
En los laboratorios de investigación de todo el mundo, desde las instalaciones de Harvard Medical School hasta los centros académicos distribuidos por el planeta, un cambio silencioso pero profundo está tomando forma. La inteligencia artificial, esa tecnología que ha transformado desde nuestras formas de comunicarnos hasta cómo consumimos entretenimiento, se encuentra ahora en el umbral de revolucionar algo mucho más fundamental: el propio proceso de descubrimiento científico. No se trata meramente de automatizar tareas repetitivas o de procesar grandes volúmenes de información, ambiciones ya alcanzadas en décadas anteriores. La visión actual es más ambiciosa y, quizás, más inquietante en su alcance: crear entidades computacionales capaces de razonar, experimentar y colaborar en el descubrimiento científico de manera autónoma.
Esta transformación, sin embargo, enfrenta obstáculos considerables. Los sistemas de inteligencia artificial diseñados para actuar como científicos han permanecido, hasta ahora, como creaciones aisladas, construidas a medida para problemas específicos y carentes de la infraestructura compartida que permita su reutilización y expansión. Son, en esencia, prototipos únicos que demandan inversiones enormes de tiempo y recursos para cada implementación nueva. Esta fragmentación contrasta dramáticamente con los ecosistemas que han impulsado revoluciones en campos como la biología molecular o la genómica, donde plataformas estandarizadas han permitido que miles de investigadores construyan sobre el trabajo de sus colegas, multiplicando exponencialmente el ritmo del progreso.
Ahora, un equipo interdisciplinario liderado desde el Departamento de Informática Biomédica de Harvard Medical School ha presentado ToolUniverse, un ecosistema diseñado para transformar radicalmente esta situación. No se trata de otro modelo de lenguaje grande ni de un algoritmo más potente. ToolUniverse representa algo diferente: una infraestructura completa que permite a cualquier investigador, independientemente de su formación técnica, construir científicos artificiales personalizados conectando modelos de razonamiento con más de seiscientas herramientas científicas que abarcan desde algoritmos de aprendizaje automático hasta bases de datos especializadas, APIs de servicios externos y paquetes de software científico. La ambición es clara: democratizar el acceso a estas tecnologías emergentes y establecer un estándar común que permita a la comunidad científica global colaborar en la construcción de sistemas cada vez más sofisticados.
Para comprender la magnitud de esta propuesta, conviene primero entender qué significa realmente un «científico artificial» y por qué su construcción ha resultado tan compleja hasta ahora. Estos sistemas no son simples herramientas de búsqueda ni asistentes conversacionales sofisticados. Son entidades computacionales diseñadas para ejecutar el ciclo completo de investigación científica: formular hipótesis basándose en conocimiento existente, diseñar experimentos para validarlas, ejecutar análisis sobre datos reales, interpretar resultados y refinar sus teorías en función de lo descubierto. Requieren, por tanto, no solo capacidades de razonamiento abstracto, sino también la habilidad de interactuar con el mundo real, de manipular instrumentos, consultar bases de datos, ejecutar simulaciones y, cuando sea necesario, solicitar la intervención de expertos humanos.
El desafío técnico radica en que el conocimiento y las herramientas científicas están dispersos en formatos incompatibles entre sí. Un modelo de aprendizaje automático entrenado para predecir propiedades farmacológicas puede requerir configuraciones computacionales específicas y acceso a hardware especializado. Una base de datos de compuestos químicos puede utilizar protocolos de consulta particulares. Un paquete de software para análisis estadístico puede demandar conocimiento profundo de su sintaxis y peculiaridades. Tradicionalmente, integrar estas piezas heterogéneas ha requerido equipos de ingenieros especializados trabajando durante meses, produciendo soluciones que funcionan para un problema concreto pero que resultan imposibles de adaptar a otros contextos.
El protocolo que unifica la diversidad científica
ToolUniverse aborda este problema estableciendo lo que sus creadores denominan un «protocolo de interacción entre inteligencia artificial y herramientas». La analogía con el protocolo HTTP, el estándar que permite la comunicación en internet, resulta particularmente iluminadora. Así como HTTP estableció reglas comunes que permiten a navegadores y servidores comunicarse independientemente de sus implementaciones internas, ToolUniverse define un lenguaje universal mediante el cual los modelos de inteligencia artificial pueden descubrir, comprender y utilizar herramientas científicas sin necesidad de conocer sus complejidades técnicas subyacentes.
