

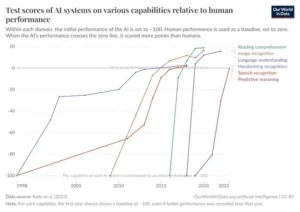
Hemos sido testigos de un milagro digital, un florecimiento de la inteligencia en el silicio que ha redefinido los límites de lo posible en un abrir y cerrar de ojos. Las inteligencias artificiales de hoy son virtuosas de lo instantáneo. Pueden componer un soneto en el estilo de Shakespeare, depurar un fragmento de código con una lógica impecable o resumir un denso informe financiero en segundos. Son capaces de superar exámenes de abogacía, medicina y finanzas con puntuaciones que humillan a la mayoría de los expertos humanos. Esta explosión de habilidades, documentada febrilmente en tablas de clasificación que miden el conocimiento y la destreza en tareas breves y bien definidas, ha alimentado una narrativa de progreso exponencial, una sensación de que nos acercamos a pasos agigantados a una inteligencia artificial verdaderamente general y autónoma. Son los prodigios del laboratorio, los genios del sprint cognitivo, capaces de deslumbrar con cualquier tarea que se les presente, siempre y cuando esa tarea dure apenas unos minutos.
Sin embargo, una vez que estos prodigios salen del entorno protegido del laboratorio y se enfrentan a la desordenada y prolongada realidad de un problema del mundo real, la brillantez a menudo se desvanece. La misma IA que puede escribir una función de código perfecta en treinta segundos se muestra irremediablemente incapaz de construir una aplicación sencilla a lo largo de una tarde. El modelo que puede responder a cualquier pregunta de un examen de historia es incapaz de escribir un ensayo de investigación coherente que requiera consultar fuentes, estructurar un argumento y refinar un borrador durante varias horas. Esta desconcertante brecha entre la habilidad en tareas cortas y la incompetencia en tareas largas es el secreto a voces de la industria de la IA, el abismo que separa la «capacidad» de la verdadera «autonomía». Es la diferencia, como ha propuesto un enigmático y muy respetado laboratorio de seguridad e investigación en IA, entre un interno brillante y un empleado de confianza. El interno puede ejecutar cualquier instrucción específica que se le dé con una velocidad y precisión asombrosas, pero requiere una supervisión constante. El empleado, en cambio, puede recibir un objetivo de alto nivel y trabajar de forma autónoma durante horas, o incluso días, para conseguirlo.
Es precisamente para medir y, en última instancia, cerrar esta brecha que este laboratorio ha presentado una nueva y revolucionaria metodología de evaluación. Su trabajo, detallado en un reciente informe que está causando un profundo revuelo en la comunidad tecnológica, propone un cambio radical en la forma en que medimos la inteligencia de las máquinas. Argumentan que los exámenes estandarizados actuales, aunque útiles, son fundamentalmente insuficientes para predecir la utilidad y el impacto real de la IA. En su lugar, proponen un nuevo estándar de oro: la finalización de tareas largas y autónomas, o ALC (Autonomous Long-task Completion). No se trata de un nuevo conjunto de datos con preguntas de opción múltiple, sino de un examen final, una prueba de resistencia cognitiva diseñada para medir lo que realmente importa: la capacidad de una IA para llevar a cabo un proyecto complejo de principio a fin, sin supervisión humana.
La propuesta es tan elegante en su concepción como rigurosa en su ejecución. Consiste en asignar a una IA una tarea de alto nivel que a un experto humano le llevaría entre una y ocho horas completar, como «elaborar un informe de análisis de mercado sobre el sector fintech en Argentina» o «desarrollar una aplicación web sencilla que cumpla estas especificaciones». A la IA se le proporciona un entorno informático realista y seguro, con acceso a un navegador web, un editor de código y una terminal de comandos, las mismas herramientas que usaría un profesional humano. La evaluación es brutalmente simple y binaria: éxito o fracaso. No hay crédito parcial por casi terminar o por hacer un buen intento. O la IA produce un resultado final que cumple con todos los criterios de una rúbrica detallada, o falla. La puntuación resultante, el ALC-Score, es el porcentaje de veces que el modelo tiene éxito. Este enfoque revela una verdad aleccionadora: los modelos más potentes de la actualidad, aquellos que dominan las tablas de clasificación de tareas cortas, tienen un ALC-Score cercano a cero. Son internos brillantes, pero aún no están listos para ser empleados. Este artículo se sumergirá en las profundidades de esta nueva frontera de la evaluación de la IA, explorando por qué las viejas métricas ya no son suficientes, cómo funciona exactamente esta nueva prueba de maratón cognitivo y qué nos dicen sus primeros y sombríos resultados sobre el verdadero estado de la inteligencia artificial y el largo camino que aún queda por recorrer hacia la autonomía genuina.

