
La historia del descubrimiento científico es una crónica de la paciencia humana. Es la imagen de Johannes Kepler pasando una década inmerso en las tablas astronómicas de Tycho Brahe para descifrar las leyes del movimiento planetario. Es Marie Curie en su gélido cobertizo, removiendo pacientemente toneladas de pechblenda para aislar una mota de radio. Es el esfuerzo lento, metódico y a menudo frustrante de la mente humana al enfrentarse a la abrumadora complejidad del universo, un proceso en el que cada destello de genialidad está separado por años, a veces décadas, de laborioso trabajo. Durante mucho os, hemos soñado con acelerar este ritmo, con crear herramientas que no solo nos ayuden a calcular más rápido o a observar más lejos, sino que participen activamente en el acto mismo del descubrimiento. Con la llegada de la inteligencia artificial, ese sueño pareció al alcance de la mano, pero siempre ha chocado con una barrera fundamental: nuestras creaciones digitales, aunque brillantes para encontrar patrones en datos existentes, carecían de la chispa esencial de la indagación científica. Podían responder preguntas, pero no sabían cómo formular las suyas.
Ahora, desde los laboratorios de Google Research, emerge una nueva arquitectura de inteligencia artificial que promete derribar esta última frontera. Su nombre es Deep Researcher, y su propósito es tan ambicioso como parece: emular el ciclo completo del descubrimiento científico. No se trata de una herramienta de análisis de datos más, ni de un modelo de lenguaje con más conocimiento enciclopédico. Es un sistema diseñado para funcionar como un verdadero investigador, un colega digital capaz de sumergirse en un campo de estudio, generar hipótesis novedosas y originales, diseñar experimentos para ponerlas a prueba y, finalmente, interpretar los resultados para refinar su comprensión del mundo. Es un intento de automatizar no solo las respuestas, sino la curiosidad misma. Esta capacidad no surge de un simple aumento de la potencia de cálculo, sino de una innovación técnica profunda y elegante conocida como difusión en tiempo de prueba o Test-Time Diffusion.

Para el lector no especializado, la explicación de esta tecnología puede parecer arcana, pero su concepto es de una belleza sorprendente. Imaginemos los modelos de IA convencionales como estudiantes que han memorizado a la perfección una biblioteca entera de libros de texto. Pueden recitar cualquier dato y resolver cualquier problema que ya esté en los libros, pero se paralizan ante una pregunta que requiere pensar más allá de su entrenamiento. La difusión en tiempo de prueba, en cambio, dota a la IA de la capacidad de un estudiante que no solo ha leído los libros, sino que ha internalizado los principios fundamentales de la materia. Al enfrentarse a un problema nuevo, este sistema no busca una respuesta memorizada, sino que aplica esos principios en tiempo real, adaptando su proceso de razonamiento a los matices específicos del desafío que tiene delante. Es la diferencia entre saber y comprender, entre recitar y razonar.
El corazón de Deep Researcher es, por tanto, esta capacidad de adaptación dinámica. El sistema no es una entidad estática, sino un proceso fluido que refina su propio «pensamiento» mientras trabaja. Esta innovación conceptual transforma a la inteligencia artificial de un erudito omnisciente pero pasivo a un explorador activo y adaptable. Puede sumergirse en la complejidad de la biología molecular o la ciencia de los materiales no como un archivo, sino como un participante, capaz de especular, experimentar y aprender en un bucle de retroalimentación continua que imita, y en algunos aspectos supera, la metodología científica humana. Este artículo se adentrará en la arquitectura de este científico artificial, explorará la ingeniosa mecánica de la difusión en tiempo de prueba, desvelará las aplicaciones que podrían acelerar el progreso humano y reflexionará sobre el profundo cambio filosófico que supone para el rol del científico en el siglo veintiuno.
El cuello de botella del descubrimiento
Para comprender la magnitud de lo que Deep Researcher pretende solucionar, primero debemos apreciar la naturaleza del desafío científico moderno. La imagen romántica del genio solitario ha dado paso a una realidad de equipos multidisciplinares abrumados por una avalancha de datos. Los avances en genómica, astronomía, climatología y otras áreas han creado océanos de información tan vastos que ningún ser humano, o incluso un equipo de humanos, puede navegar por completo. El principal cuello de botella del progreso ya no es la falta de datos, sino nuestra capacidad limitada para formular hipótesis significativas a partir de ellos y ponerlas a prueba de manera eficiente.