Este protocolo se construye sobre tres pilares fundamentales. El primero es un esquema de especificación que describe cada herramienta en un formato estandarizado: su nombre, una descripción funcional clara, los parámetros que acepta con sus tipos de datos correspondientes y la estructura de los resultados que devuelve. Esta especificación se proporciona directamente a los modelos de lenguaje dentro de su contexto de procesamiento, permitiéndoles comprender cómo emplear cada herramienta de manera correcta.
El segundo pilar consiste en un esquema de interacción uniforme. Todas las solicitudes a herramientas, independientemente de su naturaleza, se codifican como estructuras simples que especifican el nombre de la herramienta deseada y los argumentos necesarios para su ejecución. Esta estandarización convierte herramientas radicalmente diferentes, desde funciones locales en Python hasta modelos de aprendizaje automático alojados en servidores remotos o incluso instrumentos de laboratorio, en componentes intercambiables desde la perspectiva del científico artificial.
El tercer elemento fundamental son los métodos de comunicación. Para operaciones locales, ToolUniverse ejecuta directamente en entornos Python. Para herramientas remotas, aquellas que requieren configuraciones especializadas o que deben permanecer privadas por razones de seguridad o propiedad intelectual, el sistema implementa el Model Context Protocol, un estándar reciente que permite transmitir solicitudes a través de redes de manera segura y eficiente.
Lo notable de esta arquitectura es que abstrae completamente la complejidad técnica. Un investigador puede consultar una nueva base de datos sin escribir consultas SQL específicas, ejecutar modelos de aprendizaje automático sin configurar entornos de cómputo con GPUs, o acceder a equipamiento de laboratorio conectado a internet mediante una única llamada estandarizada. La heterogeneidad del backend se vuelve invisible para el usuario.
Los componentes esenciales del ecosistema
La potencia de ToolUniverse no reside únicamente en su protocolo unificador, sino en los componentes especializados que orquestan el ciclo de vida completo de las herramientas. Estos módulos, trabajando en conjunto, permiten que el ecosistema no sea meramente un repositorio pasivo sino un entorno activo y adaptativo.
El buscador de herramientas implementa tres estrategias complementarias de búsqueda. La primera, basada en palabras clave, procesa consultas en lenguaje natural mediante técnicas de tokenización, eliminación de términos comunes y reducción morfológica, generando índices de relevancia mediante algoritmos de frecuencia de términos e inversa de frecuencia documental. Esta aproximación, independiente de modelos de aprendizaje, garantiza respuestas rápidas incluso en entornos con recursos computacionales limitados.
La segunda estrategia aprovecha las capacidades de razonamiento de modelos de lenguaje grandes. Construye indicaciones contextuales detalladas que presentan la consulta del usuario junto con especificaciones de herramientas candidatas, permitiendo al modelo inferir qué recursos resultan óptimos para tareas complejas o abstractas que demandan comprensión semántica profunda.
La tercera estrategia emplea búsqueda por embeddings, representaciones vectoriales del significado semántico. El sistema ha sido entrenado mediante pares sintéticos de consultas de usuarios y especificaciones de herramientas, aprendiendo a capturar la correspondencia entre intenciones y funcionalidades. Durante la búsqueda, las consultas se convierten en vectores que se comparan con vectores precomputados de todas las herramientas disponibles, identificando coincidencias mediante similitud coseno. Esta aproximación escala eficientemente a repositorios masivos.
El ejecutor de herramientas gestiona la instanciación dinámica y la validación de solicitudes. Para minimizar el consumo de memoria del sistema, las herramientas se cargan bajo demanda cuando son requeridas por primera vez, manteniéndose en caché para usos posteriores. Durante la carga, el ejecutor inyecta configuraciones necesarias como credenciales de autenticación o direcciones de servicios remotos. Antes de cada ejecución, valida rigurosamente que los argumentos proporcionados cumplan con los tipos de datos y estructuras esperadas, generando mensajes descriptivos de error cuando detecta inconsistencias.
