
Por Elena Vargas, Periodista Especializada en Ciencia y Tecnología, para Mundo IA
El nuevo barómetro de la inteligencia: las máquinas ante el espejo de nuestra ignorancia
Durante la última década, hemos sido testigos de una procesión casi ininterrumpida de triunfos de la inteligencia artificial. La hemos visto derrotar a los grandes maestros en los juegos más complejos concebidos por la mente humana, como el ajedrez y el Go. La hemos observado generar arte de una belleza inquietante, componer música que conmueve y escribir código con una eficiencia sobrehumana. Para medir este avance vertiginoso, la comunidad científica ha diseñado un arsenal de exámenes y pruebas, conocidos en la jerga técnica como benchmarks. Estos sistemas de evaluación son para la IA lo que las olimpiadas son para los atletas: un campo estandarizado para medir la fuerza, la agilidad y la destreza. Lo que no se puede medir, al fin y al cabo, no se puede mejorar.
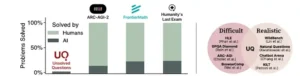
En esta carrera por cuantificar la inteligencia de las máquinas, han surgido dos grandes filosofías. La primera es la del examen académico. Pruebas como la célebre MMLU, que abarca 57 materias desde la historia hasta el derecho, o la aún más formidable Humanity’s Last Exam, diseñada por expertos para ser casi imposible, presentan a los modelos un conjunto de preguntas con respuestas ya conocidas. Son desafíos difíciles, sin duda, pero artificiales. Ningún usuario en el mundo real se comunica con una IA planteándole un problema de opción múltiple de física de partículas extraído de un examen de posgrado. La segunda filosofía es la del mundo real. Plataformas como Chatbot Arena o WildBench recopilan preguntas auténticas de usuarios, evaluando a los modelos en su capacidad para ser útiles en conversaciones cotidianas. Estos son escenarios realistas, pero a menudo las preguntas son sencillas, repetitivas o ya han sido respondidas miles de veces en la web.
Esta dicotomía ha creado una tensión fundamental en el corazón de la investigación en IA. Las pruebas son o muy difíciles pero poco realistas, o muy realistas pero a menudo demasiado fáciles para las capacidades de los modelos más avanzados, que saturan estos exámenes con una velocidad asombrosa. ¿Cómo podemos, entonces, medir de forma significativa el verdadero avance de la inteligencia artificial? ¿Cómo diseñamos una prueba que sea, a la vez, un desafío formidable para las máquinas más potentes y un reflejo genuino de los problemas que realmente importan?
Un equipo de investigadores de algunas de las instituciones más prestigiosas del mundo, como la Universidad de Stanford y la Universidad de Washington, ha propuesto una solución tan radical como elegante, presentada en un trabajo que podría cambiar la forma en que concebimos la evaluación de la IA. Su idea es simple en su enunciado y profunda en sus implicaciones: dejar de medir a las máquinas con los problemas que ya hemos resuelto y empezar a evaluarlas con aquellos que, como especie, aún no podemos responder. El proyecto, bautizado como UQ por Unsolved Questions (Preguntas sin Resolver), plantea un cambio de paradigma. En lugar de un examen estático con un solucionario, UQ es un ecosistema dinámico que confronta a los modelos de lenguaje más avanzados con las fronteras del conocimiento humano.
Para lograrlo, los artífices de este nuevo barómetro han construido un sistema de tres pilares interconectados. El primero es el UQ-Dataset, un tesoro de 500 preguntas cuidadosamente seleccionadas de entre millones, que abarcan desde las matemáticas más abstractas hasta la historia o la ciencia ficción, y que comparten una característica esencial: nadie en la vasta comunidad de expertos de internet ha sido capaz de ofrecer una respuesta satisfactoria. El segundo pilar es el UQ-Validator, un conjunto de estrategias algorítmicas diseñadas para una tarea casi paradójica: juzgar la corrección de una posible respuesta sin conocer de antemano la solución verdadera. Es un juez que no tiene el libro de leyes, pero que ha sido entrenado para detectar contradicciones, errores lógicos y falacias. Finalmente, el tercer componente es la UQ-Platform, una plataforma abierta y colaborativa donde la comunidad de expertos humanos interviene para verificar las soluciones que han logrado pasar el filtro de los validadores automáticos, completando así un ciclo de evaluación que es a la vez riguroso, continuo y transparente.