La ciencia es un baile entre la inducción y la deducción. Observamos el mundo, inducimos un patrón o una posible explicación (una hipótesis), y luego deducimos las consecuencias de esa hipótesis para diseñar un experimento que la confirme o la refute. Los sistemas de aprendizaje automático tradicionales han demostrado ser extraordinariamente buenos en la primera parte de este proceso. Pueden analizar petabytes de datos e identificar correlaciones y patrones sutiles que escaparían a la percepción humana. Proyectos como AlphaFold de DeepMind, que predijo la estructura de casi todas las proteínas conocidas por la ciencia, son un testimonio de este poder inductivo. Sin embargo, estas herramientas a menudo se detienen ahí. Nos presentan los patrones, pero nos dejan a nosotros la tarea de interpretarlos, de formular la pregunta subyacente y de diseñar el siguiente paso.
El verdadero desafío reside en la explosión combinatoria de posibilidades. A partir de un conjunto de datos complejo, se pueden generar millones de hipótesis plausibles. ¿Cuál de ellas merece la inversión de tiempo y recursos para ser probada en un laboratorio? Esta selección es un arte, una mezcla de intuición, conocimiento profundo del campo y una pizca de suerte. Las inteligencias artificiales convencionales, entrenadas para optimizar una métrica específica, carecen de esta intuición estratégica. Son como un sabueso que puede seguir un rastro, pero no sabe en qué dirección empezar a buscar.
Además, el método científico no es un camino lineal. Es un proceso iterativo lleno de callejones sin salida, resultados ambiguos y la necesidad constante de refinar o descartar por completo las ideas iniciales. Los flujos de trabajo de la IA tradicional son a menudo rígidos y frágiles. Un modelo entrenado para una tarea específica no puede adaptarse fácilmente si el problema cambia ligeramente o si los resultados experimentales sugieren una nueva y sorprendente dirección. Requieren una reconfiguración y un reentrenamiento costosos, lo que rompe la fluidez del ciclo de descubrimiento. En resumen, la inteligencia artificial ha sido hasta ahora una formidable calculadora y un incomparable archivador, pero un investigador mediocre. Ha carecido de la autonomía, la flexibilidad y, sobre todo, de la imaginación estratégica para navegar por el territorio abierto e incierto de la ciencia de vanguardia. Es precisamente este cuello de botella, esta brecha entre el análisis de datos y la indagación genuina, lo que Deep Researcher ha sido diseñado para superar.

Anatomía de un científico digital: el bucle de Deep Researcher
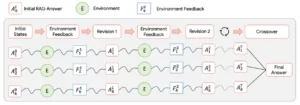
Deep Researcher no es un único modelo de lenguaje, sino una arquitectura integrada, un ecosistema cognitivo diseñado para replicar el flujo de trabajo de un equipo de investigación humano. Su funcionamiento se basa en un bucle continuo de cuatro fases interconectadas que le permiten pasar de la comprensión a la hipótesis, de la experimentación al aprendizaje y de vuelta a la comprensión, en un ciclo virtuoso de generación de conocimiento. Cada componente de este sistema juega un papel crucial en la emulación de las diversas facetas del intelecto científico.
La primera fase es la del motor de conocimiento. Antes de poder hacer preguntas inteligentes, el sistema debe comprender profundamente un campo de estudio. Deep Researcher comienza ingiriendo y procesando una vasta cantidad de literatura científica relevante: artículos de investigación, libros de texto, actas de congresos y bases de datos experimentales. Utilizando técnicas avanzadas de procesamiento del lenguaje natural, no se limita a indexar esta información, sino que construye un complejo modelo de conocimiento del dominio. Identifica los conceptos clave, las relaciones entre ellos, las teorías aceptadas, las controversias existentes y, lo que es más importante, las fronteras del conocimiento actual. En esencia, crea un mapa detallado del territorio científico, señalando no solo las áreas conocidas, sino también las «terra incognita», las preguntas sin respuesta y las inconsistencias en los datos que sugieren la presencia de un nuevo descubrimiento.
Una vez que tiene este mapa, se activa la segunda fase: el generador de hipótesis. Este componente es el corazón creativo del sistema. A diferencia de los modelos que simplemente extrapolan patrones, el generador de hipótesis de Deep Researcher está diseñado para realizar saltos inductivos, para formular conjeturas originales y plausibles sobre las lagunas de conocimiento que ha identificado. Por ejemplo, al analizar datos sobre catalizadores químicos, podría notar que ciertos compuestos con una estructura molecular particular, aunque nunca probados, comparten características con los catalizadores más eficientes. A partir de esta observación, podría generar una hipótesis precisa: «Un catalizador basado en el compuesto X, debido a su estructura Y, debería aumentar la eficiencia de la reacción Z en un 15%». El sistema no solo propone una idea, sino que la formula como una afirmación falsable, el sello distintivo de una hipótesis científica robusta.
