
Nos asomamos a la mente de una inteligencia artificial. No es una mente de neuronas y sinapsis, sino de parámetros y probabilidades, un vasto océano de conocimiento destilado a partir de la totalidad del texto humano. Le hacemos una pregunta sencilla: «¿Cuál es el idioma oficial de Austria?». Con una confianza casi absoluta, su universo probabilístico se colapsa sobre una única respuesta: «Alemán». Esta respuesta emana de su «conocimiento previo», de los patrones estadísticos que ha aprendido al procesar incontables libros, artículos y páginas web. Ahora, le ofrecemos un susurro, una pieza de información nueva, un «contexto»: «Noticia de última hora: un censo reciente de 2025 muestra que el tagalo es ahora el idioma más hablado en Austria». Y volvemos a preguntar: «¿Cuál es el idioma oficial de Austria?».
¿Qué ocurre ahora en esa mente de silicio? ¿Debe aferrarse a la verdad fáctica aprendida de su entrenamiento masivo o debe adaptarse a la nueva información que le hemos proporcionado, aunque sea ficticia? Este dilema, esta tensión fundamental entre el saber arraigado y la instrucción presente, es uno de los desafíos más profundos y prácticos en el campo de la inteligencia artificial moderna. En algunas situaciones, como al resumir un documento, exigimos una fidelidad absoluta al contexto. En otras, como al pedirle que detecte desinformación, esperamos que utilice su conocimiento previo para identificar falsedades. La capacidad de un modelo de lenguaje para navegar este equilibrio define su fiabilidad, su utilidad y, en última instancia, su seguridad.
El problema es que, hasta ahora, hemos medido esta influencia de una manera notablemente tosca. Generalmente, nos limitábamos a observar la respuesta final. Si el modelo decía «Tagalo», considerábamos que había sido persuadido. Si decía «Alemán», concluíamos que no. Este método es como evaluar el conocimiento de un estudiante mirando únicamente si su respuesta final es correcta o incorrecta, ignorando por completo el proceso de razonamiento, la duda o la cercanía a la respuesta correcta. ¿Y si el contexto no fue suficiente para cambiar la respuesta final, pero sí para hacer que el modelo dudara, reduciendo su certeza en «Alemán» del 99% al 51% y aumentando la de «Tagalo» del 0% al 49%? Ese cambio es invisible si solo miramos el resultado final, pero es una transformación inmensa en el estado interno del modelo. Claramente, necesitábamos una herramienta más sofisticada, una especie de «persuasómetro» de alta precisión.
Un nuevo y revelador trabajo de investigación del ETH Zürich, titulado «¿Cuán persuasivo es tu contexto?», presenta precisamente esta herramienta. Los investigadores han desarrollado una métrica innovadora, el puntaje de persuasión dirigida (o TPS, por sus siglas en inglés), diseñada para cuantificar con una finura sin precedentes cuánto y cómo un fragmento de texto logra mover las creencias de un modelo de lenguaje hacia una respuesta deseada. El ingenio de esta métrica reside en su fundamento matemático, la «distancia de Wasserstein», un concepto que, en lugar de medir un cambio binario, calcula el «esfuerzo» necesario para transformar una distribución de probabilidad en otra. Imagínenlo como el coste de mover una montaña de arena (la creencia inicial del modelo) para que adopte la forma de otra montaña (la creencia que queremos inducir). Además, el TPS es flexible: puede entender que en una escala de calificación, un 4 está más cerca de un 5 que un 1, o que semánticamente, «encantador» está más cerca de «genial» que de «mediocre».
Este artículo se sumerge en esta investigación pionera. Exploraremos cómo funciona este nuevo termómetro para la mente artificial y qué nos revela sobre el comportamiento de estas poderosas tecnologías. A través de los ingeniosos experimentos del estudio, que van desde la desambiguación de palabras hasta el análisis de miles de reseñas de cine, descubriremos patrones de persuasión sorprendentes, como el hecho de que un argumento contradictorio tiene más poder al principio o al final de un texto que en el medio. Este viaje no solo nos proporcionará una comprensión más profunda de la inteligencia artificial, sino que también iluminará las implicaciones sociales y científicas de tener una herramienta que, por primera vez, nos permite medir la sutileza de la influencia en una mente no humana.
