
Hace apenas unos años, interactuar con una inteligencia artificial era un ejercicio de simplicidad. Podíamos pedirle que definiera la «fusión nuclear» y, con suerte, nos devolvería un párrafo conciso extraído de una enciclopedia digital. Era una herramienta útil, una especie de oráculo de bolsillo con el conocimiento del mundo congelado en el momento de su entrenamiento. Hoy, esa misma petición ha evolucionado hasta convertirse en algo que roza la ciencia ficción. La nueva consigna no es definir, sino analizar: «Redacta un informe exhaustivo sobre los avances, desafíos y viabilidad económica de la fusión nuclear comercial para 2050, incluyendo un análisis comparativo de los proyectos ITER y DEMO, y fundamenta tus conclusiones con fuentes académicas y gubernamentales». Este salto cuántico en la ambición de nuestras preguntas refleja una transformación silenciosa pero profunda en la naturaleza misma de la inteligencia artificial.
Estamos presenciando el ocaso de una era y el amanecer de otra. El paradigma de los Modelos Lingüísticos Grandes (LLM), como los conocíamos, está siendo reemplazado. Aquellos sistemas, a pesar de su asombrosa elocuencia, eran esencialmente entidades estáticas, prisioneras de los datos con los que fueron entrenadas. Su conocimiento era una fotografía, no una película en movimiento. Ahora, emerge una nueva arquitectura: la de los sistemas de agentes interconectados. Estos no son meros procesadores de información; son actores digitales. Un «agente» de inteligencia artificial es una entidad que puede percibir su entorno digital, planificar una secuencia de acciones, utilizar herramientas externas como un navegador web para buscar información en tiempo real, e integrar esos hallazgos para cumplir un objetivo complejo. Este cambio representa una evolución fundamental desde la mera «encapsulación del conocimiento» hacia una forma de «inteligencia cognitivamente extendida», donde la máquina no solo sabe, sino que aprende y actúa sobre el mundo digital.
En la vanguardia de esta revolución se encuentran los Agentes de Investigación Profunda, o DRA por sus siglas en inglés (Deep Research Agents). Estos sistemas son la materialización más sofisticada de la nueva era. Su funcionamiento se asemeja más al de un analista de investigación humano que al de un chatbot tradicional. Ante una tarea compleja, un DRA exhibe un conjunto de capacidades extraordinarias. Primero, realiza una descomposición de la tarea, dividiendo una pregunta abrumadora en una serie de sub-preguntas más manejables y lógicas. A continuación, emprende una recuperación de fuentes cruzadas, consultando y extrayendo información de una multitud de sitios web, artículos científicos y bases de datos. Luego, aplica un razonamiento en múltiples etapas, un proceso cognitivo en el que conecta los puntos, evalúa la información recopilada y construye un argumento coherente. Finalmente, produce una salida estructurada, que no es una simple respuesta de texto, sino un producto complejo y bien organizado, como un informe, un ensayo o un análisis de mercado.
Sin embargo, esta explosión de capacidades ha creado una crisis silenciosa, un desfase peligroso entre lo que estas inteligencias artificiales pueden hacer y nuestra capacidad para medirlo de forma fiable. A medida que sus habilidades se han disparado, nuestros métodos de evaluación han quedado anclados en el pasado. Es como si intentáramos medir la potencia de un motor de Fórmula 1 con las herramientas de un taller de bicicletas. Esta brecha, este abismo entre la capacidad real y nuestra habilidad para verificarla con rigor, es el nudo dramático que un reciente y trascendental artículo científico, titulado «A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports», se propone desatar. El trabajo, liderado por un equipo de investigadores de instituciones de primer nivel, no solo diagnostica el problema, sino que ofrece una solución: una nueva vara de medir, un examen tan exigente y matizado como las propias inteligencias que pretende evaluar.