El gestor de herramientas simplifica radicalmente la integración de nuevos recursos. Para herramientas locales, requiere únicamente una especificación en formato JSON y una función de ejecución. Un decorador de código permite registrar estas herramientas mediante una sola línea de programación. Para herramientas remotas, proporciona un cargador automático que, dada la dirección de un servidor compatible con el Model Context Protocol, registra todas sus capacidades en el ecosistema sin configuración adicional.
El compositor de herramientas habilita la construcción de flujos de trabajo complejos mediante la combinación programática de recursos existentes. Soporta ejecución secuencial, donde la salida de una herramienta alimenta la entrada de la siguiente; ejecución paralela, donde múltiples herramientas procesan simultáneamente consultas relacionadas; y bucles retroalimentados, donde sistemas agénticos generan llamadas a funciones, ejecutan herramientas e incorporan resultados en análisis iterativos de múltiples pasos.
Optimización automática y descubrimiento de nuevas capacidades
Dos componentes adicionales distinguen a ToolUniverse de repositorios convencionales de software: el optimizador y el descubridor de herramientas. Ambos emplean sistemas multiagente que automatizan procesos tradicionalmente reservados a ingenieros de software especializados.
El optimizador mejora iterativamente las especificaciones de herramientas existentes. Genera casos de prueba sintéticos basándose en la configuración de cada herramienta, ejecuta estas pruebas y analiza los resultados para identificar inconsistencias entre la descripción formal y el comportamiento real. Un agente analizador examina estas discrepancias y propone especificaciones refinadas que eliminan ambigüedades y redundancias. El proceso evalúa la calidad resultante mediante seis dimensiones: claridad, precisión, completitud, concisión, facilidad de uso y ausencia de información redundante. Las iteraciones continúan hasta alcanzar umbrales de calidad predefinidos o límites de esfuerzo computacional.
El descubridor de herramientas genera recursos completamente nuevos a partir de descripciones en lenguaje natural. El proceso comienza con una fase de descubrimiento que identifica herramientas existentes con funcionalidades similares, proporcionando patrones y convenciones que guían la creación. Un agente generador de especificaciones produce documentación formal estructurada, incluyendo nombres, descripciones funcionales, definiciones de parámetros con anotaciones de tipo y esquemas de valores de retorno. Un segundo agente sintetiza código ejecutable que implementa la funcionalidad descrita, incorporando manejo de errores, gestión de dependencias e integración con el sistema de registro. Un evaluador de calidad analiza la herramienta resultante mediante múltiples dimensiones, incluyendo análisis estático del código, pruebas dinámicas con casos generados automáticamente y perfiles de rendimiento. La retroalimentación de estas evaluaciones alimenta refinamientos iterativos hasta que la herramienta alcanza estándares de producción.
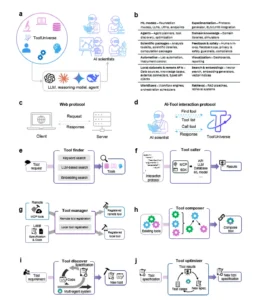
a) TOOLUNIVERSE: un ecosistema para la formación de científicos de IA. Los LLM de propósito general, los modelos de razonamiento y los agentes están conectados al ecosistema TOOLUNIVERSE, compuesto por más de 600 herramientas científicas, lo que permite flujos de trabajo de investigación autónomos en todos los dominios. b) Descripción general de las diversas categorías de herramientas compatibles con TOOLUNIVERSE, incluyendo modelos de AA, agentes, conocimiento del dominio, experimentación, paquetes científicos, automatización, retroalimentación humana, flujos de trabajo, conjuntos de datos, API, almacenamiento de incrustaciones, visualización y recuperación. c-d) Así como HTTP estandariza la comunicación cliente-servidor, TOOLUNIVERSE proporciona un protocolo de interacción que regula cómo los modelos de IA emiten solicitudes de herramientas y reciben respuestas. Operaciones principales para los científicos de IA que interactúan con TOOLUNIVERSE: Buscar herramienta (mapeo del lenguaje natural a las especificaciones de la herramienta) y Llamar herramienta (ejecución de una herramienta y retorno de resultados estructurados). e) Buscador de herramientas: componente para identificar