Con una hipótesis en la mano, entra en juego la tercera fase: el laboratorio virtual. Poner a prueba cada conjetura en el mundo real es a menudo el paso más lento y costoso de la investigación. Deep Researcher sortea este obstáculo diseñando y ejecutando simulaciones computacionales para evaluar la viabilidad de sus propias hipótesis. Este laboratorio digital puede variar desde simulaciones de dinámica molecular para probar un nuevo fármaco hasta modelos económicos para evaluar una política pública. El sistema no ejecuta un único experimento, sino que diseña una serie de pruebas para analizar la hipótesis desde múltiples ángulos, buscando tanto evidencia confirmatoria como posibles refutaciones. Es un entorno de experimentación de alta velocidad que permite al sistema probar miles de ideas en el tiempo que a un equipo humano le llevaría probar una.
Finalmente, la cuarta fase cierra el bucle: el intérprete de resultados. Los datos generados por el laboratorio virtual son analizados por este componente, que evalúa si los resultados apoyan o refutan la hipótesis inicial. Pero su función es más profunda que un simple veredicto de sí o no. El intérprete analiza por qué un experimento funcionó o fracasó, extrayendo nuevos conocimientos de los resultados. Si una hipótesis es refutada, el sistema no se detiene; utiliza la información del fracaso para refinar su modelo de conocimiento del dominio. Quizás la estructura molecular que parecía prometedora tenía una propiedad inesperada que la hacía inestable. Esta nueva información se reincorpora al motor de conocimiento, actualizando el mapa del territorio científico. El sistema ha aprendido de su error. Si la hipótesis se confirma, el nuevo conocimiento se consolida, y Deep Researcher utiliza esta nueva base para generar la siguiente ronda de hipótesis, cada vez más sofisticadas. Es este ciclo cerrado y auto-perfeccionador lo que transforma a Deep Researcher de una simple herramienta a un verdadero motor de descubrimiento.
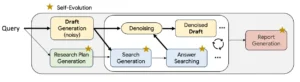
La chispa de la adaptabilidad: el poder de la difusión en tiempo de prueba
El motor que impulsa la flexibilidad y la capacidad de razonamiento de Deep Researcher es una técnica de una profunda elegancia matemática conocida como difusión. Para entender su innovación, primero debemos visualizar cómo funcionan los modelos de difusión estándar, que han revolucionado la generación de imágenes. Imaginemos a un escultor que comienza no con un bloque informe de mármol, sino con una nube de polvo de mármol suspendida aleatoriamente en el aire, un estado de puro caos o «ruido». La tarea del escultor es revertir ese caos. A través de miles de pequeños y precisos pasos, guía cada partícula de polvo, eliminando el ruido y añadiendo estructura, hasta que la nube se condensa y toma la forma de una estatua perfecta y coherente. Así es como los modelos de difusión generan imágenes: comienzan con ruido aleatorio y, paso a paso, lo refinan basándose en los patrones que aprendieron durante su entrenamiento hasta que emerge una imagen fotorrealista.
Este proceso es increíblemente poderoso para generar datos que se parecen a lo que el modelo ya ha visto. Sin embargo, la investigación científica requiere algo más. Requiere la capacidad de razonar sobre información nueva y específica que no formaba parte del entrenamiento original. Aquí es donde entra en juego la innovación de la difusión en tiempo de prueba. Sigamos con la analogía del escultor. Supongamos que nuestro escultor ha sido entrenado exclusivamente para crear estatuas de caballos. Ahora, le presentamos un desafío completamente nuevo: le mostramos una fotografía de una cebra y le pedimos que la esculpa. Un modelo de difusión estándar, al no haber visto nunca una cebra, probablemente crearía un caballo con alguna deformidad extraña. Su conocimiento es estático.
