
Estamos presenciando una olimpiada intelectual a escala global. Los atletas, sin embargo, no son humanos de carne y hueso, sino vastas mentes digitales forjadas en silicio y alimentadas por la totalidad del conocimiento humano digitalizado. En estadios virtuales repartidos por todo el mundo, desde los laboratorios de Silicon Valley hasta los centros de investigación en Pekín y Hangzhou, estos titanes de la inteligencia artificial (IA) compiten día y noche en una carrera sin precedentes.
Se enfrentan a desafíos que abarcan desde resolver problemas matemáticos de nivel competitivo hasta reparar errores en complejos programas informáticos y comprender los matices del razonamiento ético. Esta contienda silenciosa pero vertiginosa está definiendo el futuro de la tecnología y, quizás, de la propia humanidad. Estamos construyendo entidades con una capacidad cognitiva nunca antes vista, pero nuestras herramientas para medir su «inteligencia» son un campo de batalla en sí mismas, en constante evolución y desafío.
Para navegar este nuevo y fascinante territorio, es fundamental comprender a los competidores, las reglas del juego y, sobre todo, la naturaleza de las pruebas que deben superar. El campo de juego es el dominio de los Modelos Lingüísticos Grandes, o LLM por sus siglas en inglés. Imaginemos un programa informático cuyo único objetivo es predecir la siguiente palabra en una frase.
Ahora, escalemos esa idea a una dimensión planetaria. Un LLM es un tipo de inteligencia artificial que ha sido entrenada con cantidades monumentales de datos, que incluyen textos, libros, artículos y código de programación, a menudo abarcando una porción significativa de todo internet. A través de este proceso de aprendizaje masivo, no solo aprende gramática y vocabulario, sino que también asimila patrones, contextos, estilos de razonamiento e incluso sesgos latentes en la información que consume.
El código genético de estas mentes digitales se basa en una innovación fundamental: la arquitectura Transformer. Desarrollada por investigadores de Google en 2017, esta estructura de red neuronal revolucionó el campo al permitir que los modelos procesaran secuencias enteras de texto de una sola vez, en lugar de hacerlo palabra por palabra.
Su mecanismo clave, conocido como «atención», permite al modelo sopesar la importancia de diferentes palabras en el texto de entrada para comprender el contexto, sin importar cuán distantes estén unas de otras. Esta capacidad para captar relaciones a larga distancia es lo que confiere a los LLM modernos su asombrosa coherencia y profundidad de comprensión.
Si la arquitectura Transformer es el ADN, los «parámetros» son las neuronas y sinapsis que componen el cerebro del modelo. Estos son los resortes internos, las variables que el modelo ajusta durante su entrenamiento para optimizar su capacidad de predicción. Un modelo simple puede tener unos pocos miles de parámetros, pero los gigantes que compiten hoy en día cuentan con cientos de miles de millones, e incluso billones, de estas «perillas» ajustables.
Un mayor número de parámetros generalmente permite una comprensión más matizada y compleja de los datos, pero también exige una cantidad descomunal de recursos computacionales para su entrenamiento y aumenta el riesgo de un fenómeno llamado «sobreajuste», donde el modelo memoriza sus datos de entrenamiento tan bien que pierde la capacidad de generalizar a información nueva que no ha visto antes.

Para medir y comparar a estos titanes, la comunidad científica ha desarrollado una serie de «benchmarks». Estos son marcos de evaluación estandarizados, esencialmente exámenes rigurosos diseñados para poner a prueba habilidades específicas. Funcionan como un decatlón olímpico: en lugar de una única prueba de fuerza, hay múltiples eventos que evalúan la velocidad, la agilidad, la resistencia y la precisión.
Estos benchmarks son cruciales para seguir el progreso del campo, orientar la investigación hacia áreas de mejora y ofrecer una base objetiva para comparar las capacidades de diferentes modelos. Las evaluaciones a menudo se realizan mediante métodos como el «zero-shot», donde el modelo debe responder sin haber visto ningún ejemplo previo, o el «few-shot», donde se le proporcionan unos pocos ejemplos para medir su capacidad de aprendizaje a partir de un contexto mínimo.
En este estadio global compiten laboratorios de renombre. OpenAI, el pionero que popularizó esta tecnología; Google DeepMind, un gigante de la investigación con recursos casi ilimitados; Anthropic, un contendiente centrado en la seguridad que ha sorprendido al mundo con sus capacidades; Meta AI, el campeón del código abierto que ha democratizado el acceso a modelos potentes; y una nueva ola de estrellas emergentes como xAI, Alibaba y DeepSeek, que demuestran que la vanguardia de la IA ya no pertenece a una sola nación o empresa.
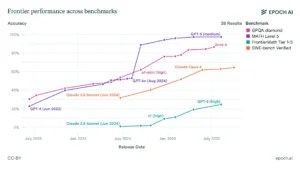
El ecosistema de la inteligencia artificial funciona como un bucle de retroalimentación perpetuo entre la capacidad de los modelos y la complejidad de su evaluación. La mera existencia de un conjunto tan vasto y en constante evolución de benchmarks demuestra que, a medida que los modelos se vuelven más inteligentes, las pruebas deben volverse exponencialmente más difíciles. No se trata de una medición estática, sino de una coevolución dinámica. Los primeros benchmarks, como GLUE, se vieron rápidamente «saturados» a medida que los modelos superaban el rendimiento humano.
Esta saturación fue el catalizador directo para la creación de pruebas mucho más exigentes como MMLU. Ahora, incluso este exigente examen muestra signos de ser conquistado por los modelos de frontera, lo que ha impulsado el desarrollo de la siguiente generación de desafíos, como MMLU-Pro, FrontierMath y GPQA Diamond. Por lo tanto, el acto mismo de medir el rendimiento de la IA impulsa la siguiente ola de desarrollo para superar la nueva prueba, y la siguiente ola de investigación en evaluación para crear una prueba aún más ardua. Este ciclo crea una dinámica de «carrera armamentista» cognitiva que define el ritmo vertiginoso de este campo.

Las pruebas de aptitud: ¿Qué se le pregunta a una IA?
Para comprender la verdadera naturaleza de esta competición, debemos adentrarnos en los diferentes eventos que componen esta olimpiada digital. Cada benchmark está meticulosamente diseñado para sondear una faceta distinta de la inteligencia, desde el conocimiento enciclopédico hasta la creatividad abstracta. No se trata solo de obtener una puntuación, sino de entender qué habilidades cognitivas se están poniendo a prueba y por qué son importantes.