herramientas relevantes mediante tres estrategias: búsqueda por palabras clave, búsqueda contextual basada en LLM y búsqueda por similitud basada en incrustación. f) Llamador de herramientas: motor de ejecución que valida las entradas, carga dinámicamente las herramientas, envía llamadas mediante TOOLUNIVERSE.run() o MCP y devuelve resultados estructurados a los clientes. g) Gestor de herramientas: entorno para integrar herramientas locales y remotas. Las herramientas locales se registran mediante especificaciones JSON y decoradores, mientras que las herramientas remotas se añaden mediante MCP para configuraciones con restricciones de privacidad o dependencia. h) Compositor de herramientas: entorno para encadenar múltiples herramientas en flujos de trabajo compuestos. Admite la orquestación secuencial, paralela y basada en retroalimentación de herramientas heterogéneas. i) Descubrimiento de herramientas: sistema multiagente para generar nuevas herramientas a partir de requisitos de lenguaje natural. Combina la síntesis de especificaciones, la generación automatizada de código, la validación y el refinamiento iterativo para crear herramientas listas para producción. j) Optimizador de herramientas: sistema multiagente que refina iterativamente las especificaciones de las herramientas para mejorar la claridad, la precisión y la usabilidad. Integra la generación de pruebas, el análisis de la ejecución y la mejora basada en la retroalimentación.
Construyendo científicos artificiales: tres aproximaciones
La versatilidad de ToolUniverse se manifiesta en su capacidad de integrarse con distintas arquitecturas de inteligencia artificial, desde modelos de lenguaje convencionales hasta sistemas de razonamiento avanzados y agentes especializados. Tres aproximaciones ilustran este espectro de posibilidades.
La primera aproximación emplea modelos de lenguaje grandes, como Claude o GPT, equipándolos con acceso a herramientas mediante instrucciones contextuales simples. El modelo recibe especificaciones de herramientas disponibles dentro de su ventana de procesamiento y puede generar solicitudes válidas durante su razonamiento. La instalación requiere únicamente configurar el cliente del modelo para que se comunique con el servidor de ToolUniverse, proceso que demanda minutos en lugar de semanas de desarrollo.
La segunda aproximación utiliza sistemas agénticos como Gemini CLI, que combinan modelos de razonamiento con bucles de retroalimentación autónomos. Estos sistemas emplean el buscador de herramientas de ToolUniverse para identificar recursos relevantes de manera automática, razonan sobre su aplicabilidad y los invocan iterativamente para resolver problemas complejos de múltiples pasos. La configuración se reduce a especificar la dirección del servidor de ToolUniverse en el archivo de ajustes del agente.
La tercera aproximación integra agentes especializados, entrenados mediante aprendizaje reforzado para dominar tareas en dominios científicos específicos. Ejemplos incluyen TxAgent para investigación terapéutica o Virtual Lab para diseño de nanobodies. Estos agentes pueden utilizar ToolUniverse tanto durante inferencia como durante entrenamiento, empleando el ecosistema como entorno de experimentación donde el aprendizaje reforzado optimiza sus estrategias de navegación en espacios de herramientas complejos.
Un caso de estudio: del razonamiento abstracto al descubrimiento terapéutico
Para demostrar las capacidades del ecosistema en un contexto realista, los creadores de ToolUniverse presentan un estudio de caso centrado en el descubrimiento terapéutico para hipercolesterolemia. El proceso, ejecutado mediante Gemini CLI conectado a ToolUniverse, ilustra cómo un científico artificial puede orquestar herramientas diversas para progresar desde la generación de hipótesis hasta la validación de candidatos terapéuticos.
El proceso inicia con la identificación de objetivos moleculares. El científico artificial emplea herramientas de minería bibliográfica, perfilado de objetivos terapéuticos y análisis de expresión tisular para priorizar la HMG-CoA reductasa como el objetivo más prometedor, documentando simultáneamente efectos secundarios potenciales asociados con su inhibición. Esta selección se somete a validación por expertos humanos mediante las herramientas de retroalimentación integradas en el ecosistema.
