
Durante la última década, la ambición central de la inteligencia artificial ha sido acercar sus capacidades a algo que, sin abusar del término, podamos llamar pensamiento. No basta con que un modelo complete frases o recite datos. Para que resulte útil en problemas que exigen criterio, secuenciación y autocorrección, debe ser capaz de organizar pasos, evaluar posibilidades y sostener en la memoria de trabajo una serie de transformaciones internas coherentes. En otras palabras, debe aprender a razonar. De ese impulso nacieron dos familias de estrategias que hoy protagonizan un debate intenso: la cadena de pensamiento, que hace visible el razonamiento paso a paso, y los marcadores de pensamiento, que prometieron incorporarlo en silencio.
La cadena de pensamiento se consolidó como un recurso eficaz para forzar al modelo a “mostrar su trabajo”. En lugar de saltar directo a la respuesta, el sistema despliega una secuencia de pasos intermedios. El efecto, replicado una y otra vez, fue contundente en tareas de aritmética con varios movimientos, en lógica elemental, en problemas de texto con trampas semánticas e incluso en preguntas que requieren mezclar hechos con inferencias. El motivo es intuitivo: si la red neuronal produce, paso a paso, un esquema de resolución y lo mantiene consistente, es menos probable que se pierda en atajos estadísticos. La contracara es conocida. Para que funcione bien, suele requerir ejemplos supervisados, indicaciones explícitas y tolerar respuestas más extensas, lo que eleva costos y tiempos.
Los símbolos de pensamiento nacen de una intuición seductora y casi minimalista. ¿Y si pudiésemos regalarle a la red una pausa interna sin pedirle que nos explique nada? Bastaría insertar glifos especiales en la entrada que actúen como señales de “detente y procesa” para que el modelo, en su maquinaria latente, realice microcómputos adicionales antes de seguir. Sería un atajo elegante: menos ingeniería de instrucciones, menos dependencia de datos con soluciones intermedias y, en teoría, una vía más cercana a un razonamiento autónomo. La expectativa fue alta. Si los humanos nos tomamos unos segundos mentales para ordenar un cálculo, tal vez un modelo pueda beneficiarse de ciclos adicionales invisibles, sin necesidad de textualmente “pensar en voz alta”.
El estudio que motiva este análisis interroga esa promesa con lupa técnica y conclusión incómoda. La evidencia empírica indica que, en la práctica, los indicadores de pensamiento no rinden como se esperaba frente a la cadena de pensamiento. En muchos escenarios apenas superan al modelo sin ayudas y, en otros, ni siquiera logran eso. El desenlace no es un simple no funciona, sino un diagnóstico profundo. La investigación muestra la causa de fondo: un diseño que concentra toda la “pausa cognitiva” en un único marcador genérico termina provocando señales de aprendizaje ruidosas y contradictorias. El resultado es que el modelo no aprende a aprovechar ese señalizador silencioso de un modo estable y útil.
Este artículo, adaptado al tono editorial de Mundo IA, recorre con precisión periodística y claridad didáctica las preguntas centrales que plantea el trabajo. Qué prometían los símbolos de pensamiento, cómo se los puso a prueba, por qué fracasan cuando deberían ayudar y qué lecciones dejan para la agenda de investigación. La historia, lejos de clausurar el camino hacia una IA que razone con mayor autonomía, delimita con realismo qué requiere una pausa que valga la pena y qué tipo de estructura latente podría necesitar un sistema para pensar sin palabras.
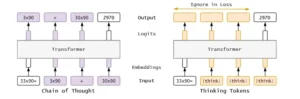
Cadena de pensamiento comparada con fichas pensantes. Estos enfoques muestran una sorprendente similitud a pesar de sus diferencias.