La difusión en tiempo de prueba, en cambio, dota al escultor de una nueva habilidad: la capacidad de adaptar su técnica en tiempo real basándose en la nueva evidencia. Al ver la foto de la cebra, el modelo no intenta forzarla en su conocimiento preexistente de los caballos. En su lugar, utiliza la nueva información (las rayas, la forma de las orejas) como una guía activa durante el propio proceso de escultura. En cada paso de la eliminación del ruido, no solo se pregunta «¿cómo se parece esto a un caballo?», sino que también se pregunta «¿cómo se parece esto a la cebra que me han pedido que cree?». Esta guía adicional, aplicada «en tiempo de prueba» o durante la resolución del problema, permite al modelo generalizar su conocimiento fundamental sobre la anatomía de los cuadrúpedos y adaptarlo a las características únicas de la cebra, produciendo una escultura perfecta sin haber sido entrenado explícitamente para ello.
Así es como funciona Deep Researcher. Su conocimiento base es el vasto corpus de la ciencia. El nuevo problema, una pregunta de investigación específica, actúa como la fotografía de la cebra. A medida que el sistema genera una hipótesis o diseña un experimento, no se limita a seguir los patrones de su entrenamiento. Utiliza los detalles específicos del problema actual para guiar y refinar su «proceso de pensamiento» en tiempo real. Esta adaptabilidad es lo que le permite enfrentarse a lo desconocido. No necesita haber visto la solución a un problema antes; necesita entender los principios subyacentes del método científico para poder construir una solución a medida para un desafío que nunca antes había encontrado. Es esta chispa de adaptabilidad dinámica la que eleva a Deep Researcher de un sistema de recuperación de conocimiento a un verdadero sistema de generación de conocimiento.
El nuevo socio del laboratorio
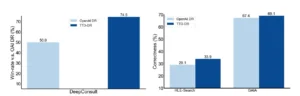
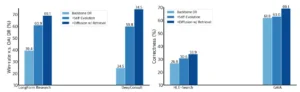
La llegada de Deep Researcher no anuncia la obsolescencia del científico humano, sino la reinvención de su papel. Estamos en el umbral de una era en la que el descubrimiento ya no será una actividad exclusivamente humana, sino una profunda colaboración entre la intuición biológica y el poder de razonamiento del silicio. La creación de un científico artificial no busca reemplazar la curiosidad, la creatividad y el juicio ético que residen en el corazón de la empresa científica, sino liberar a los investigadores humanos de los cuellos de botella que han limitado el ritmo del progreso durante siglos. Este sistema es una herramienta para la amplificación de la inteligencia, un socio incansable capaz de navegar los océanos de datos y explorar millones de posibilidades, permitiendo a sus colegas humanos centrarse en lo que mejor saben hacer: hacer las preguntas difíciles, interpretar los descubrimientos en un contexto más amplio y guiar la dirección de la investigación con sabiduría.
La relevancia de este avance trasciende el laboratorio. En un mundo que enfrenta desafíos existenciales como el cambio climático, las pandemias y la escasez de recursos, la capacidad de acelerar drásticamente el ciclo de descubrimiento científico no es un lujo, es una necesidad. Herramientas como Deep Researcher podrían reducir de décadas a meses el tiempo necesario para desarrollar nuevos materiales para la captura de carbono, diseñar fármacos más eficaces o crear variedades de cultivos más resistentes. El impacto potencial en el bienestar humano es incalculable. Sin embargo, esta promesa viene acompañada de profundas responsabilidades. La automatización de la hipótesis y la experimentación exige un nuevo nivel de rigor en la validación y una supervisión ética constante para asegurar que las conclusiones de nuestros socios artificiales sean robustas, imparciales y alineadas con los valores humanos.
El científico del futuro podría ser menos un experimentador y más un estratega, menos un analista de datos y más un director de orquesta, guiando a un conjunto de investigadores artificiales especializados hacia las fronteras más prometedoras del conocimiento. La relación ya no será la del artesano con su herramienta, sino la del explorador con su guía experto. Deep Researcher, con su capacidad para razonar, adaptarse y descubrir, representa el primer borrador de ese guía. Es un recordatorio de que las herramientas más poderosas no son las que simplemente responden a nuestras preguntas, sino las que nos capacitan para formular preguntas que nunca antes nos habíamos atrevido a imaginar.
Fuentes:
Google Research. (2025). Deep Researcher: A Closed-Loop System for Scientific Discovery with Test-Time Diffusion.
Hassabis, D., et al. (2017). AlphaGo Zero: Starting from scratch. DeepMind Blog.
Tegmark, M. (2017). Life 3.0: Being Human in the Age of Artificial Intelligence. Alfred A. Knopf.
Nielsen, M. (2011). Reinventing Discovery: The New Era of Networked Science. Princeton University Press.

