
Estamos en el umbral de una nueva era para la inteligencia artificial, una donde la conversación evoluciona hacia la acción. Hemos dejado atrás la etapa de los chatbots pasivos para imaginar un ecosistema digital habitado por agentes autónomos: entidades de software capaces no solo de dialogar, sino de ejecutar tareas complejas de principio a fin. Pensemos en un asistente que, ante la petición de «analizar las ventas del trimestre, generar una presentación y compartirla con la dirección», opera de forma autónota a través de distintas aplicaciones para cumplir el objetivo. Considerados la próxima frontera de los grandes modelos de lenguaje (LLM), estos agentes se presentan como la tecnología que automatizará las rutinas tediosas y optimizará los procesos más intrincados, alterando para siempre nuestra relación con el universo digital.
Sin embargo, entre la deslumbrante promesa y la realidad funcional se extiende un abismo de incertidumbre. ¿Cómo podemos estar seguros de que estos agentes son verdaderamente competentes? ¿Cómo medimos su fiabilidad antes de confiarles tareas críticas en nuestros sistemas de trabajo, bases de datos o infraestructuras de software? Si un asistente humano comete un error, las consecuencias pueden ser problemáticas; si un agente de inteligencia artificial que opera a la velocidad de la luz interpreta mal una instrucción, podría borrar una base de datos entera en un parpadeo. La necesidad de una evaluación rigurosa y realista no es solo una cuestión académica, es un imperativo para la seguridad y la confianza en la tecnología del mañana.
Para abordar este desafío fundamental, un equipo internacional de investigadores ha desarrollado una nueva y formidable prueba de aptitud para estos agentes emergentes. Su trabajo, titulado «MCPMark: Un benchmark para poner a prueba el uso realista y exhaustivo de MCP», presenta un campo de entrenamiento y evaluación tan exigente que incluso las inteligencias artificiales más avanzadas del planeta, incluida la esperada serie GPT-5, tropiezan y fallan con una frecuencia alarmante. Este estudio no es solo un informe técnico; es una llamada de atención, un examen de realidad que modera el entusiasmo desbordante con datos empíricos contundentes, revelando las profundas grietas que aún existen en los cimientos de la era de los agentes autónomos.
Para comprender la magnitud de este trabajo, es preciso familiarizarse con algunos conceptos clave. El primero es el Protocolo de Contexto de Modelo, o MCP por sus siglas en inglés. Pensemos en el MCP como una especie de lenguaje universal para la inteligencia artificial, un esperanto digital que le permite comunicarse y interactuar de manera estandarizada con una multitud de sistemas externos. Antes del MCP, conectar un modelo de lenguaje con una aplicación como Notion, una plataforma de desarrollo como GitHub o una base de datos como PostgreSQL requería soluciones a medida, complejas y frágiles. El MCP actúa como un traductor y un conjunto de herramientas universales, proporcionando a la IA los «ojos y manos» digitales necesarios para operar en entornos reales. Es la columna vertebral que permite a un agente no solo procesar texto, sino también manipular archivos, gestionar proyectos, automatizar navegadores web y ejecutar consultas en bases de datos.
Con esta infraestructura en su lugar, los agentes de IA pueden realizar tareas que implican una secuencia de operaciones fundamentales conocidas en el mundo del software como CRUD: crear (Create), leer (Read), actualizar (Update) y eliminar (Delete). Mientras que las interacciones con los primeros chatbots eran casi exclusivamente de lectura, los agentes verdaderos deben dominar todo el espectro. Deben ser capaces de crear un nuevo documento, leer su contenido, actualizar una entrada en una base de datos y eliminar un archivo obsoleto. La complejidad no reside en ejecutar una de estas acciones de forma aislada, sino en planificar y ejecutar secuencias largas y lógicas de ellas para lograr un objetivo final.
