
Hay una imagen que se repite en titulares, keynotes y folletos corporativos: la medicina del futuro impulsada por inteligencias artificiales ubicuas, capaces de leer imágenes radiológicas con pericia sobrehumana, vincular hallazgos con historias clínicas en segundos y ofrecer explicaciones claras para diagnósticos complejos. La promesa seduce, y no es casual. En los últimos años, los grandes modelos de propósito general dieron un salto formidable y empezaron a dominar pruebas estandarizadas, escalas de evaluación y rankings que se convirtieron en el termómetro de tendencias. Si uno se queda con esas tablas, parecería que la clínica está al borde de una transformación irreversible. Sin embargo, el brillo de las listas oculta zonas de penumbra. Cuando se examina cómo toman decisiones estos sistemas y se les somete a condiciones que se parecen más a la vida real que a un examen de opción múltiple, su aparente solidez se resquebraja.
Ese es el punto de partida del trabajo académico que inspira este artículo. Su tesis central es incómoda y, por eso mismo, valiosa: la sensación de que los modelos frontera están listos para tareas clínicas nace, en buena medida, de cómo los estamos midiendo. Las evaluaciones actuales, centradas en la exactitud final de una respuesta, no distinguen si el camino hacia esa respuesta fue clínicamente válido, si el modelo integró de veras la información visual y textual, o si se apoyó en atajos estadísticos. Bajo estrés, la fachada se vuelve translúcida. Cuando se quita una imagen a una pregunta que exige mirar, el sistema a menudo acierta igual. Cuando se reordenan opciones, cambia la decisión. Cuando se pide que “piense paso a paso”, puede justificar con seguridad algo que no vio o que ni siquiera existe. La hipótesis, entonces, se vuelve clara: una parte del progreso medido en benchmarks proviene de trucos de examen y no de comprensión médica robusta.
Para entender qué está en juego conviene poner en limpio algunos conceptos. Un modelo multimodal es aquel que puede recibir texto e imágenes como entrada y producir una respuesta conjunta, por ejemplo, interpretar una placa de tórax a la vez que lee el motivo de consulta. Un benchmark es un conjunto de preguntas o casos con una pauta de corrección, pensado para comparar sistemas bajo reglas homogéneas. En medicina abundan: desde desafíos inspirados en revistas clínicas reconocidas hasta colecciones de preguntas de radiología. Sirven, y mucho, pero no capturan toda la película. La clínica es un terreno de incertidumbre, ruido, ambigüedad y contexto. Un paciente no viene con opciones A, B, C y D. Trae síntomas imprecisos, estudios de calidades variables y antecedentes parciales. Allí, lo que importa no es solo si se acierta, sino por qué, en qué condiciones, con qué grado de seguridad y cómo se explica.
El estudio que analizamos propone mirar con lupa ese “por qué” y esas “condiciones”. Evalúa seis modelos de primera línea en seis benchmarks médicos ampliamente utilizados, desde pruebas de diagnóstico con imágenes y viñetas clínicas hasta tareas de preguntas y respuestas en radiología o generación de informes. Luego, aplica una batería de pruebas de estrés diseñadas para eliminar claves superficiales, romper patrones espurios y forzar al sistema a demostrar comprensión verdadera. Los resultados, como veremos, son un baño de realismo. Modelos que lideran rankings muestran caídas abruptas cuando se les quita lo accesorio. Otros sostienen precisión sin imágenes donde deberían fallar si de verdad dependieran de la visión. Algunos elaboran cadenas de razonamiento que suenan plausibles pero carecen de anclaje visual o contienen errores fácticos. Y, sobre todo, se evidencia que los propios benchmarks miden cosas distintas aunque se los trate como intercambiables: hay conjuntos que pueden resolverse en su mayor parte por texto, otros que demandan lectura visual fina, otros que favorecen la eliminación de distractores en lugar del análisis médico.
Este artículo resume, explica y enmarca esas observaciones para una audiencia no técnica. No se trata de boicotear la adopción de IA en salud, sino de dar un paso de madurez: si queremos confiar de verdad en estos sistemas, debemos evaluarlos como lo haríamos con un fármaco o un dispositivo, atendiendo a sus mecanismos, límites y estabilidad bajo presión. La meta no es derribar la ilusión y quedarnos sin nada, sino reemplazarla por un diagnóstico más honesto de dónde estamos, qué falta y qué estándares hacen falta para que la IA no solo apruebe exámenes, sino que ayude a pacientes reales.
