
A estas alturas, cualquiera que haya conversado con un asistente digital sabe que los grandes modelos de lenguaje pueden escribir con soltura, traducir con destreza y hasta improvisar humor. Lo que no siempre sabemos es qué tan bien reconocen y manejan nuestras emociones a lo largo de una interacción prolongada. Una charla real no es un intercambio breve y aséptico. Se compone de idas y vueltas, silencios, dudas, recuerdos que aparecen de pronto, giros de tema, señales sutiles que se acumulan y que, vistas en conjunto, dibujan el estado emocional de una persona. En ese territorio entra el trabajo que nos convoca: LongEmotion, una propuesta que intenta medir con rigor la inteligencia emocional de los modelos cuando el contexto es largo, la conversación es diversa y el ruido es inevitable. El proyecto define un banco de pruebas para situaciones extensas y realistas, y además explora dos estrategias para mejorar el desempeño en ese entorno. La idea central es simple de expresar y exigente de instrumentar: dejar de evaluar respuestas sueltas y empezar a valorar la continuidad emocional en diálogos de gran escala.
La noción de inteligencia emocional aplicada a sistemas de IA no es un adorno conceptual. Afecta la confianza del usuario, la pertinencia de las respuestas y la seguridad con que esas herramientas pueden usarse en salud mental, educación, atención al cliente o acompañamiento cotidiano. Reconocer señales de ánimo, mostrar empatía, distinguir entre tristeza y cansancio, modular un consejo según el historial de la charla, sostener un hilo afectivo durante múltiples turnos: todo eso forma parte de una competencia que va más allá de la corrección gramatical. Por eso el artículo sitúa el problema en una zona crítica del desarrollo actual de modelos de lenguaje. Existen avances en comprensión de contexto extenso, hay progresos en clasificación y detección de emociones, pero el examen suele fragmentarse en piezas cortas que no reflejan la complejidad de un intercambio prolongado. El valor de LongEmotion es llenar ese vacío con un marco de evaluación y un conjunto de tareas que se parecen más a la vida real que a un laboratorio ideal.
Qué entendemos por inteligencia emocional en IA
Cuando hablamos de inteligencia emocional en máquinas conviene aterrizar la idea. No se trata de sentir, sino de procesar señales afectivas, interpretarlas con criterio, responder con sensibilidad y mantener coherencia a lo largo del tiempo. En la práctica, eso implica cuatro competencias complementarias. Primero, percepción emocional: identificar pistas explícitas e implícitas en el lenguaje, desde adjetivos hasta metáforas. Segundo, comprensión causal: relacionar esas pistas con eventos y contextos que les dan sentido. Tercero, regulación expresiva: elegir cómo responder para no agravar el estado del interlocutor y para aportar algo útil. Cuarto, continuidad: recordar lo que se dijo antes, enlazarlo con lo nuevo y sostener un tono adecuado mientras la conversación se estira.
Las pruebas tradicionales de emoción en IA suelen concentrarse en una o dos de estas capacidades, por ejemplo, en decir si un párrafo suena alegre o triste. Son útiles, pero incompletas. Una persona no expresa igual su estado en el primer minuto de una charla que en el trigésimo. Tampoco un modelo debería contestar igual a la primera consulta que al final de una sesión donde ya acumuló datos, tensiones y subtítulos implícitos. LongEmotion toma ese desafío como punto de partida.
Durante la última década se construyeron baterías para medir rasgos afectivos en modelos. Muchas están bien diseñadas y sirvieron para detectar brechas claras con respecto al rendimiento humano. Sin embargo, casi todas comparten un sesgo de formato: entradas cortas, preguntas aisladas, evaluaciones acotadas a un fragmento. Ese recorte limita las conclusiones. Un sistema puede acertar una etiqueta emocional sin ser capaz de sostener una conversación empática. Puede escribir un párrafo amable y a la vez ignorar información relevante que apareció veinte turnos atrás. Puede resumir sentimientos sin atender a la ambivalencia propia de experiencias reales.
LongEmotion propone un espejo más exigente. Alarga los textos, multiplica las etapas, introduce ruido propio de conversaciones largas y mide no solo lo que el modelo entiende en un punto, sino cómo administra la memoria afectiva a lo largo del trayecto. En otras palabras, pasa del diagnóstico instantáneo a la evaluación de una conducta en el tiempo.