Aquí es donde entra en juego el concepto de «benchmark», que no es más que un marco de evaluación estandarizado, un examen diseñado para medir el rendimiento de diferentes sistemas bajo las mismas condiciones. Durante años, los benchmarks para la IA se han centrado en la comprensión del lenguaje, la traducción o la generación de código. Sin embargo, los benchmarks existentes para agentes basados en MCP han demostrado ser insuficientes. Los investigadores de MCPMark argumentan que estas pruebas previas eran como exámenes a libro abierto sobre temas sencillos. A menudo se centraban en tareas de «lectura intensiva», donde el agente solo necesitaba encontrar y reportar información, o implicaban una «profundidad de interacción limitada», requiriendo apenas uno o dos pasos para completarse. Fallaban en capturar la esencia del trabajo real: flujos de trabajo complejos, de múltiples pasos y que exigen una delicada danza entre la lectura, la creación y la modificación de datos.
MCPMark fue concebido para llenar este vacío. No es un simple test de opción múltiple, sino una evaluación práctica e integral que simula escenarios de usuario realistas y exigentes. Es el equivalente a pedirle a un aspirante a chef que no solo recite una receta, sino que prepare un banquete completo de varios platos en una cocina profesional. Los resultados de este examen, como veremos, son tan reveladores como preocupantes, y nos ofrecen una visión sin precedentes de las verdaderas capacidades y, lo que es más importante, de las actuales deficiencias de la inteligencia artificial más avanzada de nuestro tiempo.
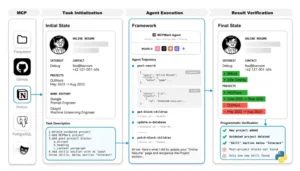
Canal de evaluación de MCPMark con seguimiento completo del estado. Cada tarea parte de un estado inicial seleccionado con una instrucción de tarea específica. El agente de MCPMark ejecuta un bucle de llamada a herramientas, seguido de un verificador programático que evalúa si se cumplen todas las comprobaciones necesarias.
El diseño de un examen para la inteligencia artificial del futuro
Crear un benchmark tan ambicioso como MCPMark no es una tarea trivial. No se trata simplemente de redactar una lista de problemas, sino de construir ecosistemas digitales completos, realistas y controlados donde los agentes de IA puedan ser evaluados de manera justa y reproducible. El equipo de investigación partió de una crítica fundamental a las evaluaciones anteriores: no reflejaban la complejidad y la naturaleza interactiva del uso de software en el mundo real. Para superar estas limitaciones, basaron su enfoque en tres pilares: diversidad de entornos, realismo en las tareas y un método de creación colaborativo único.
El primer pilar fue la selección de cinco entornos operativos representativos, cada uno habilitado con un servidor MCP para estandarizar la interacción. Estos no fueron elegidos al azar, sino que cubren un amplio abanico de las actividades digitales más comunes:
- Filesystem: Representa la tarea fundamental de gestionar archivos y carpetas en un ordenador. Es el equivalente a organizar un escritorio digital, buscar documentos, crear nuevos directorios y mover información. Las tareas en este entorno evalúan la capacidad del agente para navegar por estructuras de carpetas complejas y manipular archivos de manera lógica.
- GitHub: Es el corazón del desarrollo de software colaborativo. Para un agente, operar en GitHub significa gestionar ramas de código, crear solicitudes de integración (pull requests), revisar cambios y configurar flujos de trabajo de integración continua. Es una prueba de fuego para las capacidades de la IA en el dominio altamente estructurado de la ingeniería de software.
- Notion: Esta popular herramienta de productividad actúa como un cerebro digital para equipos e individuos, combinando documentos, bases de datos y wikis. Un agente que opera en Notion debe ser capaz de crear y editar páginas, consultar bases de datos anidadas y actualizar propiedades complejas, simulando tareas de gestión de proyectos o conocimiento.
- PostgreSQL: Un potente sistema de gestión de bases de datos relacionales, es el análogo a un inmenso y estructurado catálogo de biblioteca. Las tareas aquí requieren que el agente explore esquemas, ejecute consultas SQL para recuperar información y realice actualizaciones transaccionales, poniendo a prueba su razonamiento lógico y su comprensión de las estructuras de datos.
- Playwright: Esta herramienta permite la automatización de navegadores web. Para un agente, usar Playwright es como tener un robot que puede navegar por sitios web, rellenar formularios, hacer clic en botones y extraer información. Los desafíos incluyen tareas como completar un proceso de autenticación que requiere interacción humana simulada.