La crisis de la medición en la era de los agentes autónomos
Durante años, el progreso en el campo de la inteligencia artificial se ha medido a través de una batería de pruebas estandarizadas, conocidas en la jerga técnica como benchmarks. Estos exámenes, como los populares tests de respuesta múltiple o las tareas que requieren una respuesta corta y factual, han sido los pilares sobre los que se ha construido la evaluación de los LLM. Su diseño priorizaba la eficiencia y la automatización; era fácil y rápido para una máquina calificar si una respuesta era correcta o incorrecta cuando solo había unas pocas opciones válidas. Sin embargo, lo que fue una ventaja en la era de las respuestas simples se ha convertido en un grillete en la era de los informes complejos. Estos métodos antiguos son fundamentalmente incapaces de evaluar la comprensión profunda, el razonamiento crítico o la capacidad de síntesis que demuestran los nuevos agentes.
El fracaso de las viejas métricas para evaluar un informe de investigación de varias páginas generado por un DRA es total y se manifiesta en varias dimensiones críticas. En primer lugar, se basan en métricas superficiales. Herramientas de evaluación automática como ROUGE o BLEU, que durante mucho tiempo fueron el estándar de oro, operan bajo una lógica simple: comparan las palabras y frases del texto generado por la IA con un texto de referencia. Su funcionamiento es análogo al de un corrector perezoso que solo verifica si las palabras de un ensayo coinciden con las del libro de texto, sin prestar atención a si el estudiante ha comprendido la materia, si su argumento es lógico o si sus ideas son originales. Estas métricas no pueden distinguir entre un argumento bien razonado y un plagio sofisticado; confunden la coincidencia léxica con la coherencia semántica.
En segundo lugar, estos benchmarks tradicionales pecan de realizar una evaluación de habilidades aisladas. Miden la capacidad de un modelo para realizar una búsqueda web o para resolver un problema de lógica de forma independiente, pero no evalúan su capacidad para integrar estas habilidades en un flujo de trabajo coherente. Es como si un jurado culinario evaluara la destreza de un chef para cortar verduras y su pericia para usar un horno por separado, pero nunca le pidiera que cocinara un plato completo. El verdadero genio de un DRA no reside en sus habilidades individuales, sino en su capacidad para orquestarlas sinérgicamente: planificar la investigación, buscar información relevante, razonar sobre ella y, finalmente, sintetizarla en un producto final coherente. Las viejas pruebas nunca ven el plato terminado.
Pero el fallo más grave, el verdadero punto ciego de los métodos antiguos, es su incapacidad para evaluar la credibilidad de las fuentes. En un mundo digital saturado de información y desinformación, la capacidad de discernir entre una fuente autorizada y una dudosa es quizás la habilidad más importante. Los benchmarks tradicionales no tienen ningún mecanismo para valorar la calidad, la autoridad o la veracidad de las fuentes que una IA utiliza para construir su respuesta. No pueden diferenciar si la información que sustenta un argumento proviene de una publicación científica revisada por pares, un informe gubernamental o un oscuro foro de teorías conspirativas. Para estas métricas, toda la información es igual, una omisión que en el mundo real tiene consecuencias potencialmente catastróficas.
Esta crisis de medición no es un mero problema académico. Sin una herramienta de evaluación adecuada, el desarrollo y despliegue de estos potentes agentes en campos críticos como la medicina, las finanzas, el derecho o el análisis de políticas se convierte en un ejercicio de fe ciega. Es una necesidad imperiosa contar con un nuevo estándar, un listón que no solo mida la elocuencia de la máquina, sino también su rigor, su fiabilidad y su honestidad intelectual. Sin él, navegamos a ciegas en la era más transformadora de la tecnología.
Rigorous Bench, el listón que definirá a la próxima generación de IA
Frente a esta crisis de evaluación, el equipo de investigación presenta su solución: Rigorous Bench. Este no es simplemente un conjunto de datos más grande o más complejo; es una obra de artesanía intelectual, un desafío diseñado con la precisión y el cuidado de un maestro relojero. A diferencia de muchos otros benchmarks a gran escala, que a menudo se generan de forma automática y pueden contener ruido e inconsistencias, Rigorous Bench es el producto de una meticulosa curación manual por parte de expertos humanos. Cada elemento ha sido sometido a un riguroso proceso de validación en múltiples etapas, que integra el diseño humano con la auditoría por parte de otras IAs y la revisión cruzada por pares. Este enfoque garantiza un nivel de calidad, dificultad y validez semántica que lo distingue fundamentalmente de sus predecesores.