Panorama conceptual: hablar para pensar, pensar sin hablar
La diferencia entre cadena de pensamiento y marcadores de pensamiento es conceptual y práctica. La primera agrega estructura visible. El modelo genera un razonamiento intermedio y lo redacta. Esa verbalización le impone al sistema una ruta con hitos. Es como trazar una hoja de ruta y discutirla en voz alta. Los símbolos, en cambio, son silenciosos. Operan como etiquetas sin significado lingüístico. No dicen cómo razonar, no piden explicaciones, no crean un texto intermedio. Son señales de que el sistema tiene permiso para iterar internamente antes de decidir la siguiente palabra de salida.
La cadena de pensamiento, por su naturaleza explícita, trae consigo ventajas verificables. Si el modelo se equivoca, es posible leer dónde falló la cadena lógica. Si acierta, queda una pista de por qué. En entornos sensibles, esta trazabilidad es oro. Los marcadores de pensamiento, si funcionaran, resolverían otra tensión: harían más autónomo el proceso, ahorrarían datos con pasos intermedios y podrían, idealmente, reducir la verbosidad en despliegue. La pregunta que articula el estudio es directa: cuando medimos ambas aproximaciones con el mismo rigor, ¿qué ocurre?
El ensayo se apoya en una batería de pruebas que cubren dos clases de tareas. Por un lado, un banco de ejercicios aritméticos de varios dígitos, idóneos para evaluar secuenciación. Por otro, problemas de texto y preguntas de conocimiento que exigen inferencia, comprensión de contexto y cadenas lógicas cortas. El modelo se entrena y evalúa en cuatro variantes. Primera, la línea base que responde sin ayudas intermedias. Segunda, la cadena de pensamiento supervisada con ejemplos de resolución paso a paso. Tercera, los marcadores de pensamiento sin supervisión de pasos explícitos. Cuarta, una condición híbrida que combina señales silenciosas con cadena de pensamiento supervisada para testear si hay sinergia adicional.
La expectativa que alimentaba el enfoque de marcadores era razonable. Insertar un mismo símbolo en diferentes posiciones permitiría al modelo consumirlo como un tiempo muerto útil para recalcular. Si la red aprendiera a usarlo, su representación interna del marcador, su vector de embedding, tendría que evolucionar notoriamente a lo largo del entrenamiento. Es decir, ese punto en el espacio numérico que representa al glifo debería moverse hacia una configuración que codifique, aunque sea de forma implícita, una instrucción de iterar, refinar o sostener estado. Deberían verse gradientes con magnitud suficiente apuntando en direcciones estables. Eso no ocurrió.
El análisis microscópico de lo que pasa dentro del modelo muestra que el embedding del marcador de pensamiento casi no se desplaza desde su posición inicial. Los gradientes asociados al símbolo son pequeños e inconsistentes en comparación con los que reciben marcas con significado léxico. Traducido a lenguaje llano: el sistema no encuentra “por dónde agarrar” ese carácter especial para convertirlo en un hábito interno de razonamiento. La razón de fondo es estructural. Un único marcador pretende cumplir todos los roles posibles. En un contexto debería señalar “haz un cálculo aritmético sencillo”, en otro “divide el problema en subpasos”, en otro “trae un dato previo y combínalo con esta nueva pista”. Esa polifuncionalidad forzada introduce señales de entrenamiento que se contradicen entre sí. Las correcciones que empujan el embedding del glifo en una dirección en un lote de ejemplos son deshechas por correcciones opuestas en otro lote. La red nunca consolida un patrón.
En las tareas aritméticas con varios dígitos, la cadena de pensamiento muestra el comportamiento esperado. A medida que el entrenamiento progresa, la tasa de aciertos sube y la producción de errores por saltos apurados disminuye. Los marcadores de pensamiento, en cambio, apenas arrancan algunos puntos de mejora respecto de la línea base y, en ciertos regímenes de dificultad, no superan ni siquiera al modelo sin ayudas. En los problemas de texto que requieren mezclar comprensión y cálculo, la historia se repite. El razonamiento explícito mantiene su ventaja. La condición híbrida, que combina señales con cadena de pensamiento, no agrega beneficios. Cuando el modelo ya sabe desplegar una ruta comprensible de resolución, la presencia de marcadores silenciosos ni lo ayuda ni lo perjudica. Quedan invisibles.
