latente anterior z, la red neuronal calcula un nuevo z que encapsula un razonamiento más profundo y una detección de errores potenciales. En segundo lugar, el modelo utiliza esta nueva información latente para refinar y mejorar su respuesta final y. Este ciclo de razonamiento continuo le permite al TRM detectar inconsistencias en sus primeras conclusiones, retroceder y probar caminos alternativos, simulando un proceso de deliberación humana.
Esta mecánica es comparable a un ingeniero que diseña una estructura: primero hace un boceto, luego lo analiza, encuentra una falla, vuelve a dibujar y refina el diseño hasta que cumple con todos los criterios de seguridad. El TRM automatiza este proceso de ingeniería mental. Se ha demostrado que esta capacidad de auto-corrección es particularmente efectiva en tareas de razonamiento espacial y lógico.
Por ejemplo, en el benchmark Maze-Hard, que consiste en laberintos complejos, el TRM logró una precisión del 85.3%, superando consistentemente a su predecesor HRM, que usaba una arquitectura más compleja. De manera similar, en el benchmark de sudoku, el TRM entrenado con solo 1.000 ejemplos pudo resolver con éxito 423.000 puzzles de prueba diferentes, alcanzando una precisión del 87.4%. Este espectacular rendimiento demuestra una capacidad de generalización extraordinaria: el modelo no ha memorizado las soluciones, sino que ha aprendido el principio del razonamiento lógico necesario para resolver cualquier rompecabezas de ese tipo.
Además de la recursividad básica, el equipo detrás del TRM implementó varias mejoras clave para garantizar la estabilidad y la eficacia del proceso iterativo. Una de ellas fue el uso de una Media Móvil Exponencial (EMA), una técnica que suaviza las actualizaciones del estado latente z para evitar oscilaciones bruscas y mantener una trayectoria de mejora coherente. Otra mejora importante fue el diseño de la arquitectura.
El TRM utiliza redes multicapa percepitron (MLP), que son más adecuadas para contextos de secuencia corta como el Sudoku, en contraste con los mecanismos de atención que dominan los LLMs y que son más útiles para textos largos. Esta adaptación de la arquitectura al tipo de tarea específica resultó en un aumento de rendimiento significativo, pasando del 74.7% al 87.4% en Sudoku-Extreme. Estas decisiones de diseño muestran un enfoque meticuloso, donde cada componente se ajusta para maximizar la eficiencia y la profundidad del razonamiento en lugar de depender de la simple fuerza bruta de un modelo más grande.
El triunfo de la arquitectura sobre la fuerza bruta: rendimiento y benchmarking
El verdadero testimonio del genio detrás del Tiny Recursive Model (TRM) se revela en su impresionante rendimiento en una serie de benchmarks de razonamiento. Estos resultados no solo demuestran que el modelo pequeño puede competir con los gigantes, sino que en muchas áreas los supera de manera contundente, utilizando recursos computacionales insignificantes en comparación.
El benchmark ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) es un conjunto de pruebas diseñado para evaluar la capacidad de un sistema para resolver problemas nuevos y desconocidos, juzgando así su inteligencia general artificial. En este desafío, el TRM alcanzó una precisión del 45% en ARC-AGI-1 y del 8% en ARC-AGI-2, superando consistentemente a modelos de lenguaje masivos como Deepseek R1, o3-mini y Gemini 2.5 Pro, a pesar de tener menos del 0.01% de los parámetros de estos últimos. Esto es una declaración contundente: la capacidad de generalización no proviene de la cantidad de datos procesados, sino de la calidad del proceso de razonamiento aplicado.
Las comparaciones cuantitativas subrayan aún más la ventaja del TRM. En lugar de una mera afirmación, los datos proporcionados en las fuentes ofrecen una visión clara de la disparidad en el tamaño y el rendimiento.
| Modelo | Parámetros | Precisión en Sudoku-Extreme | Precisión en Maze-Hard | Precisión en ARC-AGI-1 |
|---|---|---|---|---|
| Tiny Recursive Model (TRM) | 7 millones | 87.4% | 85.3% | 44.6% |
| Hierarchical Reasoning Model (HRM) | 27 millones | 55.0% | 74.5% | 40.3% |
| Modelos Grandes (ej. Deepseek R1, o3-mini, Gemini 2.5 Pro) | > 70.000 millones (estimado) | Inferior | Inferior | Superior |
Como se puede observar en la tabla, el TRM, con una cuarta parte de los parámetros del modelo HRM (su predecesor directo), muestra un rendimiento superior en todas las métricas clave. Esto confirma que la simplificación de su arquitectura, eliminando redundancias y enfocándose en la mejora iterativa, es una estrategia mucho más eficaz.