La naturaleza del desafío es tan diversa como exigente. El benchmark consta de 214 consultas de alta complejidad, distribuidas estratégicamente en diez dominios temáticos que abarcan desde la academia y las finanzas hasta la historia, la tecnología y la medicina. La amplitud de las preguntas está diseñada para poner a prueba los límites de los agentes actuales. Para ilustrar su alcance, basta con observar dos ejemplos extraídos del propio corpus. Una consulta, eminentemente práctica, pide un informe detallado sobre los preparativos necesarios para adoptar un gato callejero, incluyendo los cuidados durante los primeros siete días y los protocolos veterinarios. Otra, de un cariz altamente técnico, solicita un resumen de la historia de la estandarización del protocolo de transporte de internet QUIC, incluyendo un análisis comparativo de sus diferentes borradores y las versiones finales del RFC (Request for Comments). Esta dualidad demuestra que el examen no solo mide el conocimiento enciclopédico, sino también la capacidad de ofrecer orientación práctica y análisis técnico profundo.
La verdadera innovación de Rigorous Bench, su fórmula secreta, reside en lo que los autores denominan el «paquete de referencia» (reference bundle) que acompaña a cada consulta. Este paquete es un conjunto de herramientas de evaluación multifacéticas, diseñado para medir el rendimiento desde todos los ángulos posibles. Sus componentes son:
- Rúbricas específicas y generales (QSRs y GRRs): Actúan como las plantillas de calificación de un examinador humano. Las Rúbricas Específicas de la Consulta (QSRs) son una lista de puntos obligatorios y factuales que una respuesta competente debe abordar. Por ejemplo, para la consulta sobre el protocolo QUIC, una QSR podría ser: «¿El informe menciona correctamente que el borrador 17 introdujo espacios de numeración de paquetes independientes?». Por otro lado, las Rúbricas Generales del Informe (GRRs) evalúan la calidad estructural y estilística del texto, con criterios como: «¿El informe tiene una introducción, un cuerpo y una conclusión claramente definidos?» o «¿El lenguaje utilizado es preciso y formal?».
- Enlaces a fuentes fiables (TSLs): Este componente aborda directamente el problema de la credibilidad. Para cada consulta, los expertos han compilado una lista de Enlaces a Fuentes Fiables (TSLs), una especie de bibliografía recomendada de sitios web autorizados, publicaciones oficiales y artículos académicos que contienen la información necesaria para responder correctamente. Esto permite evaluar si el agente es capaz no solo de encontrar información, sino de encontrarla en los lugares adecuados.
- Palabras clave de anclaje y de desviación (FAKs y FDKs): Funcionan como detectores de enfoque temático. Las Palabras Clave de Anclaje (FAKs) son los conceptos centrales que un buen informe debe discutir en profundidad. Las Palabras Clave de Desviación (FDKs) son «distracciones» temáticas, términos relacionados pero irrelevantes que una IA eficiente y centrada debería evitar para no malgastar recursos ni desenfocar la respuesta.
Este diseño meticuloso revela una ambición que va más allá de la simple medición. Rigorous Bench no es solo una herramienta para calificar a las IAs; es un instrumento práctico para el «alineamiento de la IA». El problema del alineamiento consiste en asegurar que los sistemas de inteligencia artificial persigan objetivos y se comporten de acuerdo con los valores humanos. Los benchmarks son el principal mecanismo a través del cual la comunidad científica define y recompensa lo que considera un «buen» comportamiento en una IA. Al codificar explícitamente valores como la precisión fáctica (a través de las QSRs), la calidad estructural (GRRs), la credibilidad de las fuentes (TSLs) y el enfoque temático (FAKs y FDKs), Rigorous Bench traduce los principios abstractos de la investigación humana rigurosa en un objetivo de optimización concreto y medible para los ingenieros de IA. De este modo, el benchmark no solo evalúa el estado actual de la tecnología, sino que activamente guía su desarrollo futuro hacia estándares más elevados de rigor, veracidad y calidad. Esto sugiere que una de las vías más efectivas para lograr una IA más segura y beneficiosa no reside únicamente en los debates filosóficos, sino en la ingeniería de mejores herramientas de evaluación que incentiven y recompensen los comportamientos que deseamos ver en nuestras creaciones más avanzadas.