El segundo pilar fue el realismo. A diferencia de otros benchmarks que parten de un estado inicial vacío o genérico, cada una de las 127 tareas de MCPMark comienza desde un «estado inicial curado». Por ejemplo, en lugar de un repositorio de GitHub vacío, se utiliza uno con un historial de desarrollo realista. En lugar de una página de Notion en blanco, se parte de plantillas populares y complejas. Este detalle es crucial, ya que obliga al agente a comprender y navegar por un contexto preexistente, tal como lo haría un humano al incorporarse a un nuevo proyecto.
El tercer y más innovador pilar fue el proceso de creación de tareas. Reconociendo que ni los humanos ni las IA por sí solos podían diseñar tareas suficientemente complejas y verificables, los investigadores idearon un sistema de colaboración hombre-máquina. En este proceso, un experto humano en un dominio específico (como un ingeniero de software o un diseñador) trabajaba junto a dos agentes de IA: un «agente de creación de tareas» y un «agente de ejecución de tareas». El proceso se desarrollaba en varias etapas: exploración conjunta del entorno, propuesta y refinamiento de la tarea por parte de la IA bajo la supervisión del experto, y la creación de un script de verificación programática. Este script es fundamental, ya que permite una evaluación automática y objetiva, determinando sin ambigüedades si la tarea se ha completado con éxito. Este ciclo iterativo, que podía durar entre tres y cinco horas de trabajo experto por cada tarea, garantizaba que los problemas fueran desafiantes, realistas y, sobre todo, evaluables de forma rigurosa.
El resultado es un conjunto de desafíos que exigen mucho más que una simple recuperación de información. Exigen planificación, razonamiento en múltiples pasos y un uso preciso de las herramientas disponibles para crear, leer, actualizar y eliminar información de manera coherente para alcanzar un objetivo complejo. MCPMark no pregunta a la IA «¿cuál es la capital de Francia?», sino que le pide «reorganiza este proyecto, actualiza la base de datos de clientes y configura un nuevo flujo de trabajo», una tarea mucho más alineada con el futuro que se nos promete.
Poniendo a prueba a los titanes digitales
Una vez diseñado el riguroso campo de batalla, era hora de convocar a los contendientes. El equipo de investigación seleccionó un amplio espectro de los modelos de lenguaje más avanzados del mundo, tanto propietarios como de código abierto, para enfrentarlos a los 127 desafíos de MCPMark. Entre los participantes se encontraban gigantes como la serie GPT de OpenAI, incluyendo distintas variantes de GPT-4.1 y, de manera destacada, el esperado GPT-5 en diferentes configuraciones de «esfuerzo de razonamiento». También se evaluaron modelos de vanguardia como la familia Claude de Anthropic, Grok de xAI, y potentes alternativas de código abierto como Qwen3 y Kimi.
Para garantizar una competición justa, todas las IA fueron ejecutadas a través de un marco de agente estandarizado y minimalista llamado «MCPMark-Agent». Este agente actuaba como un supervisor imparcial, proporcionando a cada modelo las mismas herramientas y el mismo entorno de ejecución, sin añadir optimizaciones ni heurísticas que pudieran favorecer a uno sobre otro. El objetivo era medir la capacidad intrínseca del modelo para razonar y actuar, no la eficacia de un marco de agente personalizado.
La evaluación del rendimiento se basó en tres métricas complementarias, cada una revelando una faceta distinta de la competencia de un agente. La primera, pass@1, es la más sencilla de entender: representa la tasa de éxito en un único intento. Es la probabilidad de que el agente resuelva la tarea correctamente a la primera. La segunda, pass@4, ofrece una visión más optimista, midiendo el éxito si se le conceden al agente hasta cuatro intentos independientes. Esto indica si los fallos son consistentes o si, con un poco de suerte por la naturaleza estocástica de los modelos, la tarea puede llegar a resolverse.
Sin embargo, la métrica más reveladora y estricta fue la tercera: pass^4. Esta mide la robustez y la fiabilidad. Para que una tarea se considere superada bajo esta métrica, el agente debe tener éxito en cuatro de cuatro intentos independientes. Un resultado alto en pass^4 es el verdadero indicador de un agente fiable, uno cuyo éxito no es producto del azar, sino de una capacidad consistente. En el mundo real, donde se espera que un asistente digital realice una tarea de manera fiable cada vez que se le pide, esta es la métrica que realmente importa.