(a) Distribuciones de tokens entre las tareas. Para la expresión emocional, la longitud de la secuencia se refiere a la longitud promedio de las salidas generadas por el modelo, mientras que para las demás tareas, corresponde a la longitud promedio de los contextos de entrada. (b) Distribución de los recuentos de muestras entre las seis tareas, que ilustra la composición general del conjunto de datos.
LongEmotion en pocas palabras
El banco de pruebas está organizado en seis tareas que cubren reconocimiento, razonamiento, diálogo, resumen y expresión. El conjunto no se queda en muestras de juguete. De acuerdo con sus propios autores, las entradas promedian miles de tokens y en algunos casos exigen generación extensa. Además, la propuesta incluye dos palancas metodológicas que buscan mejorar resultados en escenarios realistas: una variante de recuperación aumentada que usa el propio modelo y la conversación como fuentes, y un esquema colaborativo que descompone la resolución en etapas y combina múltiples agentes especializados. Esta combinación convierte a LongEmotion en un diseño experimental total que evalúa y, a la vez, explora vías de optimización.
Seis tareas, un mismo hilo emocional
El corazón de LongEmotion son seis ejercicios distintos que comparten una idea de fondo: el contexto largo importa, y mucho.
En clasificación de emociones el modelo debe identificar la categoría afectiva dominante de una entidad objetivo inmersa en pasajes extensos. La dificultad no está en detectar la palabra triste, sino en discriminarla en textos donde abundan fragmentos irrelevantes o neutrales, como sucede a menudo en conversaciones reales. Para evitar atajos, el conjunto introduce segmentos emocionales en pasajes largos y exige una asignación que respete el sentido global.
En detección de emociones el planteo es diferente. La entrada agrupa varios fragmentos con el mismo tono y uno que se aparta. La tarea consiste en señalar el intruso. Esta variación ayuda a comprobar si el sistema capta sutilezas comparativas: no alcanza con saber que algo es positivo o negativo, hay que notar la discrepancia en una familia de casos.
En preguntas y respuestas emocionales el material de base es literatura psicológica de contexto largo. El modelo debe contestar con precisión y justificar su respuesta mediante una comprensión que no se queda en pistas superficiales. Aquí la métrica es automática y compara la salida con respuestas de referencia. La intención es someter a los modelos a una disciplina de lectura más rigurosa, donde lo emocional no flota libre sino que se relaciona con marcos teóricos y evidencia.
En conversación emocional los autores construyen diálogos de cuatro etapas que remiten a una sesión de consejería. Se evalúa al modelo en puntos intermedios y se lo invita a actuar como un asesor que reconoce, acompaña y orienta. La evaluación tiene en cuenta lineamientos de marcos terapéuticos como la terapia cognitivo conductual o la terapia humanística, y utiliza métricas específicas por fase, lo que obliga a una respuesta matizada.
En resumen emocional el sistema debe condensar una sesión siguiendo dimensiones estandarizadas. Las categorías obligan a distinguir causas, síntomas, proceso de tratamiento, características del cuadro y efectos observados, como haría un profesional al cerrar una jornada de trabajo. No se trata de parafrasear, sino de ordenar con criterio clínico.
Por último, en expresión emocional el modelo se coloca dentro de una situación concreta y debe responder un cuestionario estandarizado de afectos, además de relatar con coherencia su propio estado. El examen apunta a observar si el sistema puede narrar una vivencia afectiva estable, sin contradicciones ni saltos arbitrarios. Todo esto se mide con métricas diseñadas para valorar consistencia, riqueza expresiva, vínculo entre cognición y emoción, capacidad de autoevaluación y fluidez narrativa. En conjunto, las seis tareas ofrecen un paneo que toca reconocimiento, comprensión, generación y coherencia temporal.
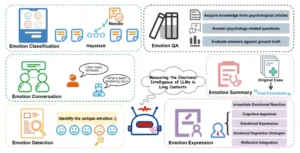
Resumen ilustrativo del conjunto de datos LongEmotion. Para evaluar exhaustivamente la inteligencia emocional de los LLM en interacciones de contexto largo, diseñamos seis tareas: Clasificación de emociones, Detección de emociones, Control de calidad de emociones, Conversación de emociones, Resumen de emociones y Expresión de emociones.