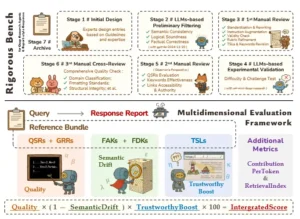
Canalización para la construcción de puntos de referencia y visión general del marco de evaluación.
Anatomía de una evaluación, un sistema de puntuación para el siglo XXI
Crear un desafío tan sofisticado como Rigorous Bench es solo la mitad de la batalla. La otra mitad es diseñar un sistema de puntuación que pueda capturar todos sus matices. El marco de evaluación propuesto en el estudio es tan innovador como el propio benchmark, y se fundamenta en tres pilares que, en conjunto, ofrecen una visión holística del rendimiento de un agente.
El primer pilar es la Calidad semántica. Esta métrica responde a la pregunta fundamental: ¿cuán bueno es el informe en sí mismo? Para calcularla, el sistema combina las puntuaciones obtenidas en las rúbricas específicas (QSRs), que miden la finalización de la tarea y la corrección de los datos, con las puntuaciones de las rúbricas generales (GRRs), que valoran la calidad de la escritura, la estructura y la claridad. Es una medida compuesta que evalúa tanto el fondo como la forma.
El segundo pilar es el Enfoque temático. Su objetivo es responder a la pregunta: ¿se mantuvo la IA centrada en el tema solicitado? Para ello, se introduce una métrica ingeniosa llamada `Deriva Semántica` (`SemanticDrift`). Este indicador penaliza al agente por dos tipos de errores. Por un lado, mide la omisión de conceptos clave (las FAKs), asegurando que el informe cubra todos los aspectos importantes. Por otro, detecta la inclusión de temas irrelevantes (las FDKs), penalizando al agente por desviarse y generar «ruido» informativo. Una baja deriva semántica indica que el agente ha comprendido la intención de la pregunta y ha mantenido el foco de manera eficiente.
El tercer y último pilar es la Fiabilidad de la búsqueda. Este componente se pregunta: ¿podemos confiar en las fuentes que ha utilizado la IA? Aquí entra en juego el factor de `Impulso de Fiabilidad` (`TrustworthyBoost`). Este mecanismo premia al agente por citar las fuentes de alta calidad que los expertos preseleccionaron (las TSLs). Cuantas más fuentes fiables y recomendadas cite el agente en su informe, mayor será este impulso, lo que refleja una mayor confianza en la veracidad de la información presentada.
La verdadera genialidad del sistema reside en cómo combina estos tres pilares para generar una única puntuación final. En lugar de simplemente sumarlos, el marco utiliza un modelo multiplicativo. La fórmula de la `Puntuación Integrada` (`IntegratedScore`) se define de la siguiente manera: $$IntegratedScore = Quality \times (1 – SemanticDrift) \times TrustworthyBoost \times 100$$ Esta elección matemática no es trivial; es una profunda declaración de principios sobre lo que constituye la verdadera competencia. Un sistema aditivo, donde las puntuaciones se suman, implicaría que las habilidades son intercambiables. Por ejemplo, una IA podría generar un texto de una calidad literaria excepcional pero inventar todas sus fuentes, y aun así obtener una puntuación decente porque su alta calidad compensaría su nula fiabilidad. El modelo multiplicativo, en cambio, establece que las habilidades son interdependientes y que todas son absolutamente necesarias. Un fallo crítico en cualquiera de las tres dimensiones (calidad, enfoque o fiabilidad) tiene un efecto devastador en la puntuación final. Si la fiabilidad es cero, la puntuación total es cero, sin importar cuán elocuente sea el texto. Si la deriva semántica es máxima (valor de 1), el factor `(1 – SemanticDrift)` se convierte en cero, anulando también el resultado.