La ilusión de la inteligencia: por qué los exámenes estandarizados fallan en la IA
Durante la última década, la narrativa del progreso en la inteligencia artificial ha sido contada a través de las puntuaciones de los benchmarks. Estos son, en esencia, los exámenes estandarizados que diseñamos para medir la «inteligencia» de nuestras creaciones. Al igual que los exámenes SAT o GMAT para los humanos, estas pruebas buscan cuantificar la habilidad en un conjunto de dominios bien definidos. El más famoso de ellos es el MMLU (Massive Multitask Language Understanding), una batería de preguntas de opción múltiple que abarca 57 asignaturas, desde la física y la historia hasta la ética profesional. Cuando un nuevo modelo de lenguaje es anunciado, su puntuación en el MMLU es a menudo el titular, una métrica única que pretende encapsular su vasto conocimiento del mundo. Otro pilar de la evaluación es HumanEval, una prueba en la que se le pide a la IA que escriba funciones de código para resolver problemas lógicos, midiendo su destreza como programadora.
Estas pruebas han sido increíblemente útiles. Han proporcionado un objetivo claro para los investigadores, han estimulado la competencia y nos han permitido seguir el ritmo vertiginoso del progreso. Han demostrado, sin lugar a dudas, que los modelos actuales han alcanzado y, en muchos casos, superado el nivel humano en la recuperación y aplicación de conocimiento en tareas atómicas y bien estructuradas. Nos han dado la capacidad de medir, con una precisión cada vez mayor, la «capacidad» de un modelo, su potencial para ejecutar una instrucción específica y delimitada en el tiempo. Sin embargo, esta misma focalización en las capacidades ha creado una ilusión de competencia general, un espejismo que se desvanece tan pronto como se pide al modelo que haga algo más que responder a una pregunta de examen.
El problema fundamental de estos benchmarks es que no miden las habilidades que son la esencia de la autonomía. La capacidad de completar una tarea larga y compleja no depende únicamente del conocimiento o de la lógica, sino de un conjunto de habilidades metacognitivas que los exámenes actuales ignoran por completo. Entre ellas se encuentran la planificación a largo plazo, la capacidad de descomponer un objetivo de alto nivel en una secuencia de subtareas manejables. También está la autogestión y la corrección de errores, la habilidad de darse cuenta de que un enfoque no está funcionando, de diagnosticar el problema y de pivotar hacia una nueva estrategia sin necesidad de una intervención externa. Y quizás la más importante sea la persistencia y la resiliencia, la capacidad de mantener el «foco» en un objetivo a lo largo de horas de trabajo, superando obstáculos y distracciones.
Los humanos desarrollamos estas habilidades a través de años de educación y experiencia profesional. Un examen de opción múltiple no puede medir la capacidad de un estudiante para escribir una tesis doctoral, del mismo modo que el MMLU no puede predecir la capacidad de una IA para elaborar un informe de mercado. Al optimizar los modelos para que sobresalgan en estas pruebas cortas, la industria ha creado, sin quererlo, una generación de «genios frágiles». Son sistemas que pueden demostrar una brillantez deslumbrante en ráfagas de dos minutos, pero que se desmoronan ante la perspectiva de un proyecto de dos horas. Carecen del andamiaje cognitivo necesario para gestionar la complejidad que emerge con el tiempo. El trabajo de este laboratorio de investigación, por tanto, no es solo una propuesta de un nuevo examen, es una crítica fundamental a la filosofía de evaluación que ha dominado el campo. Es un llamado a dejar de medir el conocimiento en un vacío y empezar a medir la capacidad de aplicar ese conocimiento de forma autónoma y sostenida en un entorno que se asemeja, aunque sea de lejos, a la complejidad del mundo real.
La arquitectura de la autonomía: diseñando el examen final para una mente digital
La respuesta de este laboratorio al desafío de medir la autonomía es una metodología que es tanto una prueba como una filosofía. Su diseño se aleja deliberadamente de la simplicidad escalable de los benchmarks de preguntas y respuestas para abrazar la complejidad y el desorden de un entorno de trabajo realista. Cada componente de la evaluación ha sido cuidadosamente diseñado para probar las habilidades metacognitivas que los modelos actuales carecen, convirtiéndolo en un verdadero examen final para una mente digital.
El primer pilar de la evaluación es la naturaleza de las tareas. Estas son definidas como objetivos de alto nivel que requieren entre una y ocho horas de trabajo para un humano competente y bien remunerado. Los ejemplos son ilustrativos: «Realiza un análisis de mercado exhaustivo sobre las cinco principales empresas del sector de la computación en la nube, incluyendo un análisis FODA para cada una y una recomendación de inversión justificada». O «Encuentra tres vulnerabilidades de seguridad en esta base de código de código abierto y escribe un informe detallado con pruebas de concepto y sugerencias de mitigación». Estas no son preguntas con una única respuesta correcta. Son proyectos que requieren investigación, análisis, síntesis, creatividad y juicio. Exigen que la IA no solo recupere información, sino que la estructure, la evalúe y genere un producto de trabajo original y valioso.