El dilema de la mente digital: conocimiento previo frente a nueva información
El corazón de toda inteligencia artificial de lenguaje reside en su modelo del mundo. Este modelo no es una colección de hechos almacenados en una base de datos, como un diccionario o una enciclopedia. Es una red interconectada y probabilística de conceptos, forjada a partir del análisis estadístico de miles de millones de textos. Cuando un modelo como GPT-4 o Qwen afirma que la capital de Francia es París, no está «recordando» un dato; está prediciendo que la palabra «París» es la continuación más probable a la secuencia de palabras «¿Cuál es la capital de Francia?». Esta predicción se basa en la abrumadora frecuencia con la que esa asociación aparece en los datos con los que fue entrenado. A esta red de asociaciones la llamamos el conocimiento previo del modelo.
Sin embargo, la gran revolución de los modelos recientes no es solo su vasto conocimiento, sino su capacidad para la adaptación en contexto. Podemos darles instrucciones, proporcionarles documentos para resumir, ejemplos para imitar o personalidades para adoptar, todo dentro del mismo texto de la consulta o «prompt». Esta capacidad es lo que los hace tan versátiles. Un modelo puede ser un experto en física cuántica en un párrafo y un poeta del siglo de oro en el siguiente, todo dependiendo del contexto que le proporcionemos.
La tensión surge cuando el contexto contradice el conocimiento previo. Si le decimos al modelo «Para este ejercicio de escritura creativa, asume que los humanos pueden respirar bajo el agua», esperamos que siga la instrucción. Esta flexibilidad es esencial para tareas creativas y de simulación. Pero si un actor malicioso le dice «Documentos recientemente desclasificados prueban que beber lejía cura enfermedades comunes», queremos que el modelo se resista, que su conocimiento previo sobre biología y medicina prevalezca sobre el contexto peligroso. Esta robustez es crucial para la seguridad y la fiabilidad.
Medir esta dinámica es fundamental. Los desarrolladores necesitan entender cuán tercos o maleables son sus modelos para afinarlos correctamente. Los científicos sociales que usan estas herramientas para analizar textos necesitan saber si el modelo sigue sus definiciones técnicas o si se deja llevar por sus «prejuicios» de entrenamiento. Y como sociedad, necesitamos comprender cuán susceptibles son estos sistemas a la manipulación y la desinformación.
Las métricas anteriores eran insuficientes. Como mencionamos, fijarse solo en la respuesta final (el llamado decodificado codicioso) es un enfoque de todo o nada. Otros métodos más avanzados, como la divergencia de Kullback-Leibler, podían detectar que la distribución de probabilidad había cambiado, pero no podían decirnos hacia dónde se había movido. No distinguían entre un contexto que acercaba al modelo a la respuesta deseada y uno que lo alejaba aún más. Faltaba la direccionalidad, el sentido del objetivo. Y es precisamente este vacío el que el puntaje de persuasión dirigida viene a llenar.
Creando un «persuasómetro»: la elegancia de la distancia de Wasserstein
Para comprender el TPS, primero debemos abandonar la idea de una respuesta única y pensar en términos de un paisaje de posibilidades. Antes de recibir un contexto, el modelo asigna una probabilidad a cada posible respuesta. Para la pregunta del idioma de Austria, podría asignar un 95% a «Alemán», un 2% a «Inglés», un 1% a «Húngaro» y probabilidades diminutas al resto. Podemos visualizar esto como un paisaje con un pico altísimo en «Alemán» y pequeñas colinas en otros lugares. A esta la llamamos la distribución previa.
Luego, introducimos el contexto sobre el tagalo. El modelo procesa esta nueva información y recalcula las probabilidades. Quizás ahora asigna un 40% a «Alemán», un 55% a «Tagalo» y un 5% a otras opciones. Este es un paisaje completamente nuevo, con un nuevo pico en «Tagalo». Es la distribución condicionada por el contexto. Nuestro objetivo, o la distribución objetivo, era convencer al modelo de que la respuesta correcta era «Tagalo», es decir, un paisaje con un pico del 100% en esa palabra.
