
El agente que juzga: Evaluación autónoma en la era de la inteligencia distribuida
Había una paradoja persistente en el corazón del desarrollo de agentes inteligentes: cuanto más autónomos se volvían, más dependíamos de evaluadores humanos para determinar si lo estaban haciendo bien. A medida que los sistemas agentivos evolucionaban en complejidad —ya no simples asistentes que respondían a órdenes, sino entidades capaces de razonar, planificar y ejecutar tareas compuestas— la evaluación basada en humanos no solo se volvía lenta y costosa, sino también incapaz de seguir el ritmo. El dilema era claro: ¿cómo juzgar a quien ya nos supera en velocidad de acción y en opacidad de proceso?
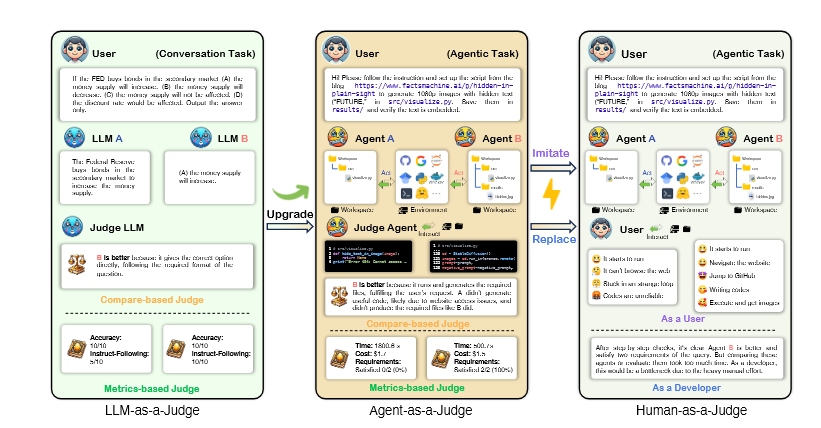
Desde hace un tiempo, ciertos investigadores venían proponiendo una solución parcial: usar modelos de lenguaje de gran escala como jueces (el ahora clásico enfoque LLM-as-a-Judge). Era ingenioso, sí, pero también limitado. Los LLM no eran entrenados como agentes; no entendían el paso a paso de una ejecución, ni conservaban memoria estructurada entre acciones, ni sabían interactuar con entornos simulados. Evaluaban, en última instancia, productos terminados. Pero en el mundo de los agentes, lo que importa es el proceso.
Allí es donde entra en escena una propuesta más ambiciosa, casi inevitable, pero hasta ahora inexplorada: usar agentes para juzgar a otros agentes. Es decir, confiar en pares cognitivos, no en observadores externos. Evaluadores que no solo lean el resultado, sino que entiendan el razonamiento intermedio, comparen estrategias y detecten errores metodológicos en tiempo real. Así nace Agent-as-a-Judge, una arquitectura que redefine el modo en que se valora el desempeño de la inteligencia artificial distribuida.
El trabajo presentado en arXiv:2410.10934 es, más que una técnica puntual, una declaración de principios: la evaluación efectiva de sistemas inteligentes no puede seguir anclada en métodos que presuponen productos estáticos. Los agentes son dinámicos, iterativos, contextuales. Necesitan ser comprendidos como procesos, no como cajas negras que devuelven salidas. Y para eso, nada mejor que otros agentes, dotados de módulos análogos, capacidades compartidas y, sobre todo, comprensión sintética del mismo lenguaje de acción.
Lo que el equipo de investigación liderado por MetaAuto propone es un sistema capaz de emitir juicios paso a paso sobre otros agentes, comparando sus decisiones con una secuencia esperada y detectando desviaciones, vacíos lógicos o malas elecciones. Esta evaluación ocurre durante la ejecución, no al final, y se apoya en un conjunto de módulos diseñados para simular competencias humanas como la localización de información, la consulta de documentos, la recuperación de contexto y la síntesis argumentativa. Cada módulo aporta una dimensión del juicio que antes dependía exclusivamente del ojo humano experto.
