
En un mundo donde la inteligencia artificial promete revolucionar todos los ámbitos de la vida, desde la economía hasta la cultura, su aplicación en el campo más preciso y exigente de la medicina (la radiología) se ha convertido en un campo de batalla para determinar los límites de la tecnología y el valor inestimable del conocimiento humano. La radiología no es simplemente una disciplina; es una ciencia visual compleja que exige años de formación para interpretar con precisión las sutiles pistas ocultas en imágenes médicas como tomografías computarizadas, resonancias magnéticas e incluso radiografías. Es aquí, en este terreno de alta especialización, que se libra una contienda fundamental: ¿puede una máquina, por muy sofisticada que sea, equipararse o incluso superar al experto humano? Un estudio reciente, titulado «Radiology’s Last Exam« (RadLE), ofrece una respuesta contundente y desafiante a esta pregunta, revelando un panorama mucho más matizado que el optimismo tecnológico a menudo sugiere.
El benchmark RadLE representa uno de los primeros intentos serios y exhaustivos de comparar directamente el rendimiento de los modelos de inteligencia artificial más avanzados del mercado con el de sus equivalentes humanos en condiciones clínicas realistas. El objetivo era claro: evaluar si la vanguardia de la inteligencia artificial multimodal (capaz de procesar y correlacionar información textual, numérica y visual) podía rivalizar con el juicio clínico adquirido tras años de experiencia y entrenamiento riguroso. Para ello, el estudio seleccionó cinco de los modelos de inteligencia artificial más potentes disponibles en septiembre de 2025, accedidos a través de sus interfaces web nativas para simular el acceso que tendría un usuario profesional. Estos modelos son el OpenAI o3, el ya esperado GPT-5, el Gemini 2.5 Pro de Google, el Grok-4 de xAI y el Claude Opus 4.1 de Anthropic. A su lado, participaron dos cohortes de profesionales humanos: radiólogos certificados, considerados el estándar de oro en el diagnóstico por imagen, y residentes de radiología, que representan a los futuros expertos en etapa de aprendizaje.
La prueba consistió en evaluar 50 casos de «diagnóstico rápido» de nivel experto, extraídos de seis sistemas clínicos diferentes para asegurar una amplia variedad de escenarios. Estos casos abarcaban tres modalidades de imagen principales: tomografía computarizada (24 casos), resonancia magnética (13 casos) y radiografía (13 casos), lo que permitió al estudio analizar el rendimiento de la inteligencia artificial en diferentes tipos de datos y patologías. El formato fue diseñado para imitar la presión y la naturaleza del trabajo diario de un radiólogo: cada caso presentaba una serie de imágenes junto con datos clínicos relevantes, y tanto los humanos como los modelos debían generar un informe diagnóstico completo y preciso en un tiempo limitado. La evaluación no se basó únicamente en la corrección final, sino en una puntuación ordinal que distinguía entre un diagnóstico exacto (1.0), parcialmente correcto (0.5) y completamente erróneo (0.0), proporcionando así una medida más matizada de la calidad del razonamiento.
Este experimento, publicado en arXiv en septiembre de 2025 y aceptado para una presentación oral en la Reunión Anual de la Sociedad Radiológica Norte Americana (RSNA 2025), establece un nuevo punto de referencia para medir el progreso de la inteligencia artificial en un dominio crítico. Al someter a estos gigantes tecnológicos a una prueba tan rigurosa, el estudio RadLE no solo cuantifica la brecha actual entre la capacidad humana y la artificial, sino que también abre una discusión crucial sobre la fiabilidad, la interpretabilidad y, fundamentalmente, la seguridad de integrar estas herramientas en la cadena de atención médica. La pregunta que surge de forma inevitable es si, dada la evidencia de su inferioridad diagnóstica, la implementación masiva de estas inteligencias artificiales en entornos clínicos puede constituir un riesgo innecesario para la seguridad del paciente. El estudio no solo compara números, sino que también explora la lógica detrás de esos números, buscando entender por qué estas máquinas, capaces de crear arte y poesía, fallan cuando se les pide que lean el cuerpo humano con precisión.
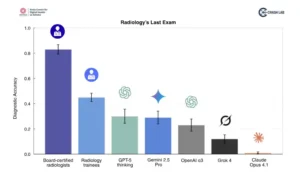
Precisión diagnóstica en humanos y sistemas de IA multimodales según el parámetro de referencia Radiology’s Last Exam (RadLE) v1. Los radiólogos certificados obtuvieron la mayor precisión (0,83), seguidos de los residentes (0,45). Todos los modelos fronterizos evaluados obtuvieron un rendimiento inferior al esperado, con GPT-5 (0,30) y Gemini 2.5 Pro (0,29) mostrando los mejores resultados de IA, pero muy por debajo de los parámetros humanos.