El decatlón del conocimiento general: MMLU y MMLU-Pro
El MMLU (Massive Multitask Language Understanding) es el equivalente a un examen de acceso a la universidad de élite, pero para las IA. Se trata de una prueba exhaustiva que abarca 57 materias, desde humanidades y ciencias sociales hasta campos STEM (ciencia, tecnología, ingeniería y matemáticas) y derecho. Su propósito fundamental es evaluar la capacidad de un modelo para generalizar su conocimiento a través de dominios dispares, una habilidad crucial para una inteligencia verdaderamente versátil.
Su historia de origen es reveladora: fue creado en 2020 precisamente porque los modelos de la época, como GPT-3, comenzaban a superar con creces los benchmarks existentes. Cuando MMLU fue presentado, la mayoría de los modelos obtenían una puntuación cercana al azar (un 25% de aciertos en preguntas de cuatro opciones), mientras que el mejor, GPT-3, apenas alcanzaba un 43.9%. Esto estableció un nuevo y elevado listón.
Sin embargo, el progreso ha sido tan rápido que incluso MMLU está empezando a ser conquistado por los modelos más avanzados. Esto ha llevado a la creación de MMLU-Pro, una versión de «posgrado» del examen. Esta nueva iteración eleva drásticamente la dificultad mediante dos innovaciones clave: las preguntas son más complejas y requieren un razonamiento más profundo, y el número de opciones de respuesta se ha incrementado de cuatro a diez. Este último cambio reduce drásticamente la probabilidad de acertar por casualidad y exige una comprensión mucho más precisa por parte del modelo.
La olimpiada de lógica y matemáticas: GSM8K y MATH
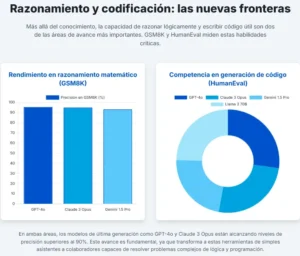
Si MMLU evalúa la amplitud del conocimiento, otros benchmarks se centran en la profundidad del razonamiento. El GSM8K (Grade School Math 8K) es una prueba engañosamente simple pero increíblemente reveladora. Consiste en 8,500 problemas de matemáticas de nivel de escuela primaria, formulados como problemas de palabras.
Aunque las operaciones aritméticas requeridas son básicas (suma, resta, multiplicación, división), la diversidad lingüística de los enunciados y la necesidad de seguir una secuencia lógica de varios pasos para llegar a la solución lo convierten en una excelente herramienta de diagnóstico para la capacidad de razonamiento secuencial de un modelo.
El siguiente escalón en esta disciplina es el benchmark MATH. Este conjunto de problemas se extrae de competiciones de matemáticas de secundaria de alto nivel, como el American Mathematics Competitions (AMC) y el American Invitational Mathematics Examination (AIME). Resolver estos problemas no solo requiere conocimiento matemático avanzado, sino también estrategias creativas de resolución de problemas y una capacidad de abstracción significativamente mayor que la necesaria para GSM8K.
El desafío del mundo real: HumanEval y SWE-Bench para la programación
Una de las aplicaciones más transformadoras de los LLM es la generación de código. Para medir esta habilidad, se crearon benchmarks que van más allá de la simple corrección sintáctica. HumanEval fue pionero en este ámbito. Consiste en 164 problemas de programación en Python, donde el modelo debe generar una función funcional a partir de una descripción en lenguaje natural (conocida como «docstring»).
Su gran innovación fue evaluar la «corrección funcional»: el código generado no solo debe parecer correcto, sino que debe ejecutarse y pasar una serie de pruebas unitarias. Para medir el éxito, se introdujo la métrica pass@k, que calcula la probabilidad de que al menos una de las k soluciones generadas por el modelo sea correcta, imitando cómo un desarrollador humano podría probar varias sugerencias de una IA.
Si HumanEval es como un examen de programación en un entorno controlado, SWE-Bench (Software Engineering Benchmark) es como poner a la IA a trabajar en un proyecto de software real, caótico y complejo. En esta prueba, los modelos se enfrentan a problemas y errores reales (issues) extraídos de repositorios populares en GitHub. La tarea consiste en generar un parche de código que resuelva el problema dentro de una base de código existente y compleja. Es una prueba mucho más práctica y desafiante, que evalúa no solo la capacidad de codificar, sino también de comprender un contexto de software amplio y depurar problemas del mundo real.
El desafío del razonamiento abstracto: ARC
Quizás la prueba más fascinante y la que más se acerca a medir una forma de inteligencia «humana» es el ARC (Abstraction and Reasoning Corpus). Creado por el investigador de Google François Chollet, ARC se compone de una serie de rompecabezas visuales. Cada tarea presenta un puñado de ejemplos de una transformación en una cuadrícula de colores, y el modelo debe inferir la regla abstracta subyacente y aplicarla a una nueva cuadrícula de entrada. Lo que hace a ARC tan especial es que fue diseñado explícitamente para ser inmune a la memorización y a los atajos estadísticos.
No se puede resolver buscando patrones en internet; requiere una genuina capacidad de generalización y descubrimiento de reglas a partir de muy pocos datos. A día de hoy, incluso los LLM más potentes obtienen resultados muy pobres en ARC en comparación con los humanos, lo que indica que este tipo de razonamiento abstracto sigue siendo una de las fronteras más difíciles para la IA.
La prueba de inteligencia social: HellaSwag y WinoGrande
La inteligencia no es solo lógica y conocimiento; también es sentido común. HellaSwag es un benchmark diseñado para medir precisamente esto. Presenta un escenario cotidiano y pide al modelo que elija la continuación más plausible entre cuatro opciones. La clave es que las tres opciones incorrectas son generadas «adversarialmente», lo que significa que están diseñadas para ser muy atractivas y semánticamente similares a la respuesta correcta, engañando a los modelos que se basan en asociaciones de palabras superficiales en lugar de una comprensión genuina del mundo.
De forma similar, WinoGrande se centra en la resolución de pronombres en frases cuidadosamente construidas para ser ambiguas sin una capa de sentido común. Por ejemplo, en la frase «El trofeo no cabía en la maleta porque era demasiado grande», ¿a qué se refiere «grande»? ¿Al trofeo o a la maleta? Un humano lo sabe por su conocimiento del mundo, y WinoGrande pone a prueba si una IA también puede hacerlo.