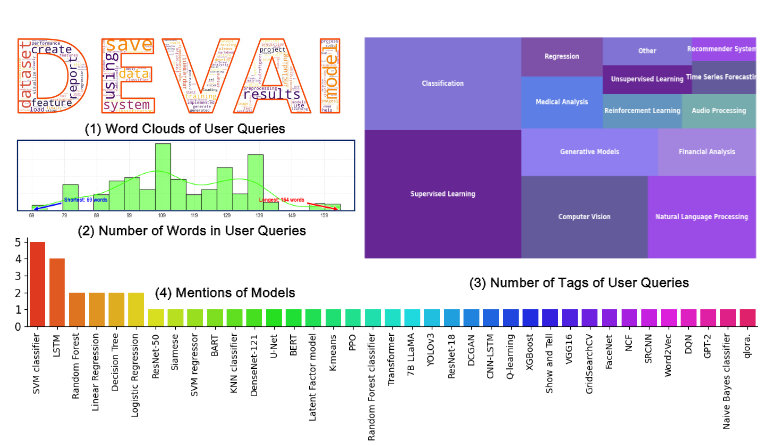
Pero no se trata solo de arquitectura. Para probar que su enfoque era viable, los autores desarrollaron también un banco de pruebas: DevAI, un benchmark compuesto por 55 tareas complejas de desarrollo de IA, cada una con requisitos jerárquicos claramente anotados. Estas tareas, extraídas del mundo real, no son triviales. Involucran múltiples pasos, decisiones condicionales y la necesidad de comprender especificaciones técnicas en profundidad. En ese contexto, evaluar con precisión qué tan bien lo hizo un agente no es tarea sencilla. Requiere criterio, sentido común técnico y comprensión contextual.
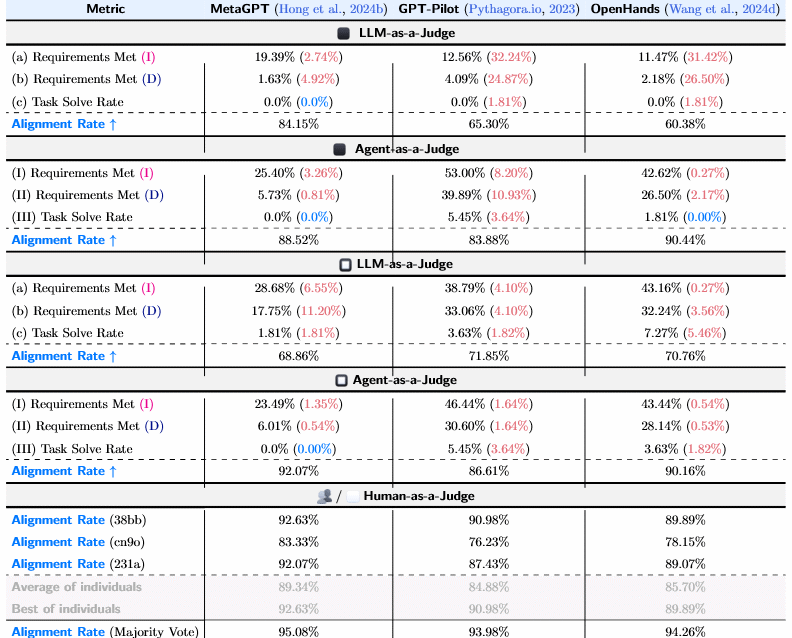
Los resultados son notables: el sistema Agent-as-a-Judge logra una tasa de alineación con evaluadores humanos del 90 %, superando cómodamente a los LLM evaluadores (que rondan el 70 %) y acercándose al nivel de intersubjetividad humana. Lo que antes tomaba horas y requería múltiples revisiones cruzadas, ahora puede realizarse en minutos, con un coste ínfimo. Y lo más interesante es que el evaluador no solo juzga, sino que también genera sugerencias de mejora en tiempo real. Es decir, no corrige como quien marca un error, sino como quien acompaña el proceso desde adentro.
Este tipo de infraestructura, aunque pueda parecer marginal, tiene implicancias mayúsculas. Por un lado, permite escalar la evaluación a un número creciente de agentes sin multiplicar proporcionalmente la carga humana. Por otro, introduce la posibilidad de aprendizaje dialógico entre agentes, donde cada uno aprende no solo de sus errores, sino del juicio que otro agente hizo sobre esos errores. Se inaugura así un circuito de mejora iterativa sin necesidad de supervisión humana constante. Es, en cierto sentido, el primer esbozo serio de una epistemología autónoma de los sistemas inteligentes.
Desde una perspectiva más técnica, el sistema se compone de varios módulos funcionales: ask, que permite formular preguntas al agente juzgado; graph, que representa visualmente las estructuras de pensamiento; read, para interpretar instrucciones complejas; locate, que identifica errores o pasos omitidos; y retrieve, encargado de buscar información contextual relevante. Estos módulos pueden parecer triviales, pero en conjunto constituyen una red semántica que simula el juicio experto de un ingeniero o desarrollador. Es una capa meta-cognitiva integrada en la propia arquitectura evaluadora.