La propuesta de UQ es, en esencia, una invitación a cambiar el propósito de los benchmarks. Ya no se trata solo de obtener una puntuación para una tabla de clasificación. Se trata de crear un motor de descubrimiento, un sistema en el que cada punto obtenido por una inteligencia artificial representa una pequeña pero genuina expansión de la frontera del conocimiento humano. Es un espejo en el que, por primera vez, no le pedimos a las máquinas que reflejen lo que ya sabemos, sino que nos ayuden a vislumbrar lo que aún ignoramos.
El arte de encontrar la pregunta perfecta
El corazón de este proyecto ambicioso es, por supuesto, la colección de preguntas. ¿Dónde encontrar interrogantes que sean a la vez un desafío genuino y de relevancia para las personas? La respuesta estaba en una de las bibliotecas de conocimiento colectivo más grandes del mundo: la red de sitios de preguntas y respuestas Stack Exchange. Lugares como Stack Overflow para la programación o MathOverflow para las matemáticas son crisoles donde cada día miles de expertos y aficionados plantean y resuelven dudas. Pero entre las millones de conversaciones, existen joyas ocultas: preguntas que, a pesar de atraer la atención de mentes brillantes, permanecen sin respuesta durante años.
El equipo de investigación se embarcó en una expedición digital monumental para encontrar estas agujas en un pajar de más de tres millones de preguntas candidatas. Para ello, diseñaron un meticuloso proceso de filtrado en tres etapas, una especie de destilación progresiva para aislar solo los problemas más puros y desafiantes.
La primera etapa fue un filtrado basado en reglas. Los investigadores aplicaron una serie de criterios heurísticos para hacer una primera criba masiva. Por ejemplo, una pregunta debía tener al menos dos años de antigüedad, asegurando que la comunidad había tenido tiempo suficiente para intentar resolverla. Debía haber atraído un número significativo de visitas y de votos positivos, lo que indica que la comunidad la consideraba interesante y bien formulada. Y, crucialmente, no debía tener ninguna respuesta aceptada por quien la formuló originalmente. Estas reglas, sencillas pero efectivas, redujeron el vasto océano de tres millones de candidatos a un estanque mucho más manejable de aproximadamente 34.000 preguntas.
La segunda etapa introdujo un giro fascinante: usar la propia inteligencia artificial para juzgar la calidad de las preguntas. Los investigadores emplearon un enfoque de dos modelos. Primero, le pedían a un modelo de lenguaje de propósito general que intentara responder a cada una de las 34.000 preguntas. Luego, un segundo modelo, especializado en razonamiento, evaluaba no la respuesta, sino la pregunta original, utilizando la respuesta generada como un indicio de su dificultad. Si la IA podía responderla fácilmente, la pregunta probablemente no era lo bastante difícil. Este juez algorítmico evaluaba cada interrogante según cuatro criterios fundamentales. Debía ser bien definida, es decir, clara y sin ambigüedades. Debía ser difícil, no solo para la IA, sino también para expertos humanos. Tenía que ser abordable, lo que significa que, en principio, una solución es posible, descartando problemas mal planteados o paradójicos. Y finalmente, debía ser objetiva, buscando una respuesta verificable en lugar de una opinión. Este sofisticado filtro de IA redujo el conjunto a poco menos de 8.000 preguntas de alta calidad.
La tercera y última etapa devolvió el control a los humanos. Un equipo de revisores, con formación de doctorado en diversas disciplinas, examinó las preguntas restantes. Su misión era realizar el control de calidad final, descartando duplicados, problemas triviales que se hubieran colado por los filtros o preguntas que, a pesar de todo, no cumplían con el espíritu del proyecto. Este toque humano y experto fue el que cinceló la colección final: un conjunto de 500 preguntas que representan la cúspide de lo que es a la vez difícil, relevante y, hasta ahora, irresoluble.