El examen de doctorado: GPQA Diamond
En el extremo más alto del espectro de conocimiento se encuentra GPQA (Graduate-Level Google-Proof Q&A). Se trata de un conjunto de preguntas de opción múltiple de nivel de posgrado en biología, física y química. La joya de la corona es el subconjunto «Diamond», que contiene 198 preguntas que los expertos con doctorado en el campo pueden responder correctamente, pero que los no expertos altamente cualificados fallan sistemáticamente, incluso con acceso ilimitado a buscadores web. Esto lo convierte en una prueba formidable contra la simple recuperación de información, exigiendo un conocimiento profundo y especializado que no puede ser fácilmente «buscado en Google».
Cuadro 1. Benchmarks utilizados: qué miden y por qué importan
| Benchmark | Mide | Ejemplo de tarea |
| MMLU / MMLU-Pro | Conocimiento general y razonamiento multitarea | Responder una pregunta de opción múltiple de física a nivel universitario. |
| GSM8K | Razonamiento matemático en varios pasos | Resolver un problema de palabras sobre manzanas y naranjas que requiere 3 pasos. |
| HumanEval | Generación de código funcional | Escribir una función en Python para comprobar si una cadena es un palíndromo. |
| SWE-Bench | Ingeniería de software en el mundo real | Corregir un error específico reportado como un «issue» en un repositorio público de GitHub. |
| ARC | Razonamiento abstracto y generalización | Dados 3 ejemplos de transformaciones de cuadrículas, aplicar la regla oculta a una nueva cuadrícula. |
| GPQA Diamond | Conocimiento científico a nivel de experto | Responder una pregunta de biología a nivel de doctorado que los no expertos fallan incluso con acceso a la web. |
Aquí se aclara el alcance de cada prueba y se muestra una tarea típica para aterrizar su significado. MMLU/MMLU-Pro evalúa conocimiento general y razonamiento multitarea; GSM8K verifica aritmética en varios pasos; HumanEval comprueba si el código generado pasa tests unitarios; SWE-Bench mide ingeniería de software en condiciones reales con issues y pruebas del proyecto; ARC observa razonamiento abstracto y generalización; GPQA Diamond estresa conocimiento científico de nivel experto. La idea no es sumar puntos, sino entender qué habilidad ilumina cada banco y cómo ese dato se traduce en valor: amplitud temática, encadenamiento lógico, código funcional, entrega en repositorios reales, generalización de patrones o dominio experto.
Los titanes de la IA bajo el microscopio: Un retrato de familia
Una vez delineado el campo de batalla y las pruebas a superar, es hora de analizar a los competidores. Cada laboratorio de IA tiene su propia filosofía, su propia historia y sus propias fortalezas y debilidades. El análisis de su rendimiento a través de los diversos benchmarks pinta un retrato fascinante de un panorama competitivo en constante cambio.
Cuadro 2. Benchmarks representativos y su vínculo con los modelos
| Familia de modelo | Programación aplicada (repos reales y verificación) | Matemáticas exigentes (razonamiento y prueba) | Biología computacional (estructura, candidatos, protocolos) | Predicción y multimodal (meteorol., tablas, figuras) |
|---|---|---|---|---|
| GPT (última gen.) | Estable con agentes; buen balance diagnóstico+edición; baja regresión con tests estrictos | Preciso en respuesta entera; mejora con trazas; competitivo en formalización | Integrador generalista: lectura de papers, resúmenes, planificación segura | Fusión de fuentes y calibración probabilística confiables |
| Claude (Sonnet/Opus) | Muy fuerte en issues verificados; estilo conservador que reduce roturas | Cadenas claras; explicaciones limpias; buen encaje con asistentes de prueba | Instrucciones nítidas y control de riesgos en protocolos | Parejo en híbridos físico-datos; comunicación clara |
| Grok (últ. gen.) | Velocidad y rutas largas; picos altos en análisis de error; requiere barandas | Creativo en combinatoria; sensible a dominio; exigir verificación | Explora espacios de candidatos con rapidez | Integra señales heterogéneas con agilidad |
| Qwen (cerr./abierto) | Competitivo con tooling fino; atractivo por control de stack y privacidad | Sube con verificadores simbólicos; estable en lotes rotativos | Ventaja en entornos on-prem y personalización | Avances con datos locales y pipelines abiertos |
| Gemini (Ultra/Flash) | Firme con documentación extensa y contexto largo | Correcto; crece con trazas estructuradas | Muy bueno en figuras, tablas y extracción | Sólido en multimodal satélite-sensor y tablas |
Este cuadro define, para cada benchmark, qué habilidad evalúa y un ejemplo de tarea, y sirve como “leyenda” para leer el otro cuadro de modelos. En la práctica, MMLU/MMLU-Pro es la base para juzgar amplitud de conocimiento y razonamiento multitarea que luego vemos reflejado en modelos como GPT-5, Claude u otros; GSM8K comprueba aritmética paso a paso y anticipa qué tan estables serán en problemas numéricos; HumanEval valida si el modelo genera funciones que pasan tests unitarios, lo que no equivale a editar proyectos reales y por eso no es comparable con SWE-Bench, que sí mide ingeniería de software en repositorios con issues y pruebas del proyecto y explica por qué, por ejemplo, Claude Sonnet 4.5 sobresale en “Verified”; ARC capta razonamiento abstracto y transferencia de reglas, útil para inferir generalización fuera de temarios; GPQA Diamond estresa conocimiento científico experto y ayuda a entender por qué Grok 4 puede liderar en preguntas de posgrado. Usá esta tabla como mapa: cada fila es un termómetro distinto que justifica las diferencias de rendimiento entre modelos en tu cuadro comparativo; no se promedian entre sí porque miden competencias diferentes.
OpenAI: La dinastía GPT y la búsqueda de la inteligencia general
OpenAI es, para muchos, el nombre sinónimo de la revolución de la IA generativa. Su trayectoria es una historia de escalada exponencial. El viaje comenzó en 2018 con GPT-1, un modelo con 117 millones de parámetros que sirvió como prueba de concepto. Le siguió GPT-2 en 2019, con 1.5 mil millones de parámetros, un modelo tan potente para su época que su lanzamiento completo se retrasó por temor a un uso malicioso.
El verdadero punto de inflexión llegó en 2020 con GPT-3 y sus 175 mil millones de parámetros, que introdujo al mundo la asombrosa capacidad de aprendizaje «few-shot», donde el modelo podía realizar tareas para las que no había sido entrenado explícitamente con solo unos pocos ejemplos. La versión refinada, GPT-3.5, se convirtió en el motor del fenómeno global que fue ChatGPT a finales de 2022.