En términos prácticos, el mensaje es transparente. Si el objetivo es hacer que un modelo mejore en tareas que exigen encadenar pasos, debemos darle estructura. Esa estructura puede venir como datos con pasos intermedios o como indicaciones de estilo, pero tiene que forzar a la red a sostener estados coherentes a lo largo de varias decisiones. La esperanza de sustituir esa estructura por un único carácter silencioso, abstracto y polivalente no se concretó. En la comparación directa, la estrategia que habla gana a la que calla.
Autopsia técnica de un fracaso instructivo
La exploración del espacio de embeddings no es un adorno académico. Permite rastrear por qué algo no aprende cuando debería. El hecho de que el marcador de pensamiento permanezca casi inmóvil señala que el modelo no lo “encuentra” como punto de apoyo para un hábito interno. La hipótesis que mejor explica este fenómeno es la de señales de entrenamiento con alta varianza y coherencia escasa. Si un mismo símbolo aparece en circunstancias heterogéneas y en cada una la corrección deseable es diferente, la suma de correcciones tendrá valor esperado cerca de cero. La red recibe muchos pequeños empujones en direcciones que, en promedio, se cancelan. No hay gradiente neto que consolide una pauta.
La investigación explora un paliativo interesante. Introducir más de un tipo de marcador de pensamiento y dejarlos evolucionar de modo independiente. En ese escenario, el análisis de gradientes y desplazamientos de embeddings sí muestra actividad apreciable. Con dos símbolos distintos, el sistema tiene la oportunidad de asignar roles diferenciados. No sabemos exactamente cuáles, porque la dinámica latente no es interpretable por sí misma, pero la señal es clara: dividir el trabajo entre más de un marcador reduce la colisión de correcciones. Sin embargo, esa mejoría microscópica no se traduce en un salto macroscópico de rendimiento comparable al de la cadena de pensamiento. El remedio parcial ordena el caos, pero no reemplaza la estructura explícita.
Cuándo la pausa sirve y cuándo no
Si lo que buscamos es evitar la verbosidad y los costos de las cadenas de pensamiento, la idea de una pausa silenciosa sigue siendo atractiva. Pero requiere una ingeniería más rica. Pausas que no sean meros marcadores idénticos, sino señales con identidad contextual. Pausas que puedan alinearse con tipos de tareas o con fases del razonamiento. Pausas que se combinen con mecanismos de memoria de trabajo más expresivos. Es razonable imaginar una familia de símbolos especializados que el modelo aprenda a invocar o interpretar según la naturaleza del paso por venir. También es razonable pensar en bucles internos con control explícito del número de iteraciones, en lugar de confiar todo a un carácter pasivo con un embedding estático.
La lección no es abandonar la exploración del razonamiento latente, sino aceptar que no basta con proclamar “ahora piensa” mediante un comodín. Hace falta una gramática interna de la pausa. Hace falta una taxonomía funcional. Y, sobre todo, hace falta un mecanismo de crédito de asignación que refuerce la utilidad de cada pausa específica en relación con el resultado final. Mientras esa arquitectura falte, la cadena visible seguirá ganando porque impone por fuera la disciplina que por dentro todavía no emerge.
