
Imagínese poder pedirle a su computadora que realice por usted un conjunto complejo de tareas (desde organizar archivos, enviar correos electrónicos, hasta configurar una hoja de cálculo con gráficos) y que, tras unos minutos, encuentre todo hecho a la perfección. Esta escena, que podría parecer sacada de la ciencia ficción, está cada vez más cerca de ser realidad gracias a los avances en agentes digitales capaces de usar una computadora casi como lo haría un ser humano.
En los últimos años ha emergido la visión de convertirnos en gestores de tareas digitales en lugar de ejecutores directos: delegar labores cotidianas a programas de inteligencia artificial que navegan interfaces gráficas, hacen clic, escriben y manejan aplicaciones en nuestro nombre. Estos sistemas, conocidos como agentes de uso de computadora (siglas en inglés CUA, por Computer-Use Agent), prometen una auténtica revolución en la forma en que interactuamos con la tecnología y gestionamos nuestra productividad.
Sin embargo, desarrollar un asistente virtual con la capacidad de realizar múltiples pasos en entornos informáticos reales ha demostrado ser un desafío formidable. Si bien prototipos recientes (desde asistentes integrados en sistemas operativos hasta agentes autónomos que reservan vuelos o programan software por su cuenta) demuestran el potencial de esta idea, también han puesto de manifiesto sus limitaciones. En la práctica, estos agentes suelen cometer errores, atascarse o mostrar un desempeño inconsistente cuando enfrentan tareas largas y complejas. Un pequeño fallo al hacer clic en el lugar equivocado o al interpretar mal una instrucción puede descarrilar por completo una secuencia de acciones. Además, su comportamiento tiende a ser variable: incluso dando la misma instrucción dos veces al mismo agente, el resultado puede diferir. Esta falta de fiabilidad y alta variabilidad ha frenado la adopción de los CUAs en escenarios reales, donde se requiere confianza para delegar tareas críticas.
Frente a este panorama, un grupo de investigadores en inteligencia artificial se planteó cómo aumentar la robustez y el éxito de los agentes informáticos en tareas de largo alcance. Su trabajo, titulado The Unreasonable Effectiveness of Scaling Agents for Computer Use (“La eficacia irrazonable de escalar agentes para el uso de la computadora”), presentó una solución ingeniosa y contraintuitiva: en lugar de intentar perfeccionar al agente en un único intento, hacer que lo intente varias veces y luego elegir su mejor resultado. Esta idea de “escalar” al agente multiplicando sus oportunidades de actuar demostró ser sorprendentemente efectiva. Al combinar múltiples ejecuciones de un agente con un mecanismo inteligente para evaluar cuál de ellas cumplió mejor el objetivo, lograron que el asistente digital alcanzara tasas de éxito cercanas al nivel humano en un conjunto de tareas complejas. A continuación, exploraremos en detalle en qué consisten estos agentes de uso de computadora, cuáles son sus problemas actuales, y cómo la técnica propuesta, denominada Behavior Best-of-N (bBoN), consigue superar muchos obstáculos mediante narrativas de comportamiento y una cuidadosa selección de trayectorias. También revisaremos los resultados experimentales que evidencian las mejoras en rendimiento y generalización a distintos sistemas operativos, así como las limitaciones que aún persisten.
Agentes de uso de computadora: qué son y qué problemas enfrentan
En términos sencillos, un agente de uso de computadora es un programa de inteligencia artificial diseñado para utilizar una computadora como lo haría un usuario humano. Esto significa que el agente puede interactuar con aplicaciones y sistemas operativos: abre y cierra programas, hace clic en botones, escribe texto, navega por menús y páginas web, todo guiado por instrucciones u objetivos definidos previamente. A diferencia de un software tradicional, que sigue pasos preprogramados, un agente CUA tiene cierto grado de autonomía y flexibilidad para decidir cómo cumplir una tarea. Por ejemplo, si se le pide “envía este informe por correo electrónico a la lista de ventas y guarda una copia en Drive”, el agente debe entender el objetivo final y luego realizar los pasos intermedios necesarios: abrir el cliente de correo, redactar el mensaje, adjuntar el archivo, identificar la lista de ventas, enviar el correo; luego abrir el navegador, ingresar a Google Drive, navegar hasta la carpeta adecuada y subir el archivo. Todo ello, además, gestionando las ventanas y diálogos que aparezcan en pantalla como lo haría una persona.