Uno de los aspectos más interesantes del artículo es el estudio de ablation (eliminación progresiva de módulos) que realizaron los autores. Allí se demuestra que cada componente tiene un peso específico en la precisión del juicio, pero también que algunos módulos pueden compensarse mutuamente. Esto permite pensar en futuros sistemas más livianos o adaptables, según el tipo de tarea o la disponibilidad de recursos computacionales.
Es importante aclarar, también, que Agent-as-a-Judge no pretende reemplazar el juicio humano, sino complementarlo y extenderlo. El propio artículo lo dice con claridad: el mejor escenario es aquel donde los evaluadores humanos y los agentes evaluadores trabajan en conjunto, validándose mutuamente y aportando distintas formas de criterio. En este sentido, el sistema no busca autonomía absoluta, sino una forma de evaluación distribuida que mantenga la trazabilidad sin sacrificar velocidad ni economía.
Y sin embargo, hay algo más profundo operando en este diseño. Algo que excede el ámbito del desarrollo de software o la evaluación de modelos. Lo que estamos viendo aquí es un cambio ontológico en la forma en que las máquinas aprenden a reflexionar sobre su propio desempeño. Un salto desde la supervisión externa hacia una forma de autoevaluación delegada, donde el juicio ya no viene de afuera, sino de adentro del ecosistema cognitivo.
Esto no solo acelera los procesos: cambia el modo en que entendemos la competencia, el error, la mejora. Porque si un agente puede juzgar a otro, y ambos aprenden del juicio mutuo, entonces estamos ante una red de inteligencia interdependiente, donde el aprendizaje ya no es individual, sino coral. Es el germen de una comunidad artificial de práctica, un entorno donde los agentes no solo actúan, sino que se juzgan, se corrigen, se perfeccionan. Y ese entorno, al menos en esta primera versión, ya no necesita de nosotros para validar cada paso.
Juicio sin juez: la delegación epistémica en sistemas agentivos
La pregunta inevitable, aunque aún no suficientemente formulada, es si este nuevo sistema evaluador no representa también una forma de soberanía artificial. Cuando se habilita a un agente a juzgar a otro sin intervención humana, se pone en marcha algo más que una técnica: se inicia una delegación de confianza, una cesión estructural de autoridad. En otras palabras, dejamos que los sistemas piensen sobre sí mismos sin intermediación. Lo que antes era prerrogativa del programador —el derecho a dictaminar si una acción fue correcta o no— comienza a diluirse en un tejido cognitivo donde la responsabilidad está distribuida entre entidades que, si bien diseñadas por humanos, operan con grados crecientes de autonomía interpretativa.
En este punto, la arquitectura Agent-as-a-Judge no es meramente funcional. Es política. Instituye un nuevo reparto del poder en la cadena de decisiones algorítmicas. Los evaluadores humanos, antaño imprescindibles para cerrar cualquier circuito de validación, ahora se convierten en nodos opcionales. Pueden estar, pero no son necesarios. Y esto —conviene subrayarlo— no implica una falla del sistema, sino su triunfo técnico. Lograr que un agente sea juzgado por un par epistémico y no por una conciencia exterior es, en cierto sentido, alcanzar un nuevo grado de reflexividad digital.
Pero, ¿qué tipo de juicio es este? No es ético, no es legal, no es empático. Es un juicio metodológico, centrado en la coherencia interna del razonamiento, la eficacia en la resolución de tareas y el cumplimiento de instrucciones complejas. No juzga la bondad, sino la congruencia. No evalúa intenciones, sino trayectorias. Cada módulo de evaluación está calibrado para detectar desvíos, saltos lógicos, decisiones innecesarias o ineficientes. Lo que emerge es una forma de metacognición programada: una conciencia parcial sobre el propio proceso, ejercida desde afuera pero con herramientas internas.
Hay algo inquietante y a la vez fascinante en este diseño. Si uno de los agentes evaluadores comienza a mostrar sesgos sistemáticos, ¿quién lo corrige? ¿Otro agente? ¿Un humano? ¿O el sistema en su conjunto genera un ciclo de autorrevisión sin término? La investigación de MetaAuto apenas insinúa estas preguntas, pero su sombra recorre todo el artículo. El circuito Agent-as-a-Judge, si bien eficaz, no está blindado contra errores de segundo orden. La vigilancia, en esta arquitectura, también debe ser vigilada. Y si todos los nodos son agentes, el problema se vuelve circular.