Cuadro 1. Comparación explicativa visual: cadena de pensamiento vs marcadores de pensamiento
| Dimensión de análisis | Cadena de pensamiento | Marcadores de pensamiento |
|---|---|---|
| Naturaleza del proceso | Razonamiento explícito redactado paso a paso | Razonamiento implícito sin verbalización |
| Señal de entrenamiento | Fuerte, con ejemplos de pasos intermedios | Débil, etiqueta genérica sin guía específica |
| Trazabilidad | Alta, permite auditar la lógica | Baja, el proceso queda oculto |
| Escalabilidad de datos | Costosa, requiere ejemplos con cadena | Atractiva, prescinde de pasos supervisados |
| Costo de inferencia | Mayor, respuestas más largas | Potencialmente menor si funcionara bien |
| Rendimiento observado | Consistentemente superior | Marginal o nulo frente a la línea base |
| Riesgo principal | Verborrea y overfitting a plantillas | Gradientes ruidosos y no aprendizaje del marcador |
De la teoría a la práctica: ejemplos didácticos
Tomemos una multiplicación de tres dígitos por dos dígitos. Para un humano, el procedimiento estándar es descomponer, multiplicar por cada dígito del segundo número y sumar resultados parciales. La cadena de pensamiento reproduce esta receta y la hace textual. El modelo que la sigue genera piezas intermedias comprensibles, algo como multiplicar 314 por 27 como 314 por 20 más 314 por 7, acumular y sumar. En pruebas controladas, esa disciplina textual conduce a más aciertos.
El enfoque de marcadores supone que la red, al encontrar un señalizador silencioso, preferirá internamente reusar subcircuitos de cálculo que ya sabe componer, iterar una o dos rondas latentes, mantener consignas en su memoria y recién luego producir el siguiente símbolo de salida. La evidencia muestra que ese comportamiento no emerge de manera estable si todo descansa en un único carácter polivalente. No hay premio diferenciado que indique cuándo conviene gastar ese “tiempo de pensar” en una subtarea concreta. Sin una semántica funcional asociada a cada pausa, el sistema no internaliza un hábito.
Algo similar ocurre con problemas en lenguaje natural que exigen, por ejemplo, identificar datos relevantes, descartar distractores, transformar unidades y combinar pistas. La cadena obliga al modelo a marcar las etapas. Los símbolos piden que el modelo las elabore por dentro. Cuando se comparan los resultados, el método visible obtiene mejores tasas de exactitud y menos respuestas que se quedan a mitad de camino. La explicación no es mágica. La verbalización impone una alineación fuerte entre la representación interna y la producción externa. Los marcadores, en cambio, no arrastran a la red hacia ninguna trayectoria consistente a menos que se diseñen con mayor especificidad.
Los argumentos a favor de los símbolos no eran caprichosos. En despliegues masivos, cada carácter adicional cuesta. Si se necesita pedir cadenas largas para asegurar precisión, las cuentas crecen. Además, hay situaciones en las que no hace falta que el sistema nos explique su proceso si el resultado es correcto y verificable. La pregunta legítima es si podemos entrenar modelos para que razonen mejor sin obligarlos siempre a narrar. Lo que este trabajo demuestra es que, con el diseño actual, esa economía no se logra. Es preferible gastar marcadores de salida en pasos visibles que desperdiciar etiquetas especiales que el modelo no aprende a aprovechar.
La economía de cómputo también sugiere otra lectura. Aun cuando la cadena encarece la inferencia, alinear el modelo con pasos intermedios reduce la probabilidad de exploraciones erráticas. En dominios con alto costo del error, ese gasto deliberado es una inversión. Los símbolos de pensamiento prometían combinar lo mejor de ambos mundos. La práctica los desmiente. No por mala intención ni por falta de creatividad, sino por un diagnóstico de aprendizaje profundo: un único vector no puede representar todas las funciones de la pausa cognitiva.
Hacia una gramática de pausas útiles
Si la pausa silenciosa va a sobrevivir, necesita ganar semántica. No hace falta que cada marcador sea una palabra humana. Basta con que el sistema aprenda que hay familias de pausas con cometidos diferentes. Un símbolo que activa una rutina de conteo. Otro que prioriza traer memoria relevante. Otro que ancla la atención en dependencias a largo plazo. Otro que congela el contexto para evaluar la consistencia de una hipótesis. Esa diversificación, acompañada por un currículo de entrenamiento que refuerce la utilidad de cada pausa en problemas donde esa función aporta, puede generar gradientes estables y embeddings que sí se muevan hacia configuraciones funcionales.