Posteriormente, el sistema accede a la base de datos DrugBank para perfilar fármacos existentes que inhiben la HMG-CoA reductasa, identificando estatinas. El análisis farmacológico detallado de cada compuesto resulta en la selección de lovastatina como candidato inicial a optimizar, dado que presenta efectos fuera del objetivo en tejidos no hepáticos.
La fase de cribado in silico combina recuperación de análogos estructurales desde ChEMBL con modelos predictivos de aprendizaje automático. El sistema emplea Boltz-2 para predecir afinidad de unión y ADMET-AI para perfilar propiedades farmacocinéticas. Esta combinación evalúa probabilidad de unión, afinidad predicha y penetrancia en la barrera hematoencefálica para treinta y dos compuestos candidatos. Dada la variabilidad estocástica de Boltz-2, cada compuesto se evalúa cuatro veces, calculando medias y desviaciones estándar.
El análisis identifica pravastatina, un fármaco aprobado con menores efectos fuera del objetivo que lovastatina, reproduciendo conocimiento establecido. Más significativamente, descubre una molécula candidata, designada CHEMBL2347006 o CHEMBL3970138 según variaciones en su representación SMILES, que exhibe mayor afinidad de unión predicha, penetrancia reducida en barrera hematoencefálica y mejores propiedades de biodisponibilidad oral y estabilidad metabólica comparada con lovastatina.
La evaluación final emplea herramientas de minería de patentes para acceder a bases de datos de propiedad intelectual. El sistema recupera el identificador CID de PubChem para los candidatos prioritarios, obtiene patentes asociadas y lee los abstracts de estos documentos. Este proceso revela que el compuesto identificado había sido patentado para indicaciones cardiovasculares entre 2019 y 2021, confirmando su potencial terapéutico mediante evidencia independiente en la literatura de propiedad intelectual.
Este flujo de trabajo demuestra capacidades que trascienden el paradigma de tuberías bioinformáticas especializadas. El científico artificial navega flexiblemente entre química, biología humana y literatura de patentes, recuperando múltiples líneas de evidencia para sustentar sus candidatos finales. La recuperación de pravastatina, estatina con propiedades superiores a lovastatina, valida que la investigación mediada por ToolUniverse puede reproducir y potencialmente avanzar el conocimiento científico actual.

a) Formar científicos de IA conectando LLM (como Claude) con herramientas especializadas. Al seleccionar las herramientas adecuadas para cada tarea y proporcionar instrucciones claras, estos científicos de IA con LLM pueden realizar tareas científicas de forma eficaz. b) Formar científicos de IA con uso y razonamiento de herramientas multidisciplinares conectando TOOLUNIVERSE con agentes de IA (como Gemini CLI). Estos agentes aprovechan las capacidades de búsqueda de herramientas para seleccionar herramientas relevantes, razonar y usar TOOLUNIVERSE de forma iterativa para abordar tareas científicas complejas. c) Aplicar TOOLUNIVERSE al descubrimiento terapéutico de la hipercolesterolemia conectándose con Gemini CLI como científico de IA. Este ejemplo ilustra cómo TOOLUNIVERSE permite a un científico de IA seleccionar, encadenar y utilizar herramientas específicas de su dominio, pasando de la generación de hipótesis a la validación de candidatos, manteniendo la flexibilidad para incorporar la retroalimentación humana cuando sea necesario.
Más allá de la orquestación: un nuevo paradigma para la investigación asistida por inteligencia artificial
ToolUniverse se distingue de marcos de orquestación existentes como GPT Agent, Gemini CLI, Claude Code, LangChain o Autogen. Mientras estos sistemas permiten enrutar consultas o conectar agentes con herramientas predefinidas, no soportan el ciclo completo de creación, refinamiento e integración de recursos en flujos científicos. ToolUniverse introduce capacidades cualitativamente diferentes mediante sus componentes de descubrimiento y optimización, que generan herramientas nuevas desde descripciones en lenguaje natural y mejoran iterativamente especificaciones mediante retroalimentación automatizada.
