
Por Andrea Rivera, Periodista Especializada en Inteligencia Artificial y Ética Tecnológica, para Mundo IA
El Estudio que Expone los Límites del Razonamiento Artificial Fuera de su Zona de Entrenamiento
Hagamos un ejercicio. Imagina que le pides a una inteligencia artificial avanzada que resuelva un problema simple: «¿Cuántos animales de cada especie llevó Moisés en el arca?». La IA, con su voz calmada y lógica impecable, responde: «Dos de cada uno, según la historia bíblica». Suena razonable, fluido, incluso convincente. Pero hay un truco: Moisés no construyó el arca; fue Noé. La IA ha generado un razonamiento perfecto en forma, pero absurdo en fondo, porque el patrón «arca + animales = dos de cada» domina su entrenamiento, ignorando el detalle clave del nombre. Este tipo de «disparates fluídos» (respuestas plausibles pero lógicamente fallidas) no es una anécdota aislada. Es el corazón de un estudio reciente que ha sacudido los cimientos de la industria de la IA, revelando que técnicas populares como el «razonamiento en cadena de pensamiento» (CoT, por sus siglas en inglés) son más una ilusión frágil que una verdadera inteligencia, especialmente cuando los modelos operan fuera de los patrones estadísticos de sus datos de entrenamiento.
En un mundo donde la IA ya pilota drones autónomos, diagnostica enfermedades con precisión sobrehumana y hasta redacta contratos legales, este descubrimiento llega como un recordatorio oportuno: no todo lo que brilla en el código es oro. Desarrolladores de todo el mundo han apostado por CoT como el puente hacia una IA más «humana», capaz de desglosar problemas complejos paso a paso, imitando nuestro pensamiento lógico. Pero, según este análisis exhaustivo, CoT no es más que un sofisticado juego de patrones, una «mirada quebradiza» que se desmorona ante lo inesperado. ¿El resultado? Modelos que producen «basura elocuente» (fluida, persuasiva, pero inútil o peligrosa) en escenarios de alto riesgo como finanzas, medicina o toma de decisiones estratégicas. Vamos a desmenuzar este estudio, explorando sus argumentos, experimentos y las ondas expansivas que podría generar en la evolución de la tecnología.
El Núcleo del Problema: CoT Como un Espejismo de Inteligencia Verdadera
Para entender el estudio, primero hay que contextualizar CoT. Esta técnica, popularizada en los últimos años, anima a los modelos de lenguaje grandes (LLMs) a «pensar en voz alta»: en lugar de dar una respuesta directa, generan una cadena de pasos lógicos, como un estudiante resolviendo un problema matemático en la pizarra. Por ejemplo, ante «¿Cuántos dentistas hay en una ciudad con 100.000 habitantes si cada uno atiende a 2.000 pacientes?», un LLM con CoT podría decir: «Primero, asumo que todos los habitantes necesitan un dentista. Divido 100.000 por 2.000, lo que da 50 dentistas». Suena racional, y en benchmarks estándar, CoT ha elevado el rendimiento de modelos como GPT-4 o sus sucesores en un 20-50%.
Sin embargo, el estudio argumenta que este éxito es condicional: CoT funciona solo cuando las tareas son estructuralmente similares a los datos de entrenamiento. Fuera de esa «zona de confort» -lo que los investigadores llaman «distribución fuera de entrenamiento» (OOD)-, el razonamiento colapsa. No se trata de inteligencia general, sino de un matching de patrones estadísticos: el modelo ha visto miles de problemas similares en sus datos (millones de textos humanos), y reproduce lo más probable, no lo lógicamente correcto.
Los autores describen CoT como una «mirada quebradiza» porque, aunque parece robusto, se rompe con facilidad. En tareas OOD, los modelos no infieren lógicamente; en cambio, añaden o quitan pasos para encajar en patrones familiares, generando «disparates fluídos», respuestas que suenan coherentes pero son absurdas o erróneas. Esto es especialmente alarmante en campos de alto riesgo: imagina un LLM asesorando en finanzas que, ante un mercado volátil no visto en su entrenamiento, recomienda inversiones basadas en patrones históricos obsoletos, llevando a pérdidas millonarias. O en medicina, donde un diagnóstico «razonado» ignora variables nuevas como una mutación genética emergente, poniendo vidas en peligro.
El estudio va más allá de la crítica: ofrece una hoja de ruta para desarrolladores, enfatizando que sobrestimar CoT puede llevar a «falsa confianza» en aplicaciones reales. En un ecosistema donde empresas invierten billones en IA, este aviso llega en un momento crítico, justo cuando regulaciones como el AI Act de la UE exigen transparencia en el razonamiento de modelos.