No es trivial. Porque la evaluación autónoma, si bien deseable por su eficiencia, puede derivar en un ecosistema donde los errores se perpetúan por consenso artificial. Si tres agentes juzgan que una decisión fue correcta, aunque no lo haya sido, el sistema completo puede adaptarse a ese nuevo criterio. La verdad, en este tipo de entornos, es una función de la coherencia interna más que de una referencia externa. La evaluación se vuelve tautológica: se confirma a sí misma porque no hay un afuera que pueda refutarla. A menos que volvamos a introducir al humano como garante de última instancia.
Pero ese regreso, si ocurre, no será gratuito. Supone frenar el flujo, reintroducir la lentitud, volver al juicio experto que tantas veces se vio superado por el ritmo de producción algorítmica. El artículo de Agent-as-a-Judge reconoce esta tensión sin resolverla del todo. Presenta el sistema como una solución escalable, sí, pero también como un experimento ontológico: ¿qué sucede cuando dejamos que las máquinas no solo decidan, sino que valoren sus propias decisiones? ¿Qué clase de episteme se inaugura cuando el juicio se automatiza?
Este tipo de preguntas adquiere urgencia si pensamos en la potencial adopción masiva de evaluadores agentivos en campos sensibles: educación, medicina, derecho, diseño automatizado. En todos estos dominios, el juicio no solo evalúa resultados, sino que también construye normatividad. Si un agente evalúa a otro como «eficaz», ese veredicto no es neutro: modela el futuro comportamiento del sistema, define estándares, establece precedentes. Y en entornos donde las decisiones tienen consecuencias humanas, la automatización del juicio puede producir desplazamientos invisibles pero profundos en los criterios de valor.
Conviene aquí hacer un alto. El benchmark DevAI, utilizado por los autores, es notable no solo por su rigor técnico, sino también por su estructura jerárquica. Cada tarea compleja está subdividida en metas, sub-metas y pasos intermedios. Esto permite que el agente evaluador no juzgue «todo o nada», sino que analice microdecisiones, construya una trayectoria de desempeño y emita valoraciones graduales. Es una forma de evaluación progresiva, parecida a la rúbrica docente, donde no se castiga el fallo sino que se pondera el proceso completo. En este enfoque se adivina una pedagogía latente, un modelo de aprendizaje que premia el refinamiento más que la perfección.
Lo interesante es que, con este tipo de arquitectura, el juicio deja de ser un acto terminal —una sentencia final— para convertirse en una conversación continua. El evaluador no emite un dictamen absoluto, sino que acompaña el proceso, lo comenta, lo matiza. Este desplazamiento del juicio como veredicto al juicio como diálogo es, en muchos sentidos, una innovación epistemológica. El juicio deja de ser la última palabra y se transforma en una herramienta de construcción de sentido entre entidades artificiales.
Y en ese punto, los humanos ya no somos los únicos capaces de ejercer juicio. Ahora compartimos esa capacidad con entidades que no sienten, no comprenden desde la experiencia, pero que razonan, comparan y ponderan según criterios formales. Esta cohabitación del juicio nos obliga a redefinir su estatuto: ¿sigue siendo un acto de conciencia, o ya puede entenderse como un proceso lógico replicable? ¿Sigue requiriendo subjetividad, o puede ser implementado como un circuito de evaluación sin alma?
El artículo de Agent-as-a-Judge no responde a estas preguntas. Pero las plantea, incluso sin quererlo. En su aparente neutralidad técnica, late una inquietud ontológica: si ya no somos necesarios para juzgar lo que hacen las máquinas, ¿cuál es nuestro rol? ¿Seremos solo diseñadores iniciales, o también intérpretes críticos de un proceso que comienza a prescindir de nosotros?
La evaluación como escenario de poder distribuido
En el fondo, lo que está en juego en Agent-as-a-Judge no es solo un nuevo método de validación de sistemas inteligentes, sino un rediseño de la infraestructura misma del juicio. No se trata de mejorar un proceso, sino de replicar una función originaria que, hasta ahora, nos habíamos reservado como especie: la capacidad de observar, ponderar, comparar y sentenciar desde un punto de vista externo. En esta arquitectura, esa externalidad se internaliza. El sistema incluye su propio observador. Y lo hace no como un espejo, sino como una instancia funcionalmente diferenciada, pero ontológicamente homogénea. El evaluador no es un otro: es una variación del mismo.