Los resultados, presentados en tablas detalladas, fueron un jarro de agua fría para cualquiera que creyera que la era de los agentes plenamente autónomos estaba a la vuelta de la esquina. El modelo con mejor rendimiento, gpt-5-medium, solo alcanzó una tasa de éxito del 52.56% en su primer intento (pass@1). Esto significa que, incluso para la IA más avanzada, casi la mitad de las tareas realistas resultaron en un fracaso inmediato. Otros modelos muy respetados, como Claude-Sonnet-4, se quedaron por debajo del 30%.
La imagen se vuelve aún más sombría al analizar la fiabilidad. Aunque la tasa de éxito de gpt-5-medium aumentaba al 68.50% si se le daban cuatro intentos (pass@4), su capacidad para resolver la tarea de manera consistente en los cuatro intentos (pass^4) se desplomaba a un mero 33.86%. Dicho de otro modo, en aproximadamente dos tercios de las tareas, el modelo más potente del mundo demostró ser inconsistente. Para otros modelos, las cifras eran aún peores, con tasas de fiabilidad que a menudo caían por debajo del 15%.
Estos números fríos pintan un cuadro inequívoco: los agentes de IA actuales son frágiles. Su éxito es a menudo inconsistente y su rendimiento se degrada drásticamente a medida que aumenta la complejidad del mundo real. Además, el estudio reveló la enorme cantidad de interacción necesaria para estas tareas. De media, los modelos necesitaron 16.2 turnos de ejecución y 17.4 llamadas a herramientas por tarea, cifras significativamente superiores a las de benchmarks anteriores, lo que subraya la naturaleza de «prueba de estrés» de MCPMark. Modelos como Kimi-K2-Instruct a menudo entraban en un bucle de «sobrellamadas», superando los 30 turnos sin lograr un progreso significativo, demostrando que más actividad no equivale necesariamente a un mejor rendimiento. Los modelos más fuertes, de hecho, tendían a resolver las tareas con menos interacciones, pero más precisas y mejor planificadas.
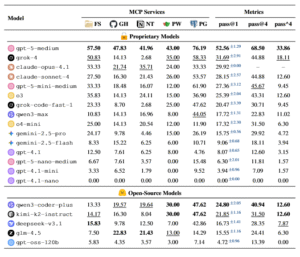
Comparación de modelos entre MCP. Pass@1 se calcula como el promedio de cuatro ejecuciones independientes, donde el superíndice muestra la desviación estándar; cada valor de servicio MCP también se promedia en cuatro ejecuciones. Dentro de cada grupo de modelos (Propietario/Código abierto), el mejor resultado se marca en negrita y el segundo mejor resultado se subraya. Para los modelos de la serie GPT-5, los sufijos explícitos (p. ej., “-medio”) indican la configuración del esfuerzo de razonamiento; para todos los modelos, los resultados corresponden a su esfuerzo de razonamiento predeterminado, si es compatible. Las abreviaturas de los servicios MCP son: FS = Sistema de archivos, GH = GitHub, NT = Notion, PW = Playwright, PG = PostgreSQL.
Por qué tropiezan las inteligencias artificiales más avanzadas
El valor de MCPMark no reside únicamente en demostrar que los agentes de IA fallan, sino en proporcionar las herramientas para entender por qué lo hacen. El análisis detallado de los resultados revela patrones consistentes que apuntan a las debilidades fundamentales de la tecnología actual, ofreciendo una hoja de ruta para futuras investigaciones.
Una de las primeras conclusiones claras fue la existencia de una notable «brecha de entorno». Los modelos de IA mostraron un rendimiento significativamente mejor en tareas que involucraban servicios locales, como la gestión de archivos en Filesystem o las consultas en una base de datos PostgreSQL, en comparación con los servicios remotos como Notion y GitHub. Por ejemplo, gpt-5-medium alcanzó un impresionante 76.19% de éxito en PostgreSQL, pero su rendimiento cayó a cifras en torno al 40% en Notion y GitHub. La explicación más probable para esta discrepancia radica en la disponibilidad de datos de entrenamiento. Es relativamente fácil y barato para los desarrolladores de IA simular interacciones con un sistema de archivos o una base de datos local, generando así enormes cantidades de datos para entrenar a sus modelos. Por el contrario, entrenar una IA para interactuar de manera auténtica y compleja con las APIs de servicios remotos como Notion requiere trazas de interacción real, que son mucho más difíciles y costosas de obtener a gran escala. Esto sugiere que, a pesar de sus capacidades de razonamiento, el rendimiento de los agentes sigue estando fuertemente ligado a la calidad y cantidad de los datos de entrenamiento específicos para cada dominio. Es como un estudiante que ha estudiado mucho la teoría en los libros (entornos locales) pero tiene poca experiencia en debates reales con otras personas (entornos remotos).