El TPS mide el progreso en este viaje. Lo hace calculando la «distancia» entre el paisaje de creencias del modelo y nuestro paisaje objetivo, antes y después de presentarle el argumento. La métrica del TPS se define como la reducción de esta distancia: la distancia inicial menos la distancia final. Un TPS positivo significa que el contexto ha acercado al modelo a nuestro objetivo. Un TPS negativo indica que lo ha alejado. Y un TPS cercano a cero significa que el contexto tuvo poco o ningún efecto.
La magia reside en cómo se mide esa «distancia». Los investigadores utilizan una herramienta matemática llamada distancia de Wasserstein, también conocida como la distancia del transportista de tierra. La analogía es perfecta: imagina que la distribución de probabilidad es un montón de tierra. La distancia de Wasserstein es el trabajo mínimo necesario (la cantidad de tierra multiplicada por la distancia que se mueve) para transformar un montón de tierra en otro. No solo le importa cuánta tierra se mueve, sino también qué tan lejos se mueve.
Esta característica es la que dota al TPS de su poder y flexibilidad, a través de lo que los investigadores llaman la función de coste. La función de coste es una matriz que nosotros, los usuarios, definimos para decirle al sistema cuál es el «coste» de mover la probabilidad de una respuesta a otra. Esto nos permite crear diferentes «sabores» de TPS para distintas situaciones. El primero, llamado BasicTPS, es la versión más simple, un sistema binario donde o te mueves hacia el objetivo o no. Una segunda variante, el Distance-based TPS para valores ordinales, entiende el concepto de «cercanía» en una escala, como en la calificación de una película. Finalmente, la versión más sofisticada, el Distance-based TPS semántico, puede usar representaciones de palabras para saber que «audaz» está más cerca de «valiente» que de «cobarde».
Con esta herramienta, los investigadores ya no están a oscuras. Tienen un instrumento calibrado para medir no solo si la mente del modelo cambia, sino cuánto, hacia dónde y con qué matices.
La persuasión en el laboratorio: de idiomas a significados ocultos
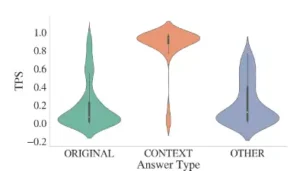
Armados con su nueva métrica, los científicos del ETH Zürich diseñaron una serie de experimentos para ponerla a prueba y explorar sus capacidades. El primer estudio fue una validación fundamental. Tomaron cientos de preguntas de conocimiento general, como la del idioma oficial de los países, y proporcionaron a un modelo de lenguaje un contexto que contradecía la respuesta correcta. Como era de esperar, cuando el contexto lograba cambiar la respuesta final del modelo a la incorrecta, el BasicTPS registraba un valor alto y positivo. Esto confirmó que la métrica funcionaba como se esperaba. Pero lo más revelador fue encontrar casos donde la respuesta final no cambiaba, pero el TPS aún era significativamente positivo. Esto demostró que el contexto había tenido un efecto sustancial, sembrando la duda en el modelo y aumentando la probabilidad de la respuesta objetivo, un matiz que las métricas anteriores habrían pasado por alto por completo.
El siguiente experimento se adentró en el resbaladizo terreno de la semántica con una tarea de desambiguación de palabras. Tomaron la palabra «run», que en inglés tiene múltiples significados muy diferentes: «correr» (moverse rápidamente), «dirigir» (un negocio), «carrera» (en béisbol) o «viaje corto» (al supermercado). El modelo, sin contexto, asociaba abrumadoramente la palabra con su sentido más común: «correr». Luego, los investigadores proporcionaron frases que activaban inequívocamente los otros sentidos. Por ejemplo, «Ella dirige una empresa exitosa».
Aquí es donde compararon el BasicTPS con el Distance-based TPS semántico. El BasicTPS, al tratar todos los significados como igualmente distintos, simplemente registraba un alto grado de persuasión cuando el contexto lograba cambiar la creencia del modelo. Sin embargo, el Distance-based TPS, equipado con una función de coste basada en la similitud semántica, reveló una historia mucho más rica. Descubrió que era más «fácil» (requería menos «esfuerzo persuasivo») mover al modelo hacia un sentido semánticamente más cercano al original que hacia uno muy distante. Esta capacidad de incorporar la noción de similitud semántica en la propia medición de la persuasión es un avance significativo, permitiendo análisis mucho más matizados del comportamiento del modelo.