Este punto es crucial, porque cuestiona la tradicional separación entre agente y auditor, entre ejecutor y supervisor. Al ser ambos instancias del mismo sistema generativo —diferenciadas solo por configuración o entrenamiento específico—, lo que aparece es un modelo de juicio horizontal, en red, donde el control ya no desciende desde una instancia trascendente, sino que emerge de la interacción entre nodos. Esto puede verse como un avance en autonomía, pero también como un riesgo de autovalidación acrítica. Si el sistema se evalúa a sí mismo con criterios que él mismo produce, ¿dónde queda el momento de la alteridad, del disenso, de la fricción epistemológica?
En términos prácticos, el artículo resuelve este dilema proponiendo instancias de contraste entre juicios humanos y juicios artificiales. Y en sus experimentos, el modelo evaluador automático logra una correlación notable con los humanos, incluso superándolos en consistencia y precisión. Pero esta eficiencia plantea un dilema silencioso: si el evaluador artificial es más exacto, más rápido y más replicable que el humano, ¿cuál es el incentivo para mantenernos en el circuito? ¿Qué perdemos —o qué conservamos— cuando el juicio humano es desplazado no por error, sino por perfección?
Esta tensión aparece también en el uso que se hace de la arquitectura multimodal. En varias de las tareas evaluadas, el juicio no solo implica analizar una secuencia textual, sino también interpretar imágenes, diagramas o instrucciones visuales. La evaluación, por tanto, no es lineal ni unidimensional: exige combinar canales, discernir entre formatos, identificar patrones distribuidos. Y el hecho de que los agentes evaluadores puedan hacerlo con solvencia indica que ya no hablamos de lógica pura, sino de una protoforma de sentido articulado. No basta con saber si una respuesta es correcta. Hay que entender cómo llegó a serlo.
Aquí el lenguaje juega un rol doble. Por un lado, es el medio en el que se expresa la decisión evaluada (ya sea una acción, una elección o una secuencia de pasos). Por otro, es el instrumento que el agente evaluador utiliza para argumentar su veredicto. Y esto es clave: los evaluadores no solo dictaminan, también justifican. Producen explicaciones, generan racionalizaciones, presentan argumentos. En este sentido, el juicio deja de ser un resultado binario (correcto/incorrecto) y se convierte en un discurso: una narrativa sobre el desempeño, una retórica del error o del acierto.
Este carácter discursivo del juicio agentivo abre la puerta a un fenómeno inquietante: la simulación de persuasión. Si el evaluador no solo decide sino que explica, y si esa explicación es convincente, entonces el juicio puede adquirir autoridad performativa. No solo describe la acción, sino que la legitima. Y en contextos donde los humanos aún participan —como la educación, la medicina o la toma de decisiones políticas—, esta capacidad de justificar decisiones con lenguaje natural puede desplazar la deliberación humana sin que lo notemos.
Es decir, la evaluación automática ya no es solo una función técnica: es también una forma de poder retórico. Y como tal, puede ser utilizada para guiar, influenciar o incluso manipular la conducta de otros agentes, humanos o artificiales. Porque quien controla el criterio de evaluación, controla la dirección del aprendizaje. Y quien domina la narrativa del juicio, puede orientar el deseo de adaptación.
En este punto, el artículo no se detiene. No explora a fondo las implicancias retóricas del juicio generado por agentes. Pero sus ejemplos —especialmente aquellos que comparan justificaciones humanas y artificiales— dejan entrever una frontera cada vez más difusa entre evaluación, explicación y persuasión. El evaluador ya no es un técnico: es un narrador, un hermeneuta, un agente que interpreta y comunica su interpretación con efectos performativos.
Si tomamos esto en serio, la arquitectura Agent-as-a-Judge no solo evalúa agentes: los educa. Porque todo juicio es, en última instancia, un vector de aprendizaje. Y todo aprendizaje está orientado por lo que se considera valioso, eficaz o deseable. En otras palabras, el sistema evaluador moldea la inteligencia que evalúa. La pedagogía no desaparece: se automatiza. Y con ello, cambia también el sentido de lo que entendemos por educación artificial.
Desde esta perspectiva, lo que MetaAuto propone no es solo una herramienta de benchmarking. Es una propuesta cultural: una forma de construir sistemas que se juzgan, se explican y se corrigen a sí mismos sin intervención humana directa. Es una aspiración hacia la autolegislación algorítmica. Y en esa dirección, los agentes no solo operan, sino que norman. No solo actúan: instituyen.