El desempeño comparativo: una evaluación rigurosa de capacidad diagnóstica
La pregunta central del benchmark RadLE fue cuál era el verdadero poder diagnóstico de las nuevas generaciones de inteligencia artificial frente a la experiencia humana. La respuesta, extraída de una muestra de 50 casos complejos, es inequívoca pero también reveladora. En términos de precisión diagnóstica, la brecha entre la inteligencia humana y la artificial es vasta y, por ahora, infranqueable. Los resultados, detallados en la siguiente tabla, pintan un retrato claro de la situación actual.
| Grupo | Precisión diagnóstica (%) | Fiabilidad (Kappa ponderado medio) |
|---|---|---|
| Radiólogos certificados | 83 | Sustancial (referencia) |
| Residentes de radiología | 45 | Baja |
| GPT-5 (mejor modelo de IA) | 30 | Sustancial (0.64) |
| OpenAI o3 | 23 | Sustancial (0.61) |
| Gemini 2.5 Pro | 29 | Moderada (0.53) |
| Grok-4 | 12 | Moderada (0.41) |
| Claude Opus 4.1 | 1 | Pobre (≈0) |
Como se observa, los radiólogos certificados lograron una tasa de precisión del 83%, un resultado que refuerza su estatus como expertos indiscutibles en el análisis de imágenes médicas. Esta cifra no es solo un número; representa la acumulación de miles de horas de entrenamiento, la internalización de patrones visuales complejos y la capacidad de integrar información clínica contextual de manera fluida. En el otro extremo del espectro se encuentran los residentes, con una precisión del 45%. Si bien están en proceso de formación, su rendimiento subyacente demuestra que el problema no reside únicamente en la falta de experiencia, sino en la incapacidad inherente de los modelos de inteligencia artificial para alcanzar un nivel básico de competencia diagnóstica.
«Los radiólogos certificados no solo superaron a la inteligencia artificial, sino que lo hicieron con un margen tan amplio, 83 % frente al 30 % del mejor modelo, que subraya la irremplazable profundidad del juicio clínico humano en el diagnóstico de casos complejos.»
El rendimiento de los modelos de inteligencia artificial es aún más revelador. El mejor de ellos, el modelo GPT-5, alcanzó un modesto 30% de precisión diagnóstica. Esto significa que, en casi siete de cada diez casos, el modelo más avanzado del mercado falló en identificar la condición clínica principal. Los otros modelos, como Gemini 2.5 Pro y Grok-4, mostraron rendimientos similares, mientras que Claude Opus 4.1 fue notablemente peor, destacando la gran disparidad en el desarrollo de estas tecnologías. Sin embargo, la historia no termina ahí. Aunque la precisión diagnóstica de la inteligencia artificial es baja, su capacidad para repetir un resultado en condiciones idénticas, es decir, su fiabilidad o reproducibilidad, varía significativamente. Para medir esto, los investigadores utilizaron el coeficiente kappa ponderado cuadrático y el coeficiente de correlación intraclase, métricas que miden el acuerdo entre diferentes ejecuciones del mismo modelo.
Los resultados de fiabilidad ofrecen una visión más matizada. Mientras que modelos como GPT-5 y o3 mostraron un acuerdo sustancial (con un kappa medio de 0.64 y 0.61 respectivamente), indicando que tienden a producir resultados consistentes, otros modelos como Gemini 2.5 Pro y Grok-4 tuvieron un acuerdo moderado (kappa alrededor de 0.53 y 0.41), y Claude Opus 4.1 demostró una fiabilidad pobre (kappa cercano a cero). Esta diferencia en la fiabilidad es crucial. Un modelo que produce respuestas inconsistentes es inherentemente menos útil en un entorno clínico, donde la predicción y la consistencia son tan importantes como la precisión. Por ejemplo, si un modelo diagnostica correctamente una patología en una ocasión y incorrectamente en otra, su utilidad práctica se ve drásticamente reducida.
El análisis cualitativo de los razonamientos generados por la inteligencia artificial, junto con la propuesta de una taxonomía de errores, profundiza aún más en estas discrepancias, explorando por qué y cómo estas máquinas cometen los errores que cometen. El estudio concluye advirtiendo contra el uso autónomo de estas inteligencias artificiales en el diagnóstico clínico debido a su baja precisión y fiabilidad en casos complejos, una advertencia que cobra relevancia dado el ritmo acelerado de su comercialización.