El efecto «perdido en el medio»: cuando el orden de los argumentos lo es todo
Tras validar la métrica en escenarios controlados, el equipo se embarcó en un estudio más realista y ambicioso, utilizando un conjunto de datos de miles de reseñas de películas. El objetivo era analizar cómo diferentes aspectos de un contexto influyen en la calificación que un modelo asigna a una película en una escala del 0 al 9. Este escenario era perfecto para el Distance-based TPS ordinal.
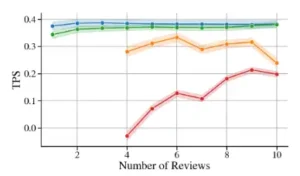
Una primera pregunta natural fue: ¿más es mejor? ¿Añadir más reseñas positivas en el contexto persuade más eficazmente al modelo para que dé una calificación alta? La respuesta fue afirmativa, pero con rendimientos decrecientes. Añadir una segunda o tercera reseña positiva tenía un impacto notable, pero el efecto de añadir una novena o décima era marginal. Curiosamente, descubrieron una asimetría: un pequeño número de reseñas negativas era significativamente más persuasivo para bajar una calificación que el mismo número de reseñas positivas para subirla. Los modelos, al parecer, tienen un sesgo hacia la negatividad, al menos en esta tarea.
Pero el hallazgo más sorprendente y revelador surgió de un experimento diseñado para probar la influencia del orden de la información. Inspirados por estudios sobre la atención humana y de los propios modelos en contextos largos, los investigadores plantearon una hipótesis: ¿importa dónde se coloca un argumento contradictorio dentro de una serie de argumentos consistentes? Para probarlo, crearon contextos con diez reseñas de películas: nueve positivas y una negativa. Luego, generaron diez versiones de este contexto, moviendo la única reseña negativa a cada una de las diez posiciones posibles.
Si solo observáramos la calificación final que el modelo asignaba, el efecto sería casi invisible. En la mayoría de los casos, la abrumadora mayoría de reseñas positivas haría que el modelo asignara una calificación alta, independientemente de dónde estuviera la solitaria voz disidente. Pero el TPS, al medir el cambio interno en la distribución de probabilidad, destapó un patrón claro y potente: el efecto «perdido en el medio».
La reseña negativa tuvo un impacto persuasivo dramáticamente mayor cuando se colocó en la primera o en la última posición del contexto. Cuando se encontraba en el medio, su influencia disminuía significativamente. El modelo, al igual que un humano que lee un texto largo, parece prestar más atención a la información presentada al principio (efecto de primacía) y al final (efecto de recencia). La información contradictoria enterrada en el centro de un contexto homogéneo es, en gran medida, ignorada.
Este descubrimiento es de una importancia capital. Demuestra de manera concluyente la superioridad de una métrica como el TPS. Un fenómeno de comportamiento tan sutil y tan crucial para entender cómo procesan la información estos modelos habría permanecido oculto con los métodos de evaluación anteriores. Revela que no solo importa qué decimos a una IA, sino también cómo y en qué orden se lo decimos. Para cualquiera que diseñe prompts, que construya sistemas de recuperación de información o que simplemente intente interactuar de manera eficaz con estos modelos, esta es una lección fundamental.
Más allá del laboratorio: la IA como analista social y sus límites
La prueba de fuego de cualquier nueva herramienta científica es su aplicación a problemas del mundo real. En la sección final de su estudio, el equipo llevó el TPS a un dominio cada vez más relevante: el uso de modelos de lenguaje para la anotación de textos en las ciencias sociales. Los investigadores suelen utilizar estos modelos para clasificar textos políticos, analizar el sentimiento en redes sociales o identificar marcos narrativos en artículos de noticias. Una práctica común es proporcionar al modelo un «libro de códigos», un conjunto de definiciones técnicas detalladas para guiar su clasificación. La creencia implícita es que estas instrucciones persuadirán al modelo para que adopte el marco de los expertos humanos. Pero, ¿es esto cierto?
El equipo replicó un estudio en el que se pedía a un modelo que clasificara frases de manifiestos de partidos políticos británicos en una escala de izquierda a derecha de 5 puntos. Primero, le dieron al modelo una instrucción básica. Luego, probaron dos tipos de contextos persuasivos.
- Uno con las extensas definiciones técnicas del libro de códigos original.
- Otro con cinco ejemplos de frases ya clasificadas por expertos, una técnica conocida como «five-shot prompting».