El segundo pilar es el entorno de trabajo. A la IA no se le presenta un simple cuadro de texto, sino que se le da acceso a un entorno informático virtualizado y seguro. Este entorno replica fielmente el espacio de trabajo de un profesional del conocimiento moderno. Incluye un sistema operativo con una terminal de línea de comandos, un navegador web para acceder a la internet pública y un editor de código para escribir y ejecutar programas. Este es un punto crucial. La IA debe aprender a usar sus herramientas. Debe saber cómo realizar una búsqueda en Google, cómo navegar por la documentación de una API, cómo instalar una biblioteca de software o cómo depurar un script que no funciona. Estas habilidades, que para un humano son una segunda naturaleza, representan un desafío monumental para los modelos de lenguaje, que deben traducir su conocimiento abstracto en una secuencia de acciones concretas y a menudo frágiles en un entorno digital.
El tercer y quizás más importante pilar es el criterio de evaluación. El éxito en una tarea de este tipo es binario: éxito o fracaso. Al final del tiempo asignado, el producto de trabajo final de la IA (el informe de mercado, el análisis de vulnerabilidades, etc.) se compara con una rúbrica de evaluación extremadamente detallada, la misma que se usaría para juzgar el trabajo de un empleado humano. Esta rúbrica puede tener docenas de criterios, desde la precisión de los datos y la coherencia del argumento hasta la calidad de la escritura y el formato del documento. Si el trabajo cumple con todos y cada uno de los criterios, la tarea se considera un «éxito». Si falla incluso en uno de ellos, se considera un «fracaso». No hay crédito parcial. Esta regla de «todo o nada» es deliberadamente implacable, porque refleja la realidad del trabajo de alto valor. Un informe de mercado con una conclusión brillante pero con datos incorrectos es inútil. Un programa que funciona el 99% del tiempo pero tiene un fallo de seguridad crítico es un desastre. La evaluación binaria es la única forma de medir si un sistema puede realmente automatizar una tarea de principio a fin con un nivel de fiabilidad que permita prescindir de la supervisión humana.
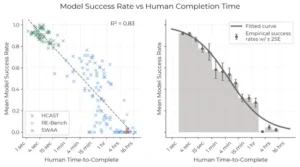
Este gráfico demuestra la fuerte correlación negativa que existe entre la complejidad de una tarea (medida por el tiempo que le toma a un humano) y la tasa de éxito de los modelos de IA, mostrando cómo su rendimiento se desploma a medida que las tareas se alargan de segundos a horas.
La aleccionadora realidad: el abismo entre la capacidad y la consecución
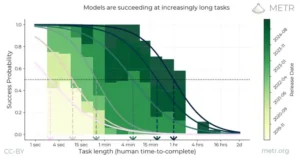
Con este nuevo y exigente examen en la mano, el equipo de investigación se dispuso a evaluar el estado de la autonomía en la generación actual de inteligencias artificiales. Los resultados son tan claros como aleccionadores. Los modelos más potentes de la actualidad, aquellos que regularmente alcanzan puntuaciones cercanas a la perfección en los benchmarks de tareas cortas, muestran una tasa de éxito cercana a cero por ciento en estas maratones cognitivas. Son capaces de iniciar las tareas, de realizar búsquedas web o de escribir las primeras líneas de código, pero invariablemente se desvían, se atascan en bucles de error, pierden de vista el objetivo general o producen un resultado final que es superficial e incompleto. Son, en efecto, internos brillantes que pueden realizar ráfagas de trabajo espectacular, pero que carecen de la tenacidad y la visión estratégica para llevar un proyecto a su conclusión.
Este fracaso casi total no es un indicador de que los modelos de IA no sean potentes. Al contrario, subraya que la autonomía es una propiedad emergente, una habilidad cualitativamente diferente que no surge automáticamente de la simple acumulación de conocimiento. Lo que esta evaluación revela es el conjunto de barreras cognitivas que los sistemas actuales deben superar para dar el salto de la capacidad a la consecución. Una de las principales es la planificación a largo plazo. Los modelos actuales operan con una «ventana de contexto» limitada, lo que les dificulta mantener un plan coherente a lo largo de miles de pasos. Otra es la fragilidad de la interacción con las herramientas. Un pequeño cambio en la interfaz de una página web o una respuesta inesperada de un comando en la terminal pueden desbaratar por completo el plan del modelo, que a menudo carece de la resiliencia para recuperarse de estos contratiempos del mundo real.
