
En el tejido silencioso de nuestra vida digital, una de las capacidades más transformadoras de la inteligencia artificial es también una de las más subestimadas: la habilidad de escuchar. La tecnología de conversión de voz a texto, o STT (Speech-to-Text), se ha convertido en una fuerza omnipresente, el motor invisible que impulsa desde los asistentes de voz en nuestros teléfonos hasta la transcripción automática de reuniones de trabajo y la subtitulación de contenido audiovisual. A medida que confiamos cada vez más en que las máquinas entiendan y documenten nuestra palabra hablada, la precisión de esa escucha deja de ser una simple comodidad para convertirse en una necesidad crítica. Un pequeño error en una transcripción médica, un matiz perdido en una declaración legal o una cifra malinterpretada en una llamada de resultados financieros pueden tener consecuencias profundas. La pregunta, por tanto, no es si las máquinas pueden oír, sino qué tan bien pueden entender.
Durante años, medir esta habilidad ha sido un desafío complejo. La métrica estándar de la industria es la Tasa de Error por Palabra, o WER (Word Error Rate), un cálculo aparentemente simple que cuantifica el porcentaje de palabras que una IA transcribe incorrectamente en comparación con una transcripción humana de referencia. Cuanto menor es el número, mejor es el oyente artificial. Sin embargo, no todas las escuchas son iguales. Transcribir a un único orador en un estudio silencioso es una tarea muy diferente a descifrar una reunión ruidosa con múltiples participantes hablando a la vez, o a comprender a un orador con un fuerte acento extranjero discutiendo terminología financiera compleja. Los benchmarks o pruebas de rendimiento existentes a menudo no lograban capturar esta diversidad del mundo real, dejando a los usuarios y desarrolladores con una visión incompleta de las verdaderas fortalezas y debilidades de cada modelo.
Para llenar este vacío y traer una nueva era de rigor al campo, la organización de investigación Artificial Analysis ha lanzado un nuevo y exhaustivo índice de rendimiento: el Artificial Analysis Word Error Rate Index (AA-WER). Este no es un examen más, sino una especie de decatlón para las IAs de transcripción. En lugar de una única prueba, el AA-WER sintetiza el rendimiento de los modelos a través de tres de los desafíos de audio más difíciles y representativos de los casos de uso del mundo real. Estos desafíos incluyen las actas multilingües y con acentos diversos del Parlamento Europeo (VoxPopuli), las llamadas de resultados corporativos llenas de jerga técnica y hablantes superpuestos (Earnings-22), y las grabaciones de reuniones con múltiples participantes y ruido de fondo capturadas con micrófonos a distancia (AMI-SDM).
Este nuevo índice compuesto proporciona, por primera vez, una única y robusta medida de la precisión de transcripción que permite una comparación justa y directa entre los principales contendientes del mercado. Al hacerlo, no solo revela quiénes son los campeones indiscutibles en la carrera por la escucha perfecta, sino que también desvela un panorama mucho más matizado de especialistas y generalistas, y la fascinante relación entre el precio y la precisión. Este artículo se sumergirá en los hallazgos de este nuevo y trascendental benchmark, analizará a los ganadores, explorará las complejidades que revela y reflexionará sobre lo que esta nueva vara de medir significa para el futuro de la interacción entre humanos y máquinas.
El decatlón del audio: anatomía de un benchmark para el mundo real
La filosofía detrás del índice AA-WER es que una verdadera prueba de la capacidad de escucha de una IA no puede provenir de un entorno de laboratorio prístino. Debe forjar a los modelos en el fuego de la complejidad del mundo real. La elección de los tres conjuntos de datos que componen el índice no es casual, cada uno está diseñado para probar un conjunto diferente de habilidades y para exponer debilidades que otras pruebas podrían pasar por alto. Juntos, forman un examen integral que evalúa la robustez y la versatilidad de un modelo de una manera que ningún conjunto de datos por sí solo podría lograr.