La capacidad del TRM para alcanzar casi un 88% de precisión en Sudoku-Extreme, un problema que requiere una lógica deductiva rigurosa, es particularmente notable. Ha demostrado una capacidad de generalización asombrosa, aprendiendo a resolver miles de veces más rompecabezas de los que se le enseñaron, lo que indica que ha capturado el «cómo» de la resolución de sudokus, no solo el «qué».
El éxito del TRM se debe a una combinación de arquitectura inteligente y un proceso de entrenamiento bien definido. Sus experimentos se llevaron a cabo en GPUs de alto rendimiento como H-100 y L40S, con tiempos de entrenamiento que podían llegar a tres días. Sin embargo, el costo computacional total es minúsculo si se compara con el entrenamiento de un Llama 3 405B, que puede requerir meses de tiempo de GPU y millones de dólares. Este análisis revela una verdad fundamental: la inversión en hardware de última generación no es necesariamente el camino más rápido hacia la inteligencia artificial superior.
En cambio, una inversión en investigación algorítmica, en encontrar nuevas formas de estructurar el conocimiento y el razonamiento, puede producir retornos mucho más altos con una fracción de los recursos. El TRM es una prueba viviente de que, en el futuro de la IA, la arquitectura inteligente podría ser tan importante, o incluso más, que la escala de los datos y el hardware.
Del laboratorio a la realidad: Implicaciones tecnológicas y de eficiencia
El impacto del Tiny Recursive Model (TRM) trasciende el ámbito académico y las competiciones de benchmarks, abriendo un panorama lleno de posibilidades tecnológicas y prácticas. Su mayor implicación reside en la promesa de una inteligencia artificial más accesible, eficiente y distribuida. La característica más tangible del TRM es su reducido tamaño: con solo siete millones de parámetros, su huella computacional es insignificante en comparación con los miles de millones que conforman un LLM moderno. Esta eficiencia tiene consecuencias directas y transformadoras.
Primero, permite que los modelos como el TRM se ejecuten en hardware mucho más económico y en dispositivos de bajo consumo, como smartphones, wearables o incluso microcontroladores. Esto representa una evolución fundamental desde los modelos de IA centralizados que dependen de vastos centros de datos hasta un paradigma de «edge computing», donde la inteligencia reside cerca de los datos, permitiendo respuestas instantáneas, privacidad mejorada y funcionamiento incluso sin conexión a internet.
Desde una perspectiva tecnológica, el enfoque del TRM sugiere una posible integración híbrida en futuras arquitecturas de IA. Si bien un LLM grande puede ser excelente para tareas de comprensión de lenguaje natural o generación de texto, podría ser ineficiente o inepto para resolver un problema lógico complejo. Aquí es donde entra el TRM. Podría concebirse como un módulo especializado de razonamiento, una «calculadora de lógica» que un sistema más grande podría invocar cuando sea necesario para tomar decisiones críticas.
Por ejemplo, un asistente virtual podría usar un LLM para interpretar una consulta compleja («Organiza mis reuniones de la semana que viene considerando mis horarios y preferencias») y luego pasar esa tarea bien definida a un módulo como el TRM para calcular la solución óptima de programación. Este enfoque modular maximiza la fortaleza de cada tipo de modelo: la comprensión semántica del LLM y la capacidad de razonamiento deductivo del TRM.
Otra implicación clave es la optimización de algoritmos. El éxito del TRM demuestra que la eficiencia algorítmica puede superar la escala computacional. Esto incentiva a la comunidad de investigación a invertir más recursos en desarrollar nuevos métodos y técnicas que mejoren la forma en que los modelos aprenden y razonan, en lugar de simplemente aumentar el tamaño de los datos o de los modelos. Este cambio de paradigma podría conducir a una nueva generación de algoritmos que sean inherentemente más eficientes.
La tecnología TinyML, que ya permite ejecutar modelos de aprendizaje automático en microchips de bajo consumo, es un claro precursor de este futuro. El TRM, con su arquitectura ligera y su capacidad de generalización, es un ejemplo robusto de cómo podría funcionar un sistema de IA en este ecosistema.
Sin embargo, el alcance del TRM no es ilimitado. Es importante reconocer que, debido a su naturaleza especializada, el modelo no sería adecuado por sí solo para tareas de propósito general o que dependen de un vasto conocimiento factual, como la mayoría de las funciones de los LLMs.
Su fortaleza radica en el razonamiento estructurado y sistemático, no en la memoria de datos. Por lo tanto, el futuro más probable no es el de un duelo entre modelos grandes y pequeños, sino una coexistencia estratégica. Las organizaciones podrían utilizar una combinación de LLMs para la interacción y la comprensión, y modelos como el TRM para la toma de decisiones, la planificación y la resolución de problemas específicos. Esta división del trabajo podría resultar en sistemas de IA más robustos, rápidos y, crucialmente, más eficientes en términos de recursos.