Lograr este nivel de entendimiento y acción con un programa requiere integrar múltiples capacidades de inteligencia artificial. El agente necesita percibir la interfaz gráfica (muchas veces utilizando visión por computadora para leer textos y reconocer botones en la pantalla), necesita razonar sobre qué acciones son pertinentes en cada momento (por ejemplo, decidir si debe hacer clic en un icono de “Enviar” o esperar a que se cargue una página), y debe ser capaz de secuenciar acciones de manera lógica para alcanzar la meta final. En esencia, un CUA combina percepción visual, comprensión de lenguaje natural (para las instrucciones y para leer contenido en pantalla) y planificación/ejecución de acciones, todo dentro de un entorno digital simulado o real.
Los avances recientes en modelos de lenguaje e IA multimodal han dado impulso a estos agentes. Ya existen demostraciones impresionantes de asistentes que programan software completo o que gestionan un sistema operativo mediante comandos de lenguaje natural. Sin embargo, la promesa de delegar completamente tareas complejas en estos agentes aún enfrenta serios problemas.
Uno de los mayores retos es la fiabilidad a largo plazo: cuando una tarea involucra decenas de pasos (lo que en jerga se llama una tarea de “horizonte largo”), las probabilidades de que el agente cometa un error en algún punto aumentan drásticamente. Por ejemplo, en el proceso de enviar el informe del ejemplo anterior, el agente podría equivocarse al reconocer el icono correcto, o tal vez escribe mal la dirección de correo, o no encuentra la carpeta de Drive y abandona. Son muchos puntos posibles de fallo. Además, los CUAs actuales suelen mostrar un comportamiento no determinista: el mismo agente que hoy completa exitosamente una tarea, mañana podría fallar en la misma debido a leves variaciones en el entorno o a decisiones internas del modelo de IA que, al no estar programado de forma rígida, puede optar por diferentes acciones en cada ejecución.
Esta combinación de errores esporádicos, acumulación de fallos y resultados impredecibles conlleva que el rendimiento global de un agente en tareas complejas sea todavía bajo comparado con un humano. Imaginemos que a un asistente digital se le asignan 10 tareas distintas de oficina (programar reuniones, ordenar archivos, extraer datos de un informe, etc.); quizá logre completar correctamente apenas 5 o 6 de ellas antes de fallar en alguna. Ese porcentaje de éxito es insuficiente si queremos confiarle tareas reales sin supervisión constante.
En los laboratorios, los investigadores han cuantificado este desempeño en plataformas de prueba. Por ejemplo, existe un entorno llamado OSWorld que consiste en una serie de tareas simuladas en un sistema operativo (basado en Linux Ubuntu) para evaluar a estos agentes. Los resultados previos a la investigación que nos ocupa indicaban tasas de éxito en torno al 60% en OSWorld con los mejores agentes disponibles. Esto significa que, de cada 10 tareas, aproximadamente 4 quedaban sin completar o con errores. Claramente, había un amplio margen de mejora.
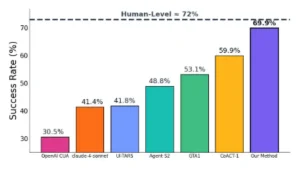
Rendimiento en OSWorld a 100 pasos. Nuestro método supera al SoTA anterior con una mejora absoluta del 10 %, alcanzando casi el nivel de rendimiento humano.