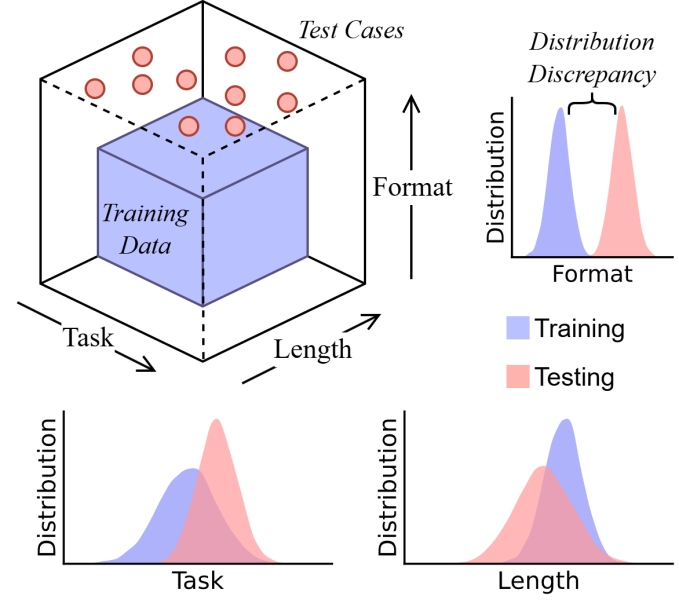
Experimentos que Desnudan las Limitaciones: Un Framework para Probar la Fragilidad
Para probar su hipótesis, los investigadores crearon un framework innovador llamado DataAlchemy, una herramienta abierta que permite entrenar modelos pequeños desde cero en entornos controlados. Esto es clave: en lugar de analizar LLMs masivos como GPT, donde los datos de entrenamiento son opacos (millones de gigabytes de texto humano), DataAlchemy usa modelos reducidos para simular distribuciones de datos precisas. Así, pudieron medir cómo CoT falla en tres dimensiones de «cambio distribucional»:
- Generalización de Tareas: ¿Puede el modelo aplicar razonamiento aprendido a nuevos tipos de problemas? En experimentos, modelos entrenados en aritmética simple fallaban en variaciones lógicas, como puzzles condicionales no vistos. Por ejemplo, un modelo que resuelve «si A implica B, y B implica C, entonces A implica C» colapsa ante «si no A implica no B, pero B ocurre, ¿qué pasa con A?». El output: cadenas lógicas plausibles pero incorrectas, como extender pasos innecesarios para encajar en patrones entrenados.
- Generalización de Longitud: CoT asume cadenas de razonamiento de longitud fija, pero en la realidad, problemas varían. Modelos entrenados en cadenas cortas (3-5 pasos) fallaban en largas (10+), añadiendo filler irrelevante o cortando prematuramente. En un test con ecuaciones matemáticas, un modelo generó «disparates fluídos» como repetir pasos redundantes, inflando tiempos de cómputo sin resolver nada.
- Generalización de Formato: Sensibilidad a cambios en el prompt. Un modelo que razona bien con «Paso 1: Analiza X» falla si se cambia a «Examina X primero». En pruebas, variaciones mínimas en wording reducían precisión en un 40%, mostrando que CoT no es abstracto, sino dependiente de formatos comunes en datos de entrenamiento.
DataAlchemy permitió replicar estos fallos controladamente: entrenaron modelos en datasets sintéticos, midiendo degradación en OOD. Resultados: colapso del 50-80% en performance, confirmando que CoT es «matching estructurado», no inferencia lógica. Un hallazgo clave: el fine-tuning supervisado (SFT) mejora rápidamente en OOD específicos, pero no generaliza, es un «parche» que memoriza, no aprende.
Estos experimentos no son abstractos; tienen ecos en fallos reales de IA. Por instancia, en benchmarks como GSM8K (matemáticas escolares), CoT eleva precisión al 90%, pero en variaciones OOD (e.g., problemas con twists culturales), cae al 40%. En aplicaciones prácticas, como chatbots legales, un LLM podría «razonar» un contrato basado en patrones estándar, ignorando cláusulas únicas, llevando a litigios costosos.