El costo oculto de la Inteligencia: Sostenibilidad Ambiental y la Huella Digital
El avance vertiginoso de la inteligencia artificial, especialmente impulsado por los grandes modelos de lenguaje, ha traído consigo un costo ambiental oculto pero creciente. La industria de la IA consume una cantidad masiva de recursos, cuyo impacto ecológico es comparable al de otras industrias de alta tecnología. Los centros de datos que alojan estos modelos son responsables de un consumo energético exorbitante; se estima que podrían representar casi el 35% del uso nacional de energía de Irlanda para 2026. Los servidores dedicados a la IA pueden consumir entre 30 y 100 kW por rack, una cifra que supera con creces los 7 kW de los servidores tradicionales.
Este consumo energético se ve agravado por la necesidad de sistemas de refrigeración intensivos, que pueden representar hasta el 40% del consumo total de energía de un centro de datos. Además del consumo de electricidad, la fabricación de la infraestructura de hardware, como las tarjetas gráficas (GPUs) y unidades de procesamiento de tensor (TPUs) que son indispensables para el entrenamiento de los modelos, requiere la extracción de minerales críticos como cobalto y litio. Esta actividad minera insostenible causa deforestación, contaminación del agua y alteración de ecosistemas delicados en regiones como el Congo y América Latina.
El papel del TRM en este panorama es doble. Por un lado, su existencia es un eco de la creciente conciencia sobre estos problemas. El propio paper menciona la relevancia del tema, aunque de forma general, y la investigación detrás del modelo se produce en un contexto donde la sostenibilidad es una prioridad. El Foro Mundial de la Inteligencia Artificial en París 2025 destacó explícitamente el desarrollo de modelos pequeños y eficientes como una estrategia clave para mitigar el impacto ambiental.
El código abierto del TRM, disponible en GitHub bajo una licencia MIT, simboliza un movimiento hacia una investigación más transparente y colaborativa, donde compartir soluciones eficientes puede beneficiar a toda la comunidad y acelerar el desarrollo de una IA más sostenible.
Por otro lado, el TRM ofrece una solución práctica y tangible a algunos de estos desafíos. Al requerir una fracción de los recursos computacionales de un LLM, el TRM reduce directamente la huella de carbono asociada a su entrenamiento y operación. Un modelo más pequeño necesita menos energía para entrenarse y para inferir respuestas, lo que se traduce en emisiones de CO₂ significativamente menores.
Según algunas estimaciones, entrenar un modelo grande como GPT-4 puede emitir tanto CO₂ como cinco coches durante toda su vida útil, una cifra que el TRM, por su tamaño, minimiza drásticamente. Además, la eficiencia del TRM se extiende a otros recursos. Menos hardware significa una menor demanda de materias primas críticas para su fabricación y una menor generación de desechos electrónicos peligrosos al final de su ciclo de vida. El PNUMA, el Programa de las Naciones Unidas para el Medio Ambiente, ha publicado recomendaciones urgentes que incluyen exigir transparencia a las empresas de IA sobre sus huellas de carbono y agua, y promover activamente la eficiencia algorítmica, justo donde el TRM excela.
En conclusión, el TRM no es solo un avance técnico, sino también un catalizador cultural en la búsqueda de una IA más responsable. Su filosofía de «menos es más» se alinea con las iniciativas globales para crear una plataforma de cooperación global para una IA sostenible. Al demostrar que se puede lograr un alto rendimiento en tareas complejas con una fracción de los recursos, el TRM inspira a la industria a reconsiderar su dependencia de la escala. El futuro de la IA podría estar definido no solo por su inteligencia, sino también por su eficiencia.
El desarrollo de algoritmos más inteligentes y eficientes, como el TRM, junto con el compromiso de las grandes corporaciones con el uso de energías renovables y la implementación de tecnologías de refrigeración más limpias, como los sistemas de enfriamiento por líquido (DLC) que reducen el consumo de agua, es fundamental para asegurar que la revolución digital sea también una revolución verde.
Un Nuevo Paradigma para la Inteligencia Artificial
En resumen, el Tiny Recursive Model (TRM) representa mucho más que un avance puntual en el rendimiento de un benchmark específico. Es un faro que ilumina un nuevo horizonte en la inteligencia artificial, desafiando las convenciones arraigadas de la industria y abriendo la puerta a un paradigma más sostenible, eficiente y potencialmente más inteligente. Su contribución principal es la demostración empírica de que la complejidad y el tamaño no son sinónimos de capacidad de razonamiento.