Escalar los intentos del agente: cuando más es mejor
Ante un agente que falla con frecuencia pero de forma impredecible, una pregunta natural es: ¿y si simplemente le damos más oportunidades de intentarlo? Después de todo, un mismo agente podría tener “suerte” en una de cada varias ejecuciones y lograr la secuencia correcta de acciones que lleva al éxito. De hecho, los investigadores observaron que muchas veces diferentes intentos del agente fallan en puntos distintos. Quizá en un primer intento se equivocó al renombrar un archivo, pero en otro intento atina en eso y falla más adelante al no encontrar un menú, mientras que un tercer intento comete un error distinto en una etapa diferente. Si se pudieran combinar las fortalezas de cada ejecución, el agente parecería mucho más competente. Aunque un solo recorrido puede ser frágil, la probabilidad de que al menos uno de varios recorridos sea exitoso es mucho mayor.
Esta idea de aprovechar múltiples intentos no es nueva en el mundo de la inteligencia artificial: en diversas aplicaciones se usa un enfoque de “best-of-N” (el mejor de N intentos), donde se generan N resultados o soluciones posibles y luego se escoge la mejor. En el caso de los agentes de computadora, “escalar” al agente se refiere justamente a ejecutar varias instancias independientes del agente en paralelo o en serie, cada una tratando de resolver la misma tarea, para luego comparar sus desempeños. En lugar de confiar todo a una única ejecución, le damos al agente, por ejemplo, cinco oportunidades y vemos cuál de las cinco sale mejor. Es casi como tener cinco versiones del asistente digital trabajando al mismo tiempo en la misma encomienda; al final, con suerte, al menos uno de ellos habrá encontrado la manera correcta de realizarla.
Sin embargo, poner en práctica este enfoque en un entorno informático complejo tiene sus matices. Primero, necesitamos asegurarnos de que estos múltiples intentos no interfieran unos con otros (cada agente debe trabajar en un ambiente aislado, como si cada uno tuviera su propio “escritorio virtual”) para que sus acciones no se crucen (por ejemplo, que dos instancias no intenten modificar el mismo archivo simultáneamente, causando caos). Segundo, y más importante, debemos tener un criterio claro para decidir cuál de los intentos fue el mejor. En ciertos casos es obvio, por ejemplo, si solo una de las ejecuciones logró completar todas las subtareas solicitadas, pero en otros puede que varios intentos sean parciales o que cada uno haya logrado diferentes partes del objetivo. Entonces surge la pregunta: ¿cómo evaluamos cada trayectoria de acciones del agente para saber cuál alcanzó el mayor éxito?
Es aquí donde entra en juego la principal contribución del equipo de investigadores: un método llamado Behavior Best-of-N (bBoN), que podríamos traducir como “Mejor Comportamiento de entre N intentos”. Este método no se limita a ejecutar N veces al agente, sino que introduce un sistema inteligente para entender y comparar lo que hizo el agente en cada intento. En esencia, bBoN propone generar una descripción narrativa del comportamiento de cada agente en cada ejecución, y luego utilizar esas descripciones para determinar de manera fundamentada cuál de los intentos cumplió mejor la tarea encomendada. En lugar de simplemente medir resultados numéricos o inspeccionar solo el estado final, el método analiza cómo llegó cada agente a su resultado y qué sucedió en el camino, lo que permite una selección más informada del mejor intento. Veamos con más detalle en qué consisten estas “narrativas de comportamiento” y cómo ayudan a escoger la trayectoria ganadora.

Éxito de tareas disjuntas en implementaciones de tres instancias de agente. El comportamiento Best-of-N (bBoN) aprovecha esta complementariedad seleccionando la mejor trayectoria entre múltiples implementaciones.