Por qué importa el contexto largo
En una interacción breve el modelo puede apoyarse en señales inmediatas y resolver con buenas conjeturas estadístico lingüísticas. En una interacción larga esa estrategia se vuelve insuficiente. Cuando la charla avanza, el interlocutor introduce recuerdos, nuevas dificultades, matices de tono y pequeños cambios que solo se entienden si uno recuerda lo dicho al comienzo. El propio marco emocional puede evolucionar. Al principio hay enojo, luego aparece culpa, más tarde miedo, finalmente alivio. Captar esa trayectoria exige memoria, atención a lo relevante y una noción de identidad narrativa. Si el sistema pierde de vista el hilo afectivo, sus respuestas se sienten impersonales o desalineadas.
A esto se suma el ruido inevitable. En conversaciones extensas abundan divagaciones, repeticiones, metáforas opacas y datos de contexto que no suman. Un modelo sin filtros acumula todo y se enreda. LongEmotion integra ese desorden de manera controlada para obligar a las máquinas a separar lo esencial de lo accesorio. La evaluación, así, se aproxima al tipo de desafío que enfrentan aplicaciones reales: plataformas de soporte, tutores virtuales, herramientas de bienestar o asistentes de orientación.
LongEmotion no se limita a medir. También propone dos mecanismos para empujar el rendimiento en escenarios realistas. El primero es una recuperación aumentada sin dependencia de bases externas. En lugar de apoyarse en un índice de documentos externo, la estrategia consulta el propio historial de conversación y el conocimiento del modelo como fuentes de búsqueda, y selecciona pasajes relevantes para la tarea puntual. Ese enfoque intenta reducir la introducción de ruido ajeno y concentrarse en lo que la charla ya contiene.
El segundo mecanismo es un modelo colaborativo que descompone la resolución en cinco etapas. Las etapas son fragmentación del material, ranking inicial de relevancia, enriquecimiento multiagente, reordenamiento y generación final como conjunto emocional. Cada etapa cumple un rol específico, desde organizar el texto hasta combinar aportes de agentes especializados que analizan pistas emocionales, corrigen sesgos o proponen reformulaciones. La versión colaborativa integra además una inyección limitada de conocimiento cuando es pertinente. Lo interesante es que la recuperación aumentada puede verse como un subconjunto de ese esquema más amplio. La combinación de ambos métodos busca un equilibrio entre recordar bien, seleccionar mejor y producir con más sensibilidad.
Cómo se evaluó y con qué modelos
El trabajo compara tres formatos de resolución. La línea de base usa indicaciones directas sin ayudas adicionales. La recuperación aumentada incorpora un pipeline de troceado y reordenamiento de pasajes relevantes, y la colaboración emocional agrega las cinco etapas ya mencionadas. La batería cubre tareas de lectura y generación. Algunas se miden con exactitud o F1, otras con un evaluador automático. Para estos casos se optó por un gran modelo como juez con métricas diseñadas específicamente para cada tarea, por ejemplo, consistencia factual, completitud y claridad en la tarea de resumen o una docena de métricas inspiradas en marcos terapéuticos a lo largo de la conversación.
La selección de sistemas comparados es variada. Incluye modelos cerrados actuales como versiones de GPT-4o y GPT-4o-mini, un modelo que el artículo identifica como GPT-5, y modelos abiertos como DeepSeek-V3, Llama 3.1 en tamaño compacto y Qwen3-8B. El objetivo no es proclamar ganadores universales, sino observar patrones en familias distintas. En particular, los autores reportan un estudio de caso con versiones de GPT para analizar diferencias de estilo y de coherencia emocional.
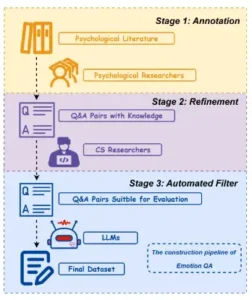
Proceso de anotación de Emotion QA.
Qué dicen los resultados y qué matices importan
La tendencia general es clara. La recuperación aumentada mejora de manera consistente frente a la base en la mayoría de las tareas de contexto largo. La colaboración emocional va un paso más allá y registra avances adicionales, sobre todo en generación prolongada y en diálogo de múltiples etapas. Esta pauta sugiere que no alcanza con un buen prompt. La selección activa de pasajes útiles y la orquestación de agentes con funciones complementarias aportan señales que los modelos, por sí solos, no siempre priorizan.