La siguiente generación, GPT-4, lanzada en 2023, introdujo capacidades multimodales (procesando texto e imágenes) y un razonamiento notablemente mejorado. Más recientemente, OpenAI ha diversificado su enfoque, lanzando modelos de «pesos abiertos» como gpt-oss y una nueva familia de modelos centrados en el razonamiento, como o1, o3 y la serie GPT-5, que continúan empujando los límites del rendimiento.
El análisis de su rendimiento confirma su estatus como el estándar de la industria. Los modelos de OpenAI, especialmente la familia GPT-5 y la serie ‘o’, aparecen sistemáticamente en la cima o muy cerca de ella en casi todas las tablas de clasificación importantes. En benchmarks de razonamiento general como LiveBench, sus modelos ocupan varias de las primeras posiciones. En pruebas de matemáticas avanzadas como MATH-500 y AIME, sus modelos logran puntuaciones casi perfectas, a menudo liderando la clasificación.
En el exigente examen de conocimiento experto GPQA Diamond, GPT-5 se sitúa en el segundo puesto, demostrando una base de conocimiento profunda y robusta. En el ámbito de la programación, sus modelos como O1 Preview y GPT-4o alcanzan puntuaciones superiores al 85% e incluso al 90% en las rigurosas pruebas de HumanEval, consolidando su reputación como excelentes generadores de código. Esta consistencia en la excelencia a través de una amplia gama de dominios cognitivos pinta un cuadro claro: los modelos de OpenAI son los competidores a batir, los campeones polivalentes que definen el estado del arte.
Google DeepMind: Gemini y la promesa de la multimodalidad nativa
La respuesta de Google a la explosión de ChatGPT fue Gemini, un modelo que representa la culminación de años de investigación pionera en IA, partiendo de sus predecesores LaMDA y PaLM. La filosofía de diseño de Gemini es fundamentalmente diferente: fue concebido desde el principio para ser «multimodal de forma nativa».
Esto significa que no fue entrenado solo con texto, sino con una mezcla integrada de texto, imágenes, audio y vídeo, con el objetivo de crear una IA que comprenda el mundo de una manera más holística y similar a la humana. La familia Gemini ha evolucionado a través de varias generaciones (1.0, 1.5 y la más reciente 2.5) y se ofrece en diferentes variantes para equilibrar rendimiento y coste: Pro como el modelo estándar de alta capacidad, Flash como una versión más rápida y económica, y Ultra como el modelo de máxima potencia.
En términos de rendimiento, Gemini 2.5 Pro se ha consolidado como un competidor de primer nivel, situándose de forma consistente en el escalón más alto de las clasificaciones, a menudo intercambiando posiciones con los últimos modelos de OpenAI y Anthropic. Su fortaleza es particularmente evidente en benchmarks que requieren una amplia base de conocimiento. En GPQA Diamond, Gemini 2.5 Pro logra una impresionante puntuación del 80.3%, empatando con algunos de los mejores modelos de OpenAI y demostrando su dominio del conocimiento experto.
De manera similar, en la prueba MMLU-Pro, alcanza un notable 86.7%, confirmando su capacidad para el razonamiento multitarea a través de docenas de disciplinas. Aunque su rendimiento en programación y matemáticas es muy sólido, generalmente se encuentra un pequeño paso por detrás de los líderes especializados en esas áreas. El perfil que emerge de los datos es el de un modelo extraordinariamente versátil y conocedor, un contendiente formidable en todas las categorías.
Anthropic: Claude y la apuesta por una IA constitucional
Anthropic representa una de las narrativas más convincentes en el panorama de la IA. Fundada en 2021 por antiguos investigadores de alto nivel de OpenAI, la compañía nació con un enfoque primordial en la seguridad y la ética de la IA. Su innovación principal es un enfoque de entrenamiento llamado «IA Constitucional». En lugar de depender exclusivamente de humanos para etiquetar respuestas como seguras o dañinas, Anthropic entrena a sus modelos para que se autoevalúen y se corrijan basándose en un conjunto de principios o «constitución» (inspirada en fuentes como la Declaración Universal de los Derechos Humanos).
El objetivo era crear una IA que fuera inherentemente «servicial, honesta e inofensiva». La evolución de sus modelos, desde el Claude 1 inicial hasta la sofisticada familia Claude 3 (con sus variantes Haiku para la velocidad, Sonnet para el equilibrio y Opus para la máxima potencia) y el reciente Claude Sonnet 4.5, ha seguido esta filosofía.
Lo que hace que la historia de Anthropic sea tan notable es que su enfoque en la seguridad no ha ido en detrimento de la capacidad, sino todo lo contrario. En los últimos meses, sus modelos no solo han alcanzado a la competencia, sino que la han superado en algunos de los benchmarks más difíciles y relevantes para el mundo real. El logro más destacado es el de Claude Sonnet 4.5, que ha establecido un nuevo estado del arte en SWE-Bench Verified, la prueba de resolución de problemas de software del mundo real, con una puntuación del 77.2%.
Este es un salto monumental que posiciona a Anthropic como el líder indiscutible en la capacidad de programación práctica. Además, sus modelos de gama alta, como Claude Opus 4.1, lideran la clasificación en el exigente MMLU-Pro con un 87.9%, demostrando una superioridad en conocimiento general y razonamiento avanzado. Esta combinación de seguridad y rendimiento de vanguardia ha transformado a Anthropic de un interesante proyecto centrado en la ética a un líder de la industria que está redefiniendo lo que es posible.
Meta AI: Llama y la revolución de los pesos abiertos
Meta AI ha desempeñado un papel fundamental en la configuración del ecosistema actual de la IA a través de su serie de modelos Llama. Su estrategia ha sido catalizar la innovación mediante la publicación de modelos de «pesos abiertos» (a menudo denominados incorrectamente «código abierto»), permitiendo que investigadores, desarrolladores y empresas de todo el mundo accedan, modifiquen y construyan sobre una base tecnológica de vanguardia. La historia comenzó con Llama 1, cuyos pesos se filtraron a la comunidad en 2023, desatando una ola de experimentación sin precedentes. Meta abrazó esta dinámica con los lanzamientos oficiales y abiertos de Llama 2, Llama 3 y, más recientemente, la familia Llama 4, que incluye variantes de diferentes tamaños como Behemoth, Maverick y Scout.
En las tablas de clasificación, los modelos más grandes de Meta, como Llama 4 Behemoth, demuestran un rendimiento muy competitivo, aunque generalmente se sitúan un escalón por debajo de los mejores modelos propietarios de OpenAI, Google y Anthropic en los benchmarks más desafiantes. Sin embargo, su verdadero valor no reside en ocupar el primer puesto absoluto, sino en ofrecer el mejor rendimiento en relación con su accesibilidad.