Narrativas de comportamiento: contando la historia de cada intento
Uno de los avances clave de la técnica bBoN es la idea de resumir cada ejecución del agente en una narrativa comprensible, es decir, en un relato estructurado que describa los pasos que tomó el agente y los efectos de esos pasos. ¿Por qué es necesario “contar una historia” de cada intento? Pensemos en cómo evaluaría un humano si un asistente completó bien una tarea: una persona probablemente repasaría las acciones realizadas (“abrió el programa de correo, luego escribió el mensaje, adjuntó el archivo, finalmente dio clic en enviar…”) y comprobaría si cada paso tuvo el efecto esperado. De forma análoga, las narrativas de comportamiento son una forma de extraer de la maraña de datos de cada ejecución, clics, capturas de pantalla, cambios en el sistema, una secuencia de frases o descripciones que reflejen las acciones clave y sus resultados.
Para lograr esto, los investigadores dotaron a su sistema de un componente generador de narrativas. Cada vez que un agente (digamos, la instancia 1 de los N en ejecución) realiza una acción, el sistema observa el estado antes y después de esa acción. Por ejemplo, si la acción fue “hacer clic en el botón ‘Eliminar archivo’ para borrar un documento llamado Reporte.pdf”, el estado del sistema antes del clic mostraba ese archivo presente en una carpeta, y después del clic el archivo ya no está. La narrativa condensaría ese paso en algo como: “El agente hizo clic en ‘Eliminar archivo’ y el archivo Reporte.pdf desapareció de la carpeta, indicando que fue borrado exitosamente”. De esta manera, se traducen las acciones e impactos visuales en la interfaz a oraciones descriptivas. Repitiendo este proceso para cada etapa relevante, al final se obtiene un resumen textual de toda la trayectoria del agente en esa ejecución, destacando qué hizo en cada paso y qué ocurrió como consecuencia.
Estas narraciones tienen varias ventajas. Primero, reducen la complejidad: en vez de analizar directamente cientos de eventos de bajo nivel (movimientos del ratón, coordenadas de clic, valores pixelados de pantallas), se trabaja con un relato simplificado que resalta solo la información importante. Segundo, al estar en formato de lenguaje natural (por ejemplo, frases descriptivas en texto), es más fácil aplicar métodos de comprensión, incluso emplear otro modelo de IA o reglas lógicas– para evaluar el éxito. Tercero, las narrativas permiten comparar intentos de manera cualitativa: es posible leer dos historias de agentes intentando la misma tarea y discernir cuál de ellos llegó más lejos o cumplió de forma más completa con la petición original.
Un detalle interesante es que estas narrativas de comportamiento funcionan como una suerte de memoria explicativa de cada agente. En escenarios multimodales donde hay elementos visuales (capturas de pantalla) y acciones secuenciales, la narrativa entrelaza ambos aspectos: menciona la acción (“abrió tal aplicación”, “escribió tal texto”) y el resultado observado (“se abrió la ventana X”, “apareció Y en pantalla”). En la investigación, se emplearon técnicas de visión artificial para detectar cambios en la interfaz (como la aparición o desaparición de elementos en la pantalla) y convertirlos en texto descriptivo. De esta manera, si un agente tomaba un rumbo equivocado –por ejemplo, abriendo la aplicación incorrecta– la narrativa lo reflejaba claramente (“el agente abrió por error la aplicación Z, que no estaba relacionada con la tarea”).
Al final de un intento, disponemos entonces de un relato estructurado que describe todo el recorrido del agente. Cabe señalar que estas narrativas deben ser precisas y objetivas, es decir, describir con veracidad lo ocurrido sin “adivinar” intenciones más allá de lo observable. Si el agente no logró completar la tarea, la narrativa quizás terminará en un punto intermedio (“el agente navegó al menú de opciones pero no encontró el comando necesario y se detuvo”). Si, por el contrario, el agente tuvo éxito, el relato lo dejará en claro (“tras varios pasos, el agente logró enviar el correo y guardar el archivo en la ubicación solicitada”). Tener esta información en un formato textual unificado es la base para el siguiente paso: que un evaluador automático decida cuál de las narrativas, y por tanto, cuál de los intentos del agente, representa el mejor desempeño.