La diversidad de este conjunto final es asombrosa y es una de sus mayores fortalezas. Hay problemas de matemática pura que indagan sobre la estructura de los anillos de enteros, un concepto del álgebra abstracta. Hay desafíos de la teoría de la computación que exploran los límites de los algoritmos bajo ciertas hipótesis. Pero también hay interrogantes de dominios inesperadamente humanos. Por ejemplo, una pregunta de historia busca identificar cuál fue la primera carretera terrestre que conectó Suecia y Finlandia, un dato perdido entre siglos de cambios de fronteras y la evolución de las infraestructuras. Otra, del foro de ciencia ficción, pide identificar un relato corto de los años 70 a partir de una descripción detallada de su trama, un desafío a la memoria cultural y a la capacidad de búsqueda de la máquina. Esta variedad asegura que el benchmark UQ no mida una única forma de inteligencia, sino un espectro de capacidades que incluyen el razonamiento lógico, la factualidad histórica y la habilidad para navegar y sintetizar información dispersa.
Juzgar sin saber la respuesta
Una vez compilado el desafiante temario, surgía el problema más complejo de todos: ¿cómo se corrige un examen del que nadie tiene el solucionario? En los benchmarks tradicionales, la evaluación es simple. Se compara la respuesta del modelo con la respuesta correcta y se asigna una puntuación. Pero con las preguntas sin resolver, esta aproximación es imposible. El equipo de UQ tuvo que inventar una nueva forma de evaluar, un método para «validar» respuestas en ausencia de una verdad fundamental conocida.
La idea central que sustenta su solución es una observación sutil pero poderosa sobre la inteligencia, tanto humana como artificial: a menudo es mucho más fácil reconocer una respuesta correcta que generarla desde cero. Pensemos en un problema matemático complejo. Producir la demostración puede requerir un golpe de genio, pero verificar si una demostración ya escrita es lógicamente coherente es una tarea más metódica y, en muchos sentidos, más sencilla. Los investigadores denominaron a esta diferencia la «brecha entre generador y validador». Sus experimentos confirmaron una hipótesis clave: a medida que los modelos de IA se vuelven más potentes, su habilidad para validar respuestas mejora mucho más rápido que su habilidad para generarlas. Un modelo puede ser incapaz de resolver un problema, pero ser sorprendentemente bueno detectando errores en la solución propuesta por otro.
Armados con esta idea, diseñaron un sistema de validación jerárquico, una especie de proceso judicial algorítmico con múltiples niveles de escrutinio. Para poner a prueba estas estrategias, utilizaron de forma inteligente otro benchmark, el ya mencionado Humanity’s Last Exam. Dado que este examen sí tiene respuestas conocidas, les sirvió como un campo de pruebas perfecto para calibrar la precisión de sus validadores antes de aplicarlos a las preguntas verdaderamente sin resolver de UQ.
El primer nivel de validación consiste en estrategias de bajo nivel, que son como los controles básicos que un detective realizaría en la escena de un crimen. Un modelo juez evalúa si la respuesta es correcta en apariencia, si contiene errores factuales o lógicos evidentes, o si mantiene la consistencia cíclica. Esta última es una técnica ingeniosa: el validador lee la respuesta y trata de inferir cuál habría sido la pregunta original que la generó; si esa pregunta inferida se parece mucho a la pregunta real, es un buen indicio de que la respuesta es relevante y no una divagación.
El segundo nivel de validación introduce estrategias de nivel medio, diseñadas para mejorar la robustez de los juicios. En lugar de preguntar una sola vez, se puede usar un muestreo repetido, pidiendo al juez su veredicto varias veces para ver si es consistente. Aún más sofisticada es la reflexión iterada, donde se le pide al modelo juez que «piense dos veces», reevaluando su juicio inicial y buscando posibles fallos en su propio razonamiento.
Finalmente, el tercer nivel de validación despliega estrategias de alto nivel para agregar múltiples juicios en un veredicto final. Se puede usar una votación por mayoría, donde una respuesta se aprueba si más de la mitad de los juicios son positivos. Un método más estricto es la votación unánime, que exige que todos los juicios sean favorables. La estrategia más potente que desarrollaron es la verificación en cadena (pipeline), un proceso de tres turnos. Una respuesta candidata primero debe pasar el control de consistencia cíclica; si lo logra, avanza al segundo turno, el chequeo de hechos y lógica; solo si supera este, llega al tercer y último turno, el juicio de corrección final.