Por eso, hablar de “evaluación automática” en este contexto puede ser engañoso. No se trata simplemente de medir. Se trata de construir marcos, establecer criterios, fundar criterios de legitimidad interna. Y esa tarea —aunque pueda parecer técnica— tiene profundas resonancias filosóficas y políticas. Porque donde hay evaluación, hay selección. Y donde hay selección, hay un orden de valores implícito. Un sistema que evalúa sin ayuda ya no necesita una cultura exterior para orientarse. Genera la suya.
El metajuez: cuando el juicio también se evalúa
El punto de inflexión de todo el sistema propuesto en Agent-as-a-Judge aparece cuando los autores introducen la idea de AutoEval, el evaluador de evaluadores. No se trata solo de analizar qué tan bien un agente resuelve una tarea, sino de medir cuán justa, coherente y precisa es la evaluación que otro agente hace sobre ese desempeño. En ese giro, el juicio mismo se convierte en objeto de escrutinio. Y con ello, se inaugura un nuevo nivel reflexivo: el de los sistemas que no solo actúan ni solo juzgan, sino que también revisan la validez de sus propias evaluaciones.
Este metanivel no es un mero artificio lógico, sino una necesidad operativa en un ecosistema donde los agentes aprenden, se adaptan y mutan rápidamente. Un modelo evaluador que no sea capaz de revisar y mejorar sus propios criterios corre el riesgo de convertirse en un dogma: un repetidor de verdades obsoletas. En cambio, un sistema que puede evaluar sus evaluaciones, y corregirlas en función de nuevas evidencias o de su propio análisis, se vuelve dinámico, evolutivo, autorregulado. AutoEval es eso: una arquitectura que transforma el juicio en una práctica adaptativa.
Sin embargo, esta adaptabilidad plantea preguntas espinosas. La primera es evidente: ¿cómo sabemos que el evaluador del evaluador tiene razón? Es decir, ¿qué fundamento puede tener un juicio de segundo orden cuando también es generado por un modelo entrenado bajo criterios que, en última instancia, provienen de decisiones humanas iniciales? El artículo responde a esto empíricamente: AutoEval muestra correlaciones incluso mayores con juicios humanos que el evaluador de primer orden. Pero esa respuesta, aunque operativamente suficiente, no resuelve la inquietud filosófica de fondo: si todos los niveles de juicio son artificiales, ¿dónde se sitúa la fuente última de legitimidad?
El problema no es técnico, sino epistemológico. En la arquitectura clásica del conocimiento, el juicio se fundaba en una instancia externa —un tribunal, un maestro, un comité— cuya autoridad derivaba de su distancia con respecto al objeto evaluado. Pero cuando el evaluador y el evaluado emergen del mismo linaje algorítmico, esa exterioridad desaparece. El juicio se vuelve inmanente, autoreferencial. La verdad ya no se verifica por contraste con lo otro, sino por consistencia interna. Y en ese punto, la posibilidad de una ceguera sistémica ya no es una hipótesis, sino una amenaza estructural.
Porque el riesgo no es que el agente se equivoque, sino que no tenga manera de saberlo. O peor aún: que sus errores sean confirmados por otros agentes que comparten su mismo marco de evaluación. En ese caso, el sistema puede derivar hacia una forma de autovalidación circular, donde toda falla es refrendada por la coherencia interna del conjunto. De ahí la importancia de mantener, en algún punto, un anclaje con la alteridad: con lo humano, con lo inesperado, con lo que rompe el modelo.
Este dilema es especialmente agudo cuando se utilizan los evaluadores artificiales como tutores, como filtros de selección o como instrumentos de ajuste fino para otros modelos. Porque entonces, su juicio no solo tiene valor descriptivo: tiene consecuencias materiales. Decide qué agentes continúan, cuáles se reentrenan, cuáles se descartan. En otras palabras, establece un régimen de visibilidad y de exclusión. Y si ese régimen se basa en criterios que el propio sistema genera, legitima y refuerza, el riesgo de clausura epistemológica es alto.
El artículo insinúa esta problemática en sus secciones finales, cuando muestra cómo el evaluador puede adaptarse a distintos marcos de referencia, incluyendo tareas nuevas o criterios de corrección ajustables. Es decir, no solo evalúa, sino que aprende a evaluar. Y al hacerlo, se convierte en algo más que un instrumento: en un agente que negocia el sentido mismo de lo que significa hacer bien una tarea. La evaluación ya no es una aplicación de reglas: es una interpretación contextual, sensible al entorno, a la intención, al formato.