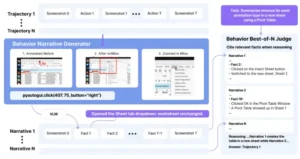
El Mejor de N en Comportamiento genera múltiples despliegues que consisten en capturas de pantalla y acciones. Estas trayectorias se convierten en narrativas de comportamiento mediante el generador de narrativas de comportamiento, utilizando la acción ejecutada y capturas de pantalla del antes y el después para describir los cambios. Finalmente, las narrativas de comportamiento se entregan al juez, quien selecciona la mejor trayectoria mediante comparación.
Un juez inteligente: cómo se elige la mejor trayectoria
Contar con las narrativas de comportamiento de cada ejecución nos permite compararlas para determinar cuál agente consiguió acercarse más o cumplir completamente la tarea. Pero, ¿cómo se implementa esta comparación? Los investigadores desarrollaron un componente al que metafóricamente podemos llamar el “juez” de bBoN. Este juez es un sistema (podemos imaginarlo como una IA especializada o un algoritmo de evaluación) que lee todas las narrativas de los N intentos en conjunto y emite un veredicto: selecciona la trayectoria que considera más exitosa o correcta.
¿Por qué leerlas en conjunto? Aquí radica otra sutileza importante: el estudio encontró que resulta más eficaz evaluar las narrativas de forma comparativa que hacerlo de manera aislada. Si uno intentara calificar cada intento por separado, por ejemplo, dándoles un puntaje de éxito independientemente de los demás, podría perder el contexto relativo. En cambio, al tener frente a sí las historias de todos los intentos, el juez puede detectar directamente cuál logró lo que los otros no. Es similar a un concurso donde los jueces comparan a todos los participantes lado a lado en vez de evaluarlos en días separados; la comparación simultánea resalta diferencias con mayor claridad.
El mecanismo concreto del juez en bBoN se basa en criterios ligados al cumplimiento del objetivo. Simplificando, el juez busca en las narrativas indicios de que el agente logró el resultado final deseado y, asimismo, presta atención a en qué paso (si alguno) cada intento se quedó corto. Por ejemplo, supongamos que la tarea era “formatear un párrafo en negrita en un documento de texto y guardar los cambios en PDF”. Si una narrativa termina con “el agente abrió el menú de formato, aplicó negrita al texto seleccionado y guardó el documento como PDF en la carpeta Documentos”, claramente ese intento tuvo éxito. Si otra narrativa distinta finaliza con “el agente seleccionó el texto pero no llegó a aplicar el formato antes de cerrar el documento inadvertidamente”, entenderemos que ese intento fracasó a mitad de camino. El juez de bBoN, al interpretar ambas descripciones, elegiría la primera como la mejor trayectoria.
Es importante destacar que el juez de bBoN no adivina ni asume más allá de las evidencias en las narrativas. Su tarea es identificar cuál historia refleja de manera más completa y correcta el cumplimiento de la instrucción dada al agente. Para ello, puede usar desde reglas predefinidas (“si la narrativa menciona explícitamente que se logró X, Y, Z, entonces se completó la tarea”) hasta modelos de lenguaje entrenados para leer y comparar texto. De hecho, en la implementación del estudio es muy posible que hayan utilizado una inteligencia artificial del tipo GPT o similar, calibrada para entender las narrativas y elegir la más exitosa. Así, el juez actúa como un árbitro neutral que decide el “ganador” entre las múltiples ejecuciones.
La eficacia de este enfoque se evidenció en los experimentos. Utilizando bBoN con, digamos, N = 10 (diez intentos paralelos por tarea), la probabilidad de que al menos uno de los intentos resolviera la tarea aumentó sustancialmente respecto a un único intento. Y gracias al juez, el sistema era capaz de identificar correctamente ese intento ganador la mayoría de las veces. En otras palabras, la combinación de exploración amplia (muchos intentos diferentes) con una selección informada (comparar narrativas) condujo a una mejora dramática en los resultados finales del agente. Incluso se observó que este método superaba a estrategias más sencillas de selección, como por ejemplo usar solo la captura de pantalla final de cada agente para intentar deducir quién logró el objetivo. Las narrativas proporcionan mucha más información que una imagen estática o que un simple indicador de éxito/fallo, lo que permite al juez tomar una decisión más sólida.