Este enfoque refleja a la perfección la expectativa humana sobre la competencia profesional. Un investigador que escribe de maravilla pero se sale del tema o cita fuentes falsas no es considerado un «buen investigador con un pequeño defecto»; es, sencillamente, un investigador incompetente. El marco de evaluación, por tanto, define la competencia de la IA no como la suma de habilidades aisladas, sino como el producto de su integración exitosa. Esta decisión de diseño tiene implicaciones de gran alcance: obligará a los desarrolladores a construir sistemas más equilibrados y robustos, en lugar de optimizar para métricas superficiales como la fluidez del lenguaje. Es un ataque directo y sistémico a la viabilidad de los modelos que son propensos a la «alucinación», el fenómeno por el cual una IA genera información plausible pero completamente falsa. Con este sistema, la elocuencia sin veracidad no vale nada.
El gran desafío, los titanes de la IA se enfrentan a la prueba
Con el campo de batalla preparado y las reglas del juego establecidas, llegó el momento de enfrentar a los contendientes. El estudio sometió a la prueba de Rigorous Bench a un total de trece modelos de inteligencia artificial, una selección que representa el estado del arte de la tecnología. Para facilitar la comprensión de los resultados, podemos agrupar a estos titanes en tres categorías. En primer lugar, los favoritos: cinco Agentes de Investigación Profunda (DRA) especializados, diseñados específicamente para este tipo de tareas complejas. En segundo lugar, el contendiente inesperado: un agente avanzado llamado Kimi-K2, conocido por su arquitectura de «Mezcla de Expertos» y su enorme capacidad de procesamiento de texto. Y, finalmente, los retadores: siete de los más potentes LLM de propósito general del mundo, equipados con herramientas de búsqueda web para la ocasión.
Los resultados, presentados en una tabla de clasificación, narran una historia fascinante sobre las fortalezas y debilidades de las diferentes arquitecturas de IA. El campeón indiscutible de la competición fue Qwen-deep-research, que se alzó con la primera posición gracias a un rendimiento extraordinariamente equilibrado y sólido en todas las métricas. No fue necesariamente el mejor en cada categoría individual, pero su capacidad para integrar todas las habilidades de forma coherente le otorgó la puntuación integrada más alta. Este resultado fue parte de una tendencia más amplia: la supremacía de los DRA. Los agentes especializados ocuparon las primeras posiciones de la tabla, demostrando de manera concluyente que, para estas tareas de investigación complejas, las arquitecturas de agente dedicadas superan a los LLM de propósito general a los que simplemente se les ha añadido una herramienta de búsqueda.
Sin embargo, la historia más reveladora se encuentra en los casos atípicos, en aquellos modelos cuyo rendimiento excepcional en un área contrastaba con sus debilidades en otras. El caso de Kimi-K2 es paradigmático. Este agente produjo los informes de mayor calidad semántica de toda la competición; sus textos eran los más elocuentes, mejor estructurados y más completos en contenido. Fue el genio literario del grupo. No obstante, su baja puntuación en enfoque temático y, sobre todo, en fiabilidad de las fuentes, lo relegó a un sorprendente cuarto puesto. Era un escritor brillante pero distraído y poco fiable. En el extremo opuesto se situó GPT-5. Este modelo demostró ser un bibliotecario maestro, obteniendo la puntuación más alta en el `Impulso de Fiabilidad`, lo que indica que fue el mejor de todos a la hora de encontrar y citar las fuentes creíbles recomendadas por los expertos. Sin embargo, su capacidad para sintetizar esa información de alta calidad en un informe de primer nivel no estuvo a la altura de los líderes, y su calidad semántica general fue solo modesta.