Los resultados de experimentar con estos validadores fueron reveladores. Descubrieron que las estrategias compuestas, como la cadena de verificación, eran significativamente más precisas que un simple juicio rápido. Sin embargo, también se toparon con un desafío persistente: la dificultad de alcanzar una alta precisión. Los mejores validadores todavía aprobaban un número considerable de respuestas incorrectas. Otra revelación importante fue la del sesgo. Los modelos de lenguaje, al igual que los humanos, a menudo muestran un considerable sesgo de autoevaluación, una tendencia a calificar sus propias respuestas, o las de modelos de su misma «familia» de desarrolladores, de forma demasiado optimista. La buena noticia fue que sus estrategias de validación más complejas y por etapas lograban mitigar significativamente este sesgo, promoviendo una evaluación más justa. Quizás el hallazgo más aleccionador fue la inestabilidad de las clasificaciones. Dependiendo del validador utilizado, el ranking de los mejores modelos de IA podía cambiar drásticamente, demostrando que confiar en un único juez automático para crear una tabla de clasificación definitiva es, por ahora, una quimera.
Una plataforma para la inteligencia colectiva
El sistema de validadores, a pesar de su sofisticación, no es infalible. Los investigadores reconocieron desde el principio que la evaluación de problemas en la frontera del conocimiento no podía ser una tarea puramente automatizada. El juicio humano, especialmente el de los expertos en cada dominio, seguía siendo la pieza insustituible del rompecabezas. Así nació el tercer pilar del proyecto: la UQ-Platform.
Esta plataforma web es la culminación del ciclo de evaluación. Es un espacio abierto diseñado para ser un espejo de Stack Exchange, pero adaptado a la interacción con la inteligencia artificial. En ella se aloja el conjunto de las 500 preguntas. Para cada una, se muestran las respuestas candidatas generadas por los modelos de IA más avanzados. Junto a cada respuesta, se presenta el veredicto del UQ-Validator, incluyendo el rastro de razonamiento que siguió el juez algorítmico para llegar a su decisión.
Aquí es donde la comunidad entra en juego. La plataforma invita a expertos de todo el mundo a revisar las respuestas que lograron pasar el filtro automático. Estos expertos humanos pueden calificar las soluciones, señalar errores que el validador no detectó o, en el caso más emocionante, confirmar que una respuesta generada por una máquina es, de hecho, correcta y novedosa. La plataforma está diseñada para ser un ecosistema vivo. A medida que los modelos de IA mejoren, podrán enviar nuevas y mejores respuestas. A medida que se resuelvan preguntas, se podrán añadir nuevos desafíos del vasto repositorio de candidatos. La calidad de la evaluación, por tanto, se compone y mejora con el tiempo, gracias a la sinergia entre la eficiencia del cribado automático y el rigor de la verificación humana.
Y entonces, ¿cuál fue el veredicto final sobre el estado actual de la inteligencia artificial? Los resultados de la primera evaluación en la plataforma UQ son una lección de humildad para la industria tecnológica. Los modelos más potentes del mundo, aquellos que superan a los humanos en tantos otros exámenes, tuvieron un desempeño muy bajo. El sistema con mejor rendimiento solo logró que un 15% de sus respuestas pasaran el filtro del UQ-Validator. De ese pequeño porcentaje, el equipo del proyecto, con la ayuda de expertos y de los propios autores de las preguntas originales, inició un minucioso proceso de verificación humana.