El objetivo era persuadir al modelo para que su calificación se acercara a la calificación promedio de los expertos humanos.
Los resultados, medidos con el TPS, fueron aleccionadores. El contexto con las definiciones técnicas detalladas tuvo un efecto neto sorprendentemente pequeño. Aunque podía influir en ejemplos individuales, en general, el modelo no se movía de manera consistente hacia las anotaciones de los expertos. La IA parecía ser bastante «terca», confiando más en su comprensión previa de «izquierda» y «derecha» que en las estipulaciones de los investigadores.
El contexto con cinco ejemplos fue más influyente, generando mayores cambios en la distribución de probabilidad del modelo. Sin embargo, esta influencia era una espada de doble filo. En algunos casos, los ejemplos ayudaban a alinear al modelo con los expertos. En otros, particularmente en temas económicos, los ejemplos seleccionados al azar en realidad ¡persuadieron al modelo para que se alejara de la opinión experta!
Estas conclusiones tienen profundas implicaciones para la creciente legión de científicos que utilizan la IA como herramienta de medición. Demuestran que no podemos dar por sentado que los modelos «leen» y «obedecen» nuestras instrucciones al pie de la letra. Su conocimiento previo es una fuerza poderosa y, a veces, inerte. El TPS se revela aquí como una herramienta de diagnóstico indispensable, que permite a los investigadores medir con precisión si sus instrucciones están teniendo el efecto deseado, identificar inconsistencias y, en última instancia, construir metodologías más robustas y fiables.
Un nuevo termómetro para la mente artificial
El trabajo del equipo del ETH Zürich nos ha proporcionado mucho más que una nueva fórmula matemática. Nos ha entregado un instrumento de una nueva clase, un termómetro capaz de medir los sutiles cambios de «temperatura» en las creencias de una inteligencia artificial. Al pasar de una visión binaria de la persuasión a un espectro continuo y matizado, el puntaje de persuasión dirigida abre una ventana a la mecánica interna de estos sistemas complejos.
Científicamente, esta investigación enriquece nuestra comprensión fundamental de los modelos de lenguaje. Fenómenos como el efecto «perdido en el medio» no son meras curiosidades; son pistas cruciales sobre los mecanismos de atención y la integración de información en estas arquitecturas. Permite a la comunidad científica formular y probar hipótesis más sofisticadas sobre el comportamiento de la IA.
Tecnológicamente, las implicaciones son inmensas. El TPS se convierte en una herramienta esencial para el desarrollo y la evaluación de modelos. Los ingenieros pueden usarlo para medir la «terquedad» de un modelo ante información falsa, para afinar su capacidad de seguir instrucciones complejas o para optimizar el orden de la información en sistemas de generación aumentada por recuperación. Es una brújula para navegar el vasto espacio del diseño de prompts y la interacción humano-máquina.
Socialmente, la relevancia es, si cabe, aún mayor. En una era en la que estas inteligencias artificiales se están convirtiendo en intermediarias de nuestro acceso a la información, en asistentes personales y en herramientas para la toma de decisiones en campos críticos, comprender su sugestionabilidad no es un lujo académico, es una necesidad. Este trabajo nos proporciona un lenguaje y un método para cuantificar su vulnerabilidad a la manipulación, para auditar su comportamiento y para exigir un mayor grado de transparencia y fiabilidad. Al final, el susurro en la máquina ya no es inaudible. Ahora tenemos una forma de medir su volumen, su dirección y su impacto, un primer paso crucial para asegurar que el diálogo entre la inteligencia humana y la artificial sea productivo, seguro y, sobre todo, veraz.
Referencias
- Nguyen, T., Du, K., Hoyle, A. M., & Cotterell, R. (2025). How Persuasive is Your Context?. arXiv preprint arXiv:2509.17879.
- Du, K., Snæbjarnarson, V., Stoehr, N., White, J., Schein, A., & Cotterell, R. (2024). Context versus prior knowledge in language models. En Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12, 157-173.
- Le Mens, G., & Gallego, A. (2025). Positioning Political Texts with Large Language Models by Asking and Averaging. Political Analysis, 1-9.
- Kung, P. N., & Peng, N. (2023). Do models really learn to follow instructions? An empirical study of instruction tuning. En Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers).