Son, de manera consistente, los modelos de pesos abiertos más potentes disponibles, democratizando el acceso a la IA de frontera. Además, destacan en áreas de aplicación práctica. Por ejemplo, en el benchmark BFCL, que mide la capacidad de un modelo para utilizar herramientas externas (una habilidad clave para agentes de IA), Llama 3.1 405b ostenta el liderazgo, lo que subraya el enfoque de Meta en la usabilidad del mundo real.
Los nuevos contendientes: Grok, Qwen y DeepSeek en el escenario mundial
El dominio de los gigantes tecnológicos de EE. UU. está siendo desafiado por una nueva ola de competidores formidables. xAI, la empresa de Elon Musk, ha irrumpido en escena con Grok, un modelo diseñado con un toque de «rebeldía» y la ventaja única de tener acceso en tiempo real a la vasta red de información de X (anteriormente Twitter). El lanzamiento de Grok 4 ha sido un acontecimiento sísmico en el mundo de los benchmarks. De forma sorprendente, se ha catapultado a la cima de algunas de las pruebas de razonamiento más respetadas, logrando el primer puesto en GPQA Diamond con un 88.1% y en MATH-500 con un 96.2%. Este rendimiento excepcional lo establece como un nuevo y poderoso actor, especialmente en las tareas que requieren un razonamiento lógico y matemático profundo.
Mientras tanto, el desarrollo de IA de vanguardia se ha convertido en un fenómeno global. Qwen, de Alibaba, se ha consolidado como uno de los principales modelos de China y un competidor de talla mundial. Su familia de modelos, incluyendo Qwen3 y el masivo Qwen3-Max con más de un billón de parámetros, demuestra capacidades impresionantes, especialmente en tareas multilingües y de programación. Modelos como Qwen2.5-Coder-32B alcanzan puntuaciones del 87.2% en HumanEval, situándose entre los mejores del mundo en generación de código.
Otro actor clave de China es DeepSeek, que ha ganado notoriedad por su enfoque en modelos de pesos abiertos de alto rendimiento y métodos de entrenamiento eficientes en costes. Sus modelos, como DeepSeek-R1 y DeepSeek V3, son extremadamente competitivos, a menudo superando a otros modelos abiertos y desafiando incluso a algunos sistemas propietarios en dominios como la programación y el razonamiento.
La narrativa inicial de una simple rivalidad entre OpenAI y Google ha quedado obsoleta. Los datos de los benchmarks pintan un cuadro mucho más complejo y dinámico: un mundo multipolar. Las tablas de clasificación muestran ahora una élite de modelos de OpenAI (GPT-5, o3), Anthropic (Claude 4.x) y Google (Gemini 2.5) que se disputan constantemente el primer puesto en diferentes disciplinas. A esta contienda se ha sumado de forma abrupta Grok 4 de xAI, que ha reclamado la corona en benchmarks de razonamiento clave. Al mismo tiempo, los modelos de Alibaba (Qwen) y DeepSeek están dominando las clasificaciones de modelos abiertos y superando a competidores propietarios en nichos específicos como la programación. La idea de un único «mejor» modelo es ahora un espejismo. El campo se caracteriza por múltiples centros de excelencia, cada uno con fortalezas, filosofías (abierto frente a cerrado, seguridad frente a capacidad) y orígenes geográficos distintos.
Cuando los exámenes mienten: Las grietas en el sistema de evaluación
Tras maravillarnos con las impresionantes puntuaciones y la feroz competencia, es imperativo adoptar una postura más crítica y escéptica. Como periodistas, nuestro deber es preguntar: ¿qué significan realmente estos números? ¿Son un reflejo fidedigno de una inteligencia emergente o una ilusión creada por un sistema de medición imperfecto? Al examinar más de cerca, encontramos grietas significativas en los cimientos de la evaluación de la IA.
El fantasma en la máquina: La contaminación de datos
El problema más insidioso que socava la validez de los benchmarks es la «contaminación de datos». Este fenómeno ocurre cuando los datos de la prueba, es decir, las preguntas y respuestas del examen, se filtran accidental o intencionadamente en los vastos conjuntos de datos utilizados para entrenar a los modelos. Dado que los LLM se entrenan con enormes porciones de internet, y muchos benchmarks son públicos y están alojados en línea, es casi inevitable que los modelos «vean» las preguntas del examen antes de la prueba. Cuando esto sucede, un modelo puede obtener una puntuación alta no porque haya razonado para encontrar la solución, sino porque ha memorizado la respuesta que vio durante su entrenamiento. Esto infla artificialmente las puntuaciones, invalida la evaluación de la capacidad de generalización del modelo y hace que las comparaciones entre sistemas entrenados con diferentes niveles de contaminación sean injustas.
La ley de Goodhart y el peligro del número único
El economista británico Charles Goodhart formuló una máxima que se ha vuelto dolorosamente relevante para la IA: «Cuando una medida se convierte en un objetivo, deja de ser una buena medida». La intensa carrera por encabezar las tablas de clasificación de los benchmarks ha convertido estas puntuaciones en el objetivo principal para muchos laboratorios de IA. Esta presión incentiva una forma de «enseñar para el examen» a gran escala.
En lugar de centrarse en el desarrollo de una inteligencia general y robusta, los esfuerzos pueden desviarse hacia la optimización de los modelos para que se desempeñen excepcionalmente bien en los formatos y tipos de preguntas específicos que aparecen en los benchmarks populares. Este fenómeno, conocido como «sobreajuste al benchmark» o «reward hacking», puede producir modelos que son genios en los exámenes estandarizados pero frágiles e ineficaces cuando se enfrentan a la complejidad y la variabilidad del mundo real.
La fragilidad de la medición: Errores en los benchmarks y sensibilidad a las instrucciones
Incluso si pudiéramos resolver la contaminación y la ley de Goodhart, nos enfrentaríamos a otro problema fundamental: los propios benchmarks no son perfectos. Un análisis manual y riguroso del benchmark MMLU, uno de los más respetados, arrojó un resultado asombroso: se encontraron errores significativos en las preguntas y respuestas. El caso más extremo fue el del subconjunto de Virología, donde se determinó que un increíble 57% de las preguntas eran defectuosas, ya sea por tener la respuesta correcta marcada como incorrecta o por ser ambiguas. Si la vara de medir está torcida, ¿cómo podemos confiar en las mediciones?