Resultados: rendimiento y generalización casi a nivel humano
La propuesta de Behavior Best-of-N no se quedó en la teoría, sino que fue puesta a prueba en una batería de experimentos con distintos conjuntos de tareas. El primero de ellos fue OSWorld, el entorno de escritorio Linux simulado del que hablábamos antes. Allí, los investigadores comprobaron que su agente escalado con bBoN alcanzó una tasa de éxito del 69,9% en las tareas de OSWorld, estableciendo un nuevo récord en comparación con métodos anteriores que rondaban el 59,9%. Este salto de aproximadamente 10 puntos porcentuales representa una mejora sustancial en términos de robustez: de pasar a completar con éxito 6 de cada 10 tareas, se logró completar prácticamente 7 de cada 10. Más impresionante aún, el desempeño del agente se acercó mucho al de un usuario humano en el mismo entorno, que se estima alrededor del 72%. En otras palabras, mediante la técnica de escalar los intentos y elegir el mejor (combinada con varias optimizaciones detalladas en el estudio), se logró que el agente casi igualara la eficacia humana en una variedad de tareas informáticas.
No solo eso, sino que el enfoque demostró ser generalizable a otras plataformas más allá de Linux. Los autores del trabajo probaron bBoN en entornos de tareas para Windows (denominado experimentalmente WindowsAgentArena) y para Android (AndroidWorld). En ambos casos, los agentes escalados mostraron mejoras notables respecto a la versión sin escalar. Por ejemplo, en WindowsAgentArena se registró un aumento de la tasa de éxito de alrededor del 6,4% por encima del método tradicional, y en AndroidWorld un aumento en torno al 3,5%. Esto indica que la idea de generar múltiples intentos y juzgarlos con narrativas no está ligada a un sistema operativo específico, sino que es un principio amplio que puede ayudar a un agente a desenvolverse mejor tanto en una PC de escritorio tradicional como en un teléfono inteligente. La adaptabilidad a distintos entornos es crucial, porque en el mundo real las interfaces y sistemas varían enormemente, no es lo mismo automatizar tareas en Windows que en un teléfono Android, y una técnica verdaderamente útil debe ser capaz de trascender una única plataforma.
Otro hallazgo interesante del estudio fue que mientras más intentos se permiten, mayor es la tasa de éxito obtenida, aunque con rendimientos decrecientes. Es decir, pasar de un intento único a, digamos, cinco intentos aporta una gran mejora; de 5 a 10 intentos continúa mejorando notablemente; pero si uno siguiera incrementando N, llegaría un punto en que el beneficio extra por cada intento adicional se reduce. Esto es intuitivo: las primeras ejecuciones adicionales cubren las principales fuentes de fallo, pero eventualmente la mayoría de intentos ya logran buen desempeño y añadir muchos más solo aumenta ligeramente la probabilidad de hallar uno perfecto. Aun así, el hecho de que la curva de éxito siga en ascenso sugiere que hay valor en escalar incluso más en casos muy críticos, siempre que se cuente con los recursos computacionales para ello.
También se comprobó que las narrativas de comportamiento superaron a descripciones más simples a la hora de seleccionar al intento ganador. Los investigadores compararon su método con variantes en las que el juez solo veía, por ejemplo, la pantalla final de cada agente, o un registro muy básico de acciones. La versión completa con narrativas detalladas permitió decisiones más acertadas, confirmando que capturar las relaciones de causa y efecto en cada paso (acción y resultado) es importante para evaluar correctamente el éxito.
En resumen, los experimentos validaron que la combinación de exploración amplia (múltiples ejecuciones) y evaluación inteligente (vía narrativas y juicio comparativo) resulta en agentes mucho más fiables y efectivos. Por primera vez, un agente de uso de computadora logró acercarse al desempeño humano en tareas de escritorio variadas, y mostró poder adaptarse a diferentes sistemas sin perder eficacia. Esto marca un hito en el camino hacia asistentes digitales verdaderamente útiles en entornos cotidianos.