Esta distinción resulta fundamental. Los repositorios estáticos de herramientas, por extensos que sean, permanecen limitados a las capacidades previamente implementadas. ToolUniverse, en contraste, puede expandir dinámicamente su propio repertorio cuando enfrenta lagunas en su conjunto de capacidades, transformando descripciones textuales de funcionalidades deseadas en componentes listos para usar. Esta característica autoextensible sugiere un modelo evolutivo donde el ecosistema crece orgánicamente en respuesta a las necesidades de sus usuarios.
La fiabilidad de las herramientas constituye una preocupación central en cualquier sistema destinado a investigación científica. ToolUniverse aborda esta cuestión mediante un proceso de validación en múltiples etapas. Para cada herramienta candidata, se generan entradas diversas que cubren casos típicos y condiciones límite, documentando las salidas correspondientes. Expertos científicos revisan sistemáticamente estos resultados, evaluando corrección, interpretabilidad y consistencia con el conocimiento del dominio. Complementariamente, sistemas automatizados de optimización prueban iterativamente las especificaciones contra las entradas muestreadas, refinando descripciones hasta alcanzar coherencia entre funcionalidad declarada y comportamiento observado.
Más allá de estas validaciones internas, el ecosistema prioriza herramientas procedentes de fuentes confiables. Muchos recursos incluidos han sido publicados, revisados por pares y validados mediante uso previo por comunidades científicas establecidas, incluyendo instituciones como los Institutos Nacionales de Salud estadounidenses, la Administración de Alimentos y Medicamentos, y otras agencias reguladoras o de investigación. Esta dependencia de recursos previamente validados reduce el riesgo de introducir funcionalidades espurias o no verificadas. Un sistema estructurado de reporte de errores y mantenimiento regular sostiene la fiabilidad a largo plazo.
Las herramientas del científico digital: una taxonomía de capacidades
El inventario de más de seiscientas herramientas en ToolUniverse abarca categorías que reflejan las necesidades multifacéticas de la investigación científica contemporánea. Los modelos de aprendizaje automático incluyen redes neuronales fundacionales, modelos de lenguaje especializados y algoritmos predictivos expuestos como puntos finales invocables. Estos recursos permiten tareas como puntuación de relaciones enfermedad-objetivo, predicción de estados patológicos, análisis de interacciones génicas, evaluación de dependencias genéticas y predicción de propiedades ADMET y afinidades de unión.
Las herramientas agénticas implementan sistemas autónomos para tareas como planificación experimental, enrutamiento de herramientas, generación de hipótesis, revisión de literatura médica y puntuación de diseños experimentales. Cada agente se configura mediante indicaciones personalizadas y especificaciones de herramientas, soportando múltiples backends de modelos de lenguaje. Esta arquitectura configurable permite construir rápidamente nuevos agentes especializados.
Los paquetes de software científico proporcionan información exhaustiva sobre bibliotecas computacionales como NumPy, Pandas y SciPy, incluyendo instrucciones de instalación, ejemplos de uso y enlaces a documentación. La implementación emplea recuperación dual desde APIs de PyPI con información de respaldo local, garantizando disponibilidad incluso cuando servicios externos resultan inaccesibles.
Las bases de datos gestionan recursos estructurados incluyendo vocabularios farmacológicos como DrugBank, registros de ensayos clínicos y repositorios moleculares. Soportan integraciones con datos tabulares, jerárquicos, basados en XML y estructurados en grafos, proporcionando capacidades de búsqueda textual, filtrado por campos, límites configurables de resultados y esquemas de retorno de metadatos.
Las herramientas de integración con APIs habilitan comunicación con fuentes externas de datos científicos mediante protocolos estándar como REST o GraphQL. Los recursos accesibles incluyen bases de datos de fármacos de la FDA, asociaciones enfermedad-objetivo de OpenTargets, información de compuestos de PubChem y numerosos repositorios adicionales, todos con manejo robusto de errores y validación de respuestas.
Las herramientas de retroalimentación experta integran juicio humano directamente en el entorno computacional. Cuando un científico artificial requiere validación o interpretación compleja, puede redirigir solicitudes a expertos humanos mediante un servidor que conecta el sistema con interfaces de usuario. Los especialistas reciben peticiones, proporcionan análisis y recomendaciones, y sus respuestas retornan como resultados de herramientas. Esta arquitectura combina análisis automatizado con validación experta.