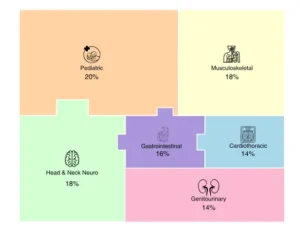
Distribución de casos por sistema clínico, que ilustra la asignación de casos de diagnóstico puntual en varios sistemas anatómicos dentro del conjunto de datos de referencia.
La lógica del error: descifrando la taxonomía de razonamiento visual de la IA
Si la comparación de precisiones revela la distancia entre la inteligencia artificial y el experto humano, el análisis cualitativo de los errores cometidos por la inteligencia artificial es donde emerge la verdadera profundidad del estudio RadLE. Este análisis no se contenta con señalar el fallo, sino que busca comprender la causa raíz del error, construyendo una taxonomía práctica de las fallas de razonamiento visual en la inteligencia artificial. Esta taxonomía es fundamental porque permite pasar de una visión mágica de la inteligencia artificial como un oráculo infalible a una comprensión pragmática de ella como una herramienta con defectos específicos y predecibles. Entender estos defectos es el primer paso para diseñar estrategias de mitigación, mejorar los modelos y, sobre todo, implementarlos de forma segura bajo supervisión humana.
La taxonomía propuesta por el estudio agrupa los errores en tres grandes categorías: perceptuales, interpretativos y de comunicación. Cada una de estas categorías encapsula un tipo diferente de fallo en el proceso de razonamiento de la inteligencia artificial.
Primero, los «errores perceptuales» se centran en la capacidad de la inteligencia artificial para detectar, localizar y diferenciar objetos en una imagen. Dentro de esta categoría se incluyen la subdetección, donde la inteligencia artificial omite por completo la presencia de un hallazgo patológico visible; la sobredetección, donde la inteligencia artificial inventa un hallazgo que no existe; y la mala localización, en la que la inteligencia artificial detecta un hallazgo, pero lo sitúa incorrectamente en la anatomía de la imagen.
Segundo, los «errores interpretativos» surgen cuando la inteligencia artificial ve algo, pero malinterpreta su significado clínico o biológico. Aquí, la máquina no está ciega, pero sí equivocada en su análisis. Incluyen la malinterpretación, donde la inteligencia artificial identifica correctamente una anomalía pero le asigna un diagnóstico incorrecto, y el cierre diagnóstico prematuro, un fallo de lógica en el que la inteligencia artificial se aferra a una primera impresión y deja de considerar alternativas diagnósticas.
Tercero, los «errores de comunicación» ocurren cuando la inteligencia artificial, aunque haya realizado un análisis visual preciso y una interpretación lógica, falla a la hora de transmitir sus hallazgos de forma coherente y precisa en el informe final. Esto se manifiesta como una discordancia entre los hallazgos descritos y la conclusión diagnóstica final, donde el modelo contradice en su resumen lo que ha observado en detalle.
Además de esta taxonomía estructurada, el estudio identifica sesgos cognitivos que pueden influir en el comportamiento de la inteligencia artificial, como el anclaje (aferrarse a la primera impresión de la imagen), la disponibilidad (dar más peso a lo que ha visto más frecuentemente en su base de datos de entrenamiento) y los efectos de encuadre (donde la formulación del prompt o la introducción del caso influye desproporcionadamente en el resultado final). Comprender estas categorías de error es vital. No se trata de una simple falla técnica, sino de un conjunto de patrones sistemáticos que revelan las debilidades fundamentales del paradigma de aprendizaje automático actual. Mientras que un radiólogo certificado utiliza una combinación de memoria visual, lógica clínica y contexto para llegar a un diagnóstico, la inteligencia artificial opera a partir de correlaciones estadísticas en grandes volúmenes de datos. Sus errores no son aleatorios; son huellas digitales de sus limitaciones inherentes, y reconocerlas es clave para evitar su uso no supervisado en aplicaciones clínicas.