Los resultados de esta verificación son fascinantes. En muchos casos, los modelos producían respuestas que parecían plausibles pero que contenían errores sutiles, como citar referencias bibliográficas que no existían, una forma de «alucinación» que los validadores no siempre lograban detectar. Sin embargo, en medio de los fracasos, surgieron destellos de verdadero progreso. De las 91 respuestas validadas que pudieron ser verificadas por humanos en esta fase inicial, un total de 10 fueron consideradas correctas. Un modelo en particular, denominado o3-PRO, destacó al proporcionar al menos cuatro soluciones que fueron aceptadas por los revisores humanos, resolviendo problemas de matemáticas y física que habían permanecido abiertos durante años. En un caso notable, un modelo proporcionó el procedimiento matemático detallado para calcular la temperatura de equilibrio de un planeta en órbita de un agujero negro, una pregunta inspirada en la película Interstellar. El propio autor de la pregunta en la comunidad de física confirmó que la respuesta era excelente y que le proporcionaba los detalles que necesitaba. Cada una de estas diez soluciones no es solo una marca en un marcador; es una contribución tangible al acervo de conocimiento humano, originada por una inteligencia no biológica.

UQ – Dataset: una colección de preguntas sin resolver con propiedades deseables.
Más allá de la puntuación, el descubrimiento
El proyecto UQ es mucho más que un nuevo y más difícil examen para la inteligencia artificial. Representa una maduración en nuestra relación con estas tecnologías y un cambio fundamental en el propósito de su evaluación. Durante años, hemos medido a las máquinas con la vara de nuestro propio conocimiento pasado. Les hemos pedido que aprendan nuestros idiomas, que reconozcan nuestras imágenes, que resuelvan los problemas que nosotros ya resolvimos. UQ propone una nueva dirección: invitar a las máquinas a ser nuestras compañeras en la exploración de lo desconocido.
La relevancia de este trabajo trasciende el ámbito técnico de los laboratorios de IA. A nivel científico, establece una metodología para utilizar la IA como una herramienta de descubrimiento. Al enfocar los modelos más potentes en problemas genuinamente abiertos, UQ transforma un ejercicio de evaluación en un motor para la ciencia. Cada vez que una pregunta de la plataforma es marcada como «resuelta» por una IA, el resultado es una nueva pieza de conocimiento que puede ser utilizada por matemáticos, físicos o historiadores en sus propias investigaciones. Se crea así un ciclo virtuoso en el que el progreso en la capacidad de la IA se traduce directamente en progreso científico.
A nivel tecnológico, UQ expone con una claridad implacable las verdaderas limitaciones de los modelos actuales. Demuestra que, a pesar de su impresionante fluidez y su vasto conocimiento factual, estas máquinas todavía luchan con el razonamiento profundo y novedoso que se requiere para resolver problemas en la frontera. Esto proporciona una guía invaluable para los desarrolladores, señalando las áreas donde se necesita más investigación, como la reducción de las alucinaciones o la mejora del razonamiento lógico en múltiples pasos.
Y a nivel social, este nuevo paradigma nos obliga a reflexionar sobre el futuro rol de la inteligencia artificial en nuestra sociedad. UQ nos muestra un camino en el que la IA no es simplemente un oráculo que nos da respuestas de su vasto almacén de datos, sino un colaborador creativo que puede ayudarnos a formular nuevas preguntas y a explorar soluciones a problemas complejos. Nos empuja a imaginar un futuro en el que un investigador humano y un sistema de IA trabajen codo con codo, cada uno aportando sus fortalezas únicas, para acelerar el ritmo del descubrimiento en todos los campos del saber.
El proyecto de las Preguntas sin Resolver no es un punto de llegada, sino un punto de partida. Es un sistema diseñado para evolucionar, para volverse más difícil a medida que las máquinas se vuelven más inteligentes. Es un barómetro que, en lugar de medir la distancia que la IA ha recorrido, mide la inmensidad del territorio que aún nos queda por explorar. Al enfrentarlas al espejo de nuestra propia ignorancia, no solo obtenemos una medida más honesta y significativa de la inteligencia de las máquinas, sino que también abrimos una nueva y emocionante vía para expandir la nuestra.
Referencias
Nie, F., Liu, K. Z., Wang, Z., Sun, R., Liu, W., Zhang, L., Ng, A. Y., Shi, W., Yao, H., Zou, J., Koyejo, S., Choi, Y., Liang, P., & Muennighoff, N. (2025). UQ: Assessing Language Models on Unsolved Questions. arXiv preprint arXiv:2508.17580.