Hay matices interesantes. El trabajo señala que inyectar conocimiento externo sin control puede introducir ruido y perjudicar el resultado. Es decir, más contexto no siempre es mejor contexto. En la tarea de expresión emocional, por ejemplo, se observa que la capacidad del agente “sabio” que guía el análisis emocional condiciona los resultados del modelo que finalmente produce el texto. En la comparación entre versiones de GPT, los autores destacan diferencias de estilo: una versión más ligera puede sonar más natural en sus expresiones, otra más grande puede estructurar mejor su análisis según teorías psicológicas, y una última versión equilibra ambas dimensiones. Estas observaciones no pretenden cerrar el debate, pero aportan pistas útiles para quienes integran modelos en productos sensibles.
Una lupa sobre cada tarea
Para entender mejor el alcance del banco de pruebas conviene detenerse en las piezas individuales y mirar qué pregunta plantea cada una.
En clasificación la virtud es la resiliencia al ruido. El sistema debe resistir pasajes largos donde la emoción objetivo aparece como una hebra del tejido, no como un cartel luminoso. Un diálogo real está lleno de segmentos informativos que no son emocionales. Saber filtrar sin perder sensibilidad es lo que distingue a un buen asistente de un autocompletado.
En detección la clave es el contraste. En un grupo de mensajes similares aparece una nota que desafina. Distinguirla supone captar matices, no solo etiquetas gruesas. Es una habilidad útil para detectar cambios de ánimo, señales de alarma o escaladas de tensión.
En preguntas y respuestas la exigencia es doble. Por un lado, comprender material psicológico extenso que incluye conceptos técnicos. Por otro, responder con precisión y economía. Aquí la evaluación automática favorece soluciones que no divagan y que justifican su salida sin inventar.
En conversación el énfasis está en la progresión. No se trata de dar un consejo amable, sino de adecuar el estilo a cada etapa. Recibir e indagar, formular una hipótesis diagnóstica, intervenir con herramientas apropiadas, cerrar la sesión con claridad. Las métricas reflejan ese itinerario y estimulan un comportamiento consistente del sistema.
En resumen la tensión central es organizar. Un buen resumen no repite, estructura. Cuando la fuente es una sesión con carga emocional, esa estructura debe distinguir causas, síntomas, proceso y efectos, sin moralizar ni borrar la ambivalencia que muchas veces acompaña al dolor o la mejora.
En expresión el reto es inhabitual. Se coloca al modelo en primera persona y se le pide que asuma un estado afectivo, responda un instrumento estandarizado y narre su experiencia. El objetivo no es teatralizar, sino observar si la narración dialoga con lo que el propio test indica. La coherencia entre medición y relato es un termómetro significativo de control emocional.
Usar un gran modelo como juez tiene ventajas evidentes. Escala bien, mantiene criterios homogéneos y permite revisar cientos de ejemplos con rapidez. También plantea riesgos. Si el juez comparte sesgos con los participantes, puede favorecer ciertos estilos sobre otros y consolidar preferencias de formato. LongEmotion intenta mitigar el problema con métricas diseñadas explícitamente, que descomponen la evaluación en dimensiones observables y convalidan correlación con especialistas humanos en tareas sensibles como la conversación. Aun así, la comunidad deberá seguir afinando protocolos de auditoría para evitar círculos cerrados donde los modelos se juzgan a sí mismos sin control externo.
El impacto potencial de un banco como LongEmotion trasciende el interés académico. Plataformas de salud mental, servicios de atención al cliente, tutores personalizados y asistentes de productividad que operan durante semanas con el mismo usuario necesitan continuidad emocional. Un mal consejo puede corregirse. Una respuesta fría en un día difícil puede erosionar la confianza. Una recaída ignorada por falta de memoria afectiva puede tener consecuencias serias. Evaluar y mejorar la coherencia emocional en contextos largos es una condición para desplegar sistemas responsables.
Además, un enfoque de este tipo ayuda a los equipos de producto a diseñar políticas. Si el análisis muestra que la recuperación aumentada del propio historial reduce errores, conviene invertir en pipelines de conversación persistente con filtros de relevancia. Si se observa que la colaboración multiagente aumenta la riqueza expresiva, puede ser preferible un backend que orqueste roles antes que un modelo único que lo haga todo. La evaluación deja de ser un número suelto y pasa a informar decisiones de arquitectura.
Límites y desafíos abiertos
Como toda propuesta ambiciosa, LongEmotion convive con limitaciones que la propia comunidad deberá trabajar.
Primero, la dependencia parcial de un juez automático y la necesidad de validar con más población humana. Aunque se reporta alta correlación en escenarios puntuales, sería deseable ampliar la diversidad de evaluadores y someter las métricas a revisiones cruzadas en distintos idiomas y culturas.