La doble fila de sesgos: implicaciones éticas en datos, modelos e implementación
El debate sobre la inteligencia artificial en la radiología trasciende la pura cuestión técnica de la precisión diagnóstica. Más allá de los errores de razonamiento visual, la inteligencia artificial introduce una capa de complejidad ética profunda y preocupante, centrada en el concepto de los sesgos. Estos sesgos no son meros fallos de programación; son la manifestación tangible de las imperfecciones sociales y culturales contenidas en los datos con los que se entrena a las máquinas. Un estudio anterior revela que la falta de diversidad entre los desarrolladores y la insuficiente representación de ciertos grupos demográficos en los datos médicos pueden perpetuar y amplificar suposiciones erróneas y estereotipos negativos. Este fenómeno, conocido como «sesgo algorítmico», es uno de los mayores obstáculos para garantizar la equidad y la justicia en la atención sanitaria impulsada por la inteligencia artificial.
La investigación de Cobb Payton y sus colegas explica que los algoritmos de inteligencia artificial, a menudo entrenados con «big data» proveniente de registros médicos y bases de imágenes, ignoran el «small data». El «small data» se refiere a los determinantes sociales de la salud: factores como el acceso a transporte público para ir a citas médicas, la capacidad de pagar productos frescos para una dieta saludable, o la flexibilidad laboral para seguir un plan de tratamiento. Cuando un algoritmo no tiene en cuenta estas variables, puede malinterpretar el comportamiento de un paciente. Por ejemplo, si un paciente no sigue el tratamiento prescrito, la inteligencia artificial podría inferir que es negligente o poco cooperador, sin saber que la razón real es la imposibilidad económica o logística de hacerlo. Este tipo de malentendido refuerza estereotipos negativos, erosionando la confianza entre los pacientes y el sistema sanitario, especialmente en comunidades ya marginadas.
Las consecuencias de estos sesgos son graves y tangibles. Se sabe que la mortalidad general es casi un 30 % más alta en pacientes no hispanos negros que en blancos no hispanos, y enfermedades como cardiopatías, accidentes cerebrovasculares, diabetes y cáncer de mama en mujeres negras tienden a ser más severas. A pesar de tener una carga de enfermedad mayor, estos pacientes pueden ser diagnosticados incorrectamente o recibir menos recursos debido a sesgos algorítmicos. Un ejemplo citado en la literatura es el de los modelos de detección de melanoma, que muestran un peor desempeño en pieles oscuras porque sus bases de datos de entrenamiento están predominantemente compuestas por imágenes de piel clara. De manera similar, el modelo Epic Sepsis Model (ESM), utilizado para detectar la sepisis en hospitales, experimentó una reducción en su rendimiento después de su implementación en el mundo real, probablemente debido a diferencias entre el entorno de entrenamiento y el de producción.
La cuestión se complica aún más con el uso de marcadores demográficos como la raza dentro de los algoritmos clínicos. Un ejemplo alarmante es la estimación del filtrado glomerular (eGFR), una medida de la función renal. Muchos modelos clínicos utilizan un factor de ajuste por raza, que puede sobreestimar la función renal en pacientes negros, retrasando su inclusión en listas de espera para trasplantes. Este tipo de sesgos no solo es injusto; es perjudicial para la salud.
El problema se origina en la recolección de datos, donde la mayoría de los datos de pacientes en Estados Unidos provienen de solo tres estados (California, Massachusetts y Nueva York), lo que crea una falta de representatividad geográfica que afecta negativamente la calidad de la atención en zonas rurales y diversas. Además, la falta de diversidad en el propio sector de la tecnología médica es crítica: solo el 5 % de los médicos activos en 2018 eran negros y el 6 % hispanos o latinos, una cifra que probablemente se refleja en el desarrollo de estas herramientas.
La solución propuesta no es trivial y requiere un esfuerzo coordinado: mayor diversidad en los equipos de desarrollo, revisiones rigurosas de los datos de entrada para identificar y mitigar sesgos, y la implementación obligatoria de un control humano («human in the loop») durante todo el ciclo de vida del algoritmo. La Administración de Alimentos y Medicamentos carece de regulaciones explícitas sobre equidad en inteligencia artificial médica, lo que subraya la necesidad urgente de transparencia y reporte estandarizado de sesgos para proteger a los pacientes vulnerables.
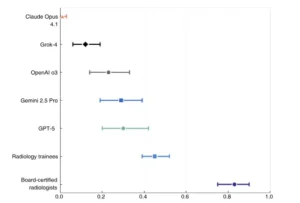
Precisión diagnóstica media (IC del 95%)
Precisión diagnóstica general en los grupos de lectores. Esta figura presenta la precisión diagnóstica media con intervalos de confianza del 95 % para radiólogos certificados, radiólogos en formación y cinco modelos de IA de vanguardia (GPT-5, Gemini 2.5 Pro, OpenAI o3, Grok-4 y Claude Opus 4.1) en 50 casos complejos de diagnóstico radiológico puntual.
