
Por Elena Vargas, Periodista Especializada en Ciencia y Tecnología, para Mundo IA
Cómo Paper2Agent transforma la investigación en una conversación
En el vasto y venerable archivo del conocimiento humano, el artículo de investigación científica se erige como la unidad fundamental de progreso, la cápsula del tiempo a través de la cual los descubrimientos se comunican, se validan y se transmiten a las generaciones futuras. Durante siglos, este formato ha permanecido inalterado en su esencia: un documento estático, un monólogo del autor al lector, una fotografía congelada de un momento de la ciencia. Leemos sus páginas, asimilamos sus gráficos y seguimos sus ecuaciones, pero no podemos conversar con él. No podemos pedirle que aclare una sección ambigua, que ejecute el código que describe, o que aplique su metodología a un nuevo conjunto de datos. Esta naturaleza pasiva, aunque venerable, representa una barrera cada vez más formidable en una era definida por la interactividad y la abrumadora velocidad de la innovación. ¿Y si pudiéramos reimaginar radicalmente esta forma fundamental de comunicación? ¿Y si un artículo de investigación pudiera cobrar vida?
Esta es la audaz pregunta que se encuentra en el corazón de un trabajo transformador que busca convertir estos textos inertes en entidades dinámicas, interactivas y fiables. La propuesta, denominada Paper2Agent, no es una mera mejora incremental, sino una reinvención fundamental del artículo científico. El objetivo es transmutar el PDF estático en un agente de inteligencia artificial, un colaborador digital que encarna el conocimiento y las capacidades descritas en el documento. Este agente, nacido del propio texto, podría responder a preguntas con una fidelidad inquebrantable a la fuente, ejecutar el software descrito para replicar resultados o analizar nuevos datos, y guiar a los usuarios a través de las complejidades del trabajo con la paciencia de un tutor experto. Es la visión de un futuro en el que acceder a la ciencia no sea solo un acto de lectura, sino un acto de diálogo.
Para el no iniciado, el concepto de un «agente de IA» puede evocar imágenes de ciencia ficción, pero en este contexto, su significado es a la vez preciso y poderoso. Un agente es un sistema de inteligencia artificial que no solo procesa información, sino que puede percibir su entorno, tomar decisiones y ejecutar acciones para lograr un objetivo específico. El sistema Paper2Agent dota a cada artículo de investigación de esta capacidad. Para lograrlo, extrae y organiza meticulosamente cada gramo de información del documento en una estructura coherente que sirve como la «mente» del agente. Esta mente se compone de tres elementos cruciales. Primero, una Base de Conocimiento, que actúa como la memoria enciclopédica del agente, conteniendo cada hecho, cifra y ecuación del documento original, garantizando que sus respuestas estén siempre ancladas en la verdad del texto. Segundo, un conjunto de Herramientas, que son, en esencia, las «manos» del agente. Estas son piezas de código ejecutables, extraídas o generadas a partir del artículo, que le permiten realizar las tareas prácticas descritas, como ejecutar un algoritmo o trazar un gráfico. Finalmente, un Perfil del Agente, que le confiere una identidad y un propósito, guiando su comportamiento para que actúe como un asistente útil y fiable.
La creación de un agente de este tipo es un proceso de múltiples etapas, una alquimia digital que transforma el lenguaje natural y los fragmentos de código de un PDF en una entidad funcional. Pero la generación es solo la mitad de la batalla. Un agente científico debe ser, por encima de todo, fiable. Para medir esta fiabilidad, los investigadores han desarrollado un nuevo y riguroso campo de pruebas llamado Agent-Eval. A diferencia de los benchmarks tradicionales, que a menudo evalúan a las IA con preguntas de opción múltiple, Agent-Eval somete a los agentes a un interrogatorio mucho más realista: diálogos de varias vueltas que simulan las interacciones que un verdadero investigador tendría con el documento. Evalúa la capacidad del agente para responder con precisión, para utilizar sus herramientas correctamente y para mantener una conversación coherente, juzgando no solo la corrección de sus respuestas, sino su fidelidad a la fuente, su fiabilidad y su utilidad general.