Además, es plausible que la pausa silenciosa sea más efectiva si se combina con mecanismos de control del número de iteraciones internas. Por ejemplo, un cabezal que evalúe la utilidad marginal de dar otra vuelta interna antes de producir salida. Sin ese control, el marcador es un simple recordatorio. Con control, puede ser el gatillo de un pequeño lazo de deliberación cuyo costo se gestione dinámicamente. Esto no es una receta terminada, sino un programa de investigación que reconoce la señal clínica de este estudio: el símbolo genérico no basta.
Cuadro 2. Esquema visual del problema de aprendizaje del marcador y una alternativa
| Elemento | Situación con un único marcador genérico | Variante con múltiples símbolos especializados |
|---|---|---|
| Embedding del marcador | Casi inmóvil, sin consolidar función | Se desplaza de forma apreciable por asignación de roles |
| Gradientes | Pequeños y ruidosos, señales contradictorias | Mayores y más coherentes por reducción de colisiones |
| Función implícita | Polivalencia confusa, sin semántica clara | Taxonomía latente de pausas con utilidad diferenciada |
| Efecto sobre rendimiento | Mejora marginal o nula | Potencial de mejora, aún por debajo de CoT |
| Interpretabilidad | Nula, proceso opaco | Nula en sí misma, pero con perfiles de uso distinguibles |
Implicancias sociales y tecnológicas
No toda discusión técnica queda puertas adentro de los laboratorios. La promesa de una pausa silenciosa entusiasmaba por sus consecuencias prácticas. Sistemas que resuelvan consultas complejas con menos palabras intermedias, sin necesitar grandes volúmenes de datos con cadenas etiquetadas, y que aprendan a autoorganizar su propio trabajo interno serían un avance en costo, privacidad y rapidez. La comunidad esperaba que los símbolos de pensamiento abrieran ese camino. La evidencia sugiere lo contrario. En este punto de la evolución de los modelos, si se busca razonamiento confiable, sigue siendo aconsejable estructurar la tarea con pasos visibles o, al menos, inducir un estilo de respuesta que fuerce al modelo a recorrer una ruta.
Desde la perspectiva de gobernanza y auditoría, el veredicto refuerza una preferencia por lo transparente. Que un modelo escriba sus pasos intermedios no solo mejora la exactitud, también habilita revisión y control. Cuando la decisión afecta a una persona, a una operación financiera, a un diagnóstico o a una política pública, la posibilidad de leer cómo se llegó a una conclusión es tan importante como la conclusión misma. Los marcadores de pensamiento, incluso si funcionaran mejor, no resolverían ese desafío, porque por diseño esconden el proceso. El estudio, al mostrar que además no mejoran el resultado, deja poco incentivo para su adopción en dominios críticos.
Vale aclarar que el fracaso relativo de los símbolos de pensamiento no clausura toda exploración de razonamiento latente. Señala un límite y sugiiere condiciones para superarlo. Es posible que, con arquitecturas diferentes, con memorias externas especializadas, con módulos de verificación internos o con pausas dotadas de semántica funcional, el razonamiento silencioso gane terreno. También es verosímil que su lugar natural sea complementario al razonamiento explícito. Pausas internas para preparar un bloque y cadena de pensamiento para exponerlo. La investigación, de hecho, muestra que cuando hay cadena de pensamiento, agregar marcadores no empeora. Simplemente no suma. Ese dato permite pensar en diseños híbridos donde la pausa interna sirva como regulador antes de escribir los pasos visibles, no como sustituto.
Otra oportunidad está en el entrenamiento por currículo. No basta con tirar símbolos en datos difíciles y esperar que la red adivine qué hacer. Un plan que asigne tareas a cada familia de pausa, que refuerce explícitamente su utilidad cuando se usa en el momento correcto y la castigue cuando se invoca en falso, podría crear gradientes robustos. La metáfora es escolar. Si queremos que un estudiante aprenda a usar la hoja borrador, hay que enseñarle cuándo conviene y cómo convertir esas notas en resultados. Dejar un solo papelito genérico en el banco no educa a nadie.