Los almacenes de embeddings gestionan representaciones vectoriales de datos científicos. La información se transforma primero en embeddings mediante modelos especializados y se almacena en bases de datos que emplean FAISS para búsqueda semántica eficiente, coincidencia por similitud y recuperación sobre estos repositorios vectorizados.
Implicaciones y horizontes futuros
La propuesta de ToolUniverse trasciende consideraciones meramente técnicas, planteando cuestiones sobre cómo la ciencia podría evolucionar en las próximas décadas. La democratización del acceso a científicos artificiales, objetivo central del proyecto, sugiere un futuro donde investigadores en instituciones con recursos limitados puedan acceder a capacidades analíticas previamente reservadas a laboratorios de élite. Esta redistribución de capacidades podría acelerar descubrimientos en regiones geográficas y disciplinas tradicionalmente marginadas del progreso científico principal.
Sin embargo, la tecnología también plantea interrogantes sobre el papel cambiante de los investigadores humanos. Si sistemas computacionales pueden formular hipótesis, diseñar experimentos y proponer candidatos terapéuticos, ¿cómo se redefine la labor científica? La respuesta probablemente no resida en la sustitución sino en la colaboración complementaria. Los científicos artificiales actuales carecen de intuición contextual profunda, creatividad genuina y juicio ético, capacidades que permanecen firmemente en el dominio humano. Su valor óptimo emerge cuando amplifican el razonamiento humano en lugar de reemplazarlo.
La integración de retroalimentación humana en los flujos de ToolUniverse refleja este reconocimiento. El sistema puede solicitar validación experta en puntos críticos de decisión, garantizando que la autonomía computacional permanezca acotada por supervisión informada. Esta arquitectura híbrida podría convertirse en el modelo predominante: sistemas que navegan eficientemente espacios vastos de posibilidades, identificando candidatos prometedores que posteriormente son sometidos a escrutinio humano riguroso.
Las direcciones futuras mencionadas por los creadores incluyen colaboraciones multiagente, donde múltiples científicos artificiales especializados trabajen coordinadamente en proyectos complejos; evaluaciones comparativas contra grupos de investigación humanos para cuantificar capacidades y limitaciones; e integración con sistemas de laboratorio físicos, permitiendo que decisiones computacionales se traduzcan directamente en experimentos robóticos automatizados.
Esta última posibilidad resulta particularmente transformadora. Laboratorios autónomos equipados con brazos robóticos, estaciones de análisis automatizadas y sistemas de monitoreo en tiempo real podrían ejecutar ciclos completos de hipótesis-experimento-análisis con intervención humana mínima. ToolUniverse proporcionaría la capa de inteligencia que coordina estos recursos físicos, transformando descripciones de experimentos de alto nivel en secuencias detalladas de acciones robóticas.
La sostenibilidad a largo plazo del ecosistema dependerá crucialmente de su adopción por la comunidad científica. Aquí, la analogía con plataformas transformadoras en biología computacional resulta instructiva. Ecosistemas como Bioconductor para análisis genómico o el proyecto scverse para ómica unicelular alcanzaron masas críticas porque resolvieron problemas reales que enfrentaban investigadores cotidianamente, porque bajaron barreras de entrada mediante interfaces accesibles y porque cultivaron comunidades activas de contribuyentes. ToolUniverse, con su énfasis en facilidad de uso, extensibilidad y documentación exhaustiva, parece posicionado para seguir una trayectoria similar.
Los desafíos no son triviales. La curación continua de herramientas, garantizando que permanezcan actualizadas conforme avanzan las tecnologías subyacentes, demandará esfuerzo sostenido. La gobernanza del ecosistema, decidiendo qué herramientas incluir y bajo qué criterios, requerirá equilibrios delicados entre apertura y control de calidad. Las consideraciones de seguridad y privacidad, especialmente cuando científicos artificiales acceden a datos sensibles o proponen intervenciones con consecuencias potenciales en salud humana, necesitarán protocolos robustos.