Paper2Agent no es una visión lejana; es un prototipo funcional que señala el camino hacia una nueva era de la comunicación científica. Una era en la que los artículos de investigación ya no serán mausoleos de conocimiento, sino laboratorios vivos, tutores interactivos y colaboradores incansables. Es el comienzo de una transformación que promete democratizar el acceso a la ciencia, acelerar el ritmo del descubrimiento y cambiar para siempre la forma en que interactuamos con el vasto océano del saber humano.
La anatomía de un artículo viviente
Para que un documento estático trascienda su forma y se convierta en un agente interactivo, debe ser dotado de una estructura interna que le permita pensar y actuar. El sistema Paper2Agent logra esta metamorfosis construyendo una arquitectura cognitiva para el agente, una anatomía digital compuesta por componentes interdependientes que le otorgan memoria, capacidad de acción y un propósito definido. La comprensión de estos componentes es fundamental para apreciar la profundidad de esta reimaginación del artículo científico.
El primer y más fundamental de estos componentes es la Base de Conocimiento del Agente. Este es el cerebro del agente, su memoria a largo plazo. Su única y sagrada función es servir como un repositorio exhaustivo y perfectamente fiel de toda la información contenida en el documento original. Para construirla, el sistema procesa el PDF, extrayendo y catalogando meticulosamente cada pieza de información: el texto, las tablas, las figuras, las ecuaciones y las citas. Esta información no se almacena como un bloque de texto sin formato, sino que se procesa y se indexa de una manera que la hace fácilmente recuperable y comprensible para el modelo de lenguaje que impulsa al agente. Esta base de conocimiento actúa como un ancla conceptual. Cuando un usuario hace una pregunta, el agente está obligado a consultar esta base antes de formular una respuesta. Este mecanismo, conocido como Generación Aumentada por Recuperación (RAG), es la garantía de que el agente no «alucinará» ni inventará información. Sus respuestas están, por diseño, ancladas a los hechos presentados en el artículo, asegurando una fidelidad absoluta a la fuente.
El segundo componente son las Herramientas del Agente. Si la base de conocimiento es el cerebro, las herramientas son las manos y los instrumentos del agente. Son las capacidades funcionales que le permiten realizar las tareas prácticas descritas en el artículo. Estas herramientas son, en esencia, fragmentos de código ejecutables. El sistema Paper2Agent tiene la sofisticada capacidad de identificar y extraer estos fragmentos de código directamente del texto del artículo o, lo que es aún más impresionante, de generarlos a partir de las descripciones en lenguaje natural de los algoritmos y metodologías. Cada herramienta se encapsula como una función independiente con una descripción clara de lo que hace, qué entradas necesita y qué resultados produce. Esto podría incluir una herramienta para ejecutar una simulación, otra para analizar un conjunto de datos según un método estadístico específico, o una tercera para generar una visualización como las que aparecen en el documento. La disponibilidad de estas herramientas transforma al agente de un simple interlocutor a un verdadero asistente de laboratorio, capaz de replicar los experimentos del artículo o aplicarlos a nuevos problemas.
Finalmente, el tercer componente es el Perfil del Agente. Este es el elemento que le da al agente su identidad, su personalidad y sus directrices de comportamiento. El perfil es una descripción concisa, generada por un modelo de lenguaje, que resume el propósito y el alcance del artículo en un formato que el propio agente puede entender. Actúa como su «directiva principal», instruyéndole sobre su rol (por ejemplo, «Eres un agente de IA que asiste a los usuarios a comprender y utilizar los métodos descritos en este artículo sobre el análisis de redes neuronales»), sus capacidades («Puedes responder preguntas sobre el contenido y ejecutar el código para analizar datos de imágenes») y sus limitaciones («No puedes ofrecer opiniones o información que no esté contenida en el documento»). Este perfil asegura que el comportamiento del agente sea coherente, enfocado y alineado con el objetivo de ser un representante útil y fiable del artículo de investigación. Juntos, estos tres componentes (conocimiento, herramientas y perfil) forman una entidad cohesiva y funcional, un verdadero agente que encarna el espíritu y la sustancia del documento del que nació.
El proceso de creación: de PDF a agente inteligente
La transmutación de un archivo PDF en un agente de inteligencia artificial es un proceso de ingeniería complejo y de múltiples etapas que se asemeja a una línea de ensamblaje automatizada para la creación de conocimiento interactivo. El sistema Paper2Agent orquesta este proceso a través de una sofisticada cadena de procesamiento que combina el análisis de documentos, el poder de los grandes modelos de lenguaje y la generación de código para dar vida al artículo.