El rendimiento contrastante de modelos como Kimi-K2 y GPT-5 no es una anécdota, sino la ilustración de una división fundamental en el estado actual de la arquitectura de la IA. Existe una tensión palpable entre los «Maestros Sintetizadores», modelos optimizados para la generación de lenguaje fluido y coherente, y los «Maestros Buscadores», aquellos excelentes en la recuperación y filtrado de información precisa. El rendimiento de Kimi-K2 sugiere una arquitectura de «Mezcla de Expertos» afinada para la síntesis del lenguaje, pero con un componente de agente (el encargado de planificar, buscar y filtrar) todavía inmaduro. Por el contrario, el éxito de GPT-5 en la fiabilidad apunta a un mecanismo de búsqueda y verificación de fuentes de primera clase, pero una capacidad de síntesis que aún no alcanza el mismo nivel de excelencia. La victoria de los DRA más equilibrados, como Qwen y Sonar, sugiere una conclusión crucial: el futuro de la IA de investigación no reside en la excelencia aislada de una de estas capacidades, sino en la integración perfecta y armoniosa de ambas. El próximo gran avance tecnológico podría no provenir simplemente de hacer los LLM más grandes o más elocuentes, sino de innovaciones en las arquitecturas de agente que orquestan cómo el modelo planifica, utiliza sus herramientas y razona sobre la información. El «cerebro» (el LLM) ya es inmensamente potente; la clave ahora está en desarrollar el «sistema nervioso» (el marco del agente) que le permita actuar en el mundo digital de forma eficaz, rigurosa y fiable.
| Modelo | Calidad Semántica | Enfoque (1 – Deriva Semántica) | Fiabilidad (Impulso de Fiabilidad) | Puntuación Integrada |
|---|---|---|---|---|
| Qwen-deep-research | 0.6348 | 0.5248 | 1.0288 | 34.65 |
| Sonar-deep-research | 0.6184 | 0.5271 | 1.0238 | 33.47 |
| o3-deep-research | 0.6176 | 0.5184 | 1.0171 | 32.90 |
| Kimi-K2-preview | 0.6707 | 0.4671 | 1.0153 | 32.07 |
| Grok-4-search | 0.6130 | 0.4890 | 1.0283 | 31.35 |
| GPT-5 | 0.5560 | 0.4593 | 1.0383 | 27.33 |
Más allá de la puntuación, los dilemas ocultos en el diseño de agentes
Los números de la tabla de clasificación cuentan una historia de ganadores y perdedores, pero el análisis más profundo del estudio revela una narrativa más compleja, una que expone los dilemas fundamentales y los desafíos de ingeniería que acechan en el corazón del diseño de los agentes de IA. El benchmark no solo mide el rendimiento, sino que también actúa como una herramienta de diagnóstico que saca a la luz las tensiones inherentes a estas arquitecturas cognitivas.
El primero de estos es el dilema entre eficiencia y calidad, o lo que podríamos llamar «el precio de la inteligencia». Los datos sobre el consumo de recursos computacionales (medido en tokens, las unidades de texto que procesa la IA) y el número de pasos de razonamiento que cada agente realiza son reveladores. Los DRA más exhaustivos y, en algunos aspectos, más potentes, como o3-deep-research, son también extraordinariamente costosos. Para generar un solo informe, estos sistemas pueden llegar a consumir decenas de miles de tokens y ejecutar un número vertiginoso de ciclos de búsqueda y razonamiento. Esta ineficiencia representa una barrera formidable para su uso práctico y generalizado. La inteligencia profunda, por ahora, tiene un coste prohibitivo.
El segundo desafío es el dilema de la coherencia en la descomposición. La estrategia de un DRA de dividir una consulta compleja en múltiples sub-tareas es una de sus mayores fortalezas, pero también encierra un riesgo significativo: la fragmentación. Si el agente descompone la pregunta en demasiadas partes o lo hace de forma poco lógica, puede perder de vista la intención original de la consulta. El resultado es un informe que, aunque pueda responder correctamente a cada una de las sub-preguntas de forma aislada, resulta inconexo y carece de una tesis central coherente. El estudio documenta casos en los que los agentes generaron sub-consultas en idiomas incorrectos o con una semántica incoherente, ilustrando cómo el proceso de descomposición puede desviarse y sabotear el objetivo final.