Pero quizás el desafío más profundo sea cultural. Adoptar científicos artificiales como colaboradores genuinos requiere reimaginar aspectos fundamentales de la práctica investigativa: cómo se atribuye autoría, cómo se evalúa originalidad, cómo se asigna responsabilidad cuando sistemas autónomos cometen errores. Estas preguntas, que apenas comenzamos a formular, definirán el futuro de la investigación asistida por inteligencia artificial tanto como cualquier avance técnico.
Reflexiones finales: hacia una ciencia aumentada
ToolUniverse representa un punto de inflexión en la evolución de la inteligencia artificial aplicada a la investigación científica. Su innovación central no reside en algoritmos novedosos ni en poder computacional bruto, sino en arquitectura conceptual: la idea de que un ecosistema estandarizado, análogo a aquellos que transformaron la biología molecular, puede acelerar dramáticamente el desarrollo de sistemas inteligentes para descubrimiento científico.
La demostración de que un científico artificial, construido en minutos mediante la conexión de un modelo de razonamiento con este ecosistema, puede navegar el proceso completo de descubrimiento de fármacos, desde identificación de objetivos hasta validación de propiedad intelectual, sugiere que hemos cruzado un umbral importante. No se trata ya de prototipos de laboratorio con aplicabilidad limitada, sino de sistemas que pueden abordar problemas reales con complejidad interdisciplinaria genuina.
La visión de los creadores de ToolUniverse es ambiciosa pero está anclada en pragmatismo. No prometen que la inteligencia artificial reemplazará a científicos humanos ni que resolverá mágicamente los desafíos profundos de la investigación. Proponen, más modestamente pero quizás más poderosamente, que proporcionando infraestructura compartida y estándares comunes, podemos acelerar colectivamente el ritmo del descubrimiento mientras mantenemos el juicio humano en el centro del proceso.
El futuro de la ciencia probablemente no será puramente humano ni puramente artificial, sino profundamente colaborativo. Investigadores armados con asistentes computacionales que pueden explorar espacios vastos de posibilidades, ejecutar análisis tediosos y proponer conexiones no obvias, pero guiados siempre por curiosidad, creatividad y criterio éticos genuinamente humanos. ToolUniverse, al democratizar el acceso a estas capacidades, podría ayudar a materializar esa visión.
En última instancia, el éxito de esta tecnología se medirá no por su sofisticación técnica sino por su impacto en el mundo real: descubrimientos acelerados que mejoran vidas, barreras reducidas que permiten participación más amplia en la empresa científica y nuevas formas de colaboración que amplifican lo mejor de la inteligencia humana y computacional. Si ToolUniverse logra contribuir a estos objetivos, su verdadero legado podría ser haber ayudado a construir un futuro donde la ciencia es más accesible, más poderosa y más capaz de enfrentar los desafíos monumentales que confronta nuestra civilización.
Referencias
Gao, S., Zhu, R., Sui, P., Kong, Z., Aldogom, S., Huang, Y., Noori, A., Shamji, R., Parvataneni, K., Tsiligkaridis, T., & Zitnik, M. (2025). Democratizing AI scientists using ToolUniverse. ArXiv preprint arXiv:2509.23426v1.
Gao, S., et al. (2024). Empowering biomedical discovery with AI agents. Cell, 187, 6125–6151.
Swanson, K., Wu, W., Bulaong, N. L., Pak, J. E., & Zou, J. (2025). The virtual lab of AI agents designs new SARS-CoV-2 nanobodies. Nature, 1–3.
Boiko, D. A., MacKnight, R., Kline, B., & Gomes, G. (2023). Autonomous chemical research with large language models. Nature, 624, 570–578.
Virshup, I., et al. (2023). The scverse project provides a computational ecosystem for single-cell omics data analysis. Nature Biotechnology, 41, 604–606.
Wang, H., et al. (2023). Scientific discovery in the age of artificial intelligence. Nature, 620, 47–60.
Anthropic. (2024). Introducing the model context protocol. Anthropic blog.
Brown, T., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877–1901.
Swanson, K., et al. (2024). ADMET-AI: A machine learning ADMET platform for evaluation of large-scale chemical libraries. Bioinformatics, 40, btae416.