El impacto clínico y el mercado de la IA en radiología
El desarrollo de la inteligencia artificial en radiología no ocurre en un vacío; está inserto en un contexto clínico y económico dinámico. Por un lado, existe una demanda creciente de herramientas que puedan acelerar y mejorar la precisión del diagnóstico, especialmente en áreas con una escasez de especialistas. Por otro, el mercado comercial de estos productos está experimentando un crecimiento explosivo, lo que genera una tensión entre la innovación rápida y la validación rigurosa. El estudio RadLE debe ser entendido a la luz de esta dualidad, ya que su mensaje de precaución choca frontalmente con la tendencia empresarial hacia una implementación acelerada.
Desde el punto de vista clínico, la radiología es un campo con una alta concentración de productos de inteligencia artificial. Según datos de octubre de 2024, existían 222 productos comerciales basados en inteligencia artificial para radiología, de los cuales 213 estaban certificados. Este número representa un aumento del 150% en relación con los 85 productos certificados en 2021, un crecimiento que muestra una trayectoria exponencial. La distribución de estos productos revela las áreas de mayor interés y necesidad.
Las modalidades de imagen más servidas son la tomografía computarizada con 89 productos y la resonancia magnética con 66, seguidas de la radiografía (46), la mamografía (16) y el ultrasonido (10). En cuanto a las patologías, el enfoque se concentra en las enfermedades con mayor impacto global: el cáncer de pulmón (28 productos), los accidentes cerebrovasculares (24 productos) y el cáncer de mama (19 productos) son las áreas con mayor número de soluciones de inteligencia artificial.
En Estados Unidos, la Administración de Alimentos y Medicamentos ha sido un motor clave de esta expansión. Se han reportado 700 algoritmos de inteligencia artificial aprobados por la Administración de Alimentos y Medicamentos, de los cuales un asombroso 76% (527) corresponden a la radiología. Este alto porcentaje subraya la importancia estratégica de la inteligencia artificial en este campo específico. La aprobación de estos productos suele estar sujeta a clasificaciones regulatorias que van desde la clase I (bajo riesgo) hasta la clase IIa (riesgo moderado). En el mercado europeo, la normativa MDD/MDR sigue un sistema similar, con una alta concentración de productos en la categoría de riesgo bajo (Clase I) y moderado (Clase IIa). Históricamente, hubo un pico en la entrada de nuevos productos al mercado en 2020, con 50 aprobaciones, y el ritmo se mantuvo elevado hasta alcanzar un máximo de más de 80 aprobaciones en 2023.
Sin embargo, esta avalancha de productos plantea una pregunta crucial: ¿la velocidad de la innovación comercial está dejando atrás la seguridad y la validación clínica? El benchmark RadLE sugiere un rotundo sí. Si los modelos más avanzados del mercado, como GPT-5, tienen una precisión diagnóstica del 30% en casos complejos, la idea de implementar estos algoritmos en línea de producción sin una supervisión humana rigurosa parece temeraria. La recomendación de mantener un «humano en el bucle» («human in the loop») no es solo una sugerencia técnica, sino una necesidad ética y clínica. Los algoritmos, por muy rápidos que sean, no poseen la sabiduría clínica, la capacidad de adaptación ni la empatía que caracterizan al radiólogo humano. Su papel ideal no es reemplazar al experto, sino complementarlo, actuando como un segundo par de ojos que puede ayudar a detectar patrones sutiles o alertar sobre patologías que podrían haber pasado desapercibidas. El desafío futuro reside en encontrar el equilibrio correcto entre la eficiencia automatizada y la seguridad garantizada por la supervisión humana, asegurando que la integración de la inteligencia artificial sea un paso hacia adelante, no un salto a ciegas.
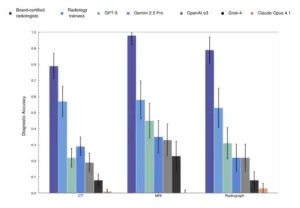
Precisión diagnóstica detallada por modalidad. Esta figura amplía la comparación por modalidad, mostrando la precisión diagnóstica media con intervalos de confianza del 95 % para radiólogos, residentes y cinco modelos de IA de vanguardia (GPT-5, Gemini 2.5 Pro, OpenAI o3, Grok-4 y Claude Opus 4.1) en TC, RM y radiografía.