Síntesis operativa y hoja de ruta
El atractivo de los símbolos de pensamiento residía en su sobriedad. Un detalle mínimo que, si funcionaba, abría una puerta amplia. La realidad experimental los pone en su lugar. Con el diseño actual, no son un sustituto de la cadena de pensamiento. El diagnóstico interno que aporta el estudio es valioso porque no se limita a reportar un margen de error. Explica el mecanismo de la falla. Un único marcador genérico acumula correcciones incompatibles. Las señales se anulan. El embedding no aprende una función estable. El resultado es que la red, en la práctica, ignora la consigna de pausar y seguir.
Lo que debe quedar para el lector no especializado es la moraleja operativa. Cuando buscamos que un modelo de lenguaje razone con fiabilidad, lo más efectivo continúa siendo exigirle estructura visible. La explicación paso a paso no es un capricho ni una excusa didáctica. Es un instrumento que alinea el proceso interno con una ruta externa y obliga al sistema a transitarla sin saltos. Hasta que los diseñadores no definan una gramática de pausas con funciones distinguibles y mecanismos de refuerzo acordes, la pausa silenciosa será un gesto vacío.
Al mismo tiempo, la pregunta que motorizó la idea es legítima y conserva su valor: cómo hacer más autónomos y económicos los procesos de razonamiento. La respuesta no es negar el problema, sino complejizar la solución. La pausa útil no es una sola, es una familia. La pausa no se aprende por osmosis, se enseña con currículo y señal. La pausa no basta por sí misma, necesita un controlador de atención y memoria que la conecte con el contexto adecuado. Diseñar esa ecología de pausas será una de las tareas estimulantes en la frontera entre aprendizaje profundo e inspiración cognitiva.
Una conclusión, pero no del sueño
La ciencia avanza tanto cuando confirma intuiciones como cuando las desarma. En este caso, la verificación fue negativa, y eso la vuelve especialmente instructiva. El sueño de una IA que piensa sin hablar no muere con un estudio, pero aprende una lección concreta. La etiqueta genérica no enseña a pensar. La cadena visible, con todos sus costos, sigue siendo el camino más confiable para forzar coherencia y precisión. La agenda que se abre a partir de aquí es doble. Por un lado, utilizar con prudencia y criterio la cadena de pensamiento donde su trazabilidad y su ganancia de exactitud importen de verdad. Por otro, investigar sin romanticismo cómo dotar a las pausas internas de funciones reconocibles, de semántica útil y de mecanismos de aprendizaje que conviertan esa latencia en resultados.
Para quienes trabajamos en divulgación tecnológica y seguimos de cerca el pulso de la investigación, el aporte es claro. La madurez de un campo se mide por su capacidad de revisar críticamente sus propias promesas. Los marcadores de pensamiento fueron una promesa hermosa por su simplicidad. Hoy sabemos que, tal como están, esa hermosura no se traduce en eficacia. Aceptarlo no es resignación. Es un modo de limpiar el terreno para la próxima generación de ideas, más exigentes en su definición, más ricas en su diseño y más honestas con las restricciones reales de los modelos actuales. Pensar sin palabras quizá sea posible, pero demanda una gramática de silencios que todavía estamos aprendiendo a escribir.
Referencias
Vennam, S., Valente, D., Herel, D., y Kumaraguru, P. (2024). Rethinking Thinking Tokens: Understanding Why They Underperform in Practice. arXiv 2411.11371v1.
Herel, D., y Mikolov, T. (2023). Thinking Tokens for Language Modeling. AITP.
Wei, J., Wang, X., Schuurmans, D., Le, Q., Chi, E., Zhou, D., y colegas. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS.
Goyal, S., Wallace, E., Tunstall, L., y colegas. (2024). Think Before You Speak: Training Language Models with Pause Tokens. ICLR.
Malach, E., Barak, B., Geva, M., y colegas. (2023). Auto-regressive Models as Virtue Machines: from Training to Inference for Algorithmic Reasoning. arXiv.