Es en este contexto que los investigadores introducen un concepto de una importancia capital para el futuro de la economía y la sociedad: la «línea del autómata» (Automaton line). Esta no es una línea general para toda la IA, sino un umbral específico para cada tarea. Se define como el nivel de rendimiento (por ejemplo, un 90% de tasa de éxito en una tarea ALC) en el que un sistema de IA puede automatizar de manera fiable el trabajo de un experto humano en ese dominio. Cuando un modelo cruce la línea del autómata para la tarea de «preparar una declaración de impuestos estándar», significará que el trabajo de un gestor fiscal para esa tarea específica puede ser, en gran medida, automatizado.
La importancia de medir la proximidad a esta línea no puede ser subestimada. Nos proporciona, por primera vez, una vara de medir empírica y prospectiva sobre el impacto económico real de la IA. En lugar de especular vagamente sobre la sustitución de empleos, nos permite hacer preguntas mucho más precisas: ¿a qué distancia está el mejor modelo actual de cruzar la línea del autómata para un paralegal, un programador junior o un analista de marketing? La aleccionadora realidad que nos muestra la investigación es que, para la mayoría de las tareas de conocimiento complejas, esa distancia es todavía inmensa. Sin embargo, el mero hecho de que ahora tengamos una forma de medirla es un paso monumental. Nos permite seguir el progreso de manera transparente y prepararnos, como sociedad, para las disrupciones que ocurrirán, no como una ola repentina e inesperada, sino como una serie de umbrales predecibles y cuantificables.
Trazando el camino hacia la verdadera agencia artificial
La investigación sobre la finalización de tareas largas y autónomas es mucho más que la propuesta de un nuevo benchmark. Es un manifiesto que aboga por una mayor madurez y honestidad intelectual en el campo de la inteligencia artificial. Nos obliga a mirar más allá de las métricas de vanidad y las demostraciones deslumbrantes para enfrentarnos a la difícil y compleja realidad de construir una autonomía genuina. Al iluminar el vasto abismo que todavía existe entre la capacidad momentánea y la consecución sostenida, este trabajo nos proporciona un mapa mucho más realista del estado actual de la tecnología y una hoja de ruta más clara para el futuro.
La relevancia de este enfoque trasciende la ingeniería de software y la investigación académica. Tiene profundas implicaciones para la seguridad de la IA. La capacidad de un sistema para actuar de forma autónoma durante largos períodos de tiempo es una de las condiciones previas para los riesgos más serios asociados con la inteligencia artificial avanzada. Entender, medir y, en última instancia, controlar esta capacidad no es una cuestión de optimización del rendimiento, es una necesidad fundamental para garantizar que el desarrollo de la IA siga siendo seguro y beneficioso para la humanidad. Un termómetro que mida la fiebre de la autonomía es el primer paso para poder controlarla.
Para las empresas y los profesionales, este nuevo marco ofrece una perspectiva mucho más sensata para evaluar y adoptar la tecnología. En lugar de dejarse llevar por las puntuaciones en benchmarks abstractos, los líderes empresariales pueden empezar a preguntarse: «¿cuál es el ALC-Score de este modelo para las tareas específicas que son cruciales para mi negocio?». Este cambio de enfoque llevará a despliegues de IA más realistas, efectivos y con un retorno de la inversión mucho más claro. Fomenta una visión de la IA no como una solución mágica y monolítica, sino como un conjunto de herramientas cuya autonomía debe ser evaluada en el contexto específico en el que se pretende utilizar.
En última instancia, esta nueva metodología nos invita a redefinir nuestra propia relación con estas mentes digitales que estamos creando. Al pasar de ser meros instructores que dan órdenes específicas a ser mentores que asignan objetivos de alto nivel, estamos fomentando el desarrollo de una nueva forma de agencia en el mundo. El camino hacia la inteligencia artificial verdaderamente autónoma será largo y lleno de desafíos. Pero gracias a este trabajo pionero, ahora tenemos una brújula. Una que no solo nos indica dónde estamos, sino que nos ayuda a navegar con mayor sabiduría y previsión hacia el profundo y transformador futuro que nos espera.
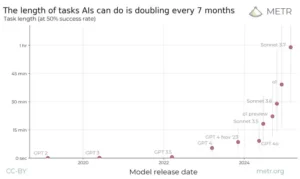
Este gráfico demuestra que la capacidad de la inteligencia artificial para completar tareas autónomas ha crecido exponencialmente, duplicando la complejidad de las tareas que puede resolver aproximadamente cada siete meses desde 2019.
Fuentes
Metr. (2025). Github Repo.
Metr. (2025) Research
Hendrycks, D., et al. (2021). Measuring Massive Multitask Language Understanding.
Chen, M., et al. (2021). Evaluating Large Language Models Trained on Code.
Thomas Kwa, et al. (2025) Measuring AI Ability to Complete Long Tasks.
Sutton, R. S. (2019). The Bitter Lesson.