Además, los LLM han demostrado una alarmante «sensibilidad a las instrucciones» (prompt sensitivity). Cambios mínimos en la redacción de una pregunta, como alterar una palabra o reformular la estructura de la frase, pueden provocar cambios drásticos en el rendimiento de un modelo, haciendo que pase de una respuesta correcta a una incorrecta. Esta fragilidad sugiere que la comprensión del modelo puede ser superficial, basada en patrones superficiales en lugar de un entendimiento conceptual robusto. De forma similar, benchmarks como HumanEval, aunque pioneros, tienen limitaciones evidentes: solo evalúan código en Python, no tienen en cuenta la calidad, legibilidad o eficiencia del código, y no reflejan la complejidad de trabajar en grandes proyectos de software del mundo real.
Todo esto nos lleva a una conclusión ineludible. Las puntuaciones de los benchmarks no deben ser vistas como una verdad objetiva, sino como un indicador ruidoso, imperfecto y potencialmente manipulable de la capacidad de una IA. La combinación de la contaminación de datos, la presión por optimizar para la prueba y los errores inherentes a los propios exámenes significa que una clasificación en una tabla debe ser interpretada con un alto grado de escepticismo. Los números que vemos no son una medida directa de la «inteligencia».
Son, más bien, una medida del «rendimiento en una prueba específica, potencialmente defectuosa y posiblemente contaminada, bajo una intensa presión para optimizar para esa prueba concreta». Comprender esta distinción es fundamental para evaluar de forma crítica las afirmaciones sobre el progreso de la IA y para apreciar los profundos desafíos metodológicos que enfrenta el campo.

Más allá de las puntuaciones, el futuro de la inteligencia
Al hacer un balance de esta vertiginosa carrera, emerge un panorama complejo. Hemos sido testigos de una competencia feroz y multipolar que está impulsando un progreso rapidísimo, aunque desigual, a través de diversos dominios cognitivos. Los modelos de IA están alcanzando, y en algunos casos superando, el rendimiento humano en tareas específicas y bien definidas, como resolver problemas de competiciones matemáticas o aprobar exámenes estandarizados de nivel de posgrado. Sin embargo, su capacidad para el razonamiento general, la planificación a largo plazo, la comprensión del mundo físico y la fiabilidad en entornos no estructurados sigue siendo un área de intensa investigación y debate.
Existe una brecha cada vez más evidente entre el rendimiento en los benchmarks y la utilidad en el mundo real. Obtener una puntuación del 96% en un examen de matemáticas no convierte automáticamente a una IA en un matemático fiable, del mismo modo que lograr un 77% en SWE-Bench no la convierte en un ingeniero de software autónomo y de confianza. Los benchmarks actuales, a pesar de su creciente sofisticación, luchan por medir cualidades humanas cruciales como la creatividad genuina, el juicio contextual, la conciencia situacional y la capacidad de mantener un objetivo coherente durante largos períodos de tiempo.
Esta constatación está generando un consenso en la comunidad investigadora: es necesario mirar «más allá de los benchmarks» para obtener una imagen más fiel de las capacidades de la IA. Están surgiendo nuevos enfoques de evaluación que intentan superar las limitaciones de los exámenes estáticos. Entre ellos se encuentran los «benchmarks dinámicos», que se actualizan constantemente con nuevos datos para prevenir la contaminación y la memorización.
También ganan terreno las evaluaciones basadas en la preferencia humana, como las «arenas» de chatbots, donde los modelos compiten entre sí y son clasificados por evaluadores humanos, capturando mejor la calidad subjetiva de la interacción. Quizás el enfoque más prometedor sea la «evaluación agéntica», que pone a prueba la capacidad de un modelo para utilizar herramientas y completar tareas complejas de varios pasos en entornos simulados, midiendo la capacidad de acción en lugar del conocimiento pasivo.
Una métrica particularmente interesante que está ganando tracción es la medición del rendimiento en función de la «longitud de la tarea» que una IA puede completar de forma autónoma. Los estudios muestran que la duración de las tareas que los agentes de IA pueden resolver con fiabilidad ha estado aumentando exponencialmente, duplicándose aproximadamente cada siete meses. Este enfoque podría ser un indicador mucho más práctico de la utilidad real de un modelo que una puntuación porcentual en un examen de opción múltiple.
La carrera documentada en estas tablas de clasificación no es, en última instancia, solo una búsqueda de puntuaciones más altas. Es el esfuerzo colectivo de la humanidad por forjar un nuevo tipo de inteligencia. Las imperfecciones de nuestras varas de medir no disminuyen la magnitud de este logro; más bien, iluminan la sutileza y la complejidad del desafío que tenemos por delante. El verdadero objetivo no es solo construir una IA que sea poderosa, sino una que sea también robusta, fiable, comprensible y, en última instancia, alineada con los valores y el florecimiento de la humanidad. La próxima etapa de esta olimpiada no se ganará simplemente siendo más inteligente, sino siendo más sabio.