Al simplificar radicalmente su arquitectura a una red neuronal de solo dos capas con siete millones de parámetros, el TRM ha logrado superar a modelos de vanguardia, muchos de ellos mil veces más grandes, en tareas que exigen una profunda comprensión lógica y espacial. Este éxito ataca el dogma de que la escala es el único camino hacia la inteligencia artificial general, sugiriendo que la calidad del algoritmo y la eficiencia del proceso de pensamiento son factores igualmente, si no más, importantes.
El legado del TRM reside en tres pilares fundamentales. El primero es el de la eficiencia algorítmica. El modelo demuestra que invertir en la creación de arquitecturas inteligentes que pueden aprender a razonar de manera sistemática y autocrítica es una estrategia más rentable a largo plazo que simplemente comprar más hardware y datos. Esta lección es crucial para guiar la investigación futura y evitar el camino de la «escalada ciega», que no solo es económicamente insostenible, sino que también agrava el impacto ambiental de la IA. El segundo pilar es la democratización de la inteligencia artificial. Al proponer un modelo que puede funcionar en hardware de bajo consumo, el TRM abre la puerta a una distribución mucho más amplia de la tecnología de IA. Esto podría reducir la brecha digital, permitir la innovación en mercados emergentes y llevar capacidades de cómputo avanzadas a lugares donde los costos de los centros de datos son prohibitivos.
Finalmente, el tercer pilar es la perspectiva ética y sostenible. El TRM surge en un momento en que la sociedad y la comunidad científica están cada vez más preocupadas por el coste real de la inteligencia artificial. Su existencia es una respuesta pragmática a estas preocupaciones. Ofrece una hoja de ruta viable para una IA que no solo sea más poderosa, sino también más amigable con el planeta. Al requerir una fracción de los recursos energéticos y mineros de los modelos grandes, el TRM es un ejemplo tangible de cómo la innovación puede ir de la mano de la responsabilidad. Este enfoque se alinea con los objetivos globales de desarrollo sostenible y marca una tendencia hacia un futuro donde los algoritmos no solo se evalúen por su rendimiento, sino también por su huella ecológica.
Para concluir, el Tiny Recursive Model es un hito que marca un punto de inflexión. No anuncia el fin de los grandes modelos, que seguirán siendo valiosos para ciertas tareas, pero sí señala el inicio de una era de eclectismo en el diseño de IA.
El futuro más probable será un ecosistema diverso donde modelos grandes y pequeños coexistan, cada uno desempeñando su rol optimizado. Los grandes modelos continuarán actuando como enciclopedias y oráculos semánticos, mientras que los modelos pequeños y especializados como el TRM se convertirán en los expertos de razonamiento, los planificadores y los ingenieros lógicos del mundo digital. El TRM nos enseña que la verdadera grandeza en la inteligencia artificial no reside en la masa, sino en la mente.
Referencias
Brock, A., Donahue, J., and Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
Chollet, F. On the measure of intelligence. arXiv preprint arXiv:1911.01547, 2019.
Chollet, F., Knoop, M., Kamradt, G., Landers, B., and Pinkard, H. Arc-agi-2: A new challenge for frontier ai reasoning systems. arXiv preprint arXiv:2505.11831, 2025.
Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022.
Geng, Z. and Kolter, J. Z. Torchdeq: A library for deep equilibrium models. arXiv preprint arXiv:2310.18605, 2023.
Hendrycks, D. and Gimpel, K. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
Jolicoeur-Martineau, A.: Less is More: Recursive Reasoning with Tiny Networks. arXiv preprint arXiv:2510.04871, 2025.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
Lehnert, L., Sukhbaatar, S., Su, D., Zheng, Q., Mcvay, P., Rabbat, M., and Tian, Y. Beyond a*: Better planning with transformers via search dynamics bootstrapping. arXiv preprint arXiv:2402.14083, 2024.
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
Moskvichev, A., Odouard, V. V., and Mitchell, M. The conceptarc benchmark: Evaluating understanding and generalization in the arc domain. arXiv preprint arXiv:2305.07141, 2023.
Park, K. Can convolutional neural networks crack sudoku puzzles? 2018.
Prieto, L., Barsbey, M., Mediano, P. A., and Birdal, T. Grokking at the edge of numerical stability. arXiv preprint arXiv:2501.04697, 2025.
Shazeer, N. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020.
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024.
Wang, G., Li, J., Sun, Y., Chen, X., Liu, C., Wu, Y., Lu, M., Song, S., and Yadkori, Y. A. Hierarchical reasoning model. arXiv preprint arXiv:2506.21734, 2025.