El primer evento de este decatlón es el conjunto de datos VoxPopuli, que podríamos denominar «el crisol multilingüe». Este compendio se extrae de las actas del Parlamento Europeo, un entorno acústico y lingüístico de una complejidad formidable. Los modelos deben enfrentarse no solo a un lenguaje formal y a una terminología política específica, sino también a una amplia gama de acentos de toda Europa, a menudo de hablantes no nativos de inglés. La calidad del audio puede variar, y la cadencia de los discursos parlamentarios presenta un desafío único. Un modelo que sobresale aquí demuestra una capacidad excepcional para la generalización y una robusta comprensión de la fonética en condiciones diversas, una habilidad crucial para cualquier aplicación de alcance global.
La segunda prueba es el conjunto de datos Earnings-22, o «la torre de babel financiera». Este desafío simula uno de los casos de uso de transcripción más valiosos y de mayor riesgo: las llamadas de resultados corporativos. Aquí, la dificultad no reside tanto en los acentos, sino en la densidad de la jerga técnica, los acrónimos financieros y los datos numéricos que deben ser transcritos con una precisión absoluta. Además, estas llamadas a menudo presentan a múltiples oradores, analistas y ejecutivos, que pueden hablar rápidamente e interrumpirse unos a otros. Un error en la transcripción de una cifra de ingresos o en la perspectiva de un analista puede tener consecuencias significativas. Un modelo que triunfa en este entorno demuestra una comprensión contextual profunda y una especialización en el dominio del lenguaje corporativo.
Finalmente, la tercera y quizás más dura prueba del decatlón es el conjunto de datos AMI-SDM, que representa «el eco de la realidad». Este conjunto de datos consiste en grabaciones de reuniones de varias personas, pero con una dificultad añadida que simula la mayoría de los entornos de oficina del mundo real: el audio se captura con micrófonos a distancia, no con micrófonos individuales para cada participante. Esto introduce una serie de desafíos formidables.
- El ruido de fondo, como el tecleo, el movimiento de papeles o las conversaciones lejanas.
- La superposición de voces, que el sistema debe ser capaz de desenredar y atribuir correctamente.
Un modelo que obtiene una buena puntuación en el AMI-SDM es un verdadero campeón en el manejo de las condiciones acústicas más adversas. Demuestra tener la capacidad no solo de oír las palabras, sino de separar la señal del ruido, una habilidad fundamental para cualquier aplicación destinada a funcionar en los espacios desordenados y ruidosos en los que vivimos y trabajamos. Al promediar el rendimiento en estas tres disciplinas tan dispares, el AA-WER ofrece una visión panorámica y exigente de lo que realmente significa ser un transcriptor de IA de élite.
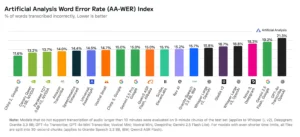
El podio de los oyentes universales: los campeones del AA-WER
Con las reglas del juego establecidas, los resultados del primer índice AA-WER revelan un claro ganador en la categoría general, así como un fascinante panorama competitivo. En la cima del podio, demostrando la mejor combinación de habilidades en las tres difíciles disciplinas, se encuentra el modelo Chirp 2 de Google, con una Tasa de Error por Palabra del 11.6%. Esto significa que, en promedio, de cada 100 palabras transcritas en estos desafiantes conjuntos de datos, el modelo de Google se equivoca en menos de 12. Es un testimonio de la robustez y la versatilidad de su arquitectura, capaz de navegar tanto la diversidad de acentos como la jerga técnica y los entornos ruidosos.
El podio, sin embargo, revela una fuerte competencia, especialmente por parte de un jugador que ha invertido masivamente en este espacio: NVIDIA. La compañía de semiconductores y computación de IA coloca a dos de sus modelos entre los cinco primeros, una hazaña notable.
Canary Qwen 2.5B ocupa el segundo lugar con un impresionante 13.2% de WER, seguido de cerca por su otro modelo, Parakeet TDT 0.6B V2, en tercer lugar con un 13.7%. La presencia de dos modelos distintos en la élite sugiere que NVIDIA ha desarrollado una base tecnológica muy sólida y adaptable para el reconocimiento de voz, capaz de funcionar bien en una amplia gama de condiciones de audio.