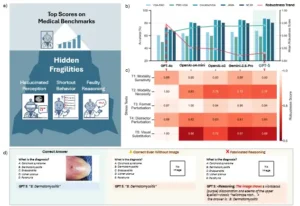
Las pruebas de estrés revelan fragilidades ocultas en los LMM en tareas médicas multimodales. a. Ilustración conceptual: Las puntuaciones de referencia sugieren una mejora constante del modelo. Las pruebas de estrés revelan vulnerabilidades ocultas: los modelos más nuevos pueden ser igual o más frágiles a pesar de las puntuaciones más altas. b. Mientras que las puntuaciones de referencia convencionales (línea verde) muestran progreso, las puntuaciones de robustez (línea roja) revelan una fragilidad creciente bajo entradas incompletas o adversas. c. El mapa de calor de la prueba de estrés altera la tabla de clasificación aparente, revelando patrones de fallo específicos del modelo. d. Ejemplos ilustrativos: (1) respuesta correcta a pesar de la ausencia de imagen y opciones desordenadas (comportamiento de atajo); (2) justificación inventada al solicitar una respuesta sin información visual.
El mapa real de lo evaluado
Antes de entrar al laboratorio de pruebas conviene recorrer el terreno. La investigación toma seis modelos de referencia recientes y los somete a seis benchmarks médicos populares. Entre los conjuntos más conocidos están desafíos de diagnóstico inspirados en casos publicados por revistas clínicas reputadas, baterías de preguntas y respuestas visuales en radiología, colecciones de ilustraciones biomédicas con interrogantes, y tareas de generación de informes a partir de radiografías de tórax. El detalle importa porque allí nace una fuente de confusión: combinar resultados de conjuntos con demandas muy diferentes crea la ilusión de una competencia homogénea que en realidad es un mosaico. Hay datasets con fuerte dependencia visual y otros que son, en el fondo, preguntas textuales con una imagen de compañía. Si un sistema “la rompe” en los segundos y se lo reporta como “multimodal sobresaliente”, estamos inflando expectativas.
El trabajo adopta un enfoque clínico para perfilar cada benchmark. Con la guía de especialistas, define ejes de complejidad razonada y complejidad visual: cuánta inferencia requiere; si precisa contexto clínico o basta un dato aislado; si necesita comparar vistas o series temporales; si la calidad de la imagen altera la conclusión; si la ubicación exacta y los detalles finos son esenciales. Con esa grilla, posiciona los conjuntos en un plano y obtiene un hallazgo crucial: hay diferencias sustantivas entre ellos. Un desafío puede exigir visión e inferencia a la vez, otro depender casi por completo del texto, otro centrarse en reconocimiento visual de baja complejidad. Promediar todo como si fueran pruebas equivalentes distorsiona la lectura. La elección del benchmark influye en la habilidad medida. Esta cartografía, además, permite explicar por qué un modelo que luce imbatible en una tabla puede flaquear en otra sin que haya “retroceso”, simplemente cambia lo que se evalúa.
La batería de estrés: quitar muletas, romper atajos
La columna vertebral del estudio es una serie de pruebas de estrés que, más que buscar la derrota del modelo, intentan despojarlo de señales superficiales para ver si queda comprensión sustantiva. El espíritu es simple: si un sistema parece entender, debería comportarse de modo estable cuando alteramos lo irrelevante y debería resentirse cuando eliminamos lo esencial. La práctica revela otra cosa.
La primera prueba explora la sensibilidad a la modalidad. Se evalúa a los modelos en desafíos diagnósticos con imagen y texto, y luego se repite sin la imagen. En un conjunto con fuerte dependencia visual se registran caídas claras. En otro, más “textual”, las puntuaciones se mantienen altas incluso sin ver nada. La interpretación es doble. Por un lado, hay modelos con puntajes similares que reaccionan de manera distinta cuando falta la visión, lo que indica diferencias ocultas que las listas no reflejan. Por otro, hay benchmarks que pueden resolverse leyendo la viñeta clínica y usando priors estadísticos, aunque la consigna diga “mire la imagen”. El mensaje es directo: la misma cifra en dos pruebas no significa que se haya logrado la misma pericia.
La segunda prueba endurece el filtro: se seleccionan manualmente preguntas que, por acuerdo de clínicos, no deberían resolverse sin mirar. Al retirarse la imagen, un sistema con integración genuina de modalidades tendría que caer casi a nivel de azar. No ocurre. La mayor parte de los modelos se mantiene muy por encima del 20 por ciento que implicaría adivinar al tuntún. Eso sugiere atajos. Puede tratarse de asociaciones aprendidas durante el preentrenamiento, de coocurrencias entre viñetas y diagnósticos típicos, o incluso de memorizar pares de pregunta y respuesta que circulan públicamente. No es “trampa” deliberada, es una propiedad esperable de redes gigantes que ingieren Internet. Aun así, para la clínica eso importa: aciertan por correlación, no porque hayan leído la placa.