El viaje comienza con la ingesta y el análisis del documento. El primer paso es puramente estructural: el sistema toma el archivo PDF del artículo de investigación y lo descompone en sus componentes básicos. Utilizando herramientas de análisis de documentos, extrae el texto, las tablas, las figuras, las leyendas y las ecuaciones. Este proceso no es trivial, ya que los PDF, especialmente los de formato académico con múltiples columnas y elementos gráficos complejos, pueden ser difíciles de analizar de manera precisa. El objetivo es obtener una representación limpia y estructurada del contenido, separando los diferentes tipos de información para su procesamiento posterior.
Una vez que el contenido ha sido extraído, entra en juego el poder de los grandes modelos de lenguaje (LLM). El sistema utiliza estos modelos para «leer» y «comprender» el contenido descompuesto. Esta es la fase de síntesis, donde se construyen los componentes del agente. El LLM es instruido para realizar varias tareas clave en paralelo. Primero, genera el Perfil del Agente, leyendo el resumen y la introducción para destilar la esencia del trabajo en una directiva clara y concisa. Segundo, procesa todo el texto, las tablas y las figuras para construir la Base de Conocimiento. La información se divide en fragmentos, se convierte en representaciones numéricas (embeddings) y se almacena en una base de datos vectorial, lo que permite una búsqueda semántica rápida y eficiente más adelante.
Simultáneamente, el sistema se embarca en la crucial tarea de crear las Herramientas del Agente. El LLM escanea el documento en busca de cualquier mención de código, algoritmos o metodologías computacionales. Si encuentra fragmentos de código explícitos, los extrae, los limpia y los encapsula en funciones ejecutables. Si encuentra descripciones de algoritmos en lenguaje natural o pseudocódigo, el LLM intenta generar el código Python correspondiente. Cada herramienta generada viene con una descripción detallada de su funcionalidad, extraída del contexto del artículo. Este es uno de los pasos más desafiantes, ya que requiere que el modelo no solo comprenda la intención del autor, sino que también la traduzca a un código que sea sintácticamente correcto y lógicamente fiel a la metodología descrita.
El resultado de esta línea de ensamblaje es un «paquete de agente» completo y autocontenido. Este paquete incluye el Perfil que define su propósito, la Base de Conocimiento que garantiza su fidelidad a los hechos, y un conjunto de Herramientas que le otorgan capacidades prácticas. Todo este proceso es completamente automatizado. Un investigador simplemente necesita proporcionar el PDF de su artículo, y la cadena de procesamiento de Paper2Agent se encarga de dar a luz a su contraparte digital e interactiva, lista para ser evaluada y desplegada.
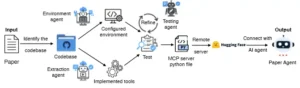
Flujo de trabajo de Paper2Agent. Comienza con la extracción del código base y la configuración automatizada del entorno para la reproducibilidad. Las características analíticas centrales se encapsulan como herramientas MCP, que luego se validan a través de pruebas iterativas. El servidor MCP resultante se despliega remotamente y se integra con un agente de IA, lo que permite la interacción en lenguaje natural con los métodos y análisis del artículo.
El crisol de la fiabilidad: el marco de evaluación Agent-Eval
Crear un agente de inteligencia artificial a partir de un artículo de investigación es una proeza técnica, pero ¿cómo podemos estar seguros de que el agente resultante es verdaderamente útil y, sobre todo, fiable? La fiabilidad es la moneda de cambio en la ciencia. Un asistente que proporciona información incorrecta o ejecuta código de manera errónea no solo es inútil, sino que puede ser activamente perjudicial, llevando a los investigadores por caminos equivocados. Conscientes de que los benchmarks existentes no estaban a la altura de esta tarea, los creadores de Paper2Agent desarrollaron un nuevo y riguroso marco de evaluación: Agent-Eval.
Agent-Eval está diseñado para ir más allá de las simples métricas de corrección y evaluar las cualidades que realmente importan en un asistente científico: la fidelidad a la fuente, la fiabilidad en la ejecución de tareas y la utilidad general en un contexto de investigación realista. Para lograr esto, este agente abandona el formato de pregunta y respuesta de un solo turno, típico de muchos benchmarks de IA, y adopta un enfoque mucho más sofisticado: el diálogo de varias vueltas.