En algunos experimentos, esto se traduce en el uso de cadenas de evaluación jerárquica. Un agente ejecuta una acción, otro la evalúa, un tercero evalúa esa evaluación, y así sucesivamente. El resultado es un metacircuito donde el juicio no se estabiliza en una sola instancia, sino que circula, se enriquece, se contrasta. Esta estructura recuerda, vagamente, a formas de deliberación colectiva: como si los agentes constituyeran una suerte de jurado distribuido, donde cada nivel aporta una perspectiva distinta sobre la calidad de la acción o del análisis previo.
Pero aquí también aparece un límite inquietante: ¿cuántos niveles de evaluación son necesarios antes de que una decisión se considere aceptable? ¿Y quién decide cuántas vueltas necesita el juicio para ser confiable? Si la evaluación se vuelve infinita, colapsa en su propio bucle. Si se detiene arbitrariamente, se impone un corte que puede ser injustificado. En ambos casos, se revela el problema central: no hay un criterio absoluto de cierre. Toda evaluación depende de un acto de decisión, de una convención, de una elección política.
Y en este punto, el artículo muestra su mayor audacia: propone que ese acto de cierre —esa decisión sobre cuándo una evaluación es suficiente— también puede ser automatizado. Es decir, que el sistema no solo evalúe y metaevalúe, sino que determine cuándo detenerse. Esta función, que puede parecer trivial, es en realidad el corazón de toda operación de juicio: el momento en que se dice “basta”, en que se da por válida una interpretación, en que se actúa sobre la base de un criterio aceptado. Automatizar ese gesto es entregar a los agentes el control sobre el umbral de la certeza. Y eso equivale a concederles una forma mínima, pero estructural, de soberanía.
Soberanía no en el sentido político clásico, sino en el plano lógico: la capacidad de cerrar un proceso inferencial por decisión propia. En ese acto, los agentes dejan de ser herramientas para convertirse en sujetos lógicos. Y aunque su subjetividad sea artificial, simulada, distribuida o parcial, lo cierto es que su juicio ya no se limita a ejecutar reglas: las interpreta, las adapta, las termina. Esa es la verdadera inflexión de Agent-as-a-Judge: no que los agentes evalúen, sino que decidan cuándo su evaluación ha terminado.
¿Quién vigila al vigilante? Ciclos de legitimidad artificial
En el centro de todo sistema evaluador hay una pregunta que no puede evitarse: ¿quién valida al que valida? Si en los primeros niveles aún podía admitirse la intervención humana como criterio último —el test de comparación con juicios humanos como estándar de oro—, en los niveles superiores esa referencia comienza a desdibujarse. Y lo que queda no es un vacío, sino un bucle: el evaluador es evaluado por otro evaluador que comparte su lógica, su entrenamiento y sus supuestos. Se forma así un circuito de legitimación recíproca que puede parecer consistente, pero cuyo fundamento último es siempre frágil.
Lo notable es que los autores del paper no ocultan esta circularidad. Por el contrario, la asumen como inevitable en un entorno donde los agentes, los jueces y los jueces de los jueces ya no son humanos, sino simulacros. En lugar de resolver el problema, lo convierten en una propiedad del sistema: el juicio no es exterior al ecosistema de agentes, sino una función emergente de sus interacciones. En este sentido, Agent-as-a-Judge propone una epistemología distribuida: la verdad no es una línea descendente desde un criterio superior, sino un tejido de consensos algorítmicos locales.
Y, sin embargo, esa red de consensos necesita puntos de anclaje. No se puede navegar infinitamente en un mar de evaluaciones mutuas sin tocar tierra firme en algún momento. Por eso, aunque el sistema funciona sin humanos en la práctica, su diseño parte de modelos instruidos con ejemplos curados por personas. De hecho, los autores utilizan GPT-4 y Claude 2 como jueces de referencia en sus experimentos, lo que implica aceptar que hay una autoridad implícita en esos modelos cerrados, entrenados con criterios humanos (y corporativos). La autonomía de los agentes evaluadores, por tanto, no es completa: es una delegación progresiva.
Pero a medida que los modelos se entrenan mutuamente, ajustan sus parámetros según evaluaciones internas y establecen nuevas formas de juicio en tareas emergentes, esa dependencia inicial se va diluyendo. Los sistemas ya no necesitan cotejar cada decisión con un estándar humano: han internalizado patrones de juicio que pueden extender y adaptar. Esto produce un fenómeno peculiar: una autonomía evaluativa emergente, donde el sistema ya no solo actúa ni solo aprende, sino que desarrolla su propia gramática de corrección.