Referencias
Allen Institute for AI. (n.d.). WinoGrande: An Adversarial Winograd Schema Challenge at Scale. Retrieved from https://winogrande.allenai.org/
Anthropic. (2025, September 29). Claude Sonnet 4.5. Retrieved from https://www.anthropic.com/news/claude-sonnet-4-5
Apple Inc. (2024, May 12). GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. Retrieved from https://machinelearning.apple.com/research/gsm-symbolic
ARC Prize. (n.d.). Guide. Retrieved from https://arcprize.org/guide
Arduin. (n.d.). The benchmark problems reviving manual evaluation. Retrieved from https://arduin.io/blog/benchmark-problems/
Arize. (n.d.). 40 Large Language Model Benchmarks and The Future of Model. Retrieved from https://arize.com/blog/llm-benchmarks-mmlu-codexglue-gsm8k
Artificial Analysis. (n.d.). GPQA Diamond Benchmark Leaderboard. Retrieved from https://artificialanalysis.ai/evaluations/gpqa-diamond
Artificial Analysis. (n.d.). MATH-500 Benchmark Leaderboard. Retrieved from https://artificialanalysis.ai/evaluations/math-500
Artificial Analysis. (n.d.). MMLU-Pro Benchmark Leaderboard. Retrieved from https://artificialanalysis.ai/evaluations/mmlu-pro
Artificial Analysis. (n.d.). SWE-bench Benchmark. Retrieved from https://www.vals.ai/benchmarks/swebench
AWS. (n.d.). What is a Large Language Model?. Retrieved from https://aws.amazon.com/what-is/large-language-model/
Cloudflare. (n.d.). What is a large language model (LLM)?. Retrieved from https://www.cloudflare.com/learning/ai/what-is-large-language-model/
CNA. (2022, September). Goodhart’s Law. Retrieved from https://www.cna.org/analyses/2022/09/goodharts-law
Confident AI. (n.d.). Top LLM Benchmarks Explained: MMLU, HellaSwag, BBH. Retrieved from https://www.confident-ai.com/blog/llm-benchmarks-mmlu-hellaswag-and-beyond
DataCamp. (n.d.). What is MMLU. Retrieved from https://www.datacamp.com/blog/what-is-mmlu
Deepchecks. (n.d.). HumanEval. Retrieved from https://www.deepchecks.com/glossary/humaneval/
Deepgram. (n.d.). HellaSwag: Understanding the LLM Benchmark for Commonsense Reasoning. Retrieved from https://deepgram.com/learn/hellaswag-llm-benchmark-guide
Doctorow, C. (2025, August). Goodhart’s Law (of AI). Medium. Retrieved from https://doctorow.medium.com/https-pluralistic-net-2025-08-11-five-paragraph-essay-targets-r-us-f4fef48e28a0
Epoch AI. (n.d.). AI Benchmarks. Retrieved from https://epoch.ai/benchmarks
Epoch AI. (n.d.). AI Models. Retrieved from https://epoch.ai/data/ai-models
Epoch AI. (n.d.). Data Insights. Retrieved from https://epoch.ai/data-insights
Epoch AI. (n.d.). GPQA Diamond. Retrieved from https://epoch.ai/benchmarks/gpqa-diamond
Epoch AI. (n.d.). Search Benchmarks. Retrieved from https://epoch.ai/benchmarks/search
EvalPlus. (n.d.). EvalPlus Leaderboard. Retrieved from https://evalplus.github.io/leaderboard.html
Galileo. (n.d.). MMLU Benchmark. Retrieved from https://galileo.ai/blog/mmlu-benchmark
Google Developers. (n.d.). Intro to Large Language Models. Retrieved from https://developers.google.com/machine-learning/resources/intro-llms
Graphlogic. (n.d.). The ARC Benchmark: Evaluating LLMs’ Reasoning Abilities. Retrieved from https://graphlogic.ai/blog/utilities/the-arc-benchmark-evaluating-llms-reasoning-abilities/
Graphlogic. (n.d.). HellaSwag: Understanding the LLM Benchmark for Commonsense Reasoning. Retrieved from https://graphlogic.ai/blog/utilities/hellaswag-understanding-the-llm-benchmark-for-commonsense-reasoning/
HolisticAI. (n.d.). Overview of Data Contamination. Retrieved from https://www.holisticai.com/blog/overview-of-data-contamination
Hugging Face. (n.d.). Big Code Models Leaderboard. Retrieved from https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard
Hugging Face. (n.d.). Leaderboards and benchmarks. Retrieved from https://huggingface.co/collections/clefourrier/leaderboards-and-benchmarks-64f99d2e11e92ca5568a7cce
Hugging Face. (n.d.). MMLU-Pro. Retrieved from(https://huggingface.co/spaces/TIGER-Lab/MMLU-Pro)
Hugging Face. (n.d.). Multilingual MMLU Benchmark Leaderboard. Retrieved from(https://huggingface.co/spaces/StarscreamDeceptions/Multilingual-MMLU-Benchmark-Leaderboard)
Hugging Face. (n.d.). Open LLM Leaderboard Blog. Retrieved from https://huggingface.co/spaces/open-llm-leaderboard/blog
Hugging Face. (n.d.). openai/gsm8k. Retrieved from https://huggingface.co/datasets/openai/gsm8k
IBM. (n.d.). Model parameters. Retrieved from https://www.ibm.com/think/topics/model-parameters
IBM. (n.d.). What are LLM benchmarks?. Retrieved from https://www.ibm.com/think/topics/llm-benchmarks
Inspirisys. (n.d.). A Beginner’s Guide to Large Language Models. Retrieved from(https://www.inspirisys.com/blog-details/A-Beginners-Guide-to-Large-Language-Models/173)
Kaggle. (n.d.). Benchmarks. Retrieved from https://www.kaggle.com/benchmarks
Kaggle. (n.d.). Benchmarking Comprehension and Reasoning. Retrieved from https://www.kaggle.com/datasets/thedevastator/benchmarking-comprehension-and-reasoning
Kaggle. (n.d.). MATH-500. Retrieved from https://www.kaggle.com/benchmarks/open-benchmarks/math-500
Kaggle. (n.d.). MMLU-Pro. Retrieved from https://www.kaggle.com/benchmarks/open-benchmarks/mmlu-pro
Karthika, A. (2024, June 14). Paper Breakdown #1: MMLU — LLMs Have Exams Too! (A Post on Benchmarking). Medium. Retrieved from https://medium.com/@alakarthika01/paper-breakdown-1-mmlu-llms-have-exams-too-a-post-on-benchmarking-a66630dfd2a6
Klu. (n.d.). GPQA Eval. Retrieved from https://klu.ai/glossary/gpqa-eval
Klu. (n.d.). GSM8K Eval. Retrieved from(https://klu.ai/glossary/GSM8K-eval)
Klu. (n.d.). HumanEval Benchmark. Retrieved from https://klu.ai/glossary/humaneval-benchmark
LiveBench. (n.d.). Leaderboard. Retrieved from https://livebench.ai/
LiveCodeBench. (n.d.). LiveCodeBench Leaderboard. Retrieved from https://livecodebench.github.io/leaderboard.html
Maxim. (n.d.). LLM Data Quality. Retrieved from https://www.getmaxim.ai/blog/llm-data-quality/
MDPI. (2024). Beyond the Benchmark: A Customizable Platform for Real-Time, Preference-Driven LLM Evaluation. Retrieved from https://www.mdpi.com/2079-9292/14/13/2577
Metr. (2025, March 19). Measuring AI ability to complete long tasks. Retrieved from https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