Completando los cinco primeros puestos se encuentran dos gigantes de la industria de la nube y la IA:
Amazon Transcribe de AWS, con un 14.0%, y Speechmatics Enhanced, con un 14.4%. Su sólida posición demuestra que el mercado de la transcripción de alta calidad es un campo de batalla muy reñido, con varios proveedores ofreciendo soluciones de un nivel de rendimiento muy similar.
Un hallazgo particularmente interesante del análisis se refiere a uno de los nombres más conocidos en la IA: OpenAI. Su modelo,
GPT-4o Transcribe, a pesar de su potencia en otras áreas, se sitúa más abajo en la clasificación, con un 21.3% de WER. La razón, según el informe, es una elección de diseño deliberada. El modelo de OpenAI tiende a «suavizar» las transcripciones, eliminando palabras de relleno, corrigiendo errores gramaticales menores y, en general, produciendo un texto más legible y fluido. Si bien esto puede ser deseable para ciertos usos, perjudica su precisión palabra por palabra en comparación con la transcripción humana literal, especialmente en el habla menos estructurada de las reuniones y las llamadas de resultados. Este es un ejemplo perfecto de un compromiso de diseño: una compensación entre la fidelidad literal y la legibilidad final, y demuestra por qué un benchmark riguroso como el AA-WER es tan importante para revelar estas sutilezas.

Campeones especialistas: quién gana en cada disciplina
Si el índice AA-WER general corona al campeón del decatlón, el análisis de los resultados en cada uno de los eventos individuales nos revela a los campeones especialistas. Aquí, la imagen se vuelve aún más matizada y revela que el «mejor» modelo depende en gran medida de la naturaleza específica del desafío de audio. Un análisis de los resultados por cada conjunto de datos muestra que diferentes modelos han sido optimizados, ya sea de forma deliberada o emergente, para sobresalir en condiciones particulares.
En la prueba de VoxPopuli, con sus procedimientos parlamentarios europeos y su diversidad de acentos, los modelos que demuestran una mayor destreza son NVIDIA Canary Qwen 2.5B y Qwen3 ASR Flash de Alibaba. Su liderazgo en esta categoría sugiere que sus arquitecturas son particularmente eficaces en el manejo de una amplia variedad de fonéticas y prosodias, lo que los convierte en una opción ideal para aplicaciones que necesitan servir a una base de usuarios global y multilingüe.
Cuando la competición se traslada al denso mundo de las llamadas corporativas de Earnings-22, el podio cambia. Aquí, los modelos que brillan son Scribe de ElevenLabs, Gemini 2.5 Pro de Google y Voxtral Small. Su éxito en este dominio, caracterizado por el lenguaje técnico y financiero, indica que han sido entrenados con conjuntos de datos que les dan una ventaja en la comprensión de la jerga específica de la industria. Para las empresas de los sectores financiero, legal o tecnológico, estos modelos especialistas podrían ofrecer un rendimiento superior al del campeón general.
Finalmente, en la prueba más dura de todas, el desafiante entorno de micrófonos a distancia de AMI-SDM, emergen nuevos líderes. Chirp 2 de Google y Granite 3.3-8b de IBM son los que mejor se desenvuelven en el caos de las conversaciones superpuestas y el ruido de fondo. Su rendimiento superior en estas condiciones demuestra una especialización en el procesamiento de señales de audio y en la separación de hablantes, capacidades cruciales para cualquier aplicación que pretenda transcribir reuniones del mundo real, conferencias o cualquier evento con una acústica no controlada. Esta especialización por disciplina demuestra que no existe un único «mejor» modelo para todas las tareas. La elección de la herramienta de transcripción adecuada depende fundamentalmente del contexto y del tipo de audio que se vaya a procesar, una conclusión que solo un benchmark multifacético como el AA-WER puede hacer tan evidente.
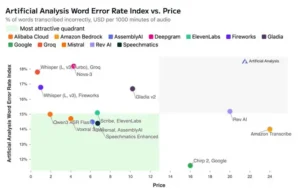
El precio de la precisión: un análisis del mercado
En el mundo de la tecnología de vanguardia, el rendimiento a menudo tiene un precio. El análisis del índice AA-WER en comparación con el costo de cada servicio revela una visión fascinante de la economía del mercado de la conversión de voz a texto y confirma una tendencia esperada: por lo general, una mayor precisión requiere una mayor inversión. El gráfico que cruza la Tasa de Error por Palabra con el precio por cada 1000 minutos de audio muestra una correlación clara: a medida que la tasa de error disminuye (es decir, la calidad aumenta), el precio tiende a subir.