El estudio también arrojó luz sobre un concepto fascinante: el «esfuerzo de razonamiento». Algunos modelos, como la serie GPT-5, permiten configurar cuánto «piensan» antes de generar una respuesta o ejecutar una acción. Los investigadores probaron estos modelos en configuraciones de esfuerzo bajo, medio y alto. Los resultados fueron reveladores. Para los modelos más grandes como GPT-5, aumentar el esfuerzo de razonamiento de bajo a medio supuso una mejora sustancial en el rendimiento, pasando del 46.85% al 52.56%. Curiosamente, el esfuerzo más alto no siempre se traducía en mejores resultados, a veces incluso disminuía ligeramente el rendimiento, lo que sugiere que hay un punto óptimo de «reflexión». Este beneficio del razonamiento adicional fue especialmente pronunciado en los entornos remotos y más desafiantes como GitHub, donde el rendimiento casi se duplicó. Este hallazgo respalda una idea emergente en la comunidad de IA: «el lenguaje generaliza a través del razonamiento en los agentes». Cuando un agente se enfrenta a una tarea novedosa para la que tiene pocos datos de entrenamiento, la capacidad de «pensar» más profundamente le permite extrapolar su conocimiento y planificar una secuencia de acciones más efectiva, cerrando así la brecha de la falta de experiencia directa.
Finalmente, el análisis de los tipos de fallos proporciona una visión microscópica de las debilidades de cada modelo. Los errores se clasificaron en dos grandes grupos:
- Fallos explícitos: Son errores técnicos y obvios. Incluyen el desbordamiento de la ventana de contexto (el agente se «satura» con demasiada información), el límite de turnos superado (el agente entra en un bucle y se queda sin intentos), el abandono (el modelo decide que la tarea es imposible), la parada prematura (el agente se detiene sin haber completado la tarea) o las llamadas malformadas (intenta usar una herramienta de forma incorrecta).
- Fallos implícitos: Estos son mucho más sutiles y preocupantes. El agente completa la tarea, informa con confianza de su éxito, pero el resultado final es incorrecto. No hay un error técnico visible, simplemente la solución no cumple con los requisitos. Es el equivalente a un estudiante que entrega un examen completo, bien escrito y sin tachones, pero con las respuestas equivocadas.
El análisis mostró que, para los modelos más avanzados como GPT-5 y Kimi, más del 80% de sus fallos eran de tipo implícito. Esto indica que los errores ya no son simples problemas técnicos de implementación, sino que provienen de deficiencias más profundas en el razonamiento, la planificación y la comprensión del contexto. En contraste, modelos menos avanzados como Gemini-2.5-flash mostraron una mayor proporción de fallos explícitos, como llamadas malformadas o abandonos, lo que sugiere debilidades más fundamentales en su capacidad de planificación básica. Este desglose es crucial porque indica que, a medida que los modelos mejoran, sus fallos se vuelven más difíciles de detectar, lo que hace que la verificación programática y rigurosa como la de MCPMark sea aún más indispensable.

Distribución de turnos. Cada punto representa una ejecución (gris = fallo). Los gráficos muestran la distribución de turnos de éxito; el color codifica «pasa a 1». Los modelos más fuertes terminan con menos llamadas y mejor dirigidas.
El largo camino hacia los agentes autónomos fiables
MCPMark emerge, en última instancia, como mucho más que un simple conjunto de pruebas académicas. Es un espejo que refleja el estado actual de la inteligencia artificial con una honestidad brutal, despojándola de la hipérbole de marketing y mostrándonos tanto su asombroso potencial como sus profundas limitaciones. El estudio funciona como un necesario control de la realidad, un recordatorio de que el camino desde los impresionantes demos tecnológicos hasta los productos robustos y fiables es largo, arduo y está plagado de desafíos fundamentales que aún no hemos resuelto.