La síntesis de la inteligencia humana y artificial en la práctica clínica
Al concluir el análisis del benchmark *Radiology’s Last Exam*, emerge una imagen compleja pero definida sobre el papel actual y futuro de la inteligencia artificial en el diagnóstico por imagen. Lejos de ser una amenaza inminente para los radiólogos, la inteligencia artificial de vanguardia se presenta como una herramienta poderosa pero incipiente, cuyo rendimiento diagnóstico es actualmente insuficiente para operar de forma autónoma en entornos clínicos complejos.
El estudio no niega el potencial transformador de la inteligencia artificial, que ya demuestra su utilidad en tareas específicas como la segmentación de tumores o la triage de emergencias, pero claramente establece los límites de su capacidad generalista. La conclusión principal es inequívoca: la brecha entre el diagnóstico humano experto y la capacidad de la inteligencia artificial moderna sigue siendo abismal, con los modelos más avanzados obteniendo una precisión del 30% frente al 83% de los radiólogos certificados.
El valor real de estudios como RadLE no reside únicamente en la medición de la precisión, sino en la profundización que realizan en el «cómo» y el «porqué» de los errores de la inteligencia artificial. Al desarrollar una taxonomía de errores de razonamiento visual (clasificándolos en perceptuales, interpretativos y de comunicación), el estudio proporciona un marco conceptual para entender las debilidades fundamentales de los actuales paradigmas de aprendizaje automático. Estos errores no son aleatorios; son signos de que la inteligencia artificial todavía no comprende el contexto clínico, la anatomía en su totalidad ni las sutilezas de la lógica diagnóstica. Reconocer que la inteligencia artificial comete errores por malinterpretación o cierre diagnóstico prematuro, por ejemplo, es crucial para anticipar sus fallos y diseñar sistemas de alerta y supervisión adecuados.
No obstante, el análisis más profundo del estudio radica en su doble foco: el diagnóstico y el sesgo. La investigación de Cobb Payton y colaboradores añade una dimensión ética indispensable al debate. Revela que los algoritmos de inteligencia artificial no son neutralidades técnicas, sino reflejos de las sociedades que los crean y alimentan. El sesgo en los datos, la falta de diversidad en los desarrolladores y la ignorancia de los determinantes sociales de la salud pueden transformar una herramienta de diagnóstico en un vehículo para perpetuar y amplificar las desigualdades existentes.
La conclusión es contundente: sin un esfuerzo deliberado y coordinado para garantizar la equidad en los datos, los modelos y la implementación, la inteligencia artificial correrá el riesgo de empeorar las disparidades en salud en lugar de resolverlas.
En resumen, el futuro de la radiología no es un duelo entre el hombre y la máquina, sino una colaboración entre ambas. La inteligencia artificial, en su estado actual, está lejos de reemplazar al radiólogo. Su rol más prometedor es el de un asistente experto, capaz de procesar enormes volúmenes de datos con rapidez y detectar anomalías sutiles. Pero para que esta colaboración sea segura y beneficiosa, deben cumplirse dos condiciones cruciales. Primero, la inteligencia artificial debe operar siempre bajo una supervisión humana rigurosa y continua («human in the loop»), donde el experto humano pueda validar, contextualizar y corregir los hallazgos de la máquina. Segundo, es imperativo abordar los sesgos algorítmicos mediante la diversificación de los datos de entrenamiento, la transparencia en el funcionamiento de los algoritmos y la participación de un equipo multidisciplinar que incluya a responsables políticos, desarrolladores, médicos y pacientes.
El camino hacia una radiología de inteligencia artificial segura y equitativa es largo y requiere una combinación de rigor científico, ética vigilante y una visión clara de que la inteligencia artificial es, en última instancia, una extensión de la capacidad humana, no una substituta.
Referencias
Datta, S., Buchireddygari, D., Kaza, L. V. C., et al. (2025). *Radiology’s Last Exam (RadLE): Benchmarking Frontier Multimodal AI Against Human Experts and a Taxonomy of Visual Reasoning Errors in Radiology*. arXiv:2509.25559 [cs.AI].
European Society of Radiology (ESR) AI Working Group. (2024). *AI in radiology: Market analysis and clinical integration report*. Insights into Imaging, 15(1), 112.
Brin, D., Sorin, V., Barash, Y., Konen, E., Glicksberg, B. S., Nadkarni, G. N., et al. (2025). Assessing GPT-4 multimodal performance in radiological image analysis. *European Radiology*, 35(4), 1959–1965.