La tercera prueba manipula el formato. Las opciones de respuesta se reordenan, sin cambiar contenidos. Un razonador estable no debería verse afectado. Sin embargo, aparecen caídas consistentes en el modo solo texto. Es una señal de dependencia superficial del formato, de posiciones comunes o patrones aprendidos en baterías previas. Curiosamente, cuando se restituyen las imágenes la precisión suele estabilizarse o mejorar levemente. La visión, al menos en esos escenarios, ayuda a escapar de heurísticas débiles, aunque no garantiza razonamiento correcto.
La cuarta prueba ataca a los distractores. Se sustituyen alternativas incorrectas por opciones irrelevantes o se introduce una opción “Desconocido”. Si el modelo realmente analiza contenido, la eliminación de distractores fuertes debería beneficiarlo y la presencia de “Desconocido” debería incentivar la abstención cuando falta evidencia. Lo que aparece, en cambio, es una mecánica de eliminación: en texto puro, al reemplazar más distractores por irrelevantes, la precisión cae hacia el azar, lo que sugiere que el sistema confía en patrones de familiaridad entre pregunta y opciones. En imagen más texto, quitar distractores suele facilitar la tarea y mejora mucho las tasas, lo cual se entiende. El dato fino es que “Desconocido” funciona como un distractor débil, no como una señal de prudencia: al introducirlo, varios modelos suben levemente su acierto, como si les resultara más fácil descartar.
La quinta prueba es quizá la más contundente para la multimodalidad: sustitución visual. Se toman ítems donde la respuesta correcta depende de rasgos visuales claros y se reemplaza la imagen original por otra que, manteniendo la misma pregunta y opciones, respalda un distractor. Si el sistema de veras integra visión y texto, debería revisar su predicción. Lo que se observa son derrumbes de precisión de treinta puntos o más en modelos líderes. La lectura es difícil de eludir: una parte del rendimiento surge de asociaciones visual–etiqueta aprendidas, no de una comprensión visual en contexto.
La sexta prueba mira la estructura del pensamiento. Se solicita “razonar paso a paso” y se auditan manualmente las justificaciones. Aquí emergen tres patrones peligrosos. Primero, explicaciones persuasivas pero fácticamente erróneas, donde el modelo “ve” hallazgos que no están. Segundo, razonamientos que empiezan mal anclados visualmente y se refuerzan a sí mismos, generando conclusiones seguras sobre observaciones fallidas. Tercero, cadenas ordenadas pero inútiles, que describen regiones o trazan pasos sin aportar información determinante para la decisión final. El resultado general es tibio: pedir cadena de pensamiento no mejora de manera consistente, y hasta puede degradar la exactitud en varias tareas.
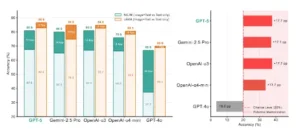
Las pruebas de estrés revelan una robustez de modalidad sobreestimada. Izquierda (Prueba de Estrés 1). La precisión disminuye al eliminar las imágenes de dos parámetros de diagnóstico (NEJM y JAMA), lo que revela diferencias ocultas en la sensibilidad de modalidad entre los modelos. Las caídas pronunciadas en NEJM, pero con un impacto mínimo en JAMA, sugieren una dependencia visual inconsistente entre los parámetros y los tipos de preguntas. Los segmentos claros muestran la precisión solo con texto; los segmentos oscuros marcan la caída con Imagen+Texto. Derecha (Prueba de Estrés 2). Rendimiento en 175 ítems de NEJM que requieren entrada visual. La mayoría de los modelos superan el 20% de referencia aleatoria, incluso sin imágenes, lo que indica una dependencia de claves abreviadas como valores previos, patrones de coocurrencia o pares de control de calidad memorizados. GPT-4o tiene un rendimiento inferior al azar debido al comportamiento de rechazo.
Lo que revelan los números sin tecnicismos
Más allá de la ingeniería del experimento, los hechos que interesan a una sala de redacción científica son claros. En desafíos diagnósticos con imagen y texto, hay sistemas que, al quitar la imagen, caen con fuerza en un conjunto y casi nada en otro. En un subconjunto especialmente curado para requerir visión, muchos modelos rinden muy por encima del azar aun sin ver, lo que apunta a pistas textuales o hábitos memorizados. Al reordenar opciones, la precisión en modo textual baja; con imágenes, en general se mantiene. Al degradar distractores de forma progresiva, en texto puro la exactitud se desploma; con imagen, sube como cabría esperar. Al sustituir la imagen por otra que justifica un distractor, la gran mayoría colapsa, prueba de que lo visual no siempre se integra con el texto como se proclama. Y cuando se examina el “por qué” de las respuestas, se detectan racionalizaciones convincentes pero infundadas.