Estos dilemas no deben ser vistos como simples errores o fallos de programación que se pueden corregir fácilmente. Son la evidencia de que los DRA actuales, a pesar de su sofisticación, todavía operan en gran medida mediante un enfoque de «fuerza bruta». Compensan una comprensión más profunda y matizada del objetivo con un mayor volumen de búsquedas y ciclos de razonamiento. Es una estrategia que, aunque a veces funciona, no es ni sostenible ni escalable. Los datos del estudio, que muestran una alta varianza en el comportamiento de algunos modelos y un consumo de recursos desorbitado, apuntan a lo que los autores describen como «rutas de recuperación no convergentes». Esto implica una falta de control interno, una ausencia de lo que en humanos llamaríamos «metacognición»: la capacidad del agente para saber cuándo una estrategia de búsqueda no está siendo fructífera y debe ser abandonada o modificada. El agente sigue buscando y razonando de forma casi compulsiva, malgastando recursos sin acercarse a una mejor solución.
Por lo tanto, Rigorous Bench revela que el gran desafío para la próxima generación de agentes no es solo hacerlos más potentes, sino hacerlos más inteligentes en la gestión de sus propios procesos cognitivos. La futura frontera de la investigación no está solo en la escala, sino en el desarrollo de arquitecturas cognitivas más sofisticadas que incorporen la autorregulación, la planificación adaptativa y una comprensión holística y persistente del objetivo principal. Necesitamos agentes que no solo piensen, sino que piensen sobre cómo piensan. Rigorous Bench proporciona, por primera vez, la herramienta de diagnóstico precisa y fiable que necesitamos para medir el progreso en estos desafíos arquitectónicos más profundos y sutiles.
Rumbo hacia una inteligencia artificial más rigurosa, estable e interpretable
El viaje desde las respuestas de una sola frase hasta los informes de investigación de varias páginas no es solo un avance tecnológico; es un reflejo de la creciente ambición que depositamos en la inteligencia artificial. Ya no le pedimos que sea una simple enciclopedia, sino un colega, un analista, un asistente de investigación. El estudio y la creación de Rigorous Bench marcan un hito en este viaje, no porque anuncien la llegada de una IA perfecta, sino porque nos proporcionan, por primera vez, una hoja de ruta clara y fiable para construirla. Este trabajo es más que una nueva prueba; es una pieza de infraestructura científica fundamental que guiará el desarrollo de una IA mejor, más segura y más alineada con los valores humanos.
Las implicaciones de este avance se extienden mucho más allá de los laboratorios de investigación. En el plano social y tecnológico, la existencia de benchmarks más rigurosos es un prerrequisito para la confianza. Una inteligencia artificial que pueda superar consistentemente una prueba como Rigorous Bench es una que podríamos empezar a considerar seriamente para tareas de alta responsabilidad: resumir las últimas investigaciones médicas para un doctor, realizar análisis de jurisprudencia para un abogado o auditar informes financieros complejos para un regulador. La confianza no puede basarse en demostraciones llamativas, sino en una evaluación sistemática y rigurosa, y este trabajo sienta las bases para ello.
Además, el marco de evaluación desglosado en calidad, enfoque y fiabilidad fomenta una mayor interpretabilidad. Uno de los mayores desafíos de la IA moderna es su naturaleza de «caja negra»; a menudo sabemos que funciona, pero no entendemos completamente por qué. Al desglosar el rendimiento en componentes específicos, este sistema nos permite diagnosticar con precisión por qué un agente ha fallado. ¿Fue porque el texto era de mala calidad, porque se desvió del tema o porque utilizó fuentes poco fiables? Ser capaces de responder a esta pregunta es un paso crucial para hacer que el comportamiento de la IA sea menos opaco y más predecible.
En última instancia, el camino que traza este estudio es uno que busca anclar la creciente potencia de la inteligencia artificial en los valores atemporales de la investigación humana: el rigor, la claridad, la honestidad intelectual y la búsqueda de la verdad. A medida que la ambición de lo que pedimos a estas máquinas siga creciendo, herramientas como Rigorous Bench serán nuestro ancla, asegurando que su desarrollo no solo sea rápido, sino también responsable. La prueba definitiva no es solo para las máquinas; es un recordatorio para nosotros, sus creadores, de los estándares que nunca debemos estar dispuestos a comprometer.
Fuentes
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L.,… & Altman, S. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
Bosse, N. I., Evans, J., Gambee, R. G., Hnyk, D., Mühlbacher, P., Phillips, L.,… & Wildman, J. (2025). Deep research bench: Evaluating AI web research agents. arXiv preprint arXiv:2506.06287.