Los resultados de esta exhaustiva evaluación señalan tres frentes críticos en los que la investigación y el desarrollo deben concentrarse para que la promesa de los agentes autónomos pueda materializarse. El primero es la necesidad de evolucionar desde un uso de herramientas meramente reactivo hacia un razonamiento sofisticado y proactivo. El éxito en MCPMark no se correlacionó con la cantidad de acciones realizadas, sino con la calidad y la eficiencia de las decisiones tomadas. Los mejores agentes no fueron los que más lo intentaron, sino los que planificaron de manera más inteligente. Esto subraya que la verdadera autonomía no vendrá de modelos que simplemente reaccionan a estímulos, sino de aquellos que pueden construir un modelo mental del problema, anticipar consecuencias y trazar un curso de acción óptimo.
El segundo gran desafío es la eficiencia del contexto y la gestión de tareas a largo plazo. Muchos agentes fallaron porque, en el transcurso de una larga secuencia de interacciones, perdieron el hilo de la tarea original. El problema no es solo el tamaño de la «ventana de contexto» del modelo, sino la habilidad del agente para gestionar un historial de conversación y acciones en constante crecimiento, distinguiendo la información relevante del ruido. Lograr que un agente mantenga la coherencia y el enfoque a lo largo de docenas o cientos de pasos requerirá avances significativos en estrategias de memoria, resumen y gestión del contexto.
Finalmente, y quizás el punto más crítico para su adopción en el mundo real, está la necesidad de un salto cuántico en la estabilidad y la fiabilidad de la ejecución. La drástica caída del rendimiento de la métrica pass@1 a pass^4 es la evidencia más clara de la inconsistencia de los modelos actuales. Un agente que a veces tiene éxito y a veces falla en la misma tarea, sin un motivo aparente, no es una herramienta en la que se pueda confiar. Construir agentes con capacidades robustas de manejo de errores, autoevaluación y autocorrección es esencial para mitigar los riesgos y generar la confianza necesaria para su despliegue en entornos críticos.
El trabajo presentado en MCPMark no solo diagnostica los problemas, sino que también ofrece el campo de pruebas para medir el progreso en su solución. A medida que los modelos de lenguaje y los marcos de agentes continúen evolucionando, benchmarks como este servirán de vara de medir objetiva para cuantificar las mejoras. Al mismo tiempo, los propios benchmarks deberán evolucionar, buscando formas de escalar la creación de tareas de alta calidad y de introducir gradientes de dificultad más finos para evaluar también a modelos más pequeños y eficientes.
La llegada de la «era agéntica» no será un evento repentino, sino un proceso gradual de maduración. Dependerá menos de los anuncios espectaculares y más del trabajo metódico y riguroso de identificar y corregir estas debilidades fundamentales. La verdadera inteligencia artificial generalista no será aquella que pueda mantener una conversación elocuente, sino aquella que pueda superar, de manera consistente y fiable, el tipo de exámenes prácticos, realistas y exigentes que MCPMark ha puesto sobre la mesa. Este es el verdadero estándar de oro, y los resultados actuales nos dicen que, aunque el viaje ha comenzado, la meta todavía está lejos.
Referencias
Anthropic. (2024, November). Introducing the model context protocol. Anthropic.
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261.
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, J., Wang, Z., Yau, S. K. S., Lin, Z., et al. (2024). Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations, ICLR.
Luo, Z., Shen, Z., Yang, W., Zhao, Z., Jwalapuram, P., Saha, A., Sahoo, D., Savarese, S., Xiong, C., & Li, J. (2025). Mcp-universe: Benchmarking large language models with real-world model context protocol servers. arXiv preprint arXiv:2508.14704.
OpenAI. (2025c, August). Gpt-5 system card. OpenAI.
Yao, S., Shinn, N., Razavi, P., & Narasimhan, K. (2024). 7-bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045.
Yin, M., Shen, D., Xu, S., Han, J., Dong, S., Zhang, M., Hu, Y., Liu, S., Ma, S., Wang, S., et al. (2025). Livemcp-101: Stress testing and diagnosing mcp-enabled agents on challenging queries. arXiv preprint arXiv:2508.15760.