El panorama no es nihilista. En promedio, las generaciones más recientes exhiben mejoras bajo pruebas de estrés con respecto a anteriores, incluso cuando se les quitan muletas. Hay progreso real, solo que menos glamoroso que el que sugiere una tabla promedio sin contexto. Si se extrajera una métrica de “robustez” que agregue la estabilidad bajo perturbaciones, los puntajes actuales quedarían lejos de un estándar clínico. La moraleja, entonces, no es que no se pueda usar IA en salud, sino que hay que elevar el listón de cómo la medimos y bajo qué condiciones se le permite opinar en problemas sensibles.
Qué miden realmente los benchmarks y por qué no son equivalentes
El aspecto más estratégico del estudio no está solo en desmitificar, sino en proponer un enfoque para catalogar y seleccionar evaluaciones. Con asesoría de médicos, se arma una rúbrica de diez dimensiones clínicas y visuales y se la aplica a un conjunto amplio de benchmarks. El resultado es un paisaje en el que algunas pruebas caen alto en complejidad visual y razonamiento, otras son mayormente textuales, otras son visuales pero de inferencia baja, y así. De esa cartografía se derivan recomendaciones obvias pero olvidadas. Los benchmarks deben tratarse como instrumentos diagnósticos, no como metas en sí mismos. Los informes de resultados deberían desagregar por dimensiones médicas pertinentes, en lugar de promediar. Y, sobre todo, la selección del conjunto de evaluación debe alinearse con el contexto de despliegue. Si se presenta un modelo generalista como listo para tareas de diagnóstico por imágenes porque obtiene altos puntajes en un desafío mayormente textual, se está comunicando de manera engañosa.
Esta distinción explica también divergencias notorias entre tareas. Sistemas que brillan en preguntas y respuestas visuales no necesariamente producen buenos informes radiológicos. La segunda actividad exige detección de hallazgos, ubicación precisa, uso disciplinado de terminología clínica y una estructura narrativa acorde al informe profesional. Allí, modelos específicos del dominio médico formados con pares imagen–texto pueden aventajar a generalistas supuestamente superiores en otras tablas. La moraleja es doble: no hay “un” número para la multimodalidad médica y, sin una taxonomía clara de lo que mide cada benchmark, las decisiones de adopción corren el riesgo de agarrarse de espejismos.
De la puntuación al procedimiento: cómo debería evaluarse la IA clínica
Si aceptamos que un 85 por ciento en una tabla no basta, la pregunta práctica es qué sí bastaría. La propuesta de fondo es incorporar pruebas de estrés como componente estándar de evaluación y reporte. Eso implica, de mínima, medir la estabilidad al retirar modalidades, al alterar formatos inocuos, al debilitar o reemplazar distractores, y al introducir sustituciones visuales controladas. La evaluación debe, además, auditar razonamientos, no para exigir “explicabilidad perfecta”, sino para rastrear si las justificaciones se apoyan en hallazgos reales y si el sistema reconoce cuándo carece de evidencia. Por último, los benchmarks tendrían que venir acompañados de metadatos que expliciten qué dimensiones clínicas exigen. Con ese combo, el sector puede pasar de la obsesión por la clasificación a un diagnóstico funcional de capacidades y límites.
Hay un elemento regulatorio implícito. Los marcos de autorización para software de diagnóstico no se contentan con exactitudes globales, exigen performance por subgrupos, análisis de error, robustez a variaciones de calidad y, cada vez más, criterios de seguridad ante la incertidumbre. Una IA que “aprende atajos” y sostiene un 80 por ciento promedio gracias a correlaciones espurias puede lucir fulgurante en una conferencia, pero en un hospital genera deuda de riesgo. La evaluación reformada no es un capricho académico, es una condición para la confianza pública. Y, de paso, alinea incentivos: cuando lo que se reporta y celebra es la estabilidad bajo perturbación y el comportamiento prudente ante evidencia incompleta, los equipos de desarrollo optimizan para eso.