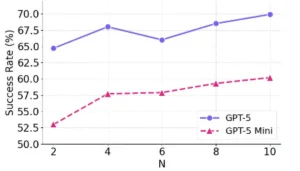
Rendimiento de ribBoN en OSWorld con un número creciente de implementaciones.
Limitaciones y desafíos pendientes
Si bien los resultados de bBoN son muy alentadores, los propios autores señalan que aún hay desafíos por resolver antes de que estos agentes escalados se conviertan en herramientas cotidianas infalibles. En primer lugar, coordinar múltiples intentos paralelos conlleva una complejidad técnica. En un entorno de laboratorio, es relativamente factible ejecutar cinco o diez instancias de un agente en máquinas virtuales aisladas, asegurándose de que cada una empiece con el mismo estado inicial y sin interferir con las demás. Pero llevar esto a entornos reales implica lidiar con posibles conflictos de recursos: por ejemplo, si varias instancias acceden a una misma cuenta en línea o base de datos simultáneamente, podrían generar inconsistencias. Se requerirá desarrollar mecanismos de aislamiento y gestión de concurrencia más sofisticados para que la técnica sea práctica a gran escala, especialmente si se piensa en integrarla en sistemas operativos reales o servicios en la nube.
Otra limitación importante está en la calidad de las narrativas de comportamiento. Estas funcionan tan bien como la precisión de la información que contengan. Si el agente no percibe correctamente un cambio sutil en la interfaz (digamos, un pequeño mensaje de error en letra pequeña) y por tanto la narrativa omite ese detalle, el juez podría sobrestimar el éxito de ese intento. De forma similar, si una narrativa es muy extensa y está llena de detalles triviales, podría “impresionar” indebidamente al juez en comparación con otra narrativa más escueta pero correspondiente a un intento que en realidad resolvió la tarea de forma eficiente. De hecho, los investigadores mencionan casos donde el agente tiene dos maneras de resolver algo, por ejemplo, mediante comandos de código o mediante la interfaz gráfica, y si una de las narrativas luce más elaborada simplemente por describir más clics y ventanas, el juez podría sesgarse a pensar que esa fue mejor, aun si la solución alternativa (más corta, vía código) sí cumplió el objetivo. Esto revela un sesgo potencial del juez hacia narrativas más “ricas” en apariencia. Abordar este sesgo requerirá afinar los criterios de evaluación para que valoren correctamente la sustancia del resultado por encima de la longitud o complejidad superficial de la historia.
Asimismo, está el asunto de la carga computacional. Ejecutar múltiples agentes simultáneamente y generar narrativas detalladas para cada uno no es trivial en términos de tiempo de cómputo y recursos. Aunque el estudio demostró que la ganancia en la tasa de éxito justifica con creces el costo adicional en sus experimentos, habrá que considerar la escalabilidad: ¿qué sucede si en vez de 10 intentos necesitamos 100 para tareas extremadamente complejas? ¿Hay un punto de rendimientos decrecientes donde el coste computacional supera al beneficio en precisión? Investigar formas de determinar un número óptimo de intentos N según la tarea, o de interrumpir ejecuciones que claramente van mal para ahorrar recursos, será importante para hacer viable este enfoque en la práctica.
Finalmente, aunque bBoN mostró funcionar bien en Linux, Windows y Android en contextos controlados, el mundo real presenta variaciones constantes. Las interfaces de software cambian con actualizaciones, aparecen ventanas emergentes inesperadas, las conexiones de internet pueden fallar, etc. Un agente robusto deberá generalizar no solo entre sistemas operativos, sino adaptarse a pequeños cambios en las condiciones de trabajo. Las narrativas y el juez podrían necesitar complementarse con mecanismos más dinámicos de verificación, como monitores del estado del sistema o comprobaciones adicionales para garantizar que el supuesto éxito narrado corresponda efectivamente a un resultado correcto en el mundo real. En suma, hay un camino por recorrer para pulir los bordes de esta técnica y garantizar que un agente escalado actúe de forma confiable en cualquier circunstancia.