Segundo, la cobertura disciplinar. El banco utiliza literatura y marcos de la psicología que aportan seriedad. A futuro, sumar corpus clínicos anonimizados, materiales educativos, contextos laborales o interacciones de soporte técnico podría mejorar la representatividad de emociones aplicadas a dominios heterogéneos.
Tercero, la robustez a manipulaciones. Un modelo puede aprender a escribir con tono empático sin realmente integrar el contexto. Gestos de superficie bastan para conformar a un evaluador demasiado permisivo. Diseñar métricas que castiguen la grandilocuencia vacía y premien la referencia específica al historial del usuario es un camino necesario.
Cuarto, el costo computacional. Contextos largos exigen memoria y atención sostenida, lo que se traduce en recursos. Las estrategias de compresión, resúmenes intermedios y memoria selectiva deberán integrarse con cuidado para no perder la riqueza emocional que se intenta preservar.
Quinto, la seguridad. Trabajar en dominios sensibles demanda protocolos de escalamiento a humanos ante señales de riesgo, y políticas claras para frenar o redirigir una conversación cuando el sistema detecta indicadores de daño. Un buen resultado en un benchmark no sustituye la ética de diseño.
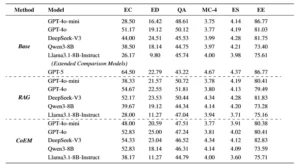
Resultados del experimento en diferentes entornos de estimulación (Base, RAG, CoEM). EC representa la Clasificación de Emociones, ED representa la Detección de Emociones, QA representa el Control de Calidad de Emociones, MC-4 representa la cuarta etapa de la Conversación de Emociones, ES representa el Resumen de Emociones y EE representa la Expresión de Emociones.
Dos sugerencias para leer estos resultados con lupa
- No confundir cortesía con comprensión. Un modelo puede sonar amable y aun así no registrar el hilo emocional que la persona trae desde el principio.
- Valorar el proceso, no solo el final. Las mejoras que introducen la recuperación aumentada y el modelo colaborativo sugieren que la ingeniería del flujo y la selección de pistas son tan importantes como el tamaño del modelo.
Más allá de los números, el artículo deja enseñanzas prácticas para quienes construyen productos con modelos de lenguaje.
Una primera lección es que la memoria sin selección es contraproducente. Guardar todo no equivale a entender. La recuperación aumentada que usa la propia conversación como archivo, con filtros de relevancia y reordenamiento, aporta una forma concreta de recordar lo que importa. El máximo de tokens deja de ser un límite rígido para convertirse en un recurso estratégico que se administra.
Una segunda lección es que la colaboración por etapas ordena el caos. Dividir la tarea en fragmentación, ranking, enriquecimiento multiagente, reordenamiento y generación final permite que cada paso agregue valor sin interferir con el siguiente. La especialización, bien diseñada, no fragmenta, coordina.
Una tercera lección es que la evaluación debe reflejar el propósito. Si la aplicación busca acompañar, conviene medir continuidad, empatía y referencia al historial. Si busca resumir, hay que penalizar la omisión y la falta de claridad. LongEmotion se inscribe en esa filosofía de métricas alineadas con objetivos.
Un punto de comparación con otros esfuerzos
En los últimos años hubo trabajos que intentaron tomar la medida de la inteligencia emocional de los modelos y del manejo de contextos extensos. Algunos bancos ofrecieron preguntas cuidadosamente redactadas y revelaron la distancia con el rendimiento humano. Otros se enfocaron en documentación prolongada o en memoria de largo plazo. LongEmotion cruza ambas líneas. Evalúa emociones y lo hace en escenarios de gran longitud. Esa intersección es valiosa porque orienta el desarrollo hacia sistemas capaces de sostener vínculos, no solo de resolver consultas.
El uso de métricas inspiradas en marcos terapéuticos, la construcción de diálogos por etapas y la inclusión de una tarea de expresión del propio estado del modelo aportan originalidad. Aun si uno discrepa con una métrica o con un ejemplo, la dirección general es difícil de negar: el futuro de la IA conversacional pasa por la continuidad emocional y por la capacidad de razonar sobre pistas afectivas distribuidas en el tiempo.
El propio trabajo bosqueja líneas de continuación. Por un lado, ampliar idiomas y culturas para evitar sesgos y para estudiar cómo varía la expresión emocional según contextos sociales. Por otro, integrar memoria a largo plazo que combine almacenamiento selectivo con mecanismos de actualización. También queda en la agenda comparar jueces humanos y automáticos de manera más sistemática, con protocolos de doble ciego y análisis de discrepancias.