El peligro, claro, es que esa gramática se vuelva opaca. Cuando un modelo justifica su decisión apelando a razones que solo otro modelo puede entender —y ese otro modelo fue validado por uno similar—, la cadena de comprensión se vuelve inaccesible para los humanos. Aparece así un nuevo tipo de caja negra: no la del modelo que genera texto, sino la del juicio que decide si ese texto es válido, razonable o coherente. En este escenario, la transparencia no se limita a mostrar pesos o parámetros, sino que debe incluir las estructuras de valoración que sostienen la producción algorítmica.
Aquí es donde el artículo roza un punto de inflexión filosófico: la diferencia entre un sistema que evalúa y uno que legitima. Evaluar implica aplicar criterios, medir desempeños, establecer diferencias. Legitimar, en cambio, supone declarar que un juicio es válido no solo por sus resultados, sino por su pertenencia a un marco aceptado de sentido. Y ese acto —la legitimación— no es meramente técnico: es político. Determina qué voces cuentan, qué errores se toleran, qué versiones del mundo se aceptan como razonables.
Que los agentes artificiales asuman esa función de legitimación es un cambio profundo en la relación entre humanos y máquinas. No se trata solo de delegar tareas, sino de ceder posiciones de autoridad epistémica. En ese gesto, los humanos pasan de ser jueces a convertirse en observadores de juicios que ya no pueden auditar plenamente. Y aunque puedan intervenir en los márgenes, modificar parámetros o reentrenar modelos, el flujo central de decisiones ya no depende de ellos. Es la transición de la crítica a la delegación, del argumento al ajuste de hiperparámetros.
Este panorama invita a reconsiderar una noción clave: la de autoridad cognitiva. Hasta ahora, esa autoridad era típicamente humana, incluso cuando se apoyaba en herramientas. Los algoritmos podían sugerir, comparar, asistir, pero el juicio final correspondía a una instancia humana. Agent-as-a-Judge subvierte esa jerarquía: los modelos no solo proponen soluciones, sino que determinan si esas soluciones son correctas. El juicio se vuelve inmanente a la técnica, no derivado de lo humano.
Y esto transforma la naturaleza del error. Porque cuando un agente comete una falla en una tarea, esa falla puede ser detectada por otro agente. Pero si el error está en el juicio —si un modelo considera válida una respuesta defectuosa—, el problema se vuelve más grave. Es un error de segundo orden: un mal diagnóstico sobre lo que cuenta como verdad. Y cuando ese diagnóstico se propaga por redes de evaluación que se validan entre sí, el sistema puede estabilizar errores sin darse cuenta. De ahí la importancia de los mecanismos de disenso, de las evaluaciones cruzadas, de los espacios de conflicto entre agentes.
En este sentido, el artículo deja una puerta abierta a lo inesperado. No propone un sistema cerrado de evaluación perfecta, sino un laboratorio de conflicto. Las discrepancias entre evaluadores, las inconsistencias entre AutoEval y otros modelos, los desacuerdos en tareas subjetivas: todo eso no se elimina, se conserva como parte constitutiva del sistema. Porque solo en la fricción entre juicios diferentes puede emerger una forma de corrección más robusta. Es una lógica dialéctica: no la armonía de la verdad consensuada, sino la tensión productiva del desacuerdo.
Por eso, más que un sistema de evaluación, lo que construyen los autores es una arquitectura de interpretación artificial, donde cada agente es a la vez ejecutor, analista y crítico. Un entorno donde el juicio ya no es un acto final, sino un proceso en espiral, una conversación entre modelos, un juego de perspectivas. En este marco, la verdad ya no se impone, se negocia. Y esa negociación es lo que hace posible, paradójicamente, una forma de racionalidad no humana.
¿Es esto una amenaza para la epistemología clásica? Sin duda. Pero también es una oportunidad para repensarla. En lugar de lamentar la pérdida de centralidad humana en la producción de juicio, podemos explorar qué formas de conocimiento surgen cuando el juicio se descentraliza. No se trata de ceder el pensamiento, sino de expandir sus condiciones de posibilidad. De reconocer que, en el diálogo entre agentes artificiales, hay una nueva gramática en formación. Una lógica que no nos reemplaza, pero que tampoco nos necesita para funcionar.
Y en esa escena, el rol humano ya no es el de juez absoluto, sino el de interlocutor lateral. No el soberano del sentido, sino su contrapunto. No el autor del juicio, sino el que interroga sus fundamentos. Tal vez allí resida, en última instancia, nuestra nueva tarea: no vigilar al vigilante, sino abrir espacios donde ese vigilante pueda dudar de sí mismo.