El líder del índice, Chirp 2 de Google, que ostenta la tasa de error más baja, se sitúa también entre los modelos más caros del mercado. Esto demuestra que existe un «premium» por el rendimiento de vanguardia. Las empresas y los usuarios que requieren el más alto nivel de precisión para aplicaciones críticas están dispuestos a pagar más por la fiabilidad que ofrecen los modelos de élite. En el otro extremo del espectro de precios, el análisis destaca a los proveedores de inferencia de bajo costo como Fireworks y Groq, que ofrecen acceso al potente modelo Whisper Large v3 de OpenAI a precios muy competitivos. Esto juega un papel crucial en la democratización de la tecnología, permitiendo a desarrolladores y startups más pequeñas acceder a una capacidad de transcripción de alta calidad sin incurrir en costos prohibitivos.
Sin embargo, la zona más interesante del gráfico es la que Artificial Analysis denomina el «cuadrante más atractivo». En esta área se encuentran los modelos que ofrecen un equilibrio excepcional entre un bajo índice de error y un precio moderado. Modelos como Qwen3 ASR Flash, Scribe de ElevenLabs, Voxtral Small y Speechmatics Enhanced residen en este punto óptimo, proporcionando un rendimiento cercano al de los líderes del mercado pero con una estructura de costos más accesible. Para una gran parte de las aplicaciones empresariales, estos modelos representan la propuesta de valor más inteligente, ofreciendo una precisión más que suficiente para la mayoría de los casos de uso sin el sobreprecio de los sistemas de rendimiento absoluto. Este análisis económico, por tanto, añade una capa crucial de pragmatismo a la evaluación, recordando que en el mundo real, la decisión de adoptar una tecnología nunca se basa solo en el rendimiento, sino en un cuidadoso equilibrio entre la calidad, el costo y el valor.
Hacia una escucha más perfecta
El lanzamiento del Índice de Tasa de Error por Palabra de Artificial Analysis marca un punto de inflexión en la forma en que medimos y comprendemos la capacidad de las máquinas para escuchar. Al pasar de benchmarks aislados a un índice compuesto y basado en los desafíos del mundo real, la industria gana una herramienta de una transparencia y una utilidad sin precedentes. Nos proporciona un lenguaje común y una vara de medir estandarizada para evaluar el progreso, comparar las ofertas y, en última instancia, tomar decisiones más informadas.
Los hallazgos de este primer informe son profundos. Nos muestran que, aunque existe un claro líder general en la figura de Chirp 2 de Google, el panorama es en realidad un rico ecosistema de generalistas y especialistas. Revela que la carrera por la precisión es también una carrera de compromisos, donde la fidelidad literal a veces compite con la legibilidad, y donde el costo y el rendimiento deben ser sopesados cuidadosamente. Más que coronar a un único rey, el AA-WER nos proporciona el programa de una competición olímpica, donde diferentes atletas digitales brillan en diferentes disciplinas.
Para los usuarios y las empresas, esta nueva capa de transparencia es una bendición. Permite elegir la herramienta adecuada para el trabajo adecuado, ya sea un modelo optimizado para acentos para un centro de llamadas global, un especialista en jerga financiera para una empresa de inversión, o un campeón de entornos ruidosos para grabar las reuniones de equipo. A medida que esta metodología de evaluación se consolide y se expanda, impulsará una mayor competencia y una innovación más enfocada, acelerando el camino hacia el objetivo final: una inteligencia artificial que pueda escuchar, entender y transcribir nuestra palabra hablada con la misma facilidad y precisión que un ser humano. La carrera por la escucha perfecta está en marcha, y ahora, por fin, tenemos un marcador claro para seguirla.
Fuentes
Artificial Analysis. (2025). Announcing the Artificial Analysis Word Error Rate Index (AA-WER).
Artificial Analysis. (2025). Speech to Text Benchmarking.
Artificial Analysis. (2025). Measuring AI Ability to Complete Long Tasks.