En paralelo, la ingeniería del aprendizaje puede beneficiarse de una didáctica interna. Si los modelos aprenden a explicar por qué eligieron un fragmento, por qué asignaron una emoción o por qué adoptaron cierto tono, la evaluación del proceso será más sólida y la depuración más veloz. No se trata de exigir conciencia, sino de hacer visible la cadena de decisiones.
La popularización de asistentes emocionales trae responsabilidades. Quienes legislan y quienes contratan servicios deberían exigir pruebas de continuidad afectiva y no solo de precisión semántica. Un banco de pruebas como LongEmotion ayuda a fijar estándares, porque transforma la noción difusa de empatía en métricas controlables, con procedimientos reproducibles. No soluciona el problema de fondo, pero da herramientas para separar marketing de ingeniería.
En entornos clínicos o educativos, la regulación puede requerir que los modelos pasen por baterías de evaluación que incluyan tareas similares a las de LongEmotion, y que documenten su rendimiento por etapa, con auditorías periódicas. En soporte al cliente, las empresas pueden usar estos resultados para entrenar a sus modelos en protocolos de desescalamiento y para diseñar umbrales de derivación a agentes humanos.
Síntesis final
LongEmotion coloca una pregunta incómoda en el centro del desarrollo actual: de qué sirve un sistema que responde bien a una consulta aislada si pierde el hilo emocional cuando la charla se estira. La respuesta del artículo es construir un espejo más fiel a la realidad, con seis tareas que abarcan lectura, diálogo, resumen y expresión, y con dos estrategias que elevan el piso de rendimiento cuando el contexto se vuelve largo. La recuperación aumentada que mira la propia conversación y el modelo colaborativo de cinco etapas no son trucos de laboratorio. Son recetas de ingeniería aplicables, que se alinean con lo que sabemos sobre memoria, atención y especialización.
Queda mucho por afinar. Las métricas deben seguir madurando, los jueces automáticos tienen que contrastarse con humanos en distintas culturas, y la comunidad necesita acuerdos para traducir estos avances a prácticas de diseño seguras. Aun así, el paso es significativo. Pone el listón donde corresponde: en la capacidad de sostener una conversación que respete lo que una persona siente, recuerda y necesita a lo largo del tiempo. En ese sentido, LongEmotion no es solo un benchmark. Es un recordatorio de que la inteligencia artificial, para ser útil, debe aprender a convivir con la duración, la ambivalencia y la continuidad que hacen a nuestra vida emocional.
Referencias
Liu, W., Xiong, J., Hu, Y., Li, Z., Tan, M., Mao, N., Zhao, C., Wan, Z., Tao, C., Xu, W., Shen, H., Li, C., Kong, L., & Wong, N. (2025). LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction. arXiv:2509.07403.
Sabour, S., Liu, S., Zhang, Z., Liu, J. M., Zhou, J., Sunaryo, A. S., Li, J., Lee, T., Mihalcea, R., & Huang, M. (2024). EmoBench: Evaluating the Emotional Intelligence of Large Language Models. arXiv:2402.12071.
Bai, Y., et al. (2023). LongBench: A Bilingual, Multitask Benchmark for Long-Context Understanding. arXiv:2308.14508.
Li, J., Wang, M., Zheng, Z., & Zhang, M. (2023). LooGLE: Can Long-Context Language Models Understand Long Contexts. arXiv:2311.04939.
Ni, X., Cai, H., Wei, X., Wang, S., Yin, D., & Li, P. (2024). XL Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies. arXiv:2404.05446.
Zhang, J., et al. (2024). CPsyCoun: A Chinese Benchmark for Evaluating Psychology using Examinations. arXiv:2405.10212.
Zhong, W., Guo, L., Gao, Q., Ye, H., & Wang, Y. (2024). MemoryBank: Enhancing Large Language Models with Long-term Memory. AAAI 38, 19724–19731.
Beck, J. (2021). Cognitive Behavior Therapy. Guilford Press.
Waltz, T. J., & Hayes, S. C. (2010). Acceptance and Commitment Therapy. In Cognitive and Behavioral Theories in Clinical Practice. Guilford Press.
Russell, J. A. (1980). A circumplex model of affect. Journal of Personality and Social Psychology, 39(6), 1161–1178.