Chen, K., Ren, Y., Liu, Y., Hu, X., Tian, H., Xie, T.,… & Gong, Y. (2025a). xbench: Tracking agents productivity scaling with profession-aligned real-world evaluations. arXiv preprint arXiv:2506.13651.
Chen, Z., Ma, X., Zhuang, S., Nie, P., Zou, K., Liu, A.,… & Su, M. (2025b). Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent. arXiv preprint arXiv:2508.06600.
Cohen, D., Burg, L., Pykhnivskyi, S., Gur, H., Kovynov, S., Atzmon, O., & Barkan, G. (2025). Wixqa: A multi-dataset benchmark for enterprise retrieval-augmented generation. arXiv preprint arXiv:2505.08643.
Du, M., Xu, B., Zhu, C., Wang, X., & Mao, Z. (2025). Deepresearch bench: A comprehensive benchmark for deep research agents. arXiv preprint arXiv:2506.11763.
Ho, X., Nguyen, A. K. D., Sugawara, S., & Aizawa, A. (2020). Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060.
Huang, Y., Chen, Y., Zhang, H., Li, K., Fang, M., Yang, L.,… & Hao, J. (2025). Deep research agents: A systematic examination and roadmap. arXiv preprint arXiv:2506.18096.
Li, M., Zeng, Y., Cheng, Z., Ma, C., & Jia, K. (2025). Reportbench: Evaluating deep research agents via academic survey tasks. arXiv preprint arXiv:2508.15804.
Pham, T., Nguyen, N., Zunjare, P., Chen, W., Tseng, Y. M., & Vu, T. (2025). Sealqa: Raising the bar for reasoning in search-augmented language models. arXiv preprint arXiv:2506.01062.
Wan, H., Yang, C., Yu, J., Tu, M., Lu, J., Yu, D.,… & Wang, A. (2025). Deepresearch arena: The first exam of llms’ research abilities via seminar-grounded tasks. arXiv preprint arXiv:2509.01396.
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J.,… & Lin, Y. (2024). A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6), 186345.
Wei, J., Nguyen, K., Chung, H. W., Jiao, Y. J., Papay, S., Glaese, A.,… & Fedus, W. (2024). Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368.
Wei, J., Sun, Z., Papay, S., McKinney, S., Han, J., Fulford, I.,… & Glaese, A. (2025). Browsecomp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516.
Wong, R., Wang, J., Zhao, J., Chen, L., Gao, Y., Zhang, L.,… & Zhang, G. (2025). Widesearch: Benchmarking agentic broad info-seeking. arXiv preprint arXiv:2508.07999.
Wu, J., Yin, W., Jiang, Y., Wang, Z., Xi, Z., Fang, R.,… & Xie, P. (2025). Webwalker: Benchmarking llms in web traversal. arXiv preprint arXiv:2501.07572.
Xu, R., & Peng, J. (2025). A comprehensive survey of deep research: Systems, methodologies, and applications. arXiv preprint arXiv:2506.12594.
Yang, Y., Wang, Y. (2018). A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports. arXiv:2510.02190.
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., & Manning, C. D. (2018). Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600.
Yifei, L. S., Chang, A., Malaviya, C., & Yatskar, M. (2025). Researchqa: Evaluating scholarly question answering at scale across 75 fields with survey-mined questions and rubrics. arXiv preprint arXiv:2509.00496.
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2019). Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675.
Zhang, W., Li, Y., Bei, Y., Luo, J., Wan, G., Yang, L.,… & Miao, C. (2025a). From web search towards agentic deep research: Incentivizing search with reasoning agents. arXiv preprint arXiv:2506.18959.
Zhang, W., Li, X., Zhang, Y., Jia, P., Wang, Y., Guo, H.,… & Zhao, X. (2025b). Deep research: A survey of autonomous research agents. arXiv preprint arXiv:2508.12752.
Zhou, J., Li, W., Liao, Y., Zhang, N., Miaoand, T., & Qi, Z. (2025). Academicbrowse: Benchmarking academic browse ability of llms. arXiv preprint arXiv:2506.13784.