El proceso de evaluación simula una conversación natural y extendida entre un usuario (un investigador) y el agente. Se crea un conjunto de preguntas y tareas de alta calidad, diseñadas para poner a prueba todas las facetas de la capacidad del agente. Estas tareas se dividen en varias categorías:
- Consulta de información: Preguntas directas sobre el contenido del artículo, diseñadas para probar la precisión de la Base de Conocimiento del agente y su capacidad para recuperar información sin inventarla.
- Uso de herramientas: Tareas que requieren que el agente utilice sus herramientas de código para realizar un cálculo, ejecutar una simulación o analizar un nuevo conjunto de datos proporcionado por el evaluador.
La evaluación se lleva a cabo a través de una conversación. Un evaluador (ya sea humano o un LLM avanzado actuando como juez) interactúa con el agente, planteando una pregunta tras otra, encadenando ideas y pidiendo aclaraciones. Por ejemplo, el evaluador podría primero pedir una explicación de un concepto, luego pedir al agente que ejecute el código relacionado con ese concepto, y finalmente hacer una pregunta de seguimiento sobre los resultados obtenidos. Este formato de diálogo es crucial porque revela no solo si el agente puede responder a preguntas aisladas, sino si puede mantener un razonamiento coherente, recordar el contexto de la conversación y combinar sus habilidades de recuperación de información y ejecución de herramientas de manera fluida.
Después de cada diálogo, el evaluador califica el rendimiento del agente en una escala del 1 al 5, basándose en tres criterios fundamentales: fidelidad, fiabilidad y utilidad. La fidelidad mide si las respuestas del agente están estrictamente ancladas en el contenido del artículo. La fiabilidad evalúa si las herramientas se ejecutaron correctamente y produjeron los resultados esperados. Y la utilidad juzga la calidad general de la asistencia proporcionada. Al promediar las puntuaciones de múltiples diálogos y múltiples evaluadores, Agent-Eval produce una medida holística y matizada del rendimiento de un agente, proporcionando una señal mucho más rica y significativa de su valor real que cualquier métrica de precisión simple.
El agente en acción: resultados y revelaciones
Una vez construido el marco de generación y el riguroso campo de pruebas de Agent-Eval, los investigadores pusieron a prueba su creación. Los resultados, aunque preliminares, son profundamente alentadores y revelan tanto el inmenso potencial del enfoque de Paper2Agent como las áreas donde aún se requiere un mayor desarrollo.
En las pruebas realizadas, los agentes creados con el sistema Paper2Agent demostraron una capacidad notablemente superior a los enfoques más simples, como el uso de un modelo de lenguaje genérico (como GPT-4) directamente sobre el texto del artículo. En las evaluaciones de diálogo de varias vueltas, los agentes Paper2Agent obtuvieron puntuaciones significativamente más altas en fidelidad, fiabilidad y utilidad general. Esto valida la hipótesis central del trabajo: que la estructuración explícita de un artículo en un perfil, una base de conocimiento y un conjunto de herramientas es fundamental para crear un asistente de IA verdaderamente eficaz y fiable.
Uno de los hallazgos más impresionantes fue la capacidad de los agentes para combinar de manera fluida la recuperación de información de su base de conocimiento con el uso de sus herramientas de código. Por ejemplo, un agente podía primero responder a una pregunta teórica sobre un algoritmo y luego, en la siguiente vuelta de la conversación, ejecutar ese mismo algoritmo sobre un nuevo conjunto de datos proporcionado por el usuario, demostrando una comprensión integrada tanto del «qué» como del «cómo» del artículo de investigación. Esta sinergia entre el conocimiento y la acción es lo que distingue a un verdadero agente de un simple chatbot.
Sin embargo, el estudio también arrojó luz sobre los desafíos actuales y las fronteras de la tecnología. La generación de herramientas de código a partir de descripciones en lenguaje natural sigue siendo una de las tareas más difíciles. Aunque los modelos de lenguaje modernos son sorprendentemente buenos en esta tarea, no son perfectos. En algunos casos, el código generado contenía errores sutiles o no lograba capturar completamente los matices de la metodología descrita, lo que afectaba a la fiabilidad del agente. Esto subraya la importancia de los ciclos de prueba y depuración, y sugiere que la colaboración con un supervisor humano sigue siendo crucial para garantizar la corrección del software generado.