Implicaciones sociales, tecnológicas y científicas
Socialmente, el mensaje es de prudencia responsable. La tentación de reemplazar pericia escasa con automatismos baratos es real, sobre todo en sistemas de salud con recursos tensos. Pero las pruebas muestran que la confianza ciega en rankings puede trasladar fragilidades, amplificar inequidades y erosionar la seguridad del paciente. Tecnológicamente, la agenda se reordena. Hace falta entrenamiento y validación con datos más ruidosos, sesiones adversariales que rompan patrones espurios, diseño de prompts que no incentiven racionalizaciones post hoc, y mecanismos de abstención calibrada. Es probable que veamos híbridos: modelos generalistas en la puerta de entrada y especialistas de dominio alineados con tareas de alto riesgo. Científicamente, el campo gana una brújula. La multimodalidad no es un bloque indivisible, sino un conjunto de habilidades que deben medirse por separado y con criterios clínicos. Un avance genuino no es subir tres puntos en un promedio, sino demostrar que, al quitar muletas, el sistema sigue de pie.
Dos cuadros para llevar a la sala de redacción
Pruebas de estrés y qué buscan
| Prueba | Qué cambia | Qué revela |
|---|---|---|
| Sensibilidad modal | Se quitan imágenes | Dependencia real de visión o uso de texto y priors |
| Necesidad modal | Ítems que exigen imagen, sin imagen | Atajos cuando debería caer a azar |
| Perturbación de formato | Reordenar opciones | Sesgos de posición, patrones superficiales |
| Reemplazo de distractores | Debilitar o sustituir alternativas | Eliminación por familiaridad vs análisis |
| Sustitución visual | Imagen que favorece un distractor | Integración visión–texto o asociaciones frágiles |
Qué miden, de verdad, los benchmarks
| Conjunto | Dependencia visual | Complejidad de inferencia |
|---|---|---|
| Desafíos inspirados en revistas clínicas | Alta a media, según ítem | Alta, integrar hallazgos con contexto |
| VQA radiológico | Alta | Baja a media, foco en localización y descripción |
| Ilustraciones biomédicas con preguntas | Media | Variable, con énfasis en reconocimiento |
| Generación de informes de tórax | Alta | Alta, hallazgos, ubicación y narrativa clínica |
Dos viñetas, no más, para equipos editoriales y clínicos
- Si el titular se apoya en rankings promediados, pida siempre la curva bajo perturbaciones: sin imágenes, con opciones reordenadas, con distractores alterados. La estabilidad es la noticia, no el número suelto.
- Si el caso de uso exige ver y razonar, exija evidencia de que el modelo falla con prudencia cuando falta la vista y que no inventa explicaciones al pedirle “paso a paso”.
Del espejismo a la confianza
Las ciencias de datos nos acostumbraron a creer que si una cifra sube, el sistema mejora. En medicina, esa conjetura es peligrosa. Un fármaco que supera a otro en una medida parcial puede empeorar la supervivencia si descuida efectos adversos. Una prótesis con excelente desempeño en laboratorio puede fallar en la calle. Con la inteligencia artificial ocurre algo análogo. La ilusión de preparación surge cuando confundimos aprobar exámenes con estar listo para la planta de internación. No se trata de volver a empezar, sino de reencuadrar. Hoy sabemos que, en pruebas diseñadas para quitar muletas, muchos modelos que encabezan tablas muestran fragilidad, dependencia de patrones espurios y razonamientos que suenan bien pero se sostienen en el aire. También sabemos que las mejoras genuinas existen, y que se ven mejor cuando medimos lo que importa: robustez, uso correcto de la evidencia, prudencia ante la falta de datos, capacidad de integrar vistas y contexto clínico.
La hoja de ruta es concreta. Catalogar benchmarks por lo que realmente miden. Reportar resultados desagregados por dimensiones clínicas, no un promedio cómodo. Incorporar pruebas de estrés como estándar de evaluación y auditoría previa a liberación. Penalizar la racionalización infundada y premiar el reconocimiento explícito de incertidumbre. Alinear despliegues con el tipo de habilidad demostrada y, en tareas de alto impacto, favorecer arquitecturas híbridas con especialistas de dominio. Si el campo adopta estas prácticas, haremos algo más importante que ganar la próxima tabla: construiremos un capital de confianza. Eso, y no el brillo de un ranking, es la base de una medicina asistida por máquinas que valga la pena.
Referencias
Gu, Y., Fu, J., Liu, X., Valanarasu, J. M. J., Codella, N., Tan, R., Liu, Q., Jin, Y., Zhang, S., Wang, J., Wang, R., Song, L., Qin, G., Usuyama, N., Wong, C., Hao, C., Lee, H., Sanapathi, P., Hilado, S., Jiang, B., Álvarez-Valle, J., Wei, M., Gao, J., Horvitz, E., Lungren, M., Poon, H., Vozila, P. The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks. Microsoft Research, Health & Life Sciences, 2025.