Relevancia científica, tecnológica y social
El trabajo “La eficacia irrazonable de escalar agentes para el uso de la computadora” demuestra de manera contundente que a veces, en la inteligencia artificial, más es diferente. Al igual que en otros hitos de la IA donde escalar el tamaño de los modelos o la cantidad de datos produjo saltos cualitativos inesperados, aquí escalar el número de intentos de un agente (acompañado de un método riguroso para evaluarlos) resultó en un salto de rendimiento sorprendente. Científicamente, esto subraya la idea de que la exploración amplia combinada con una evaluación inteligente puede vencer obstáculos que antes parecían intratables. El enfoque bBoN ofrece un marco práctico para entender las trayectorias de un agente y seleccionar buenas soluciones, lo que podría inspirar futuros trabajos no solo en agentes de computadora sino en otros dominios de la robótica y la IA donde haya que lidiar con secuencias largas de decisiones.
Desde el punto de vista tecnológico, los avances logrados acercan la posibilidad de contar con asistentes digitales verdaderamente competentes en entornos informáticos cotidianos. Un sistema capaz de usar una PC o un teléfono con casi la pericia de un humano tendría innumerables aplicaciones: automatización de tareas empresariales repetitivas, ayuda a usuarios novatos para configurar o resolver problemas en sus dispositivos, ejecución de pruebas de software de forma autónoma, y en general ser un copiloto para nuestras interacciones digitales diarias. La mejora en robustez que aporta bBoN podría ser la clave que faltaba para pasar de demos impresionantes pero frágiles a herramientas confiables integradas en plataformas de uso diario (imaginemos futuros asistentes tipo Copilot mucho más potentes y seguros) o servicios en línea que se encarguen de tareas complejas a petición del usuario.
En cuanto al impacto social, la perspectiva de delegar actividades en agentes de IA capaces de usar ordenadores abre oportunidades importantes. Por un lado, democratiza el acceso a la tecnología: personas sin conocimientos técnicos profundos podrían lograr resultados avanzados simplemente pidiéndolos en lenguaje natural a un agente (ya sea formatear un documento, analizar datos o configurar una aplicación). También promete ahorrar tiempo y esfuerzo en labores tediosas, permitiendo que los humanos nos concentremos en tareas de mayor nivel creativo o estratégico.
Por otro lado, como con toda automatización, surgen interrogantes sobre el futuro del trabajo en ciertos ámbitos administrativos o de soporte técnico. Si un agente puede realizar el trabajo de varias personas de forma más rápida y sin errores, será crucial reflexionar sobre cómo se integra esta tecnología de manera complementaria a la labor humana, evitando desplazamientos abruptos y asegurando una transición beneficiosa para la sociedad.
En síntesis, la investigación sobre escalar agentes de uso de computadora nos enseña que la fiabilidad en sistemas de IA complejos puede alcanzarse combinando la ingeniería de la escala con la interpretación inteligente del comportamiento. Es un paso significativo hacia asistentes digitales generales que realmente funcionen en el mundo real. Aún quedan retos por superar, pero el camino está trazado: multiplicar las oportunidades de éxito y saber elegir con criterio. Lo que hoy son experimentos de laboratorio, mañana podrían ser los aliados infatigables de cada usuario en su interacción diaria con la tecnología.
Fuentes:
-
Gonzalez-Pumariega, G., Tu, V., Lee, C.-L., Yang, J., Li, A., & Wang, X. E. (2025). The Unreasonable Effectiveness of Scaling Agents for Computer Use. Preprint arXiv:2510.02250.
-
Mumba, E. (2025). Los 10 mejores agentes de uso de computadoras a seguir en 2025. Blog de Apidog, 20 de junio de 2025.