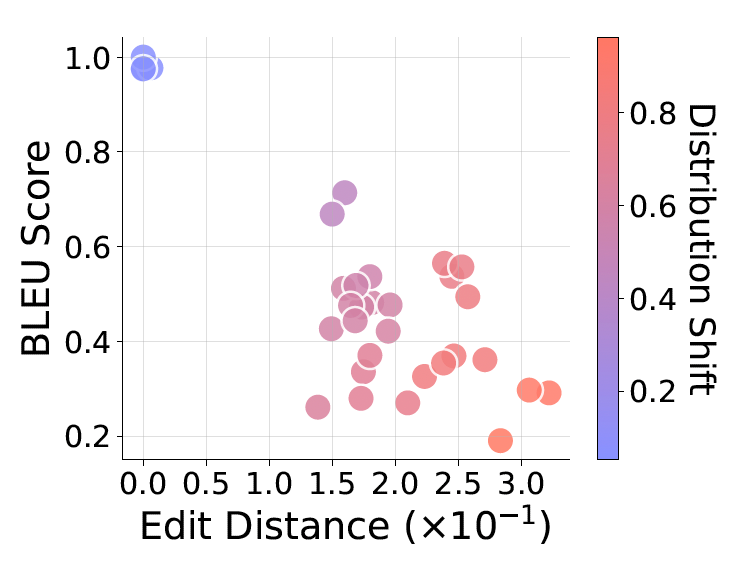
Implicaciones para el Desarrollo de IA: De la Sobreconfianza a la Prudencia Estratégica
Los hallazgos del estudio tienen ondas expansivas en la industria. Primero, advierten contra la «sobreconfianza»: CoT genera outputs «fluídos» que parecen profundos, pero son superficiales fuera de entrenamiento. En high-stakes, como finanzas (predicción de mercados volátiles) o medicina (diagnósticos con datos atípicos), esto podría generar «basura elocuente» –consejos plausibles pero peligrosos. Imagina un LLM en trading que, ante una crisis económica no vista en datos (e.g., post-pandemia 2020), recomienda estrategias basadas en patrones históricos, causando pérdidas masivas.
Para desarrolladores, el estudio ofrece tres consejos prácticos:
- Evitar la Sobredependencia: No tratar CoT como módulo de razonamiento fiable. En apps, implementar guardrails: auditorías rigurosas, cross-checking con múltiples modelos y fallbacks humanos. En educación, herramientas como asistentes de estudio podrían usar CoT para explicaciones básicas, pero no para evaluaciones críticas.
- Priorizar Pruebas OOD: Validación estándar es insuficiente; testear en cambios de tarea, longitud y formato. Empresas podrían adoptar frameworks como DataAlchemy para simular OOD internamente, reduciendo riesgos en producción.
- Ver Fine-Tuning como Parche Temporal: SFT arregla OOD específicos rápidamente, pero no crea generalización verdadera. Es un ciclo de parches: cada nuevo OOD requiere más tuning, inflando costos. Solución: invertir en modelos con entrenamiento diversificado desde cero.
En el ecosistema empresarial, esto impacta a gigantes como OpenAI o Google, que promueven CoT en productos como ChatGPT o Bard. Podría impulsar regulaciones: la UE ya exige «transparencia en razonamiento», y estos hallazgos podrían presionar por tests OOD obligatorios en certificaciones IA. Para startups, es una oportunidad: enfocarse en nichos donde CoT brilla (tareas estructuradas), o innovar en «razonamiento híbrido» humano-IA.
A nivel societal, el estudio resalta riesgos éticos: si LLMs generan «disparates fluídos» en policy-making (e.g., asesorando gobiernos en clima), podrían perpetuar errores basados en datos sesgados. En educación, estudiantes podrían confiar ciegamente en CoT, atrofiando su pensamiento crítico. Y en empleo, si CoT se sobrevalora, podría desplazar jobs sin entregar valor real, exacerbando desigualdades.
El Futuro de la IA: Hacia un Razonamiento Más Robusto y Humano-Céntrico
Mirando adelante, el estudio no es un veredicto de muerte para CoT; es un llamado a evolución. Investigadores sugieren modelos con «generalización verdadera»: entrenar en datasets más diversos, incorporar feedback dinámico o integrar multimodalidad (texto + imágenes/datos sensoriales). En 2025, con avances como modelos cuánticos o federados, podría surgir «CoT 2.0» que adapte cadenas en tiempo real a OOD.
Para la sociedad, esto refuerza la necesidad de enfoque humano-céntrico: IA como asistente, no oráculo. En medicina, por ejemplo, un LLM con CoT podría sugerir diagnósticos, pero un médico valida. En finanzas, algoritmos razonan escenarios, pero humanos deciden riesgos.
Al final, este estudio nos recuerda que la IA, por impresionante, es un espejo de nuestros datos –limitado, sesgado, frágil. «Disparates fluídos» no son fallos aislados; son síntomas de una tecnología aún inmadura. La clave para el futuro: reconocer límites, innovar con prudencia y mantener al humano al volante. En la carrera por la inteligencia artificial, a veces, la verdadera sabiduría es saber cuándo desacelerar.
Referencias