Otra área de mejora identificada fue la capacidad de los agentes para manejar preguntas muy complejas que requieren la síntesis de información de múltiples secciones del artículo. Aunque el mecanismo de recuperación de información es potente, a veces los agentes luchaban por conectar ideas distantes en el texto para formular una respuesta integral, una habilidad en la que los expertos humanos todavía sobresalen.
A pesar de estas limitaciones, los resultados generales pintan un cuadro inequívocamente positivo. Paper2Agent no es una solución perfecta, pero es una prueba de concepto abrumadoramente exitosa. Demuestra que el camino hacia los artículos de investigación interactivos no solo es posible, sino que ya está a nuestro alcance. Los hallazgos del estudio no son un punto final, sino un punto de partida, un faro que ilumina el camino hacia un futuro en el que cada artículo científico publicado vendrá acompañado de su propio gemelo digital, un agente experto listo para colaborar en la siguiente ola de descubrimientos.
El futuro de la comunicación científica
La propuesta y la implementación de Paper2Agent trascienden los límites de un mero proyecto de investigación en inteligencia artificial; representan una profunda meditación sobre el futuro de cómo creamos, compartimos y interactuamos con el conocimiento científico. Las implicaciones de transformar los artículos de investigación en agentes interactivos son vastas y podrían catalizar un cambio de paradigma en múltiples dominios de la empresa humana.
En el ámbito de la investigación, el impacto más inmediato es la aceleración. La capacidad de interactuar con un artículo, de pedirle que replique sus propios resultados con un solo comando o que aplique sus métodos a nuevos datos, reduce drásticamente una de las mayores barreras para la construcción sobre el trabajo de otros: el tiempo y el esfuerzo necesarios para comprender e implementar nuevas metodologías. Esto podría acelerar la innovación al permitir a los científicos validar y extender el trabajo de sus colegas a una velocidad sin precedentes. Además, la fiabilidad inherente de un agente bien construido, con sus respuestas ancladas en la fuente, podría ayudar a combatir la creciente crisis de replicabilidad en muchas disciplinas científicas.
Para la educación, el potencial es igualmente transformador. Imagine a un estudiante de posgrado tratando de aprender una técnica compleja. En lugar de luchar en solitario con un texto denso, podría conversar con el agente del artículo. Podría hacer preguntas de «qué pasaría si», pedir explicaciones simplificadas de conceptos difíciles y ver el código ejecutarse paso a paso. Cada artículo se convertiría en un tutor personalizado, democratizando el acceso al conocimiento experto y haciendo que las fronteras de la ciencia sean más accesibles para la próxima generación de investigadores.
El proceso de revisión por pares, el mecanismo de control de calidad de la ciencia, también podría ser revolucionado. Los revisores podrían interactuar con el agente de un artículo enviado para verificar rápidamente la coherencia de sus afirmaciones y la corrección de sus implementaciones de código. Esto podría hacer que el proceso de revisión sea más riguroso, eficiente y transparente, elevando la calidad general de la literatura científica publicada.
Por supuesto, este futuro no está exento de desafíos. Será necesario desarrollar estándares para la creación y evaluación de estos agentes. Habrá que abordar cuestiones de coste computacional, seguridad y la posibilidad de que los agentes hereden sesgos de los modelos de lenguaje que los impulsan. Y, lo que es más importante, la comunidad científica tendrá que adaptarse culturalmente a esta nueva forma de interactuar con el conocimiento.
Sin embargo, estos desafíos son superables. Paper2Agent ha encendido una antorcha, iluminando un camino hacia un ecosistema científico más dinámico, interactivo, fiable y, en última instancia, más rápido. La visión es clara: un futuro en el que cada publicación no sea el final de una historia, sino el comienzo de innumerables conversaciones, un futuro en el que el conocimiento no solo se lee, sino que se experimenta. El artículo de investigación, el pilar de la ciencia durante siglos, está a punto de aprender a hablar.
Referencias
Paper2Agent: Reimagining Research Papers As Interactive and Reliable AI Agents. (2025). arXiv:2509.06917v1.