Nan, N. (2024, February 14). The HellaSWAG benchmark is a dataset designed to evaluate advanced natural language understanding…. Medium. Retrieved from https://medium.com/@nikhilnan/the-hellaswag-benchmark-is-a-dataset-designed-to-evaluate-advanced-natural-language-understanding-a14f3d6fb462
Nightfall AI. (n.d.). Parameters and Tokens: The Essential Guide. Retrieved from https://www.nightfall.ai/ai-security-101/parameters-and-tokens
OpenCompass. (n.d.). MathBench. Retrieved from(https://open-compass.github.io/MathBench/)
OpenReview. (n.d.). MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. Retrieved from(https://openreview.net/forum?id=y10DM6R2r3)
OpenReview. (n.d.). A Meta-Reasoning-Based Paradigm for Evaluating and Enhancing the Cognitive Abilities of Large Language Models. Retrieved from https://openreview.net/forum?id=br4H61LOoI
Our World in Data. (n.d.). Artificial intelligence parameter count. Retrieved from https://ourworldindata.org/grapher/artificial-intelligence-parameter-count
Project Pro. (n.d.). MMLU Benchmark. Retrieved from https://www.projectpro.io/article/mmlu-benchmark/1162
R&D World. (2025, October 6). Claude Sonnet 4.5 pushes coding SOTA, but its physics intuition still lags. Retrieved from https://www.rdworldonline.com/claude-sonnet-4-5-pushes-coding-sota-but-its-physics-intuition-still-lags/
Reddit. (n.d.). LLM Leaderboards are Bullshit – Goodhart’s Law Strikes Again. Retrieved from https://www.reddit.com/r/LocalLLaMA/comments/1bjvjaf/llm_leaderboards_are_bullshit_goodharts_law/
Reddit. (n.d.). MMLU-Pro is a math benchmark. Retrieved from https://www.reddit.com/r/LocalLLaMA/comments/1du52gf/mmlupro_is_a_math_benchmark/
Reiter, E. (2024, March 12). Data Contamination Worries. Retrieved from https://ehudreiter.com/2024/03/12/data-contamination-worries/
Scale AI. (n.d.). Coding Leaderboard. Retrieved from https://scale.com/leaderboard/coding
Scale AI. (n.d.). MATH Leaderboard. Retrieved from https://scale.com/leaderboard/math
Shmul, C. (2024, July 1). HumanEval: The Most Inhuman Benchmark for LLM Code Generation. Medium. Retrieved from https://shmulc.medium.com/humaneval-the-most-inhuman-benchmark-for-llm-code-generation-0386826cd334
Smol Agents. (n.d.). Big Code Models Leaderboard. Retrieved from https://smolagents.org/big-code-models-leaderboard/
Stanford University. (n.d.). What are large language models (LLMs)?. Retrieved from https://uit.stanford.edu/service/techtraining/ai-demystified/llm
Statology. (n.d.). How to Interpret HumanEval: Can This AI Actually Code?. Retrieved from https://www.statology.org/how-to-interpret-humaneval-can-this-ai-actually-code/
Sun, Z., et al. (2024). [2405.04520] NaturalCodeBench: A Challenging Application-Driven Benchmark for Code Synthesis. arXiv. Retrieved from https://arxiv.org/html/2405.04520v1
SWE-bench. (n.d.). SWE-bench. Retrieved from(https://www.swebench.com/SWE-bench/)
SWE-bench. (n.d.). Viewer. Retrieved from https://www.swebench.com/viewer.html
SWE-bench-Live. (n.d.). About. Retrieved from https://swe-bench-live.github.io/
TED AI. (n.d.). Parameters. Retrieved from https://tedai-sanfrancisco.ted.com/glossary/parameters/
The Gregorian. (2024, May 22). When Benchmarks Lie: Why Contamination Breaks LLM Evaluation. Medium. Retrieved from https://thegrigorian.medium.com/when-benchmarks-lie-why-contamination-breaks-llm-evaluation-1fa335706f32
TIME. (n.d.). Definition of «Parameter». Retrieved from https://time.com/collections/the-ai-dictionary-from-allbusiness-com/7273979/definition-of-parameter/
UBIAI. (n.d.). Popular Benchmarks | LLM Guide. Retrieved from https://ubiai.gitbook.io/llm-guide/evaluation-of-fine-tuned-models/popular-benchmarks
Unite.AI. (n.d.). Beyond Benchmarks: Why AI Evaluation Needs a Reality Check. Retrieved from https://www.unite.ai/beyond-benchmarks-why-ai-evaluation-needs-a-reality-check/
Vals AI. (2025, August 26). MATH 500 Benchmark. Retrieved from https://www.vals.ai/benchmarks/math500-08-26-2025
Vals AI. (2025, September 8). GPQA Benchmark. Retrieved from https://www.vals.ai/benchmarks/gpqa-09-08-2025
Vals AI. (2025, April 15). MMLU Pro Benchmark. Retrieved from https://www.vals.ai/benchmarks/mmlu_pro-04-15-2025
Vendrow, J., Vendrow, E., Beery, S., & Madry, A. (2025). Do Large Language Model Benchmarks Test Reliability?. arXiv. Retrieved from https://arxiv.org/abs/2502.03461
Vendrow, J., et al. (2025). Platinum Benchmarks. GitHub. Retrieved from https://github.com/MadryLab/platinum-benchmarks
Verity. (n.d.). GSM8K & MATH: Benchmarking Mathematical Reasoning. Retrieved from https://verityai.co/blog/gsm8k-math-benchmarks-mathematical-reasoning
Vellum. (n.d.). LLM Leaderboard. Retrieved from https://www.vellum.ai/llm-leaderboard
Vellum. (n.d.). Open LLM Leaderboard. Retrieved from https://www.vellum.ai/open-llm-leaderboard
Wang, Y., et al. (2024). [2406.04127] MMLU-Redux: A Comprehensive Analysis and Rectification of the MMLU Benchmark. arXiv. Retrieved from https://arxiv.org/abs/2406.04127
Wang, Y., et al. (2025). [2505.17482] Knowledge Augmentation for Abstract Reasoning. arXiv. Retrieved from https://arxiv.org/abs/2505.17482
Wikipedia. (n.d.). Goodhart’s law. Retrieved from https://en.wikipedia.org/wiki/Goodhart%27s_law
Wikipedia. (n.d.). MMLU. Retrieved from https://en.wikipedia.org/wiki/MMLU
Yeledteva, Y. (2023, March 19). Beyond Artificiality: Redefining Intelligence in AI and Avoiding Goodhart’s Law. Medium. Retrieved from https://medium.com/@yoavyeledteva/beyond-artificiality-redefining-intelligence-in-ai-and-avoiding-goodharts-law-25b75c3c1101
Yu, L. (n.d.). Contamination_Detector. GitHub. Retrieved from(https://github.com/liyucheng09/Contamination_Detector)
Zhang, Y., et al. (2025). [2502.11393] HellaSwag-Pro: A Large-Scale Bilingual Benchmark for Evaluating the Robustness of LLMs in Commonsense Reasoning. arXiv. Retrieved from https://arxiv.org/abs/2502.11393
Zilliz. (n.d.). MMLU Benchmark: Evaluating Multitask AI Models. Retrieved from https://zilliz.com/glossary/mmlu-benchmark
(Para la creación de este informe se consultaron varios otros preprints y páginas web de arXiv).

